本笔记是总结了B站DR_CAN的卡尔曼滤波器的课程,他的B站主页为:DR_CAN的个人空间_哔哩哔哩_bilibili
PS:虽然我不是学自控的,但是老师真的讲的很好!
目录
Lesson1 递归算法




Lesson2 数学基础_数据融合_协方差矩阵_状态空间方程




Lesson3 卡尔曼增益的详细推导






Lesson4 误差的协方差矩阵Pe的数学推导



Lesson5 直观理解卡尔曼滤波以及一个实例




下面具体看一下,之前反复提到过:如果模型计算误差Wk小,最终的估计值就更偏向计算值;
如果测量误差Vk小,最终的估计值就更偏向于测量值。
而在这个示例中,Wk/Vk的偏差是以其协方差矩阵来反映的(主对角线是方差)。
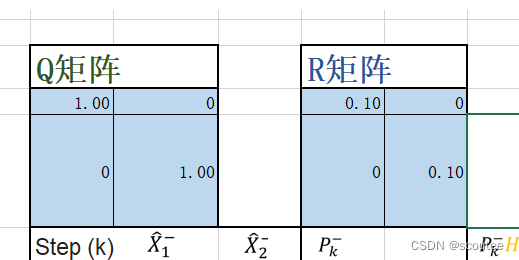
当计算误差Wk大于测量误差Vk时
Wk的协方差矩阵为Q,Vk的协方差矩阵为R:
结果图:
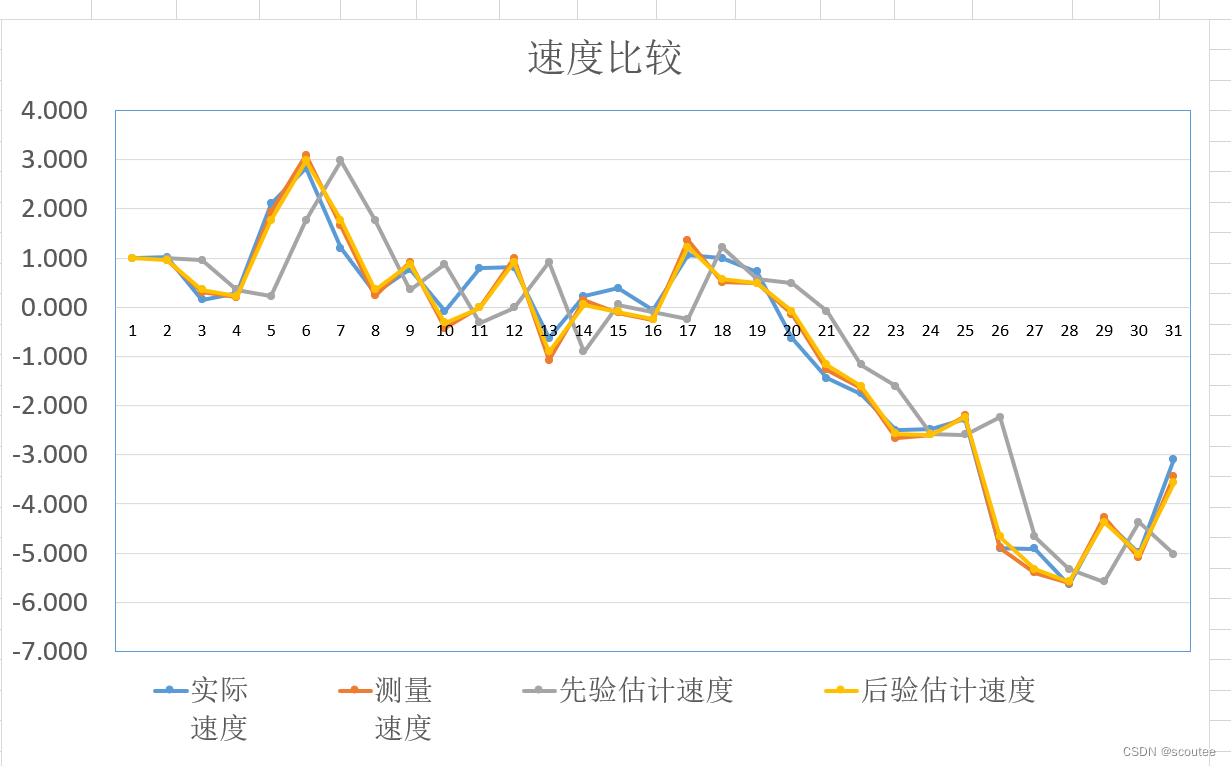
结果分析:
真实的实际速度是蓝色曲线,最终的估计速度即为后验估计速度,是黄色曲线。对比它们之间的偏差能够看出估计值与实际值之间的误差,从而判断算法的准确度。
在最优化方法中我们知道:最优估计有不同的准则,比如:最小二乘估计、最小方差估计、极大后验估计等等。具体内容不赘述。
我们要知道,如果没有不确定性(即Wk和Vk),那么估计值就是实际值(精准估计)。
卡尔曼滤波中采用的就是使得误差的方差最小为最优估计准则:因为如果后验估计值和真实值越接近,那么误差ek的变化就很小,即误差ek的方差很小。
进一步推导,考虑到误差ek会有很多不同的分量(因为状态量不同,比如说此例子中就是有状态量X1表示位置,状态量X2表示速度,那么它们就分别有误差e1和e2)。要使得总误差方差最小,那么误差各个分量的方差之和加起来就要最小。而“误差各分量的方差之和”正好是误差的协方差矩阵的主对角线之和——迹。
故此我们引入了Wk的协方差矩阵为Q,Vk的协方差矩阵为R。然后其方差越大时,说明误差越大,即越不可以相信。所以此处计算误差较大,可以看到先验估计速度(灰色)偏离实际速度(蓝色)的程度要大于测量速度(红色)偏离实际速度(蓝色的程度)。
所以最后的估计值——后验估计速度(黄色)曲线也是更为接近测量速度(红色)曲线。
一种通俗的理解方式就是:建模计算值和测量值都是不准确的,两者的不准确程度分别以计算误差的方差和测量误差的方差来衡量,方差越大越不可以相信。在两个不准确的值的基础上尽量准确估计,就是谁方差越小,越相信谁,越靠近谁。
当计算误差Wk小于测量误差Vk时
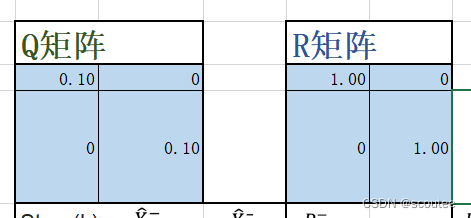
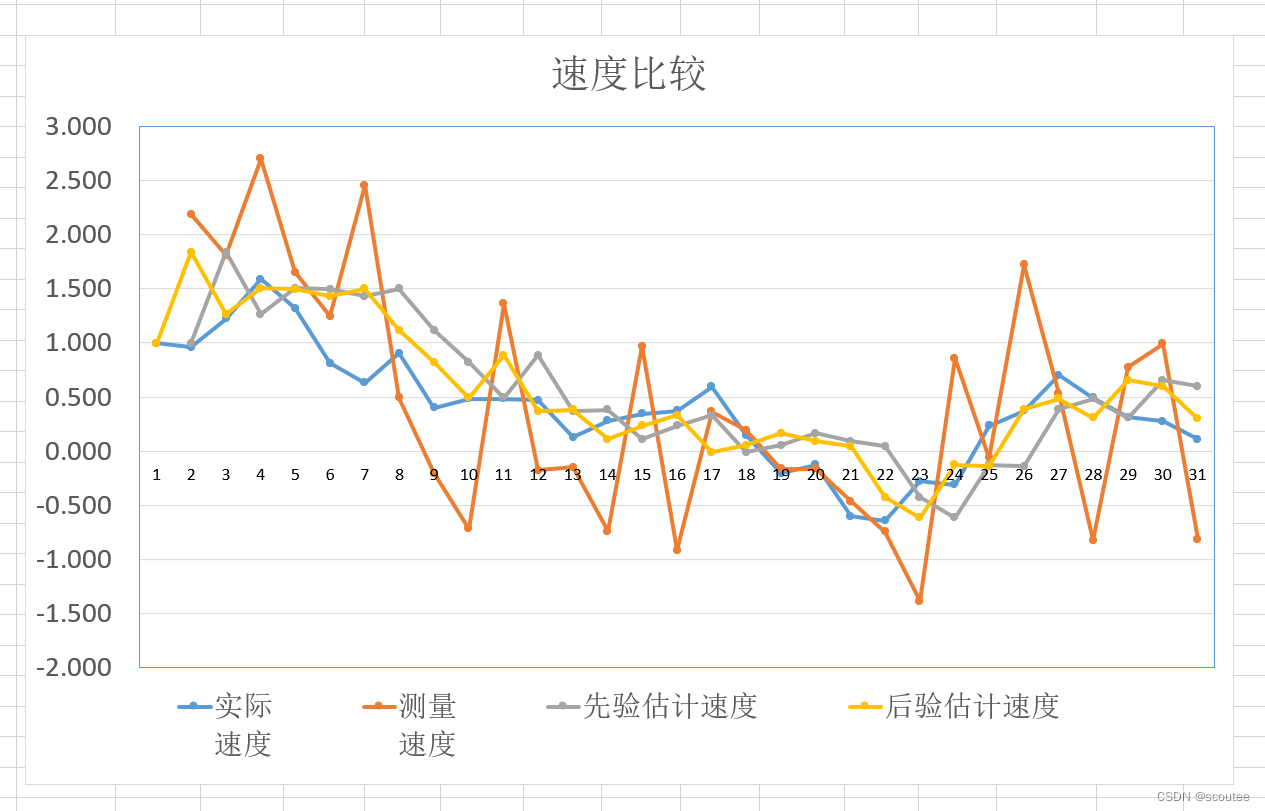
结果分析:
由于此时测量误差的方差较大,导致测量值很不可信,其变化的程度可以看到也很离谱。但是由于后验估计值(黄色)更为依赖模型计算值(灰色),所以后验估计值也没离实际值(蓝色)太远。
而这,正是卡尔曼滤波的作用:在不准确之中得到最准确的估计值。
