一、K-近邻算法
1.介绍
K-近邻算法(K Nearest Neighbor)又叫KNN算法,指如果一个样本在特征空间中的k个最相似的样本中的大多数属于某一个类别,则该样本也属于这个类别。也就是对于新输入的实例,从数据集中找到于该实例最邻近的k个实例,那么这k个实例大多数属于某一个类,那么就把该实例放到该类中。
KNN算法不仅可以用于分类,还可以用于回归。通过找出一个样本的k个最近邻居,将这些邻居的属性的平均值赋给该样本,就可以得到该样本的属性。
举个栗子:若已经对一部分人标明皮肤白还是黑,当新加入一个人时,若要对其判定皮肤是黑还是白,那么就可以看其皮肤颜色与已判定黑或者白的人群皮肤颜色进行对比,与哪方更贴近则可以表明该人皮肤到底属于哪一类
2.K-近邻算法流程
- 计算已知类别数据集中的点与当前点之间的距离
- 按距离递增次序排序
- 选取与当前点距离最小的k个点
- 统计前k个点所在的类别出现的频率
- 返回前k个点出现频率最高的类别作为当前点的预测分类
计算距离一般使用欧氏距离公式,
机器学习流程获取数据-》数据基本处理-》特征工程-》机器学习-》模型评估
3.Scikit-learn机器学习库
Scikit-learn是python学习机器学习的工具,包括很多的机器学习算法。
优点:
- 简单,易理解,精度高,既可以用来做分类也可以用来做回归
- 可用于数值型数据和离散型数据
- 无数据输入假定
- 适合对稀有事件进行分类
(1)安装
安装:pip3 install scikit-learn
注:安装scikit-learn需要Numpy, Scipy等库
(2)Scikit-learn包含的内容
- 分类、聚类、回归
- 特征工程
- 模型选择、调优
4.K-近邻算法API—sklearn.neighbors.KNeighborsClassifier(n_neighbors=5,algorithm='auto')
- n_neighbors=5:int,可选(默认= 5),k_neighbors查询默认使用的邻居数
- algorithm:{‘auto’,‘ball_tree’,‘kd_tree’,‘brute’}
- 快速k近邻搜索算法,默认参数为auto,可以理解为算法自己决定合适的搜索算法。除此之外,用户也可以自己指定搜索算法ball_tree、kd_tree、brute方法进行搜索,
