
python读取word详解【from docx import Document】
目录
python读取word详解【from docx import Document】
前言
我们平时工作的时候会有很多的时候会遇到需要将word里面的有些杂乱的数据格式化到Excel中去,但是如果手动操作那真是【超级无语】,很崩溃,几百页的word让你慢慢复制粘贴,会死掉的。所以我们需要使用程序来完成,使用python先通过【docx】的包将word中的文字逐行读取出来,再根据行的数据格式进行数据清洗,清洗成对应的列表数据,批量写入Excel即可,这里我写入的是【CSV】文件,也可以通过Excel直接打开的。
环境
系统:win10
工具:PyCharm Community Edition 2021.3.1
解析目标类型:*.docx文件
输出目标类型:*.csv文件
需要用包:pip install docx
使用技巧:字符串处理
示例字符串
1、( A )不可存放于码头普通仓库内。
A、爆炸品 B、棉料 C、煤粉
2、( A )负责核发危险化学品及其包装物、容器生产企业的工业产品生产许可证,并依法对其产品质量实施监督,负责对进出口危险化学品及其包装实施检验。
A、质量监督检验检疫部门 B、安全生产监督局 C、公安部门
3、( A )告诉我们,构成管理系统的各要素是运动和发展的,它们相互联系又相互制约。在生产经营单位建立、健全安全生产责任制是对这一原则的应用。
