目录
1. 迁移学习介绍
迁移学习可以帮助我们快速实现一个网络
通过载入预训练好的模型,然后针对不同的项目进行微调,比从头训练的网络收敛要快得多
常见的有下面几种方式:

2. 迁移学习方式
下面对上面三种的方法进行实现
迁移学习:需要保证自定义的模型和预训练的模型一样,否则载入权重的位置会对应不上
2.1 载入所有参数
测试代码用的是resnet网络:
# 构建网络
net = resnet34() # 不需要设定参数
pre_model = './resnet_pre_model.pth' # 预训练权重
missing_keys,unexpected_keys = net.load_state_dict(torch.load((pre_model)),strict=False)
这样,就可以载入预训练模型,然后再进行训练了。
其实这个就是权重的初始化,平时用的是随机的初始化,现在用的是别人训练好的,可以实际应用的初始化
2.2 载入参数,只训练最后的参数
这里用torchvision演示:
from torchvision.models import AlexNet
# Alex
model = AlexNet(num_classes=10)
'''
AlexNet(
(features): Sequential(
(0): Conv2d(3, 64, kernel_size=(11, 11), stride=(4, 4), padding=(2, 2))
(1): ReLU(inplace=True)
(2): MaxPool2d(kernel_size=3, stride=2, padding=0, dilation=1, ceil_mode=False)
(3): Conv2d(64, 192, kernel_size=(5, 5), stride=(1, 1), padding=(2, 2))
(4): ReLU(inplace=True)
(5): MaxPool2d(kernel_size=3, stride=2, padding=0, dilation=1, ceil_mode=False)
(6): Conv2d(192, 384, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(7): ReLU(inplace=True)
(8): Conv2d(384, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(9): ReLU(inplace=True)
(10): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(11): ReLU(inplace=True)
(12): MaxPool2d(kernel_size=3, stride=2, padding=0, dilation=1, ceil_mode=False)
)
(avgpool): AdaptiveAvgPool2d(output_size=(6, 6))
(classifier): Sequential(
(0): Dropout(p=0.5, inplace=False)
(1): Linear(in_features=9216, out_features=4096, bias=True)
(2): ReLU(inplace=True)
(3): Dropout(p=0.5, inplace=False)
(4): Linear(in_features=4096, out_features=4096, bias=True)
(5): ReLU(inplace=True)
(6): Linear(in_features=4096, out_features=10, bias=True)
)
)
'''
因为这里使用的是pytorch的反向传播,而是否可以反向传播就是这个参数的requires_grad 是否等于True 。只训练最后参数的话,只需要把前面参数的requires_grad设定为False,冻结就行了
显示网络的参数:
for name,para in model.named_parameters():
print(name)
'''features.0.weight
features.0.bias
features.3.weight
features.3.bias
features.6.weight
features.6.bias
features.8.weight
features.8.bias
features.10.weight
features.10.bias
classifier.1.weight