- brute是蛮力搜索,也就是线性扫描,当训练集很大时,计算非常耗时。
- kd_tree,构造kd树存储数据以便对其进行快速检索的树形数据结构,kd树也就是数据结构中的二叉树。以中值切分构造的树,每个结点是一个超矩形,在维数小于20时效率高。
- ball tree是为了克服kd树高维失效而发明的,其构造过程是以质心C和半径r分割样本空间,每个节点是一个超球体。
- 快速k近邻搜索算法,默认参数为auto,可以理解为算法自己决定合适的搜索算法。除此之外,用户也可以自己指定搜索算法ball_tree、kd_tree、brute方法进行搜索,
案例
3.1 步骤分析
- 1.获取数据集
- 2.数据基本处理(该案例中省略)
- 3.特征工程(该案例中省略)
- 4.机器学习
- 5.模型评估(该案例中省略)
3.2 代码过程
from sklearn.neighbors import KNeighborsClassifier
# 1.构造数据
# x为特征值,是dataframe形式理解为二维[[]]
x = [[1], [2], [3], [4]]
# y为目标值,可以表示为series,表示为一维数组[]
y = [0, 10, 20, 30]
# 表示
# x y
# 1 0
# 2 10
# 3 20
# 4 30
# 2.训练模型
# 2.1实例化API,实例化一个估计器对象,因为样本数只有4个,所以n_neighbors<=4
estimator = KNeighborsClassifier(n_neighbors=1)
# 2.2使用fit方法进行训练,x为二维,y为一维
estimator.fit(x, y)
# 3.数据预测,将测试集的特征值传入,根据先前计算出的模型,来预测所给测试机的目标值,注意参数为二维[[]]
ret1 = estimator.predict([[0]])
print(ret1)
# 0离1近,1的值为0,所以输出0
ret2 = estimator.predict([[10]])
print(ret2)
# 10离4近,4的值为30,所以输出30
# 输出结果[0] [30]
5.距离度量
(1)距离公式基本性质
- 非负性:
;
- 同一性:
。当且仅当
;
- 对称性:
;
- 直递性:
直递性常被直接称为“三角不等式”。
(2)常见距离公式
①欧氏距离—通过距离平方值
X=[[1,1],[2,2],[3,3],[4,4]];