本例的python代码
源代码来源:B站用户东爱北的GitHubhttps://github.com/liuchangji/2D-Kalman-Filter-Example_Dr_CAN_in_python
我对其中的源码做了注释,以及对一个小错误进行了修改(产生符合高斯分布的变量时,scale输入的应该是标准差,而协方差矩阵里面主对角线上面是方差,所以要开根号,要注意开完根号要保证其类型仍为np.float)
import numpy as np
import math
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif']=['SimHei'] #用来正常显示中文标签
plt.rcParams['axes.unicode_minus']=False #用来正常显示负号
#定义一个产生符合高斯分布的函数,均值为loc=0.0,标准差为scale=sigma,输出的大小为size
def gaussian_distribution_generator(sigma):
return np.random.normal(loc=0.0,scale=sigma,size=None)
# 状态转移矩阵,上一时刻的状态转移到当前时刻
A = np.array([[1,1],[0,1]])
# 过程噪声w协方差矩阵Q,P(w)~N(0,Q),噪声来自真实世界中的不确定性
Q = np.array([[0.01,0],[0,0.01]])
# 测量噪声协方差矩阵R,P(v)~N(0,R),噪声来自测量过程的误差
R = np.array([[1,0],[0,1]])
# 传输矩阵/状态观测矩阵H
H = np.array([[1,0],[0,1]])
# 控制输入矩阵B
B = None
# 初始位置和速度
X0 = np.array([[0],[1]])
# 状态估计协方差矩阵P初始化
P =np.array([[1,0],[0,1]])
if __name__ == "__main__":
#---------------------初始化-----------------------------
#真实值初始化 这里还要再写一遍np.array是保证它的类型是数组array
X_true = np.array(X0)
#后验估计值Xk的初始化
X_posterior = np.array(X0)
#第k次误差的协方差矩阵的初始化
P_posterior = np.array(P)
#创建状态变量的真实值的矩阵 状态变量1:速度 状态变量2:位置
speed_true = []
position_true = []
#创建测量值矩阵
speed_measure = []
position_measure = []
#创建状态变量的先验估计值
speed_prior_est = []
position_prior_est = []
#创建状态变量的后验估计值
speed_posterior_est = []
position_posterior_est = []