classifier.1.bias
classifier.4.weight
classifier.4.bias
classifier.6.weight
classifier.6.bias
'''这里我们只需要将特征提取层,也就是卷积层冻结,然后全连接层不变就行了
操作如下:
for name,para in model.named_parameters():
if 'features' in name:
para.requires_grad = False这里冻结和没冻结前做个对比:
冻结前:
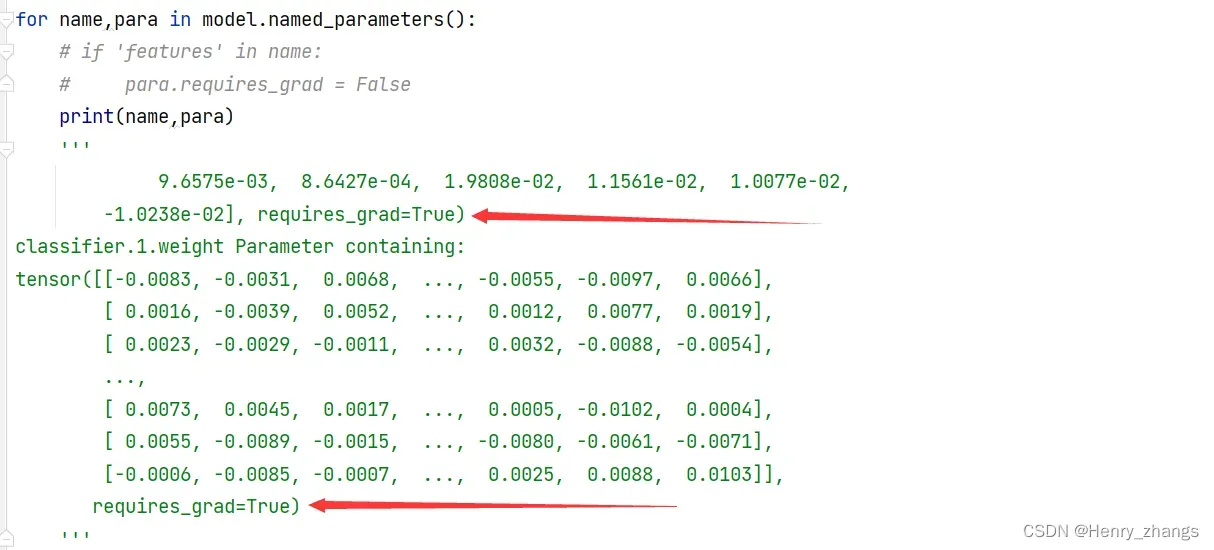
冻结后:
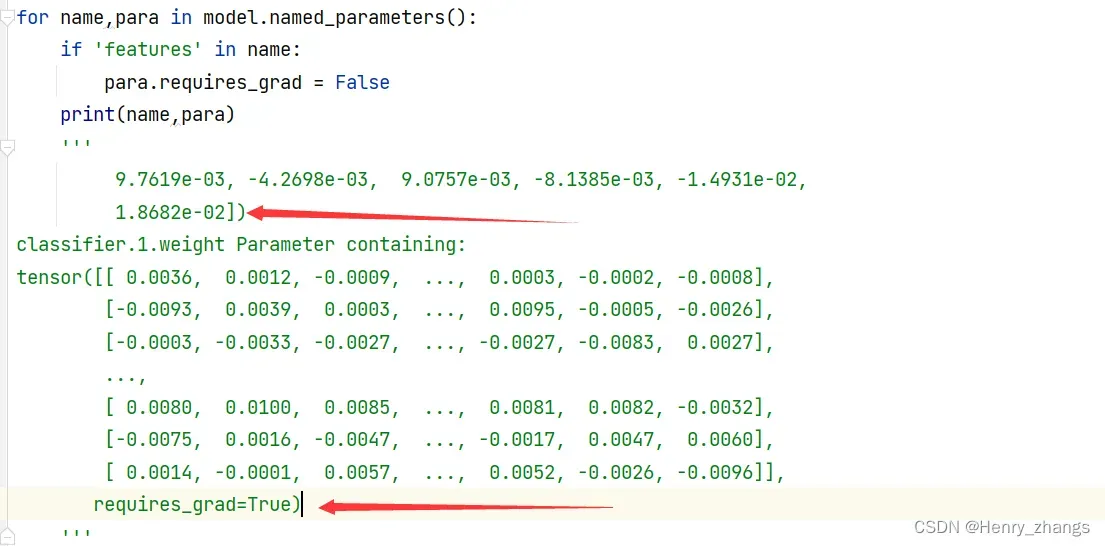
优化器中也要改变,需要过滤掉不需要反向传播的参数
优化器中过滤冻结的参数:
from torchvision.models import AlexNet
from torch import optim
# Alex
model = AlexNet(num_classes=10)
for name,para in model.named_parameters():
if 'features' in name:
para.requires_grad = False
para = [p for p in model.parameters() if p.requires_grad]
optimizer = optim.Adam(para,lr=0.001)
'''
[Parameter containing:
tensor([[ 0.0024, 0.0097, -0.0038, ..., 0.0044, 0.0014, 0.0096],
[-0.0078, -0.0014, 0.0031, ..., -0.0010, 0.0051, 0.0012],
[-0.0088, 0.0054, -0.0075, ..., -0.0026, 0.0085, -0.0103],
...,
[-0.0090, 0.0065, 0.0046, ..., -0.0077, 0.0068, -0.0092],
[ 0.0051, 0.0075, 0.0015, ..., -0.0072, -0.0044, 0.0077],
[ 0.0060, 0.0079, 0.0010, ..., 0.0066, 0.0044, -0.0006]],
requires_grad=True), Parameter containing:
tensor([-0.0072, 0.0021, -0.0079, ..., -0.0045, -0.0031, 0.0052],
requires_grad=True), Parameter containing:
tensor([[-7.3999e-03, 7.5480e-03, -7.0330e-03, ..., -2.3227e-03,
-1.0509e-03, -1.0634e-02],
[ 1.4005e-02, 1.0355e-02, 4.3921e-03, ..., 5.6021e-03,
-5.4067e-03, 8.2123e-03],
[ 1.1953e-02, 7.0178e-03, 6.5284e-05, ..., 9.9544e-03,
1.2050e-02, -2.8193e-03],
...,
[-1.2271e-02, 2.8609e-03, 1.5023e-02, ..., -1.2590e-02,
3.6282e-03, -1.5037e-03],
[-1.1178e-02, -6.8283e-03, -1.5380e-02, ..., 9.1631e-03,
-8.2415e-04, -1.0820e-02],
[ 3.5226e-03, 8.1489e-04, 1.4744e-02, ..., 3.8180e-03,
7.2305e-03, -4.8745e-03]], requires_grad=True), Parameter containing:
tensor([-0.0024, 0.0106, 0.0019, ..., -0.0047, -0.0113, 0.0155],
requires_grad=True), Parameter containing:
tensor([[-8.0021e-03, -5.3036e-03, -7.7326e-03, ..., -6.2924e-03,
1.0251e-02, -1.3929e-02],
[-1.0562e-02, 1.5300e-02, -1.3457e-02, ..., 4.8542e-03,