经计算得:
d = 1.4142 2.8284 4.2426 1.4142 2.8284 1.4142
②曼哈顿距离—通过距离的绝对值
在曼哈顿街区要从一个十字路口开车到另一个十字路口,驾驶距离显然不是两点间的直线距离。这个实际驾驶距离就是“曼哈顿距离”。曼哈顿距离也称为“城市街区距离”(City Block distance)。
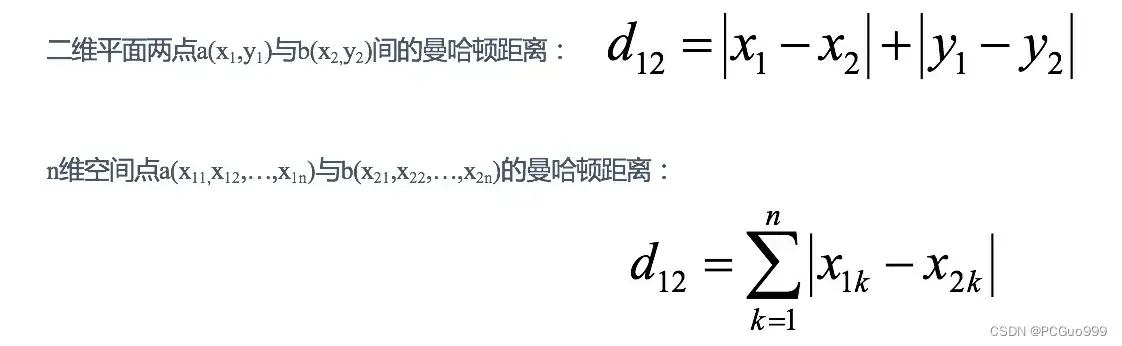
X=[[1,1],[2,2],[3,3],[4,4]];
经计算得:
d = 2 4 6 2 4 2
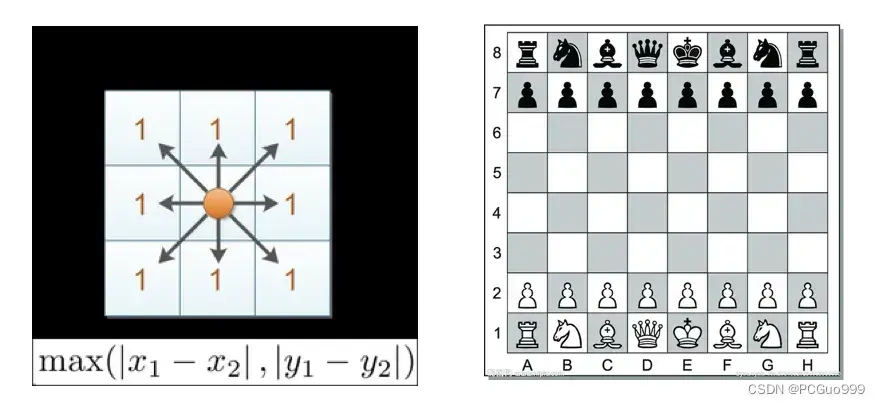
③切比雪夫距离—维度的最大值
国际象棋中,国王可以直行、横行、斜行,所以国王走一步可以移动到相邻8个方格中的任意一个。国王从格子(x1,y1)走到格子(x2,y2)最少需要多少步?这个距离就叫切比雪夫距离。
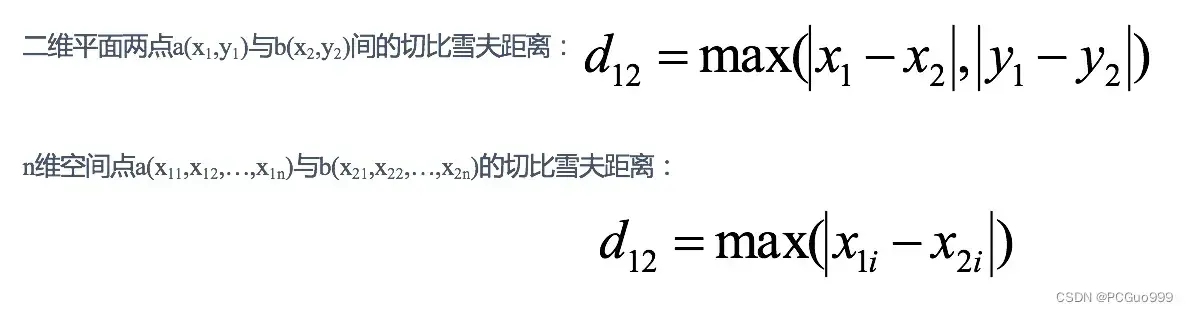
X=[[1,1],[2,2],[3,3],[4,4]];
经计算得:
d = 1 2 3 1 2 1
④闵可夫斯基距离
闵氏距离不是一种距离,而是一组距离的定义,是对多个距离度量公式的概括性的表述。
两个n维变量a(x11,x12,…,x1n)与b(x21,x22,…,x2n)间的闵可夫斯基距离定义为:
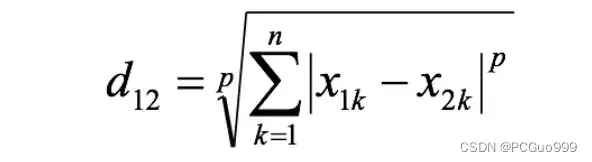
其中p是一个变参数:
-
当p=1时,就是曼哈顿距离;
-
当p=2时,就是欧氏距离;
-
当p→∞时,就是切比雪夫距离。
当次方为无穷时,即可等效为最大值
2 闵氏距离的缺点:
包括曼哈顿距离、欧氏距离和切比雪夫距离,都存在明显的缺点
(1)将各个分量的量纲(scale),也就是“单位”相同的看待了;
(2)未考虑各个分量的分布(期望,方差等)可能是不同的。
e.g. 二维样本(身高[单位:cm],体重[单位:kg]),现有三个样本:a(180,50),b(190,50),c(180,60)。
a与b的闵氏距离(无论是曼哈顿距离、欧氏距离或切比雪夫距离)等于a与c的闵氏距离。但实际上身高的10cm并不能和体重的10kg划等号。
(3) “连续属性”和“离散属性”的距离计算
我们常将属性划分为”连续属性” 和”离散属性”,前者在定义域上有无穷多个可能的取值,后者在定义域上是有限个取值.
