本次案例将教大家免费爬取4k高清大图,即使你是爬虫新手,也可以食用本次文章实现你的免费下载梦,话不多说,先看效果
网站视图:
看到这些图片你是否怦然心动,跟着我一起看下去.
一.思路分析
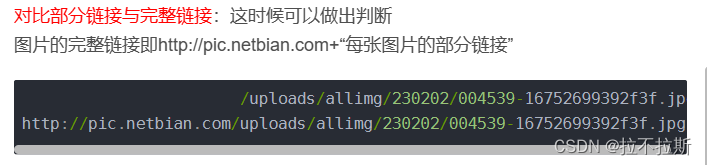
首先最基本的是获取每张图片的链接,然后下载;获取链接的方式:查看网页源代码,发现每张图片的部分url在源代码中,此时只需要找出缺失url然后拼接,即可获取图片的完整链接。
获取每张图片的链接后,进行遍历,获取原始图片名字作为图片保存名;将图片保存在指定目录,每下载一张图片,打印输出下载完成.
二.技术支撑
1.os创建指定文件夹
1.1判断文件夹是否存在
os.path.exists(path) # path是文件夹或者文件的相对路径或者绝对路径
1.2创建一级文件夹
创建一级文件是指,被创建文件夹的上级文件夹都存在。只创建最后一层文件夹,如果中间某一层文件夹不存在,将报错,可以先使用os.path.exists()判断.
os.mkdir(r'C:\Users\123\demo1\test1')
#只会创建test1文件夹,前提是前面的文件夹都存在,否则将会报错
