前言

几乎每个人都在使用银行卡,今天我们就来爬取某行外汇牌价,获取我们想要的数据。
环境使用
- python 3.9
- pycharm
模块使用
- requests
模块介绍
- requests
requests是一个很实用的Python HTTP客户端库,爬虫和测试服务器响应数据时经常会用到,requests是Python语言的第三方的库,专门用于发送HTTP请求,使用起来比urllib简洁很多。
- parsel
parsel是一个python的第三方库,相当于css选择器+xpath+re。
parsel由scrapy团队开发,是将scrapy中的parsel独立抽取出来的,可以轻松解析html,xml内容,获取需要的数据。
相比于BeautifulSoup,xpath,parsel效率更高,使用更简单。
- re
re模块是python独有的匹配字符串的模块,该模块中提供的很多功能是基于正则表达式实现的,而正则表达式是对字符串进行模糊匹配,提取自己需要的字符串部分,他对所有的语言都通用。
- os
os 就是 “operating system” 的缩写,顾名思义,os模块提供的就是各种 Python 程序与操作系统进行交互的接口。通过使用 os 模块,一方面可以方便地与操作系统进行交互,另一方面也可以极大增强代码的可移植性。
- csv
它是一种文件格式,一般也被叫做逗号分隔值文件,可以使用 Excel 软件或者文本文档打开 。其中数据字段用半角逗号间隔(也可以使用其它字符),使用 Excel 打开时,逗号会被转换为分隔符。csv 文件是以纯文本形式存储了表格数据,并且在兼容各个操作系统。
模块安装问题:
- 如果安装python第三方模块:
win + R 输入 cmd 点击确定, 输入安装命令 pip install 模块名 (pip install requests) 回车
在pycharm中点击Terminal(终端) 输入安装命令
- 安装失败原因:
- 失败一: pip 不是内部命令
解决方法: 设置环境变量
- 失败二: 出现大量报红 (read time out)
解决方法: 因为是网络链接超时, 需要切换镜像源
清华:https://pypi.tuna.tsinghua.edu.cn/simple 阿里云:https://mirrors.aliyun.com/pypi/simple/ 中国科技大学 https://pypi.mirrors.ustc.edu.cn/simple/ 华中理工大学:https://pypi.hustunique.com/ 山东理工大学:https://pypi.sdutlinux.org/ 豆瓣:https://pypi.douban.com/simple/ 例如:pip3 install -i https://pypi.doubanio.com/simple/ 模块名
失败三: cmd里面显示已经安装过了, 或者安装成功了, 但是在pycharm里面还是无法导入解决方法: 可能安装了多个python版本 (anaconda 或者 python 安装一个即可) 卸载一个就好,或者你pycharm里面python解释器没有设置好。
代码实现
首先,我们不管爬取什么网站,我们第一步就是要做的是,确认数据来源。知道我们要请求的网站是什么。就本文来说,我们确定请求的网站如下:
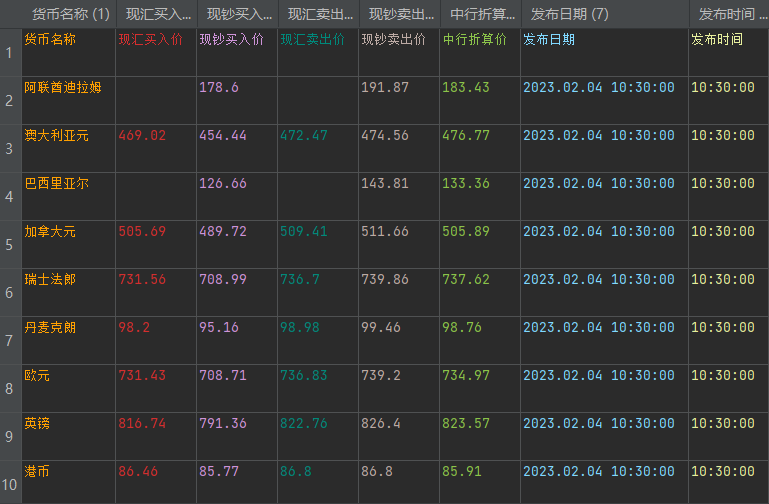
我们想把['货币名称', '现汇买入价', '现钞买入价', '现汇卖出价', '现钞卖出价', '中行折算价', '发布日期', '发布时间']的数据获取下来,有的人说我复制粘贴,这岂不是太麻烦,既然学了python,为什么不用python获取呢。