- 若属性值之间存在序关系,则可以将其转化为连续值,例如:身高属性“高”“中等”“矮”,可转化为{1, 0.5, 0}。
- 闵可夫斯基距离可以用于有序属性。
- 若属性值之间不存在序关系,则通常将其转化为向量的形式,例如:性别属性“男”“女”,可转化为{(1,0),(0,1)}。
6.K值选择
- K值过小:
- 容易受到异常点的影响
- 容易过拟合(即在训练集上表现好,但是在测试集上不好)
- k值过大:
- 受到样本均衡的问题
- 容易欠拟合
K值选择问题,李航博士的一书「统计学习方法」上所说:
- 1)选择较小的K值,就相当于用较小的领域中的训练实例进行预测,
- “学习”近似误差会减小,只有与输入实例较近或相似的训练实例才会对预测结果起作用,与此同时带来的问题是“学习”的估计误差会增大,
- 换句话说,K值的减小就意味着整体模型变得复杂,容易发生过拟合;
- 2)选择较大的K值,就相当于用较大领域中的训练实例进行预测,
- 其优点是可以减少学习的估计误差,但缺点是学习的近似误差会增大。这时候,与输入实例较远(不相似的)训练实例也会对预测器作用,使预测发生错误。
- 且K值的增大就意味着整体的模型变得简单。
- 3)K=N(N为训练样本个数),则完全不足取,
- 因为此时无论输入实例是什么,都只是简单的预测它属于在训练实例中最多的类,模型过于简单,忽略了训练实例中大量有用信息。
- 在实际应用中,K值一般取一个比较小的数值,例如采用交叉验证法(简单来说,就是把训练数据在分成两组:训练集和验证集)来选择最优的K值。
误差
- 近似误差
- 对现有训练集的训练误差,关注训练集,
- 如果近似误差过小可能会出现过拟合的现象,对现有的训练集能有很好的预测,但是对未知的测试样本将会出现较大偏差的预测。
- 模型本身不是最接近最佳模型。
- 估计误差
- 可以理解为对测试集的测试误差,关注测试集,
- 估计误差小说明对未知数据的预测能力好,
- 模型本身最接近最佳模型。
7.KD树
为了提高kNN搜索的效率,可以考虑使用特殊的结构存储训练数据,以减小计算距离的次数。
kd树:为了避免每次都重新计算一遍距离,算法会把距离信息保存在一棵树里,这样在计算之前从树里查询距离信息,尽量避免重新计算。
根据KNN每次需要预测一个点时,我们都需要计算训练数据集里每个点到这个点的距离,然后选出距离最近的k个点进行投票。
当数据集很大时,这个计算成本非常高,针对N个样本,D个特征的数据集,其算法复杂度为O(D*N^2)。
优化后的算法复杂度可降低到O(DNlog(N))。
(1)原理—平衡二叉树
①树的建立