A、动力相关性原则 B、动力原则 C、人本原理
4、( A )即根据演练工作需要,采取必要安全防护措施,确保参演、观摩等人员以及生产运行系统安全。
A、演练工作安全保障 B、安全防护措施 C、系统安全
5、( A )建立健全应急物资储备保障制度,完善重要应急物资的监管、生产、储备、调拨和紧急配送体系。
A、国家 B、社会 C、企业
下载环境
pip install docx
导入环境
from docx import Document
import csv
import uuidimport re
Document读取word
from docx import Document
import csv
import uuid
import re
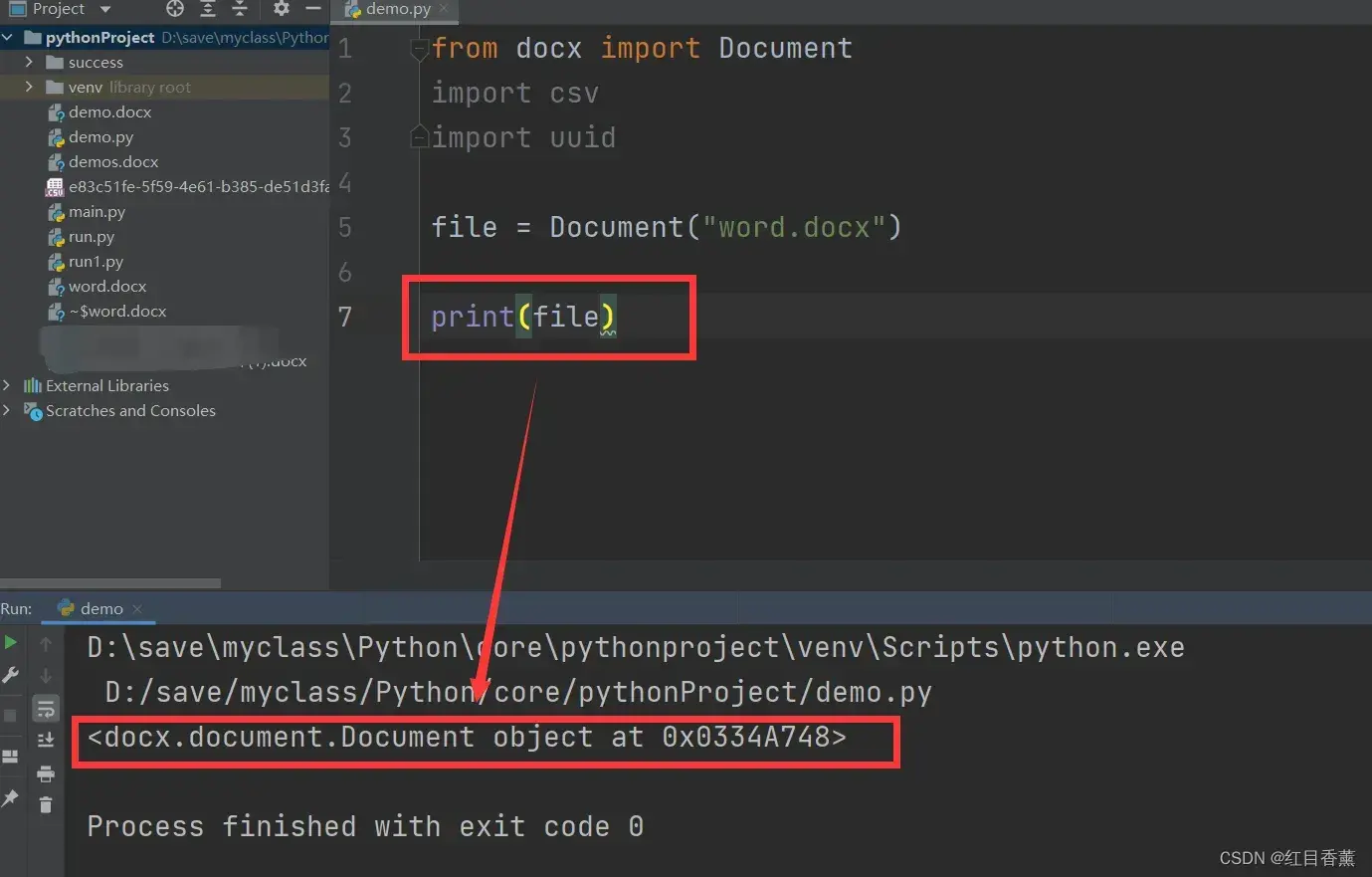
file = Document("word.docx")
print(file)输出对象查看是否读取成功,可以看到有对象的输出,代表读取成功。
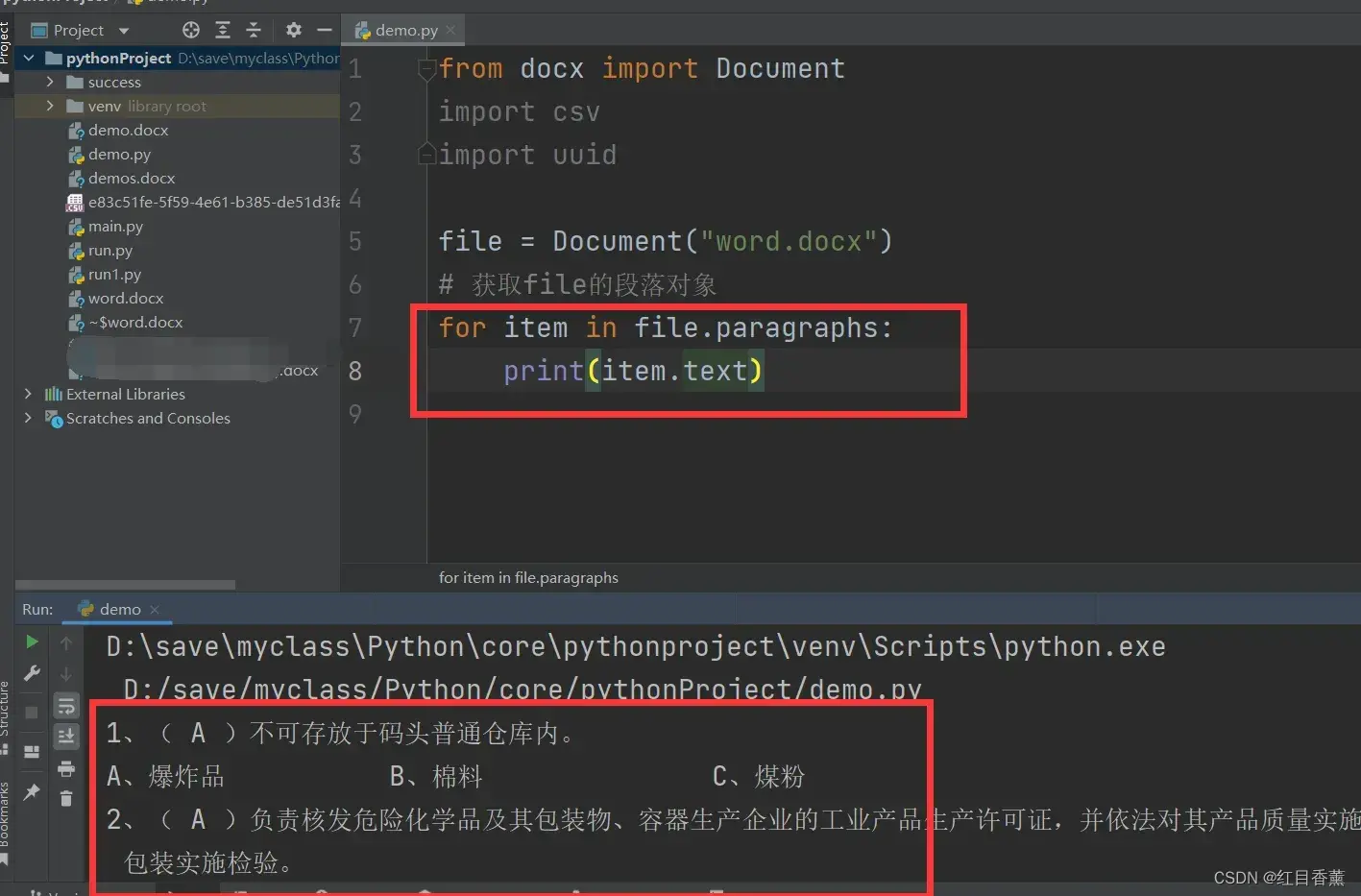
使用【paragraphs】获取段落信息,可以看出输出的文字。
行拆分
拆分题目行与选择行
from docx import Document
import csv
import uuid
