目录
一、Bert简介
BERT全称是Bidirectional Encoder Representations from Transformers,是google最新提出的NLP预训练方法,在大型文本语料库(如维基百科)上训练通用的“语言理解”模型,然后将该模型用于我们关心的下游NLP任务(如分类、阅读理解)。 BERT优于以前的方法,因为它是用于预训练NLP的第一个**无监督,深度双向**系统,从名字我们能看出该模型两个核心特质:依赖于Transformer以及双向,同时它也是木偶动画《芝麻街》里面的角色,它还有个兄弟EMLo。长右边这样:


关于Bert这个模型的神奇之处我就不在这里多说了,它直接颠覆了人们对Pretrained model的理解。尽管Bert模型有多得骇人听闻的参数,但是我们可以直接借助迁移学习的想法使用已经预训练好的模型参数,并根据自己的实际任务进行fine-tuning。复旦大学的一篇论文《How to Fine-Tune BERT for Text Classification》(下载地址:https://arxiv.org/pdf/1905.05583.pdf)给出了一些调节Bert参数的建议,作者针对文本分类任务的BERT微调方法,给出了微调模式的一般解决方案。最后,提出的解决方案在8个广泛研究的文本分类数据集上获取了最新的结果,具体实现步骤如下:
(1)进一步在开放域预训练BERT;
(2)采用多任务方式可选择性地微调BERT;
(3)在目标任务上微调BERT。同时研究了fine-tuning技术对Bert在长文本任务、隐藏层选择、隐藏层学习率、知识遗忘、少样本学习问题上的影响。
1. 微调策略:不同网络层包含不同的特征信息,哪一层更有助于目标任务?这是一个考虑的方向;
2. 进一步预训练:在目标域进一步得到预训练模型;
3. 多任务微调:多任务可以挖掘共享信息,同时对所有任务进行微调是否,使用多任务策略对结果有帮助。
1.1 Transformer模型
为了描述得更清楚,还是先把transformer的模型结构列在下面(来自论文《Attention Is All You Need》):
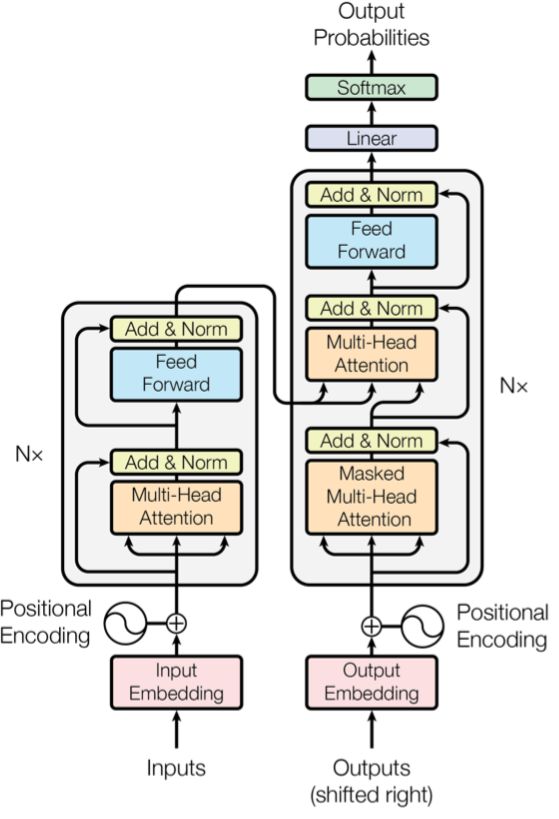
1.2 Bert模型
而Bert则是多个Transformer的双向叠加,中间每一个蓝色的圈圈都是一个transformer(来自论文《Pre-training of Deep Bidirectional Transformers for Language Understanding》)。
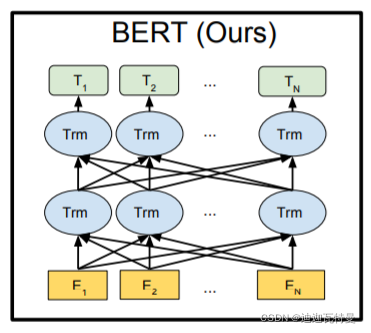
二、BERT的发展历程
2.1 One-Hot 编码
One-Hot编码,又称为一位有效编码,主要是采用N位状态寄存器来对N个状态进行编码,每个状态都由他独立的寄存器位,并且在任意时候只有一位有效。
One-Hot编码是分类变量作为二进制向量的表示。这首先要求将分类值映射到整数值。然后,每个整数值被表示为二进制向量,除了整数的索引标记为1之外,其他都是零值。
2.1.1 无法计算词相似度
例如One-Hot编码如下:
我们 = (0,1,0,0,0,0) 爬山 = (0,0,1,0,0,0)
运动 = (1,0,0,0,0,0) 昨天 = (0,0,0,1,0,0)
Euclidean distance(欧式距离)
d(我们,爬山)=√2
d(我们,运动)=√2
d(运动,爬山)=√2
d(运动,昨天)=√2
Cosine similarity(余弦相似度)sim(我们,爬山)=0
sim(我们,运动)=0
sim(运动,爬山)=0
sim(运动,昨天)=0
结论:One-hot 无法表达单词间的相似度
2.1.2 Sparsity(稀疏性)
向量大小大于等于词典大小
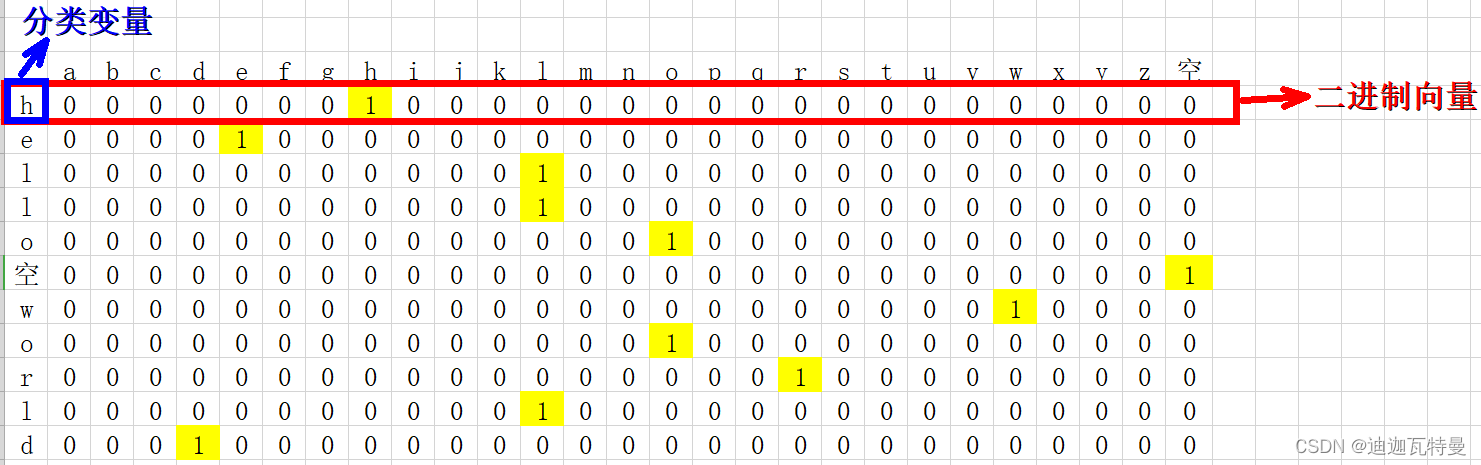
比如我们要对 “hello world” 进行one-hot编码,怎么做呢?