#---------------------循环迭代-----------------------------
#设置迭代次数为30次
for i in range(30):
#--------------------建模真实值-----------------------------
# 生成过程噪声w w=[w1,w2].T(列向量)
# Q[0,0]是过程噪声w的协方差矩阵的第一行第一列,即w1的方差,Q[1,1]是协方差矩阵的第二行第二列,即为w2的方差
# python的np.random.normal(loc,scale,size)函数中scale输入的是标准差,所以要开方
Q_sigma = np.array([[math.sqrt(Q[0,0]),Q[0,1]],[Q[1,0],math.sqrt(Q[1,1])]])
w = np.array([[gaussian_distribution_generator(Q_sigma[0, 0])],
[gaussian_distribution_generator(Q_sigma[1, 1])]])
# print('00',Q[0,0],'它的类型是',type(Q[0,0]))
# print('开根号的00', Q_sigma[0, 0], '它的类型是', type(Q_sigma[0, 0]))
# print('00的平方根',math.sqrt(Q[0,0]),"它的类型是",type(math.sqrt(Q[0,0])))
# print('w[',i,']=',w)
# 真实值X_true 得到当前时刻的状态;之前我一直在想它怎么完成从Xk-1到Xk的更新,实际上在代码里面直接做迭代就行了,这里是不涉及数组下标的!!!
#dot函数用于矩阵乘法,对于二维数组,它计算的是矩阵乘积
X_true = np.dot(A, X_true) + w
# 速度的真实值是speed_true 使用append函数可以把每一次循环中产生的拼接在一起,形成一个新的数组speed_true
speed_true.append(X_true[1,0])
position_true.append(X_true[0,0])
#print(speed_true)
# --------------------生成观测值-----------------------------
# 生成过程噪声
R_sigma = np.array([[math.sqrt(R[0,0]),R[0,1]],[R[1,0],math.sqrt(R[1,1])]])
v = np.array([[gaussian_distribution_generator(R_sigma[0,0])],[gaussian_distribution_generator(R_sigma[1,1])]])
# 生成观测值Z_measure 取H为单位阵
Z_measure = np.dot(H, X_true) + v
speed_measure.append(Z_measure[1,0]),