②最近邻域搜索(Nearest-Neighbor Lookup)
kd树(K-dimension tree)是**一种对k维空间中的实例点进行存储以便对其进行快速检索的树形数据结构。**kd树是一种二叉树,表示对k维空间的一个划分,构造kd树相当于不断地用垂直于坐标轴的超平面将K维空间切分,构成一系列的K维超矩形区域。kd树的每个结点对应于一个k维超矩形区域。
利用kd树可以省去对大部分数据点的搜索,从而减少搜索的计算量。
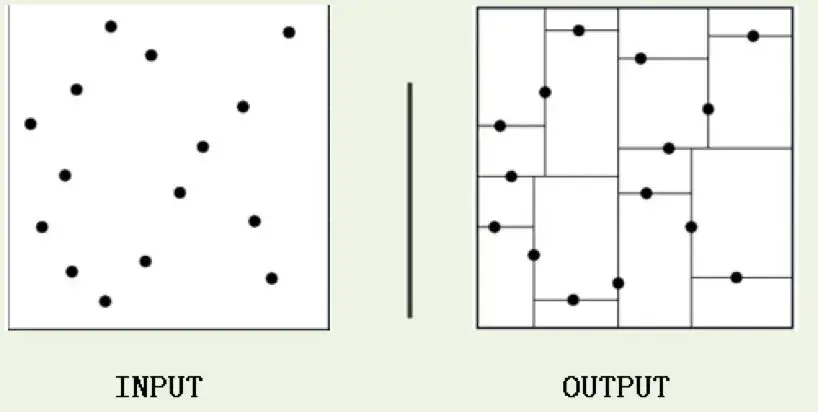
类比“二分查找”:给出一组数据:[9 1 4 7 2 5 0 3 8],要查找8。如果挨个查找(线性扫描),那么将会把数据集都遍历一遍。而如果排一下序那数据集就变成了:[0 1 2 3 4 5 6 7 8 9],按前一种方式我们进行了很多没有必要的查找,现在如果我们以5为分界点,那么数据集就被划分为了左右两个“簇” [0 1 2 3 4]和[6 7 8 9]。
因此,根本就没有必要进入第一个簇,可以直接进入第二个簇进行查找。把二分查找中的数据点换成k维数据点,这样的划分就变成了用超平面对k维空间的划分。空间划分就是对数据点进行分类,“挨得近”的数据点就在一个空间里面。
(2)构造方法
(1)构造根结点,使根结点对应于K维空间中包含所有实例点的超矩形区域;
(2)**通过递归的方法,不断地对k维空间进行切分,生成子结点。**在超矩形区域上选择一个坐标轴和在此坐标轴上的一个切分点,确定一个超平面,这个超平面通过选定的切分点并垂直于选定的坐标轴,将当前超矩形区域切分为左右两个子区域(子结点);这时,实例被分到两个子区域。
(3)上述过程直到子区域内没有实例时终止(终止时的结点为叶结点)。在此过程中,将实例保存在相应的结点上。
(4)通常,循环的选择坐标轴对空间切分,选择训练实例点在坐标轴上的中位数为切分点,这样得到的kd树是平衡二叉树
KD树中每个节点是一个向量,和二叉树按照数的大小划分不同的是,KD树每层需要选定向量中的某一维,然后根据这一维按左小右大的方式划分数据。
在构建KD树时,关键需要解决2个问题:
①选择向量的哪一维进行划分;
②如何划分数据;
第一个问题简单的解决方法可以是随机选择某一维或按顺序选择,但是更好的方法应该是在数据比较分散的那一维进行划分(分散的程度可以根据方差来衡量)。
第二个问题中,好的划分方法可以使构建的树比较平衡,可以每次选择中位数来进行划分。
(3)kd树的搜索过程
- 1**.二叉树搜索比较待查询节点和分裂节点的分裂维的值**,(小于等于就进入左子树分支,大于就进入右子树分支直到叶子结点)