1.确定要编码的对象–hello world,
2.确定分类变量–h e l l o 空格 w o r l d,共27种类别(26个小写字母 + 空格,);
3.以上问题就相当于,有11个样本,每个样本有27个特征,将其转化为二进制向量表示,
这里有一个前提,特征排列的顺序不同,对应的二进制向量亦不同(比如我把空格放在第一列和a放第一列,one-hot编码结果肯定是不同的)
因此我们必须要事先约定特征排列的顺序:
1. 27种特征首先进行整数编码:a–0,b–1,c–2,……,z–25,空格–26
2. 27种特征按照整数编码的大小从前往后排列
得到的one-hot编码如下:
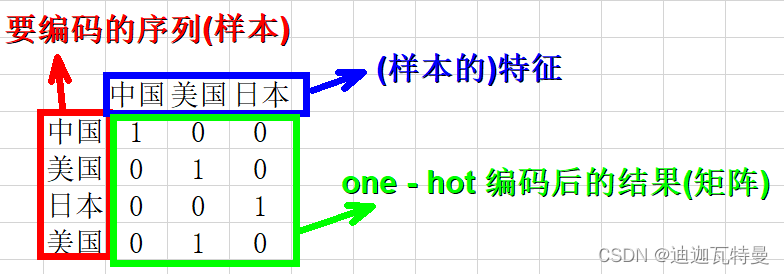
再比如:我们要对["中国", "美国", "日本"]进行one-hot编码,
怎么做呢?
1.确定要编码的对象–["中国", "美国", "日本", "美国"],
2.确定分类变量–中国 美国 日本,共3种类别;
3.以上问题就相当于,有3个样本,每个样本有3个特征,将其转化为二进制向量表示。
我们首先进行特征的整数编码:中国–0,美国–1,日本–2,并将特征按照从小到大排列
得到one-hot编码如下:
["中国", "美国", "日本", "美国"] —> [[1,0,0], [0,1,0], [0,0,1], [0,1,0]]
 2.2 Word2vec
2.2 Word2vec
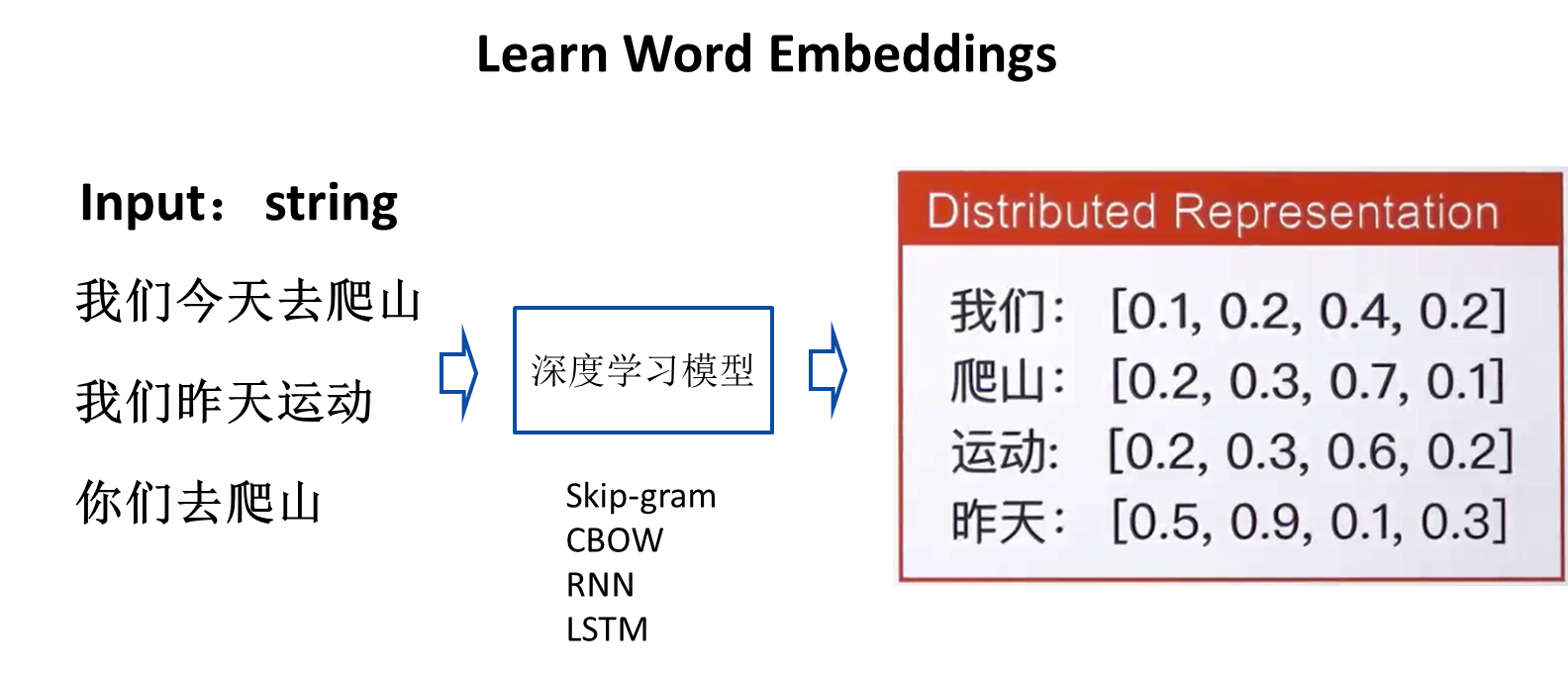
基于One-Hot编码存在的稀疏性和高维度性缺点,2013年,Google开源了一款用于词向量计算的工具——word2vec,引起了工业界和学术界的关注。首先,word2vec可以在百万数量级的词典和上亿的数据集上进行高效地训练;其次,该工具得到的训练结果——词向量(word embedding),可以很好地度量词与词之间的相似性。随着深度学习(Deep Learning)在自然语言处理中应用的普及,很多人误以为word2vec是一种深度学习算法。其实word2vec算法的背后是一个浅层神经网络。另外需要强调的一点是,word2vec是一个计算word vector的开源工具。当我们在说word2vec算法或模型的时候,其实指的是其背后用于计算word vector的CBoW模型和Skip-gram模型,下面我用图的方式直观描述word2vec的优越性。
From One-hot Respresentation to Distributed Respresentation

维度灾难、无法保留词序信息、语义鸿沟 词向量长度自定义(100、200、300)

2.3 BERT的诞生
BERT 的思想其实很大程度上来源于 CBOW 模型,如果从准确率上说改进的话,BERT 利用更深的模型,以及海量的语料,得到的 embedding 表示,来做下游任务时的准确率是要比 word2vec 高不少的。实际上,这也离不开模型的“加码”以及数据的“巨大加码”。再从方法的意义角度来说,BERT 的重要意义在于给大量的 NLP 任务提供了一个泛化能力很强的预训练模型,而仅仅使用 word2vec 产生的词向量表示,不仅能够完成的任务比 BERT 少了很多,而且很多时候直接利用 word2vec 产生的词向量表示给下游任务提供信息,下游任务的表现不一定会很好,甚至会比较差。