position_measure.append(Z_measure[0,0])
# --------------------进行先验估计-----------------------------
# 开始时间更新
# step1:基于k-1时刻的后验估计值X_posterior建模预测k时刻的系统状态先验估计值X_prior
# 此时模型控制输入U=0
X_prior = np.dot(A, X_posterior)
# 把k时刻先验预测值赋给两个状态分量的先验预测值 speed_prior_est = X_prior[1,0];position_prior_est=X_prior[0,0]
# 再利用append函数把每次循环迭代后的分量值拼接成一个完整的数组
speed_prior_est.append(X_prior[1,0])
position_prior_est.append(X_prior[0,0])
# step2:基于k-1时刻的误差ek-1的协方差矩阵P_posterior和过程噪声w的协方差矩阵Q 预测k时刻的误差的协方差矩阵的先验估计值 P_prior
P_prior_1 = np.dot(A, P_posterior)
P_prior = np.dot(P_prior_1, A.T) + Q
# --------------------进行状态更新-----------------------------
# step3:计算k时刻的卡尔曼增益K
k1 = np.dot(P_prior, H.T)
k2 = np.dot(H, k1) + R
#k3 = np.dot(np.dot(H, P_prior), H.T) + R k2和k3是两种写法,都可以
K = np.dot(k1, np.linalg.inv(k2))
# step4:利用卡尔曼增益K 进行校正更新状态,得到k时刻的后验状态估计值 X_posterior
X_posterior_1 = Z_measure -np.dot(H, X_prior)
X_posterior = X_prior + np.dot(K, X_posterior_1)
# 把k时刻后验预测值赋给两个状态分量的后验预测值 speed_posterior_est = X_posterior[1,0];position_posterior_est = X_posterior[0,0]
speed_posterior_est.append(X_posterior[1,0])
position_posterior_est.append(X_posterior[0,0])
# step5:更新k时刻的误差的协方差矩阵 为估计k+1时刻的最优值做准备
P_posterior_1 = np.eye(2) - np.dot(K, H)
P_posterior = np.dot(P_posterior_1, P_prior)
# ---------------------再从step5回到step1 其实全程只要搞清先验后验 k的自增是隐藏在循环的过程中的 然后用分量speed和position的append去记录每一次循环的结果-----------------------------
# 可视化显示 画出速度比较和位置比较
if True:
# 画出1行2列的多子图
fig, axs = plt.subplots(1,2)
#速度
axs[0].plot(speed_true,"-",color="blue",label="速度真实值",linewidth="1")
axs[0].plot(speed_measure,"-",color="grey",label="速度测量值",linewidth="1")
axs[0].plot(speed_prior_est,"-",color="green",label="速度先验估计值",linewidth="1")
axs[0].plot(speed_posterior_est,"-",color="red",label="速度后验估计值",linewidth="1")
axs[0].set_title("speed")
axs[0].set_xlabel('k')
axs[0].legend(loc = 'upper left')
#位置
axs[1].plot(position_true,"-",color="blue",label="位置真实值",linewidth="1")
axs[1].plot(position_measure,"-",color="grey",label="位置测量值",linewidth="1")
axs[1].plot(position_prior_est,"-",color="green",label="位置先验估计值",linewidth="1")
axs[1].plot(position_posterior_est,"-",color="red",label="位置后验估计值",linewidth="1")
axs[1].set_title("position")
axs[1].set_xlabel('k')
axs[1].legend(loc = 'upper left')
# 调整每个子图之间的距离
plt.tight_layout()
plt.figure(figsize=(60, 40))
plt.show()结果图1(迭代30次):

图2(迭代60次):
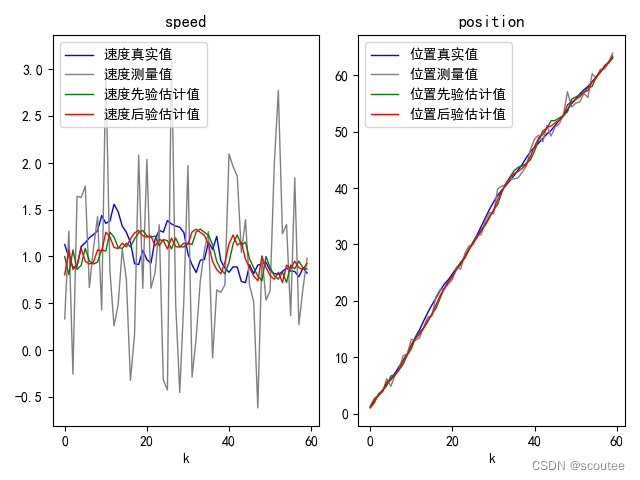
图1结果分析:
本次实例中,取了过程噪声的协方差矩阵为Q=[0.01,0;0,0.01],即过程噪声的方差为0.01。取了测量噪声的协方差矩阵为R=[1,0;0,1],即测量噪声的方差为1。根据最小方差估计准则,此时过程噪声方差小于测量噪声的误差,则先验估计值比测量值更可靠。
我们看图:
在速度的分析图中,明显看到速度测量值(灰色)偏离速度真实值(蓝色)的程度大于速度先验估计值(绿色)偏离速度真实值(蓝色)的程度,而经过卡尔曼滤波之后,后验估计值(红色)并没有非常偏离真实值(蓝色)。这就是因为此时卡尔曼滤波更为相信先验估计值。
位置分析同理。
突然想到一个问题:如何确定卡尔曼滤波要迭代多少次呢?