- 2.顺着“搜索路径”找到最近邻的近似点
- 3.回溯搜索路径,并判断搜索路径上的结点的其他子结点空间中是否可能有距离查询点更近的数据点,如果有可能,则需要跳到其他子结点空间中去搜索
- 4.重复这个过程直到搜索路径为空
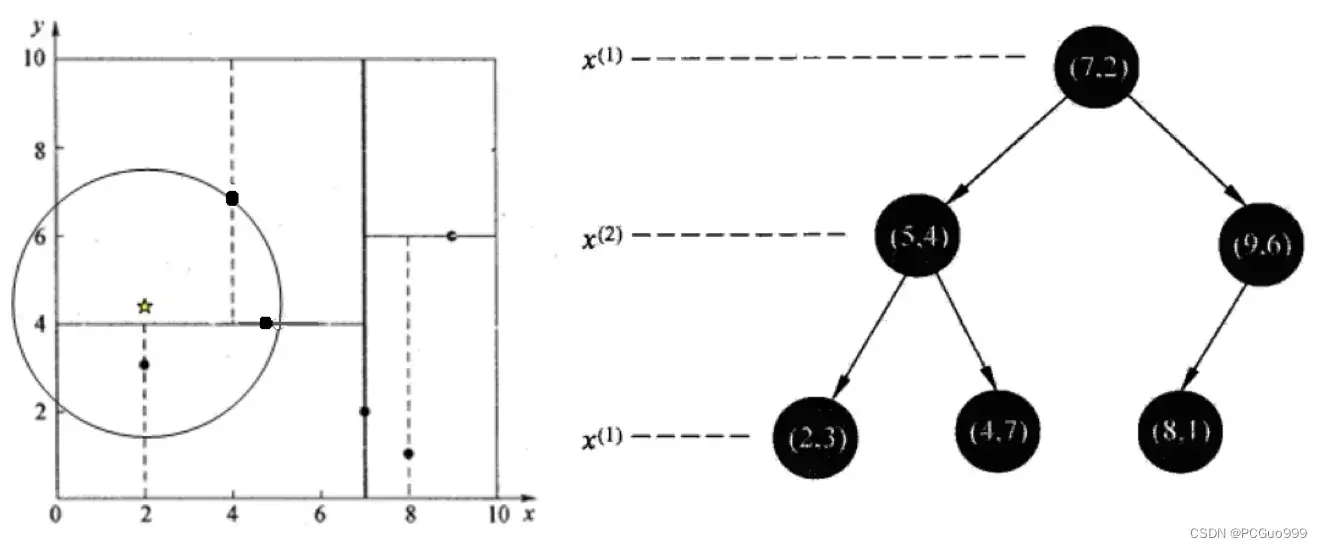
举个栗子:树的建立
给定一个二维空间数据集:T={(2,3),(5,4),(9,6),(4,7),(8,1),(7,2)},构造一个平衡kd树。
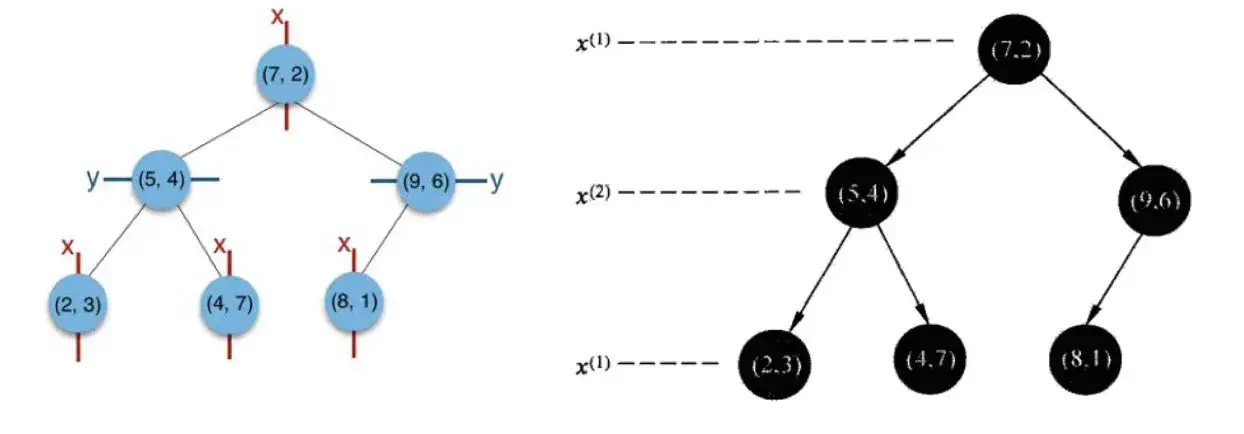
①思路引导:
- 因为x维度更分散,所以使用x(1)轴进行划分
- 中位数为6,最近的为(7,2)所以以平面x(1)=7将空间分为左、右两个子矩形(子结点)
- 2,4,5对应的y轴数据是:3,4,7。中位数是4,将4放到中间,3放到左边,7放到右边
- 8,9对应的y轴数据是:1,6
- 如此递归,最后得到如下图所示的特征空间划分和kd树。
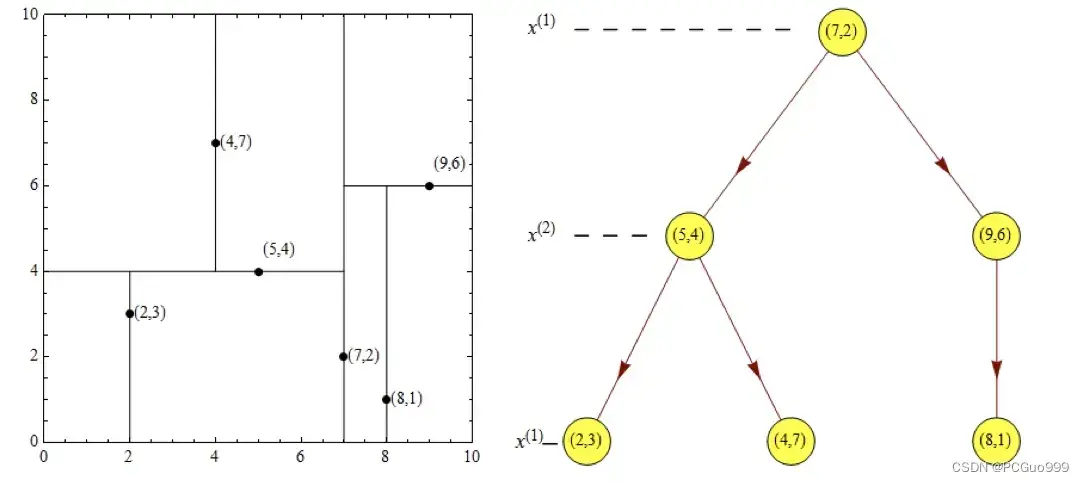
划分顺序1.紫色2.黄色3.黑色
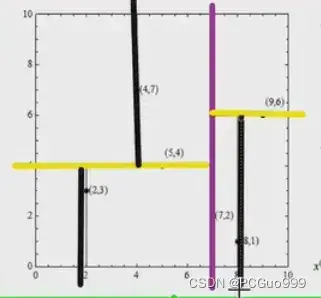
② 最近领域的搜索
假设标记为星星的点是 test point, 绿色的点是找到的近似点,在回溯过程中,需要用到一个队列,存储需要回溯的点,在判断其他子节点空间中是否有可能有距离查询点更近的数据点时,做法是以查询点为圆心,以当前的最近距离为半径画圆,这个圆称为候选超球(candidate hypersphere),如果圆与回溯点的轴相交,则需要将轴另一边的节点都放到回溯队列里面来。
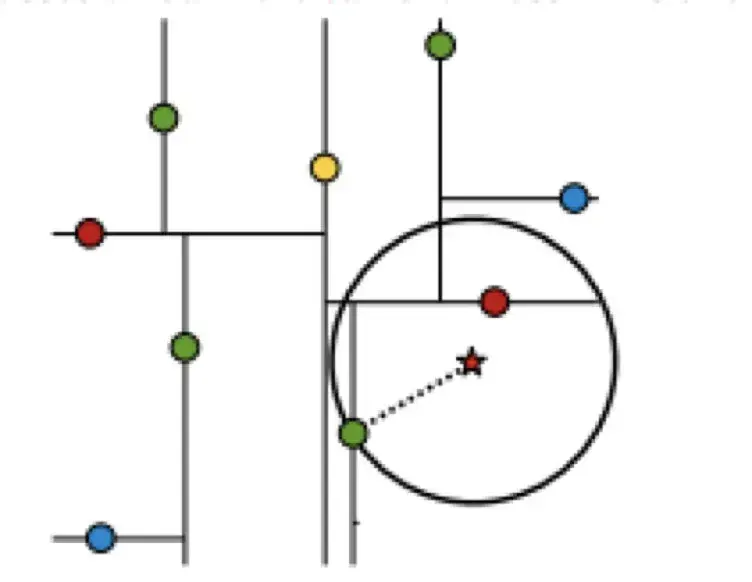
③eg:查找点(2,4.5)
- 先对比x轴,2比7小,来到左边
- 对比y轴,4.5比4小,来到右边,到达叶子结点,查找路径search_path中的结点为<(7,2),(5,4), (4,7)>
- 回溯找最近点:先拿叶子结点(4,7)当作最佳结点nearest,此时距离dist为3.202;
- 向上回溯,到(5,4),以(2,4.5)为圆心,以dist=3.202为半径画一个圆与超平面y=4相交,所以需要跳到(5,4)的左子空间去搜索。所以要将(2,3)加入到search_path中,现在search_path中的结点为<(7,2),(2, 3)>;另外,(5,4)与(2,4.5)的距离为3.04 < dist = 3.202,所以将(5,4)赋给nearest,并且dist=3.04。