三、BERT 的训练过程
BERT的核心过程
1. 从句子中随机选取15%去除,作为模型预测目标,例如:
Input: the man went to the [MASK1] . he bought a [MASK2] of milk.
Labels: [MASK1] = store; [MASK2] = gallon
2. 为了学习句子之间的关系。会从数据集抽取两个句子,其中第二句是第一句的下一句的概率是 50%
Sentence A: the man went to the store .
Sentence B: he bought a gallon of milk .
Label: IsNextSentence
Sentence A: the man went to the store .
Sentence B: penguins are flightless .
Label: NotNextSentence
3.最后再将经过处理的句子传入大型 Transformer 模型,并通过两个损失函数同时学习上面两个目标就能完成训练。
在论文原文中,作者提出了两个预训练任务:Masked LM 和 Next Sentence Prediction,我们下面来做简单讲解。
3.1 Masked LM(Language Model)
Masked LM 的任务描述为:给定一句话,随机抹去这句话中的一个或几个词,要求根据剩余词汇预测被抹去的几个词分别是什么,如下图所示。
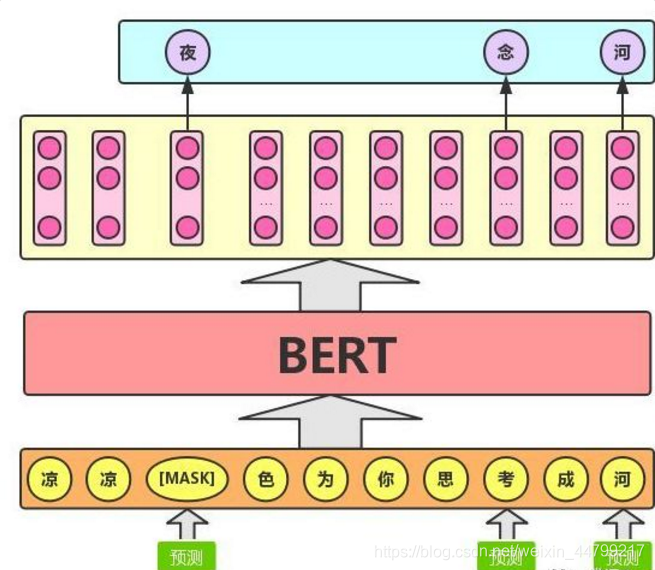
BERT 模型的这个预训练过程其实就是在模仿我们学语言的过程,思想来源于「完形填空」的任务。具体来说,文章作者在一句话中随机选择 15% 的词汇用于预测。对于在原句中被抹去的词汇, 80% 情况下采用一个特殊符号 [MASK] 替换, 10% 情况下采用一个任意词替换,剩余 10% 情况下保持原词汇不变。
80%的概率替换成[MASK],比如 my dog is hairy → my dog is [MASK]
10%的概率替换成随机的一个词,比如 my dog is hairy → my dog is apple
10%的概率替换成它本身,比如 my dog is hairy → my dog is hairy
这么做的主要原因是:在后续微调任务中语句中并不会出现 [MASK] 标记,而且这么做的另一个好处是:预测一个词汇时,模型并不知道输入对应位置的词汇是否为正确的词汇( 10% 概率),这就迫使模型更多地依赖于上下文信息去预测词汇,并且赋予了模型一定的纠错能力。上述提到了这样做的一个缺点,其实这样做还有另外一个缺点,就是每批次数据中只有 15% 的标记被预测,这意味着模型可能需要更多的预训练步骤来收敛。
3.2 Next Sentence Prediction
Next Sentence Prediction 的任务描述为:给定一篇文章中的两句话,判断第二句话在文本中是否紧跟在第一句话之后,如下图所示。
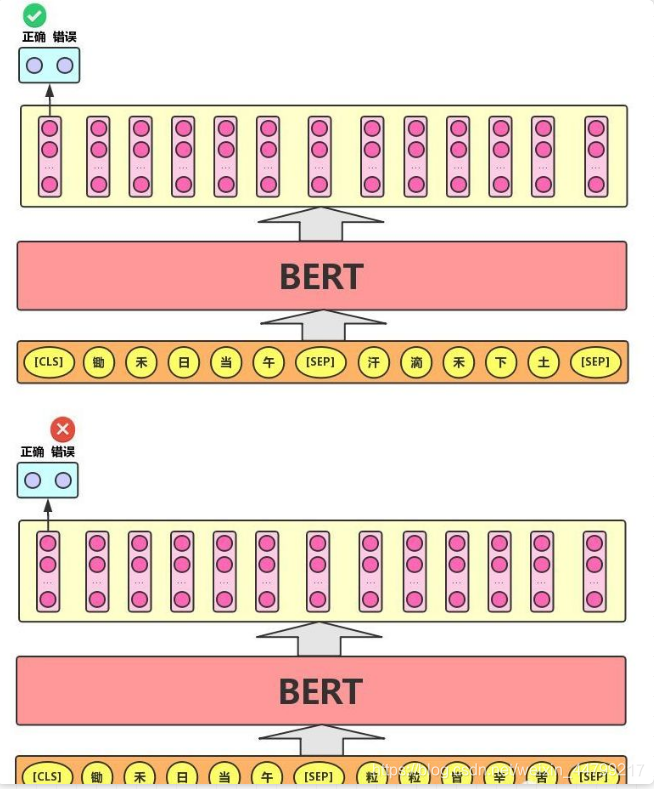