网上说不一定是迭代越多次越准确,由于采用最小方差估计准则,所以我想到了去看误差ek的协方差矩阵的迹,迹越小越好(误差分量的方差之和越小)。然后我又加了几行代码:
# 创建误差的协方差矩阵的迹
tr_P_posterior = []
# 误差的协方差矩阵的迹,迹越小说明估计越准确
# print('ek1的方差:',P_posterior[0,0],'ek2的方差',P_posterior[1,1])
tr_P_posterior.append(P_posterior[0,0]+P_posterior[1,1])
#误差的协方差的迹
axs[2].plot(tr_P_posterior,"-",color="blue",label="误差的迹",linewidth="1")
60次迭代的图:

可以看到,基本上在20次左右,误差的迹就已经收敛至min值了。
于是我把迭代次数调整成20次:
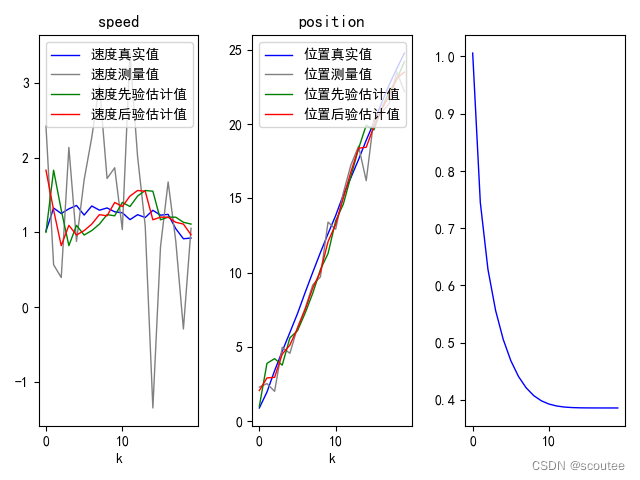
可以看到,大约在十几次的时候,误差的迹就收敛至极限值(约为0.38左右)
那么就是说,刚开始迭代时,卡尔曼滤波器的误差还是挺大的(方差之和大约为1) ,随着迭代的进行,滤波器误差逐步减少至最低点,此后的误差维持在这个点(误差无法完全消除,只存在最小误差),即预测精度达到最优值。
总结一下
1.算法迭代的五个步骤


2.算法的python代码实现
我自己从头开始写的时候最难受的点应该就是因为太久不碰后端,逻辑上会很卡,然后忘记了append函数的作用,搞得我一直在纠结怎么从k-1时刻更新到k时刻,在想是不是要对矩阵做下标的更新什么的,循环迭代这里卡了很久。还有就是对状态变量、先验估计量、后验估计量、协方差矩阵的先验估计量和后验估计量以及它们之间的关系、它们与时刻k、k-1之间的关系不熟。
其实在代码中,我们看一下这五个公式,对于当前时刻k:
step1中的(k-1)时刻的后验估计就是上一次step4估计得到的结果,它们是同一个变量X_posterior;
step2中的 Pk-1就是上一次step5计算得到的结果,它们是同一个变量P_posterior;
step3中的Pk先验,就是本次的step2计算得到的结果,它们是同一个变量P_prior;
step4中的Xk先验,就是本次的step1计算得到的结果,它们是同一个变量X_prior;
其次就是,我们要画图表示出速度、位置的迭代变化,就需要记录下每一次迭代产生的速度值和变量值,然后对它们进行可视化。
最后就是,如果你对先验、后验、时刻搞不清,用英文写清楚变量意思!!不要光贪图简洁!
文章出处登录后可见!