- 回溯至(2,3),(2,3)是叶子节点,直接平判断(2,3)是否离(2,4.5)更近,计算得到距离为1.5,所以nearest更新为(2,3),dist更新为(1.5)
- 回溯至(7,2),同理,以(2,4.5)为圆心,以dist=1.5为半径画一个圆并不和超平面x=7相交, 所以不用跳到结点(7,2)的右子空间去搜索。
- 至此,search_path为空,结束整个搜索,返回nearest(2,3)作为(2,4.5)的最近邻点,最近距离为1.5。
二、案例1:鸢尾花种类预测–数据集介绍
1.数据集介绍

2 scikit-learn中数据集介绍
(1)scikit-learn数据集API介绍
- sklearn.datasets
- 加载获取流行数据集
- datasets.load_*()
- 获取小规模数据集,数据包含在datasets里
- datasets.fetch_*(data_home=None)
- 获取大规模数据集,需要从网络上下载,函数的第一个参数是data_home,表示数据集下载的目录,默认是 ~/scikit_learn_data/
返回值类型是bunch–是一个字典类型
(2)sklearn小数据集
-
sklearn.datasets.load_iris()
加载并返回鸢尾花数据集
from sklearn.datasets import load_iris
iris = load_iris()
print(iris)
(3)sklearn大数据集
- sklearn.datasets.fetch_20newsgroups(data_home=None,subset=‘train’)
- subset:‘train’或者’test’,‘all’,可选,选择要加载的数据集。
- 训练集的“训练”,测试集的“测试”,两者的“全部”
from sklearn.datasets import load_iris
news = fetch_20newsgroups()
print(news)
(4)sklearn数据集返回值介绍
- load和fetch返回的数据类型datasets.base.Bunch(字典格式)
- data:特征数据数组,是 [n_samples * n_features] 的二维 numpy.ndarray 数组
- target:标签数组,是 n_samples 的一维 numpy.ndarray 数组
- DESCR:数据描述
- feature_names:特征名,新闻数据,手写数字、回归数据集没有
- target_names:标签名