这个类似于「段落重排序」的任务,即:将一篇文章的各段打乱,让我们通过重新排序把原文还原出来,这其实需要我们对全文大意有充分、准确的理解。
Next Sentence Prediction 任务实际上就是段落重排序的简化版:只考虑两句话,判断是否是一篇文章中的前后句。在实际预训练过程中,文章作者从文本语料库中随机选择 50% 正确语句对和 50% 错误语句对进行训练,与 Masked LM 任务相结合,让模型能够更准确地刻画语句乃至篇章层面的语义信息。
BERT 模型通过对 Masked LM 任务和 Next Sentence Prediction 任务进行联合训练,使模型输出的每个字 / 词的向量表示都能尽可能全面、准确地刻画输入文本(单句或语句对)的整体信息,为后续的微调任务提供更好的模型参数初始值。
四、BERT的用途
尽管从直观上来看,Bert可能类似于Word2vec,返回单词们的稠密表示,但是根据不同的任务Bert可以有许多不同的用法。
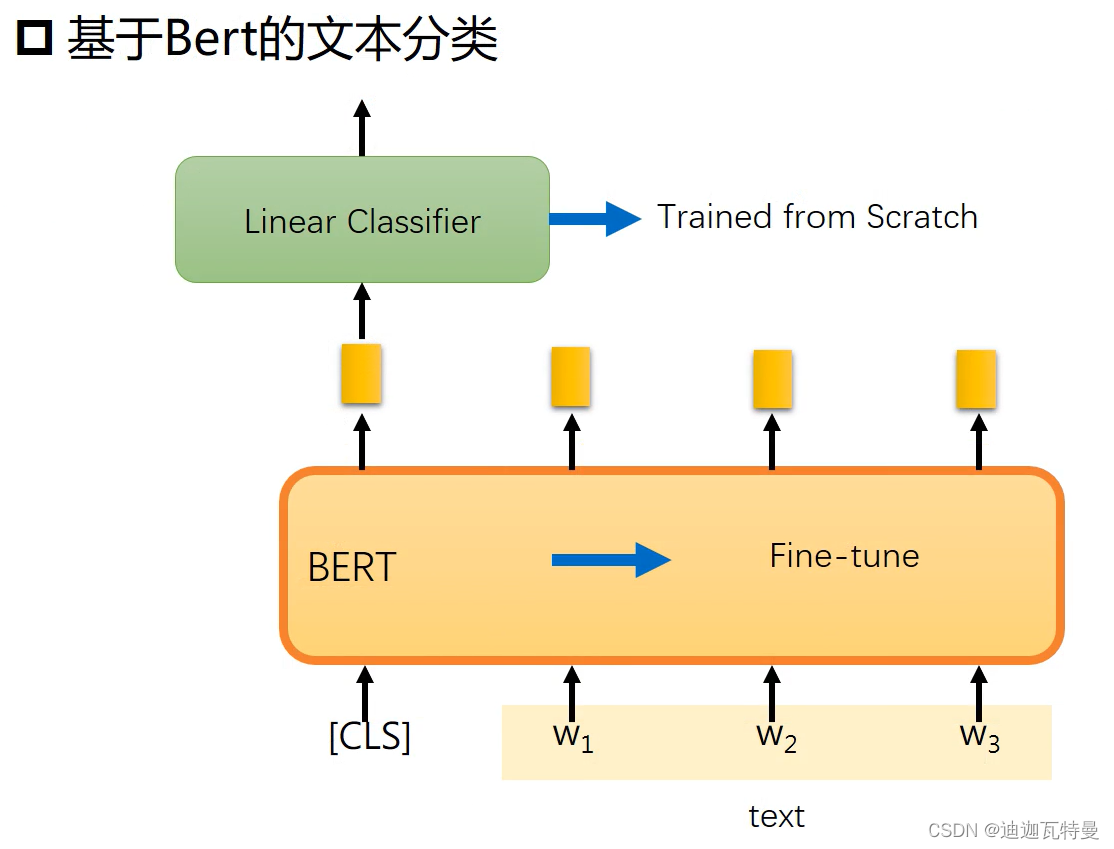
4.1 文本分类
尽管从直观上来看,Bert可能类似于Word2vec,返回单词们的稠密表示,但是根据不同的任务Bert可以有许多不同的用法。

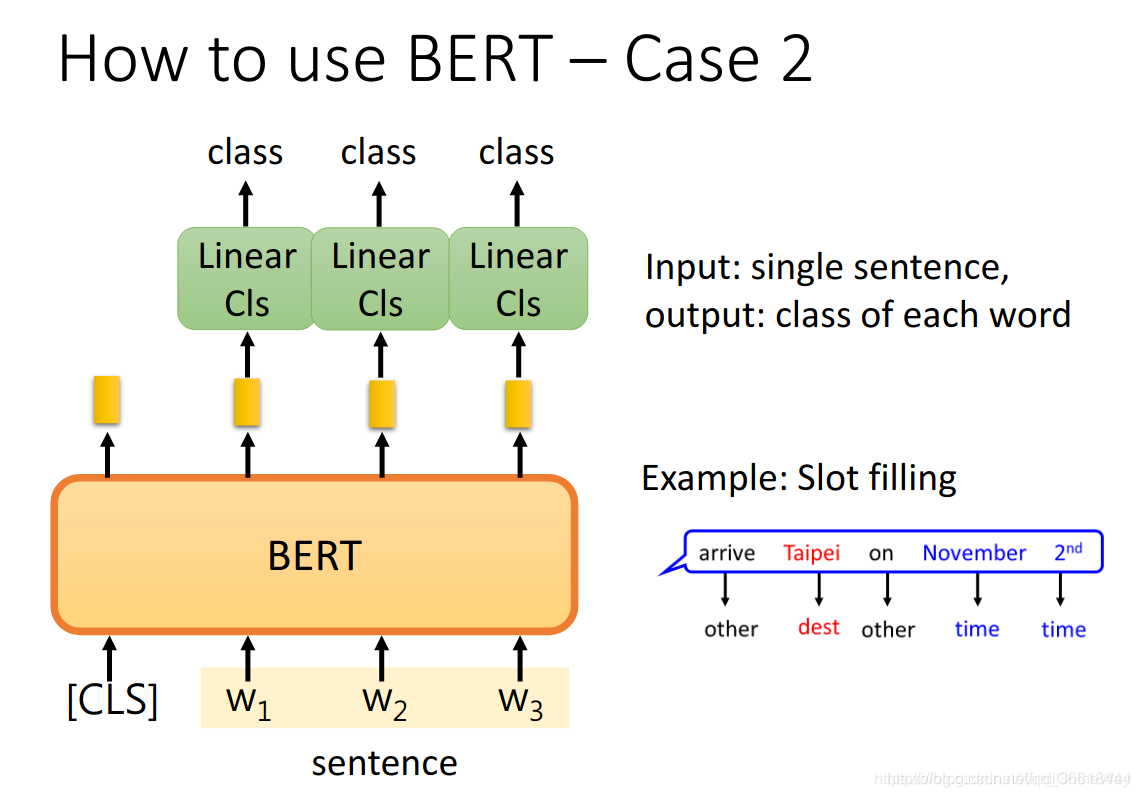
4.2 单词分类
每个单词都对应一个class。最典型的就是序列标注任务。
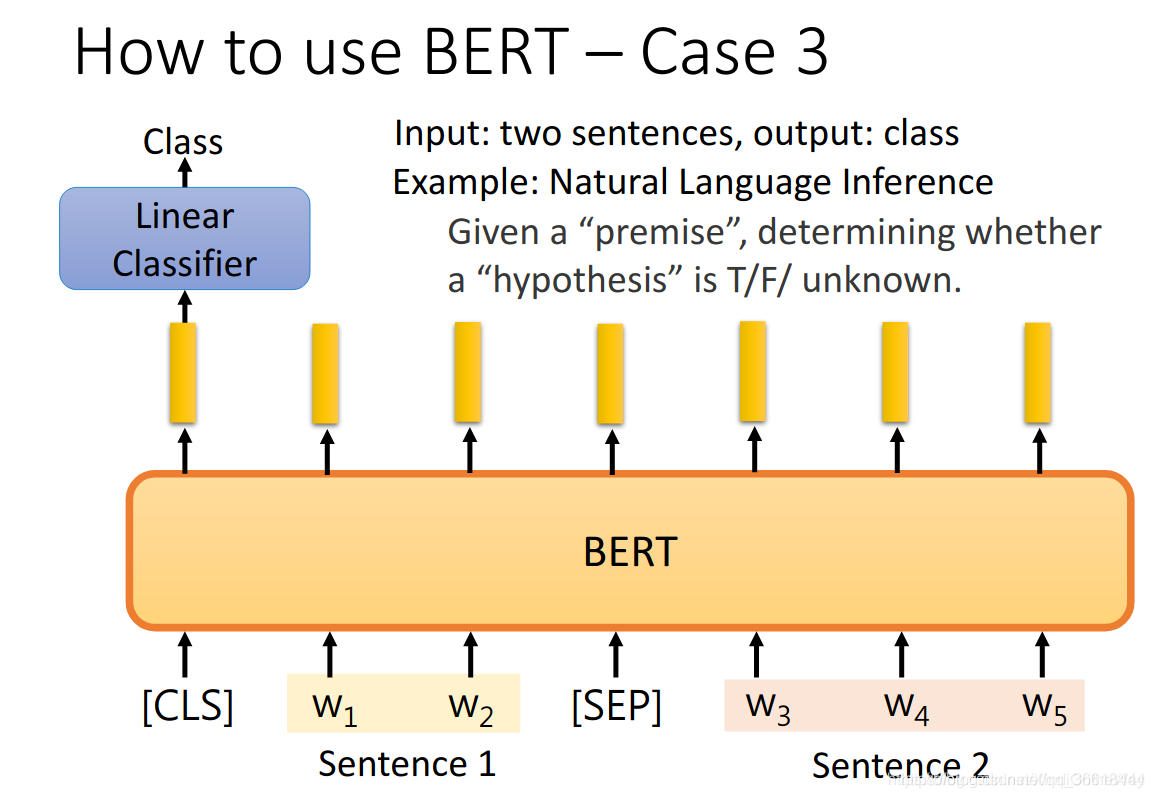
4.3 判断两个句子之间的关系
输入两个句子,output一个[CLS]的分类结果。
4.4 QA(问答系统)
问答。需要答案落在输入语料里面。输入是文档以及问题,输出是答案Start的token的id(s)和结束的id(e)。
比如,问题“什么导致的降水?”在文中的答案是第17个单词gravity(重力),所以s=17,e=17。
 Bert如何实现这个任务呢?首先,还是学习到文档中每个单词的embedding,对应图中浅黄色的条条;然后再学一个橘黄色的条条,这个维度与单词的embedding是一毛一样的,因此这俩张量之间可以做一个dot product,这个类似于注意力。得到的结果通过softmax对每一个向量都返回一个概率,概率最高的token位置就是s。同理,蓝色的条条表示e。若e<s,那么此题无解。
Bert如何实现这个任务呢?首先,还是学习到文档中每个单词的embedding,对应图中浅黄色的条条;然后再学一个橘黄色的条条,这个维度与单词的embedding是一毛一样的,因此这俩张量之间可以做一个dot product,这个类似于注意力。得到的结果通过softmax对每一个向量都返回一个概率,概率最高的token位置就是s。同理,蓝色的条条表示e。若e<s,那么此题无解。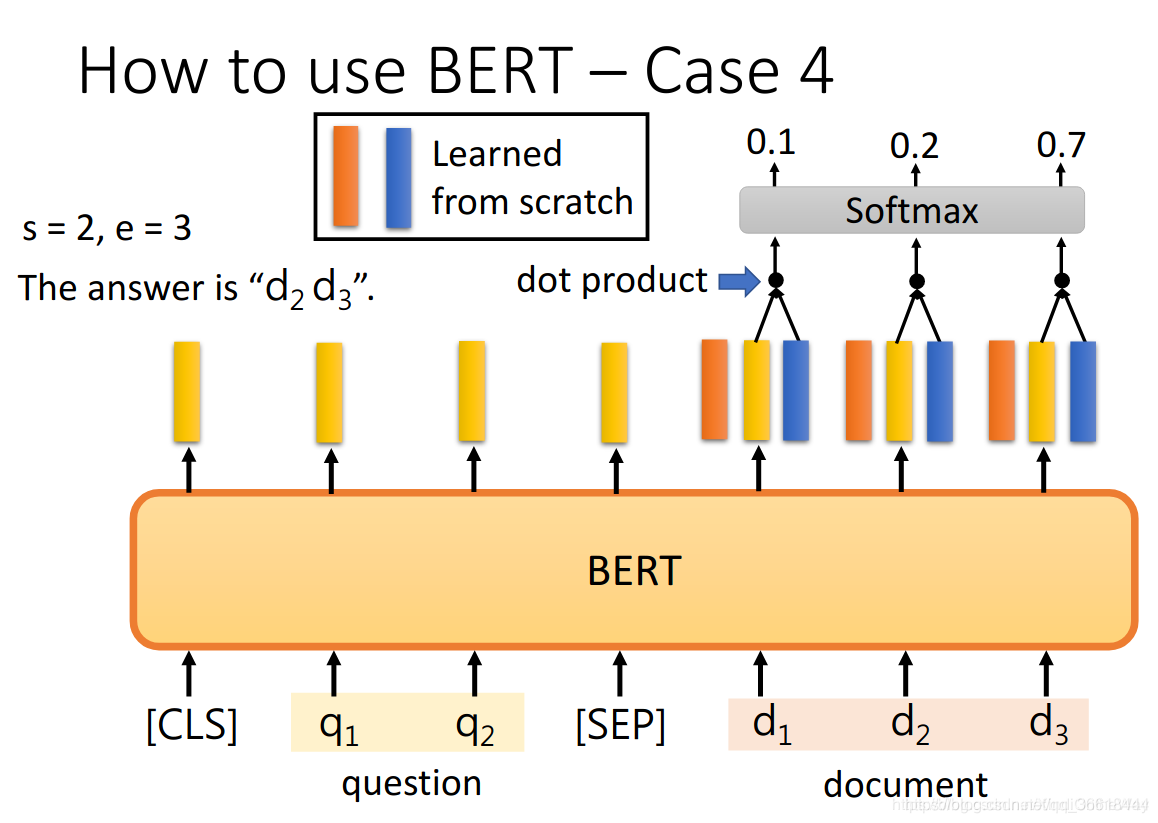
五、BERT文本分类实战
下面是代码部分,我们分别用Fine-tune和非Fine-tune模式下看一下分类效果
5.1 环境搭建
pyotroch>=0.4.1
Python 3.7
条件允许可以使用GPU训练,我CPU、GPU分别都试了一下
GPU服务器:3090Ti 20G