1.2创建多级文件夹
os.makedirs(r'C:\Users\123\demo1\test1\test2')
2.lxml相关知识(可以在csdn搜索相关文章进行系统学习)
三.逐步分析及代码实现
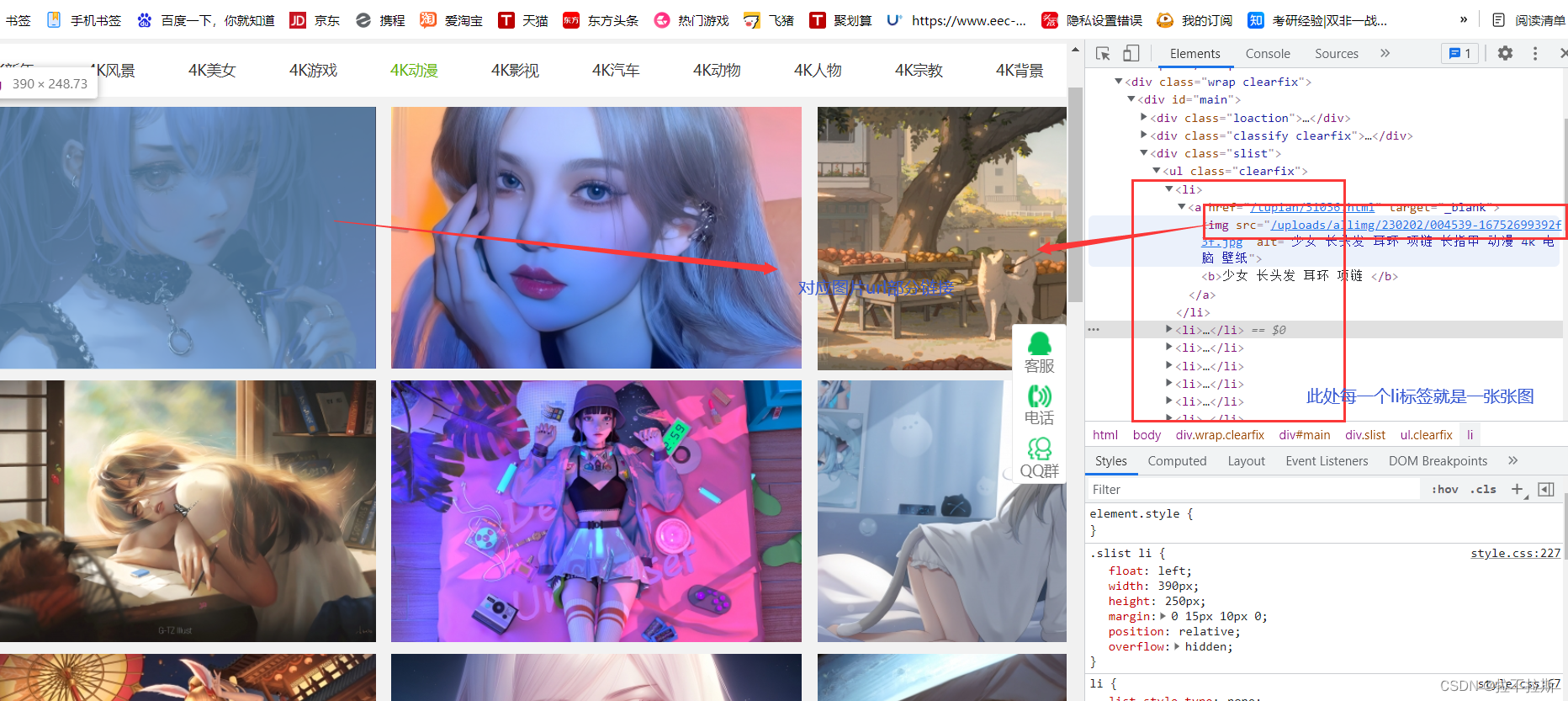
1.获取图片部分url链接
通过开发者工具,可以发现在网页源代码中有图片的部分链接但不完整
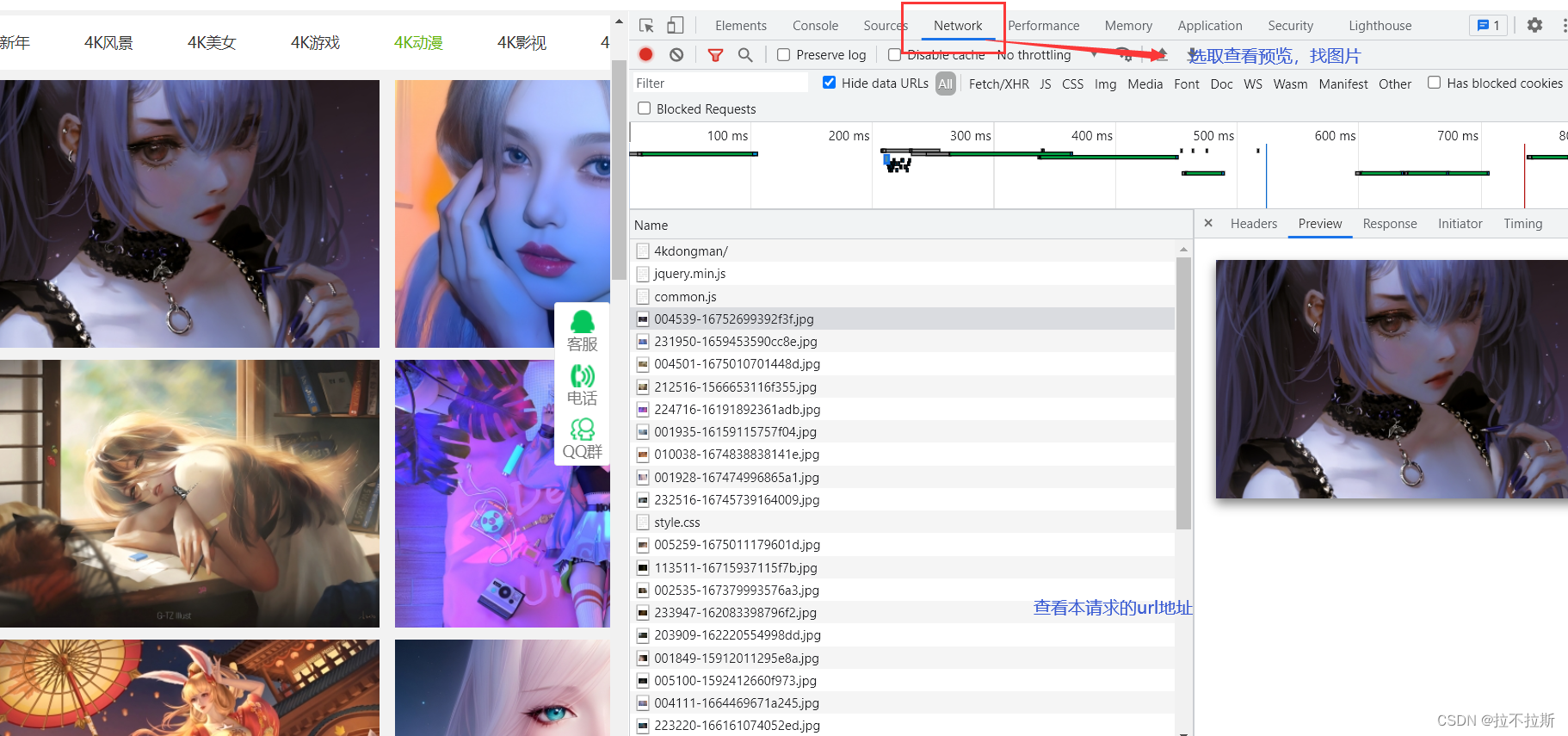
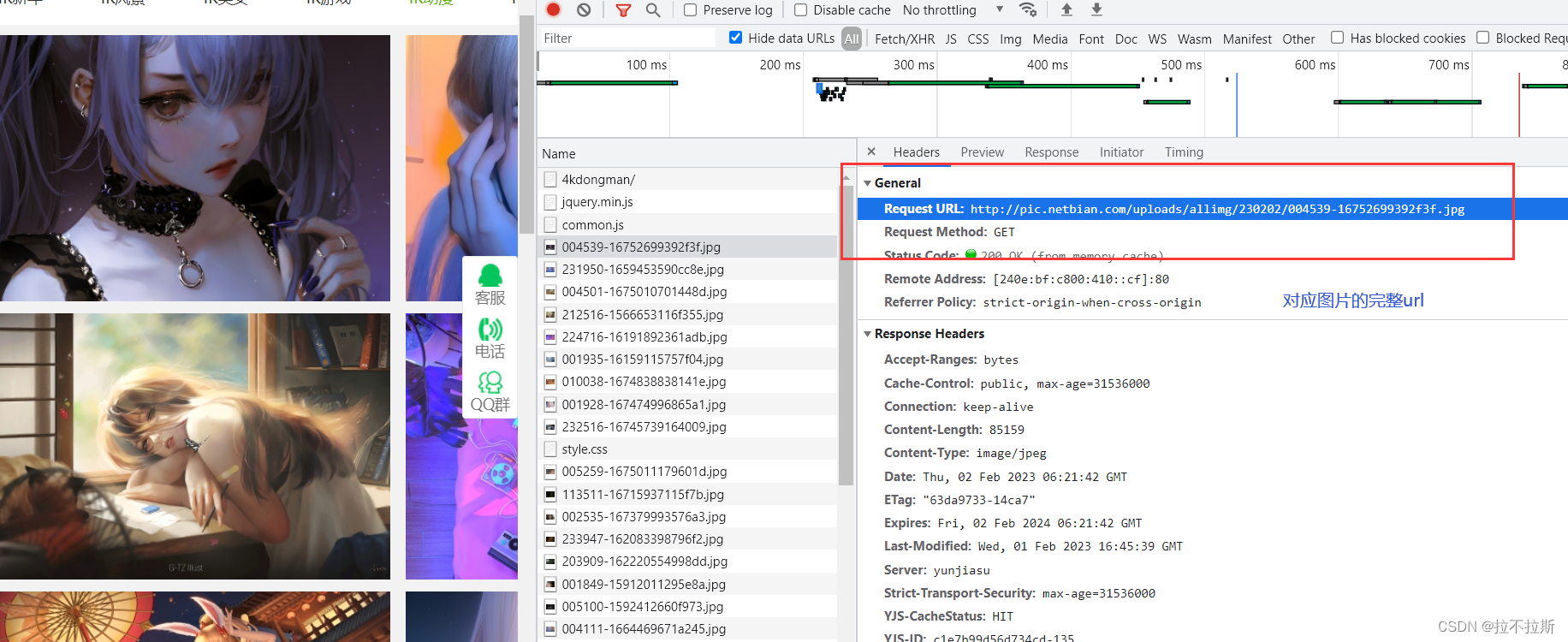
2.获取图片完整url链接
如何获取前半部分链接?这时候可以查看网络选项
3.代码实现
import requests
from lxml import etree
import os
url="http://pic.netbian.com/4kdongman/"
headers={
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.131 Safari/537.36 SLBrowser/8.0.0.3161 SLBChan/29"
}
response=requests.get(url=url,headers=headers)
response.encoding=response.apparent_encoding
text=response.text
tree=etree.HTML(text)
lis=tree.xpath('//div[@class="slist"]//li')
if not os.path.exists("./imgs1"):
os.mkdir("./imgs1")
for li in lis:
src="http://pic.netbian.com"+li.xpath('./a/img/@src')[0]
name=li.xpath('./a/img/@alt')[0]+".jpg"
img_path="imgs1/"+name
img_data=requests.get(url=src,headers=headers).content
with open(img_path,"wb") as fp:
fp.write(img_data)
print("下载完成")
文章出处登录后可见!
已经登录?立即刷新