优点1:主干网络(CSPDarknet)加入Fcous结构
主干网络加入Fcous结构,将图片宽高信息缩小,减小参数量,提升网络计算速度
Fcous结构:将输入的图片先经过Fcos结构对图片进行每隔一个像素取出一个值,得到四个特征层,然后再进行concat。从而图片宽高的信息缩小,通道数增加。在原始信息丢失较少的情况下,减小了参数量(由于fcous替代了两层卷积与一层bottleneck)
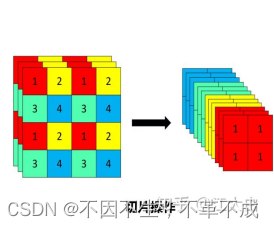
图 1 Fcous示意
优点2:主干网络的激活函数替换为silu激活函数
silu函数相比于rule非线性能力更强,解决了rule当有负数输入输出为0,发生梯度弥散的缺点。同时继承了relu收敛更快的优点。
silu函数=x*sigmoid(x),是relu与sigmoid的结合。可以看做是一个平滑的Relu,对比来看,silu解决了relu具有负数输入输出为0的缺点,不会发生梯度弥散的问题。
(上层神经元通过加权求和,得到输出值,然后被作用一个激活函数,得到下一层的输入值。引入激活函数的目的是为了增加神经网络的非线性拟合能力。)
(被fcous处理后的feature map会被用silu激活函数的,残差卷积层进行卷积,卷积后进入
CSPLayer。)
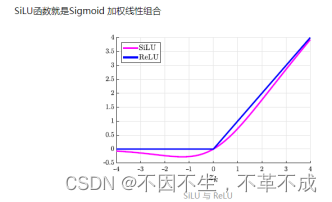
图 2 silu激活函数
优点3:主干网络沿用CSP结构
CSPLayer:内部的主要特征提取利用残差结构,但csplayer将feature map分为两部分,一部分进入残差块,与瓶颈结构,特征提取,另一部分与特征提取后的feature map进行concat操作从而进行信息融合。(需要注意从代码上,part1与part2是一样的输入)
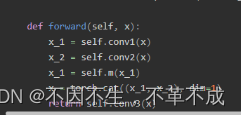
图 3 CSPLayer结构与源码
优点4:主干倒数第二层为SPPbottleneck(空间金字塔池化)
这里的SPPneck主要通过不同大小的池化核,对图像进行池化,增大网络感受野,提取更多的特征。

图 4 空间金字塔池化公式
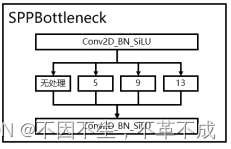
图 5 SPPneck(空间金字塔池化)
总而言之,主干网络卷积层的主要作用是特征提取与特征融合,相比于之前的YOLO版本,更换激活函数带来了一些非线性能力的提升。在主干网络中加入SPPneck增大了网络感受野。
优点5:特征利用层(FPN层)
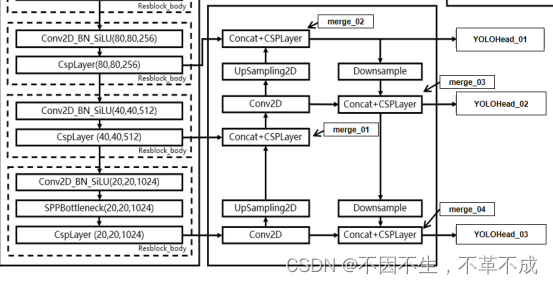
在特征利用部分,YoloX提取多特征层进行目标检测,一共提取三个特征层。
三个特征层位于主干部分CSPdarknet的不同位置,分别位于中间层,中下层,底层,当输入为(640,640,3)的时候,三个特征层的shape分别为feat1=(80,80,256)、feat2=(40,40,512)、feat3=(20,20,1024)。
第一条的路径:主干卷积(20,20,1024)特征图上采样,与主干卷积(40,40,512)特征图进行concat和卷积下采样,融合信息与进一步特征提取得到merge_01。
第二条路径:merge_01通过1×1卷积降通道上采样与主干(80,80,256)concat和卷积下采样得到(80,80,256)大小的merge_02输出到YOLOHead_01(个人理解该层的特征偏向(80,80)的特征图)
第三条路径:merge02下采样与merge01进行concat与卷积下采样操作得到(40,40,512)的(40,40,512)大小的merge_03输出到YOLOHead_02(个人理解该层的特征偏向(40,40)的特征图)
第四条路径:merge_03下采样与主干卷积到(20,20,1024)的特征图进行concat与卷积下采样操作,得到(20,20,1024)的merge_04输出到YOLOHead_03(个人理解该层的特征偏向(20,20)的特征图)
总结:FPN层对3个维度的特征图进行了融合,但是每个输出都有一定的侧重,为了对不同尺度的目标有更好的检测效果。
优点6:YOLOHead(解耦头)
YOLOV3中最后的回归框与置信度在1*1的卷积中一起实现,而在YOLOX通过解耦头,分别将置信度与回归框分别实现,在预测时合为一体。
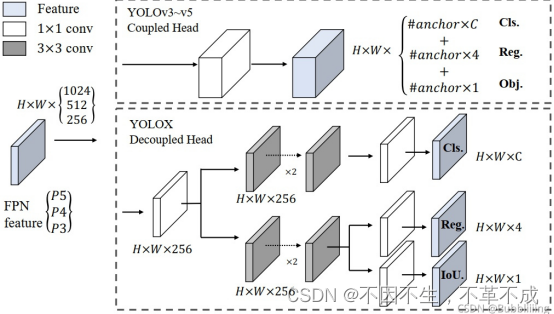
- Reg(h,w,4)用于判断每一个特征点的回归参数,回归参数调整后可以获得预测框。
- Obj(h,w,1)用于判断每一个特征点是否包含物体。
- Cls(h,w,num_classes)用于判断每一个特征点所包含的物体种类。
- 通道数即为需要预测的个数,每个通道代表一个结果。

将三个预测结果进行堆叠,每个特征层获得的结果为:
Out(h,w,4+1+num_classses)前四个参数用于判断每一个特征点的回归参数,回归参数调整后可以获得预测框;第五个参数用于判断每一个特征点是否包含物体;最后num_classes个参数用于判断每一个特征点所包含的物体种类。