5.2 模型下载
1. 下载bert:
下载地址:GitHub – google-research/bert: TensorFlow code and pre-trained models for BERT
2. 下载bert预训练模型:
pytorch_model.bin
bert_config.json
vocab.txt
下载地址: https://s3.amazonaws.com/models.huggingface.co/bert/bert-base-chinese.tar.gz
5.3 数据准备
将你的语料分成4个文件,分别为train.csv,test.csv,dev.csv,class.csv
链接:https://pan.baidu.com/s/19QlxsVKNziRKvNismH4wvA
提取码:cx44
具体操作:
我的语料来自于情感分析比赛的,是判断新闻标题情感积极消极还是中性,首先使用pandas对语料进行处理,最终处理成“content+label”的格式。如图所示:
5.4 整体代码架构
5.5 代码分解
5.5.1 bert.py
# coding: UTF-8
import torch
import torch.nn as nn
# from pytorch_pretrained_bert import BertModel, BertTokenizer
from pytorch_pretrained import BertModel, BertTokenizer
class Config(object):
"""配置参数"""
def __init__(self, dataset):
self.model_name = 'bert'
self.train_path = dataset + '/data/train.txt' # 训练集
self.dev_path = dataset + '/data/dev.txt' # 验证集
self.test_path = dataset + '/data/test.txt' # 测试集
self.class_list = [x.strip() for x in open(
dataset + '/data/class.txt').readlines()] # 类别名单
self.save_path = dataset + '/saved_dict/' + self.model_name + '.ckpt' # 模型训练结果
self.device = torch.device('cuda' if torch.cuda.is_available() else 'cpu') # 设备
self.require_improvement = 1000 # 若超过1000batch效果还没提升,则提前结束训练
self.num_classes = len(self.class_list) # 类别数
self.num_epochs = 3 # epoch数
self.batch_size = 128 # mini-batch大小
self.pad_size = 32 # 每句话处理成的长度(短填长切)
self.learning_rate = 1e-5 # 学习率