import re
file = Document("word.docx")
# 拆分依据
info = r"( A )|( B )|( C )|( )"
# 输出样式
header_list2 = ["题型", "难度", "题目问题", "正确答案", "选项A", "选项B", "选项C"]
# 获取file的段落对象
for item in file.paragraphs:
# 正则区分行
te = re.search(info, item.text)
print(te)
测试输出效果:
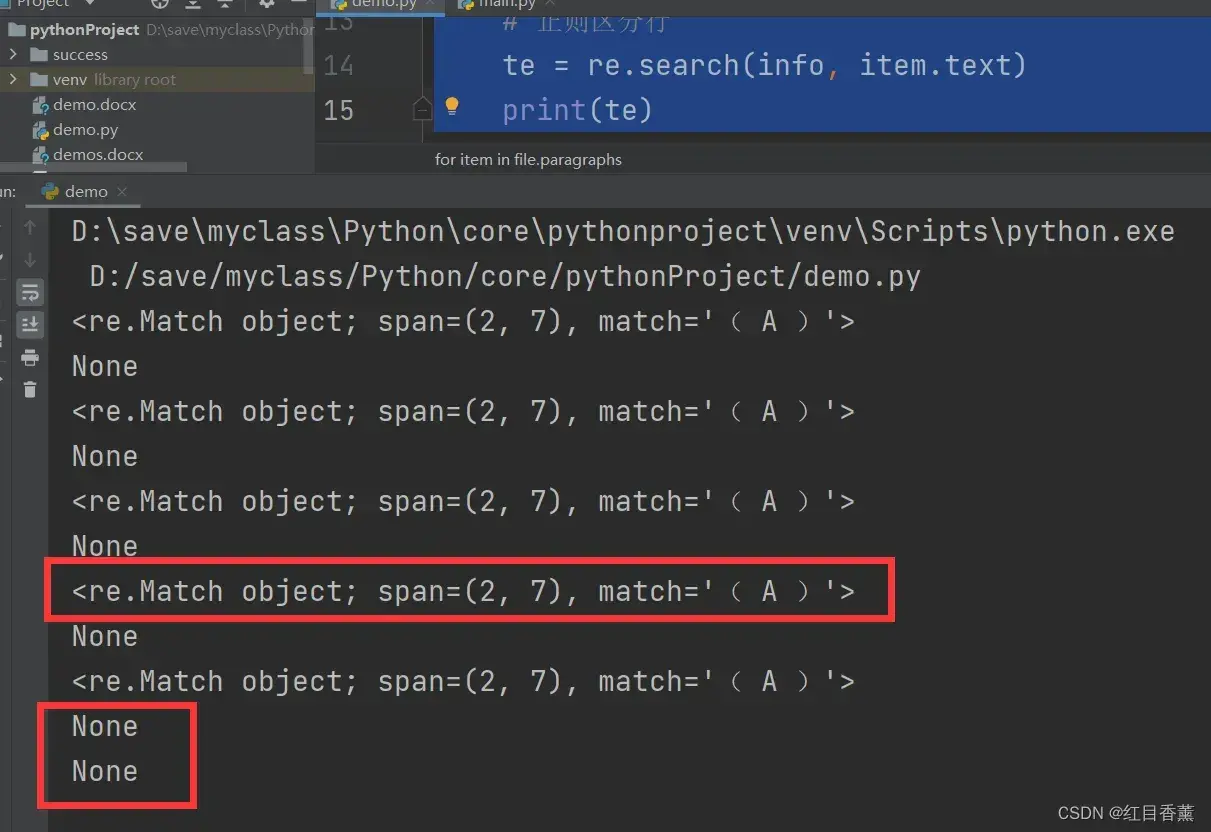
信息分析
正则判断根据答案进行判断的,如果这个行有就能输出,如果没有也就是选项那么就会输出【None】,所以我们判断一下是否等于【None】来区分题目行与选项行。
数据分组
from docx import Document
import csv
import uuid
import re
file = Document("word.docx")
# 拆分依据
info = r"( A )|( B )|( C )|( )"
# 输出样式
header_list2 = ["题型", "难度", "题目问题", "正确答案", "选项A", "选项B", "选项C"]
# 用于最终存储
data_list = []