将检测头解耦相对于YOLOV3检测头直接融合out输出而言,无疑会增加运算的复杂度,但是作者最终使用 1个1×1 的卷积先进行降维,并在分类和回归分支里各使用了 2个3×3 卷积,最终调整到仅仅增加一点点参数。解耦操作从逻辑上,对一个任务的精度而言有着绝对优势,缺点是在于增加运算的复杂程度。如何平衡性能与速度则是解耦方法是否优秀的关键。
优点7:网格点操作与解码操作
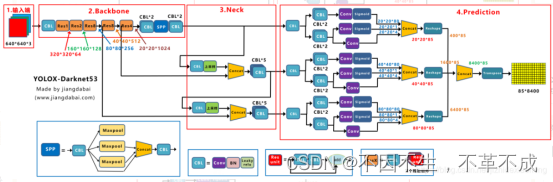
解码目标:由yolox中的decoupled_head输出后concat的形状为((numcls+5)*8400)的网格点图。
经过concat与维度转换的网格点,每一行都是代表着一个预测框信息的(numcls、中心点与宽高、判断该预测点是否有物体的obj)的anchorpoint
解码主要解码中心点坐标,以及宽高(x,y,h,w)。
解码中心点坐标是通过torch.meshgrid生成网格数据为网格点的行列索引,将中心点的偏移量x,y加上索引号再乘上缩放倍数。即可解码还原到原图。具体操作为:outputs[…, :2] = (outputs[…, :2] + grids) * strides
解码宽高w,h则是通过output输出宽高部分直接乘以步长再求对数获得。具体操作为:
outputs[…, 2:4] = torch.exp(outputs[…, 2:4]) * strides
优点8:SimOTA(动态样本匹配)
SimOTA主要的作用是为每个正样本(网络输出预测框)分配一个GT框,让正样本去拟合该GT框。从而替代之前的anchor方案去拟合anchor,从而实现anchor free
一、通过中心先验(GT框)确定fixed center area的范围fixed center area中的anchorpoint即为初筛正样本。
- 首先将3个维度特征图合成的网格点中的所有anchorpoint进行反算到原图(得到一堆框)。
- 再将这些框的中心点与GT框相对原图的坐标。可以得到在GT框内的anchorpoint的序号。
- 此时每个gt的中心点向外扩展2.5*expanded_strides距离得到fixed center area,与anchor进行比较,再找到在fixed center area内的anchorpoint即得到初筛的正样本。这里通过一个mask的方式将GT框内部的anchorpoint保留置为true其余为false。以方便下一步骤的计算。
二、将所mask内的anchorpoint都与对应的GT框进行cost代价矩阵计算。同时计算iou,获得dynamic_k(Cost代价矩阵由:cls_loss和rge_loss组成:cij=Lijcls+λLijreg+100000*~is_in_boxes_and_center。)
- 首先取出每个GT框对应的前10个iou值,将这些iou值加在一起求和取整。则获得了该GT框的dynamic_k。这个值的作用是动态的为每个GT框分配多少个anchorpoint。在训练初期可能dynamic_k为1(由于训练初期iou较小)
- 根据dynamic_k动态给GT框分配anchorpoint个数。取出前dynamic_k个cost值最低的anchorpoint进行下一步操作。另外在计算这些cost时不在中心区域(fixed center area)里的anchorpoint会被乘上一个十万的系数提高cost值。
- 如果出现一个anchorpoint分配给了两个GT框,就会对该anchorpoint的两个GT框cost值进行比较,anchorpoint会被分配给cost更低的框。
- 把去重后每个GT框取到的anchorpoint做对应的损失计算。
优点9:损失计算
1.Reg部分,利用真实框和预测框计算IOU损失,作为Reg部分的Loss组成。
2.Obj部分,所有真实框对应的特征点都是正样本,剩余的特征点均为负样本,根据正负样本和特征点的是否包含物体的预测结果计算交叉熵损失,作为Obj部分的Loss组成。
3.Cls部分,计算交叉熵损失,作为Cls部分的Loss组成。
4.损失公式如下:
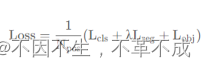
其中Lcls代表分类损失;
Lreg代表定位损失;
Lobj代表obj损失;
λ代表定位损失的平衡系数源码中设置是5.0;
Npos代表被分为正样的Anchor Point数;
感谢对本文有所帮助的人们!!
睿智的目标检测53——Pytorch搭建YoloX目标检测平台_Bubbliiiing的博客-CSDN博客
YOLOX之函数dynamic_k_matching解析 – 知乎 dynamic_k_match源码解析
yolox Head-Decoupled head源码解读_Mr.Q的博客-CSDN博客_yolox的head部分 yolo_head.py源码解析
文章出处登录后可见!