self.bert_path = './bert_pretrain' # bert预训练模型位置
self.tokenizer = BertTokenizer.from_pretrained(self.bert_path) # bert切分词
self.hidden_size = 768 # bert隐藏层个数
class Model(nn.Module):
def __init__(self, config):
super(Model, self).__init__()
self.bert = BertModel.from_pretrained(config.bert_path)
for param in self.bert.parameters():
param.requires_grad = True
self.fc = nn.Linear(config.hidden_size, config.num_classes)
def forward(self, x):
context = x[0] # 输入的句子
mask = x[2] # 对padding部分进行mask,和句子一个size,padding部分用0表示,如:[1, 1, 1, 1, 0, 0]
_, pooled = self.bert(context, attention_mask=mask, output_all_encoded_layers=False)
out = self.fc(pooled)
return out
5.5.2 main.py
# coding: UTF-8
import time
import torch
import numpy as np
from train_eval import train, init_network
from importlib import import_module
import argparse
from utils import build_dataset, build_iterator, get_time_dif
parser = argparse.ArgumentParser(description='Bert-Chinese-Text-Classification')
parser.add_argument('--model', type=str, default='bert', help='choose a model')
args = parser.parse_args()
if __name__ == '__main__':
dataset = 'THUCNews' # 数据集
model_name = args.model # bert
x = import_module('models.' + model_name)
config = x.Config(dataset)
np.random.seed(1)
torch.manual_seed(1)
torch.cuda.manual_seed_all(4)
torch.backends.cudnn.deterministic = True # 保证每次结果一样
start_time = time.time()
print("Loading data...")