-1.2721e-02, -2.1716e-03],
[ 1.2303e-02, 3.4304e-03, -1.3099e-02, ..., -6.2512e-03,
-7.1608e-03, -5.3249e-03],
...,
[ 1.4954e-02, -9.6393e-03, 1.3907e-02, ..., 2.4139e-03,
-2.5765e-03, -4.9496e-05],
[ 7.0794e-03, -5.5391e-03, -1.1280e-02, ..., 2.3952e-03,
4.2578e-03, 7.0075e-03],
[ 1.0447e-02, -8.3530e-03, 5.4398e-03, ..., -1.4187e-03,
1.2113e-02, 1.0778e-02]], requires_grad=True), Parameter containing:
tensor([-0.0004, -0.0154, -0.0008, -0.0101, 0.0106, 0.0130, -0.0051, 0.0056,
-0.0152, -0.0006], requires_grad=True)]
'''
2.3 载入后,添加新层,对新层训练
预训练的模型,分类的结果可能不是我们需要的,例如预训练是1000分类,我们做的是10分类
所以这里,需要将最后一层改变
注:这里是将最后一个分类层改变,没有在原有的基础上添加新层
2.3.1 查看网络结构
需要改变的话,那肯定得需要查看原有的网络结构
from torchvision.models import AlexNet
# Alex
model = AlexNet(num_classes=10)
'''
AlexNet(
(features): Sequential(
(0): Conv2d(3, 64, kernel_size=(11, 11), stride=(4, 4), padding=(2, 2))
(1): ReLU(inplace=True)
(2): MaxPool2d(kernel_size=3, stride=2, padding=0, dilation=1, ceil_mode=False)
(3): Conv2d(64, 192, kernel_size=(5, 5), stride=(1, 1), padding=(2, 2))
(4): ReLU(inplace=True)
(5): MaxPool2d(kernel_size=3, stride=2, padding=0, dilation=1, ceil_mode=False)
(6): Conv2d(192, 384, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(7): ReLU(inplace=True)
(8): Conv2d(384, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(9): ReLU(inplace=True)
(10): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(11): ReLU(inplace=True)
(12): MaxPool2d(kernel_size=3, stride=2, padding=0, dilation=1, ceil_mode=False)
)
(avgpool): AdaptiveAvgPool2d(output_size=(6, 6))
(classifier): Sequential(
(0): Dropout(p=0.5, inplace=False)
(1): Linear(in_features=9216, out_features=4096, bias=True)
(2): ReLU(inplace=True)
(3): Dropout(p=0.5, inplace=False)
(4): Linear(in_features=4096, out_features=4096, bias=True)
(5): ReLU(inplace=True)
(6): Linear(in_features=4096, out_features=10, bias=True)
)
)
'''
这里找网络特定层就是逐个遍历的方法
例如这里要找到最后一个分类层,首先它在classifier的6里面,然后classifier又在Alexnet下面
记住,这里的Alexnet就是自己实例化的网络,这里是model
所以这里要找到最后一个Linear的方法就是,model.classifier[6]