# 用于存储集合·前两项固定的可以直接写上·我们主要拆分后面5列
list_child = ["单选", "1", "", "", "", "", ""]
# 获取file的段落对象
for item in file.paragraphs:
# 正则区分行
te = re.search(info, item.text)
if te != None:
if list_child[2] != "":
data_list.append(list_child)
list_child = ["单选", "1", "", "", "", "", ""]
list_child[2] = item.text.replace(item.text[te.span()[0]:te.span()[1]], "( )")
list_child[3] = item.text[te.span()[0]:te.span()[1]]
else:
item2Len = []
for item2 in item.text.split(" "):
if item2 != "":
item2Len.append(item2)
list_child[4] = item2Len[0]
list_child[5] = item2Len[1]
list_child[6] = item2Len[2]
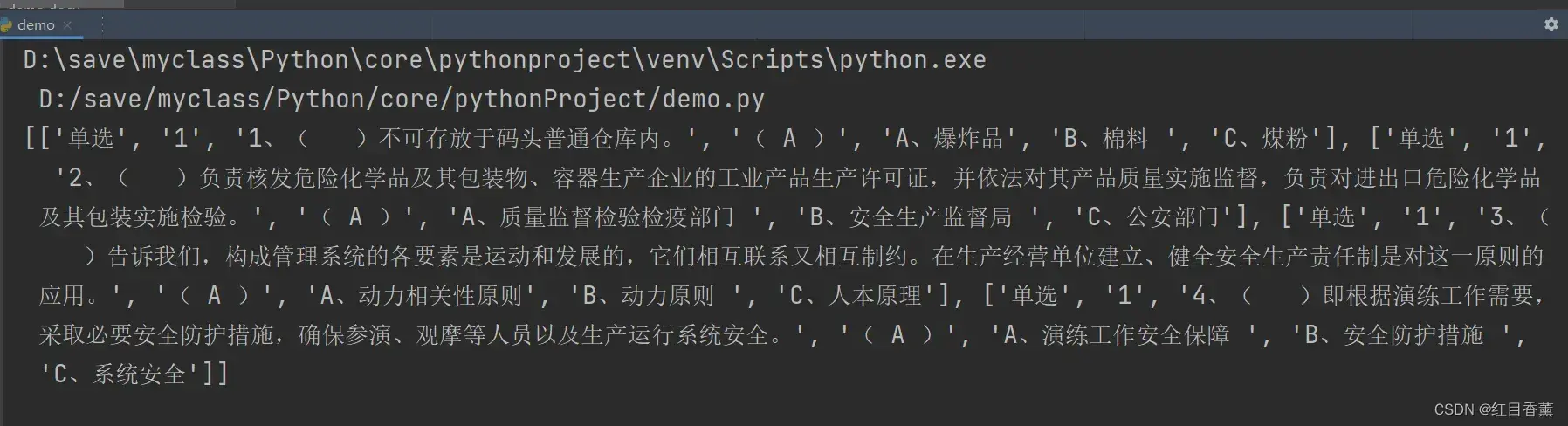
print(data_list)
分组效果:
csv文件写入
直接创建一个新的文件写入即可。
from docx import Document
import csv
import uuid
import re
file = Document("word.docx")
# 拆分依据
info = r"( A )|( B )|( C )|( )"
# 输出样式
header_list2 = ["题型", "难度", "题目问题", "正确答案", "选项A", "选项B", "选项C"]
# 用于最终存储
data_list = []
# 用于存储集合·前两项固定的可以直接写上·我们主要拆分后面5列
list_child = ["单选", "1", "", "", "", "", ""]
# 获取file的段落对象
for item in file.paragraphs:
# 正则区分行
te = re.search(info, item.text)
if te != None:
if list_child[2] != "":
data_list.append(list_child)
list_child = ["单选", "1", "", "", "", "", ""]