train_data, dev_data, test_data = build_dataset(config)
train_iter = build_iterator(train_data, config)
dev_iter = build_iterator(dev_data, config)
test_iter = build_iterator(test_data, config)
time_dif = get_time_dif(start_time)
print("Time usage:", time_dif)
# train
model = x.Model(config).to(config.device)
train(config, model, train_iter, dev_iter, test_iter)
5.5.3 train.py
# coding: UTF-8
import numpy as np
import torch
import torch.nn as nn
import torch.nn.functional as F
from sklearn import metrics
import time
from utils import get_time_dif
from pytorch_pretrained.optimization import BertAdam
# 权重初始化,默认xavier
def init_network(model, method='xavier', exclude='embedding', seed=123):
for name, w in model.named_parameters():
if exclude not in name:
if len(w.size()) < 2:
continue
if 'weight' in name:
if method == 'xavier':
nn.init.xavier_normal_(w)
elif method == 'kaiming':
nn.init.kaiming_normal_(w)
else:
nn.init.normal_(w)
elif 'bias' in name:
nn.init.constant_(w, 0)
else:
pass
def train(config, model, train_iter, dev_iter, test_iter):
start_time = time.time()
model.train()
param_optimizer = list(model.named_parameters())
no_decay = ['bias', 'LayerNorm.bias', 'LayerNorm.weight']
optimizer_grouped_parameters = [
{'params': [p for n, p in param_optimizer if not any(nd in n for nd in no_decay)], 'weight_decay': 0.01},
{'params': [p for n, p in param_optimizer if any(nd in n for nd in no_decay)], 'weight_decay': 0.0}]
# optimizer = torch.optim.Adam(model.parameters(), lr=config.learning_rate)
optimizer = BertAdam(optimizer_grouped_parameters,
lr=config.learning_rate,
warmup=0.05,
t_total=len(train_iter) * config.num_epochs)
total_batch = 0 # 记录进行到多少batch
dev_best_loss = float('inf')
last_improve = 0 # 记录上次验证集loss下降的batch数
flag = False # 记录是否很久没有效果提升
model.train()
for epoch in range(config.num_epochs):
print('Epoch [{}/{}]'.format(epoch + 1, config.num_epochs))
for i, (trains, labels) in enumerate(train_iter):
outputs = model(trains)
model.zero_grad()
loss = F.cross_entropy(outputs, labels)
loss.backward()
optimizer.step()
if total_batch % 100 == 0:
# 每多少轮输出在训练集和验证集上的效果
true = labels.data.cpu()
predic = torch.max(outputs.data, 1)[1].cpu()
train_acc = metrics.accuracy_score(true, predic)
dev_acc, dev_loss = evaluate(config, model, dev_iter)
if dev_loss < dev_best_loss:
dev_best_loss = dev_loss
torch.save(model.state_dict(), config.save_path)
improve = '*'
last_improve = total_batch
else:
improve = ''
time_dif = get_time_dif(start_time)
msg = 'Iter: {0:>6}, Train Loss: {1:>5.2}, Train Acc: {2:>6.2%}, Val Loss: {3:>5.2}, Val Acc: {4:>6.2%}, Time: {5} {6}'
print(msg.format(total_batch, loss.item(), train_acc, dev_loss, dev_acc, time_dif, improve))
model.train()
total_batch += 1
if total_batch - last_improve > config.require_improvement:
# 验证集loss超过1000batch没下降,结束训练
print("No optimization for a long time, auto-stopping...")
flag = True
break
if flag:
break
test(config, model, test_iter)
def test(config, model, test_iter):
# test
model.load_state_dict(torch.load(config.save_path))
model.eval()
start_time = time.time()
test_acc, test_loss, test_report, test_confusion = evaluate(config, model, test_iter, test=True)
msg = 'Test Loss: {0:>5.2}, Test Acc: {1:>6.2%}'
print(msg.format(test_loss, test_acc))
print("Precision, Recall and F1-Score...")
print(test_report)
print("Confusion Matrix...")