2.3.2 更改分类层
那更改的话,直接将out_feartures更改就行了,也就是model.classifier[6].out_features = 10

当然,也可以用自定义的Linear 替换掉,两种方法是一样的

在这里基础上,进行冻结,就和之前的操作一样的,这里不再演示
2.3.3 自定义网络 resnet 的演示
首先,一定要查看网络的结构,因为同一个网络,可能实现方式是不一样的
from model import resnet34
net = resnet34()
print(net)
'''
ResNet(
(conv1): Conv2d(3, 64, kernel_size=(7, 7), stride=(2, 2), padding=(3, 3), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(maxpool): MaxPool2d(kernel_size=3, stride=2, padding=1, dilation=1, ceil_mode=False)
(layer1): Sequential(
(0): BasicBlock(
(conv1): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU()
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(1): BasicBlock(
(conv1): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU()
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(2): BasicBlock(
(conv1): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU()
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(layer2): Sequential(
(0): BasicBlock(
(conv1): Conv2d(64, 128, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU()
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(downsample): Sequential(
(0): Conv2d(64, 128, kernel_size=(1, 1), stride=(2, 2), bias=False)
(1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): BasicBlock(
(conv1): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU()
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(2): BasicBlock(
(conv1): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU()
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(3): BasicBlock(
(conv1): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU()
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(layer3): Sequential(
(0): BasicBlock(
(conv1): Conv2d(128, 256, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU()
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(downsample): Sequential(
(0): Conv2d(128, 256, kernel_size=(1, 1), stride=(2, 2), bias=False)
(1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): BasicBlock(
(conv1): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU()
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(2): BasicBlock(
(conv1): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU()
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(3): BasicBlock(
(conv1): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU()
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(4): BasicBlock(
(conv1): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU()
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(5): BasicBlock(
(conv1): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU()
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(layer4): Sequential(
(0): BasicBlock(
(conv1): Conv2d(256, 512, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU()
(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(downsample): Sequential(
(0): Conv2d(256, 512, kernel_size=(1, 1), stride=(2, 2), bias=False)
(1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): BasicBlock(
(conv1): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU()
(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(2): BasicBlock(
(conv1): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU()
(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(avgpool): AdaptiveAvgPool2d(output_size=(1, 1))
(fc): Linear(in_features=512, out_features=1000, bias=True)
)
'''
注意看,这里最后一层是fc,而不是之前的classifier
所以更改最后一层应该这样实现

更改中间的卷积层为:
net = resnet34()
net.layer2[0].conv1 = nn.Conv2d(64,256,kernel_size=3,stride=1)
之前的网络:

更改之后的:

3. 查看网络的参数值
只需要在之前的索引后,加一个权重或者偏置就行了
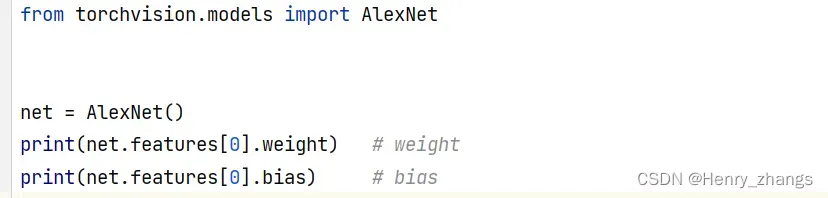
或者利用上面冻结的方法也可以

感兴趣的话可以自己试试
文章出处登录后可见!