list_child[2] = item.text.replace(item.text[te.span()[0]:te.span()[1]], "( )")
list_child[3] = item.text[te.span()[0]:te.span()[1]]
else:
item2Len = []
for item2 in item.text.split(" "):
if item2 != "":
item2Len.append(item2)
list_child[4] = item2Len[0]
list_child[5] = item2Len[1]
list_child[6] = item2Len[2]
fileName = "{0}.csv".format(uuid.uuid4())
with open(fileName, 'w', encoding="utf-8-sig", newline="") as csvFile:
wr = csv.writer(csvFile)
wr.writerow(header_list2)
wr.writerows(data_list)
写入效果:
PyCharm打开效果:
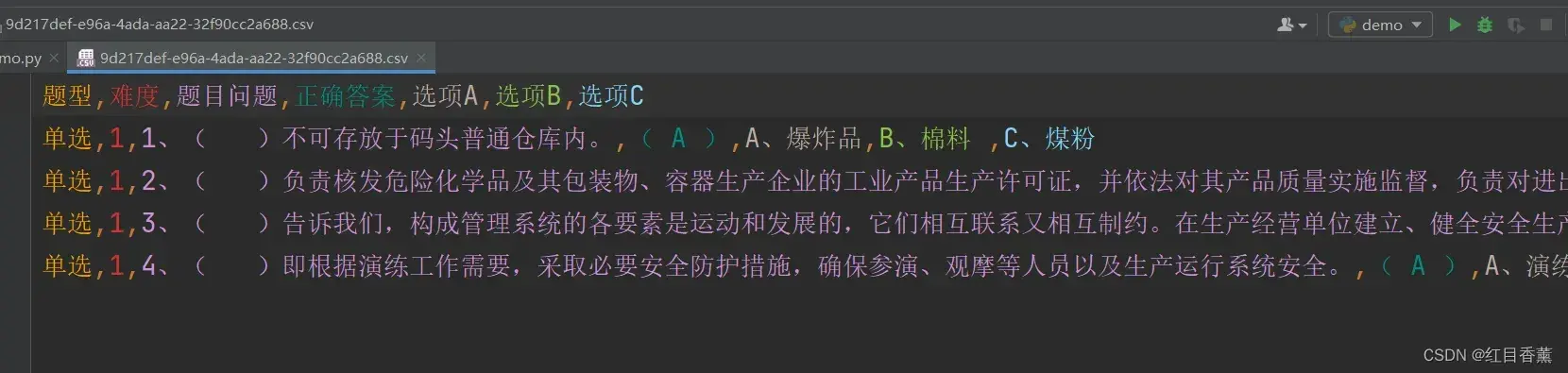
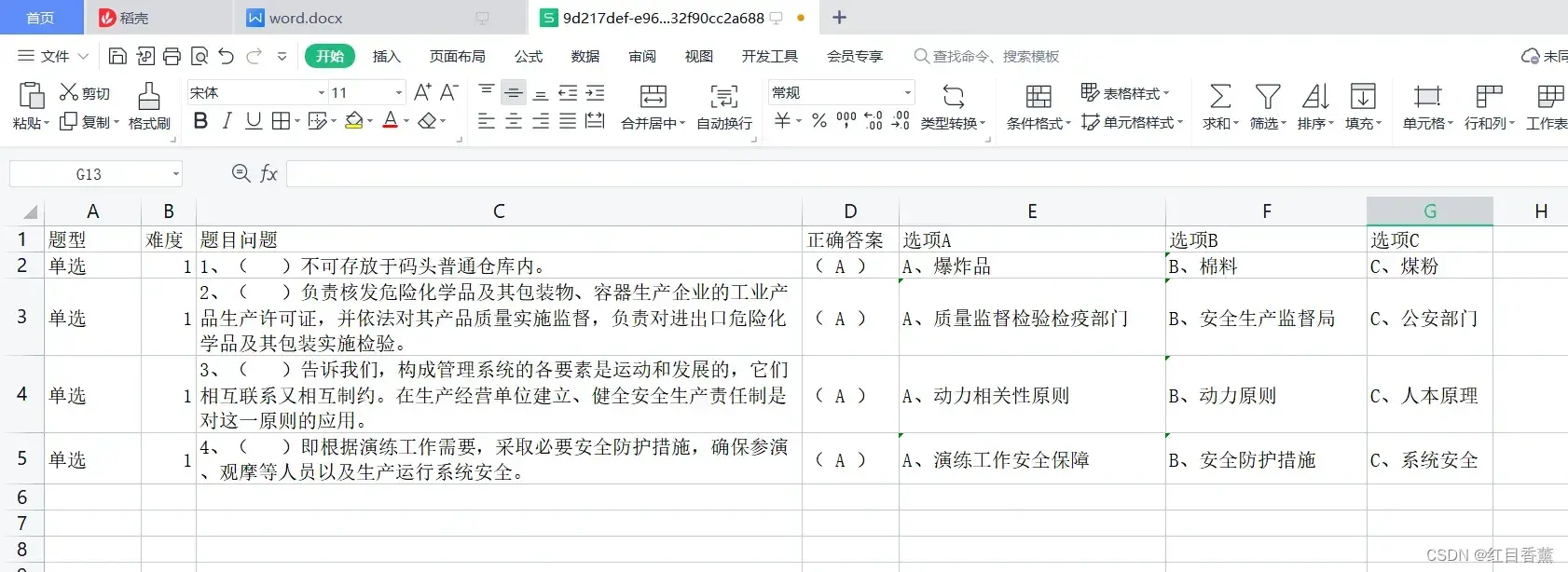
Excel打开效果:
演示完毕,根据实际需求处理数据即可。
文章出处登录后可见!