print(test_confusion)
time_dif = get_time_dif(start_time)
print("Time usage:", time_dif)
def evaluate(config, model, data_iter, test=False):
model.eval()
loss_total = 0
predict_all = np.array([], dtype=int)
labels_all = np.array([], dtype=int)
with torch.no_grad():
for texts, labels in data_iter:
outputs = model(texts)
loss = F.cross_entropy(outputs, labels)
loss_total += loss
labels = labels.data.cpu().numpy()
predic = torch.max(outputs.data, 1)[1].cpu().numpy()
labels_all = np.append(labels_all, labels)
predict_all = np.append(predict_all, predic)
acc = metrics.accuracy_score(labels_all, predict_all)
if test:
report = metrics.classification_report(labels_all, predict_all, target_names=config.class_list, digits=4)
confusion = metrics.confusion_matrix(labels_all, predict_all)
return acc, loss_total / len(data_iter), report, confusion
return acc, loss_total / len(data_iter)
5.5.4 utils.py
# coding: UTF-8
import torch
from tqdm import tqdm
import time
from datetime import timedelta
PAD, CLS = '[PAD]', '[CLS]' # padding符号, bert中综合信息符号
def build_dataset(config):
def load_dataset(path, pad_size=32):
contents = []
with open(path, 'r', encoding='UTF-8') as f:
for line in tqdm(f):
lin = line.strip()
if not lin:
continue
content, label = lin.split('\t')
token = config.tokenizer.tokenize(content)
token = [CLS] + token
seq_len = len(token)
mask = []
token_ids = config.tokenizer.convert_tokens_to_ids(token)
if pad_size:
if len(token) < pad_size:
mask = [1] * len(token_ids) + [0] * (pad_size - len(token))
token_ids += ([0] * (pad_size - len(token)))
else:
mask = [1] * pad_size
token_ids = token_ids[:pad_size]
seq_len = pad_size
contents.append((token_ids, int(label), seq_len, mask))
return contents
train = load_dataset(config.train_path, config.pad_size)
dev = load_dataset(config.dev_path, config.pad_size)
test = load_dataset(config.test_path, config.pad_size)
return train, dev, test
class DatasetIterater(object):
def __init__(self, batches, batch_size, device):
self.batch_size = batch_size
self.batches = batches
self.n_batches = len(batches) // batch_size
self.residue = False # 记录batch数量是否为整数
if len(batches) % self.n_batches != 0:
self.residue = True
self.index = 0
self.device = device
def _to_tensor(self, datas):
x = torch.LongTensor([_[0] for _ in datas]).to(self.device)
y = torch.LongTensor([_[1] for _ in datas]).to(self.device)
# pad前的长度(超过pad_size的设为pad_size)
seq_len = torch.LongTensor([_[2] for _ in datas]).to(self.device)
mask = torch.LongTensor([_[3] for _ in datas]).to(self.device)
return (x, seq_len, mask), y
def __next__(self):
if self.residue and self.index == self.n_batches:
batches = self.batches[self.index * self.batch_size: len(self.batches)]
self.index += 1
batches = self._to_tensor(batches)
return batches
elif self.index >= self.n_batches:
self.index = 0
raise StopIteration
else:
batches = self.batches[self.index * self.batch_size: (self.index + 1) * self.batch_size]
self.index += 1
batches = self._to_tensor(batches)
return batches
def __iter__(self):
return self
def __len__(self):
if self.residue:
return self.n_batches + 1
else:
return self.n_batches
def build_iterator(dataset, config):
iter = DatasetIterater(dataset, config.batch_size, config.device)
return iter
def get_time_dif(start_time):
"""获取已使用时间"""
end_time = time.time()
time_dif = end_time - start_time
return timedelta(seconds=int(round(time_dif)))
详细代码和数据集均放在我Github上,大家可以去下载:https://github.com/LePetitPrinceWh/Bert-Pytorch-TextClassification.git
5.5.5 结果分析
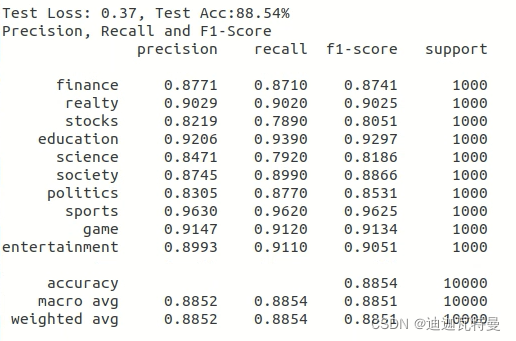
从运行结果可知,Bert文本分类的效果还是比较好的。
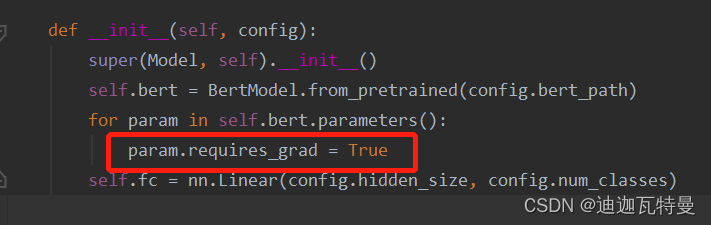 当我们把Bert.py文件的这一行代码将True改为False,就是模型训练变为非Fin Tune情况下
当我们把Bert.py文件的这一行代码将True改为False,就是模型训练变为非Fin Tune情况下
param.requires_grad = False #非Fine Tune的情况提示:
给定预训练模型(Pre_trained model),基于模型进行微调(Fine Tune)。相对于从头开始训练(Training a model from scatch),微调为你省去大量计算资源和计算时间,提高了计算效率,甚至提高准确率。
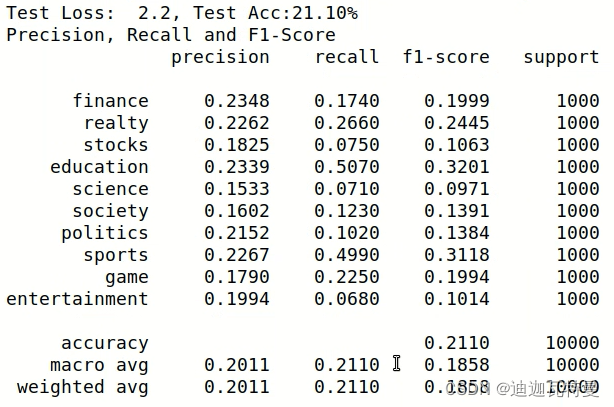
我们发现在非 Fine Tune 的情况下,准确率要降低很多。后面我会在Bert结合CNN、RNN等其他模型,并对比实验结果。
参考文档
1. BERT模型的详细介绍_IT之一小佬的博客-CSDN博客_bert模型
2. 《How to Fine-Tune BERT for Text Classification》-阅读心得 – 今夜无风 – 博客园
3. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding_Hi-Cloud的博客-CSDN博客
4. BERT解析及文本分类应用 – xlturing – 博客园
5. 基于BERT做中文文本分类(情感分析)_我开心呀的博客-CSDN博客_bert中文文本分类
7. Bert原理_五月的echo的博客-CSDN博客_bert分类原理
8. 《https://arxiv.org/pdf/1706.03762.pdfAttention is all you need》《https://arxiv.org/pdf/1706.03762.pdf
9. 《https://arxiv.org/pdf/1810.04805.pdfBERT: Pre-training of Deep Bidirectional Transformers for Language Understanding》《https://arxiv.org/pdf/1810.04805.pdf
文章出处登录后可见!