接下来,我们开始分析数据,我们可以发现这是一个静态的网页。那么就更容易了,没有什么异步加载之类的。我们通过分析网页发现,我们可以使用xpath或者css定位数据。今天呢,主要用css的方法获取我们想要的数据。
首先,我们和爬其他网页一样,都是先发送请求,然后获取响应。本文也不例外。
res = requests.get(url, headers=headers)
res.encoding = res.apparent_encoding
# print(res.text)
selector = parsel.Selector(res.text)我们会发现数据就在tr标签里面,接下来,我们的目标就是获取tr标签。
我们发现数据的标题和数据不在一个标签下,所以,我们先获取标题。代码如下:
titles = selector.css('div table tr th::text').getall()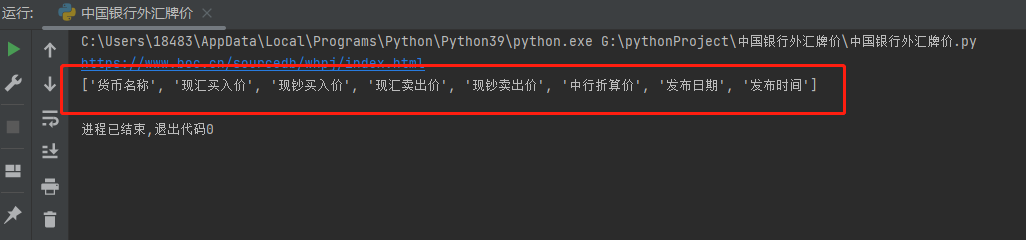
接下来,我们就可以获取我们的数据了,我们会发现,这是一个列表,所以我们要for循环遍历它。以获取货币名称为例,简单介绍一下,如何获取到我们想要的数据。
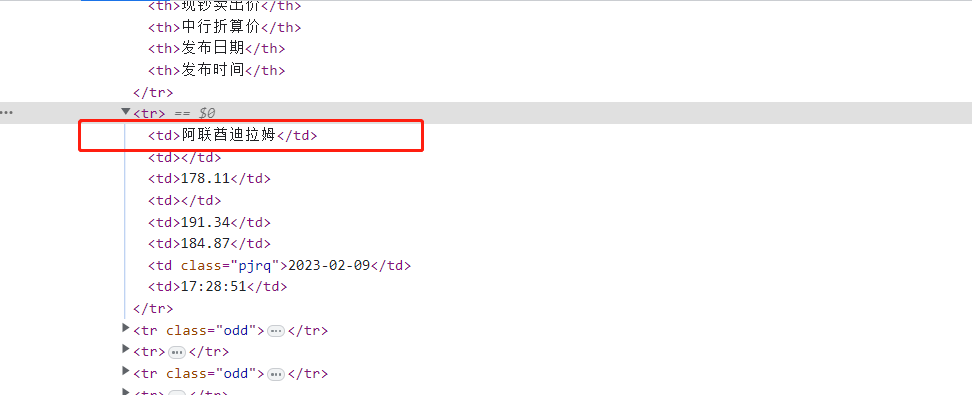
我们可以直观的看到,它在第一个,那么我们的代码如何实现呢。
theNameOfTheCurrency = info_list.css('td:nth-child(1)::text').get()
后面的代码就不解释,直接上代码。
spotPrice = info_list.css('td:nth-child(2)::text').get()
buyingRateForNotes = info_list.css('td:nth-child(3)::text').get()
theSpotSellingRate = info_list.css('td:nth-child(4)::text').get()
cashSellingRate = info_list.css('td:nth-child(5)::text').get()
theBankOfChinaReducedPrice = info_list.css('td:nth-child(6)::text').get()
theReleaseDate = info_list.css('td:nth-child(7)::text').get()
releaseTime = info_list.css('td:nth-child(8)::text').get()我们是要把这些数据保存到本地,也就是写入到csv。首先,就是写入到字典里面。
dit = {
'货币名称': theNameOfTheCurrency,
'现汇买入价': spotPrice,
'现钞买入价': buyingRateForNotes,
'现汇卖出价': theSpotSellingRate,
'现钞卖出价': cashSellingRate,
'中行折算价': theBankOfChinaReducedPrice,
'发布日期': theReleaseDate,
'发布时间': releaseTime,
}到这里,我们的代码就基本上结束了,我们想要的数据也就实现了,我们还差最后一步,代码如下:
csv_writer.writerow(dit)效果展示
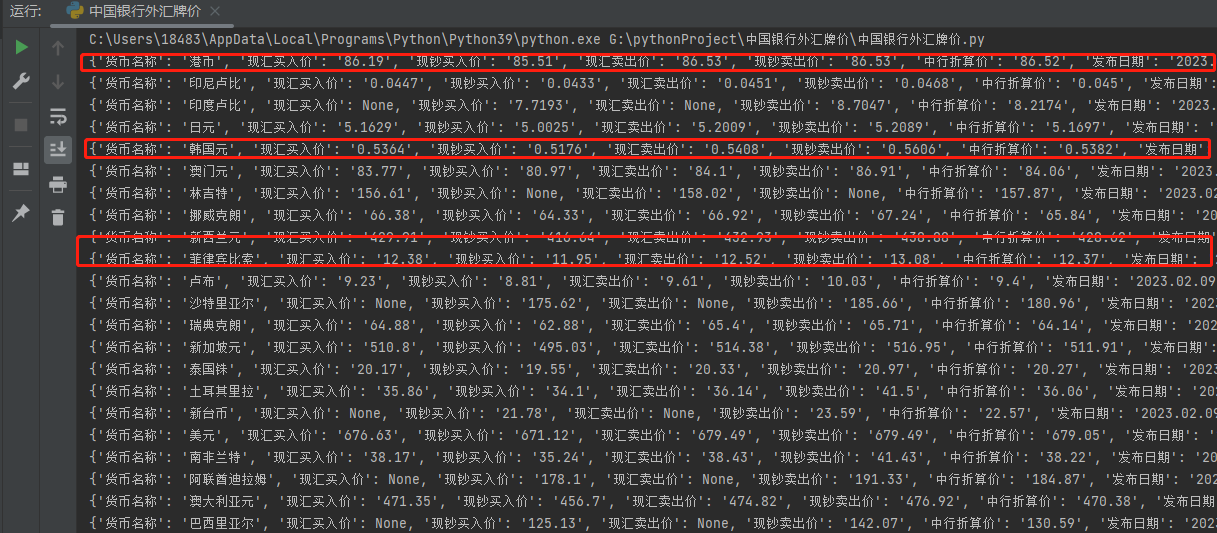
我们可以看到,本地有一个csv文件,我们打开会惊奇的发现,我们居然得到了我们想要的数据。
喜欢的话,可以给我点个赞。

文章出处登录后可见!