from sklearn.datasets import load_iris
# 获取鸢尾花数据集
iris = load_iris()
print("鸢尾花数据集的返回值:\n", iris)
# 返回值类型是bunch--是一个字典类型
print("鸢尾花数据集特征值是:",iris["data"])
# 既可以使用[]输出也可以使用.输出
# print("数据集特征值是:",iris.data)
print("鸢尾花数据集目标值是:",iris.target)
print("鸢尾花数据集特征值名字是:",iris.feature_names)
print("鸢尾花数据集目标值名字是:",iris.target_names)
print("鸢尾花数据集的描述是:",iris.DESCR)
(5)查看数据分布
通过创建一些图,以查看不同类别是如何通过特征来区分的。 在理想情况下,标签类将由一个或多个特征对完美分隔。 在现实世界中,这种理想情况很少会发生。
seaborn介绍
- Seaborn 是基于 Matplotlib 核心库进行了更高级的 API 封装,可以让你轻松地画出更漂亮的图形。而 Seaborn 的漂亮主要体现在配色更加舒服、以及图形元素的样式更加细腻。
- 安装 pip3 install seaborn
- seaborn.lmplot() 是一个非常有用的方法,它会在绘制二维散点图时,自动完成回归拟合
- sns.lmplot() 里的 x, y 分别代表横纵坐标的列名,
- data= 是关联到数据集,
- hue=*代表按照 species即花的类别分类显示,
- fit_reg=是否进行线性拟合。
import seaborn as sns
import matplotlib.pyplot as plt
import pandas as pd
from sklearn.datasets import load_iris
# 设置显示中文字体
plt.rcParams["font.sans-serif"] = ["SimHei"]
# 获取数据集
iris = load_iris()
# 图像可视化
# 把数据转换成dataframe的格式
iris_d = pd.DataFrame(iris['data'], columns = ['Sepal_Length', 'Sepal_Width', 'Petal_Length', 'Petal_Width'])
# # 输出二维数组表格
# print(iris_d)
# 种类
iris_d['Species'] = iris.target
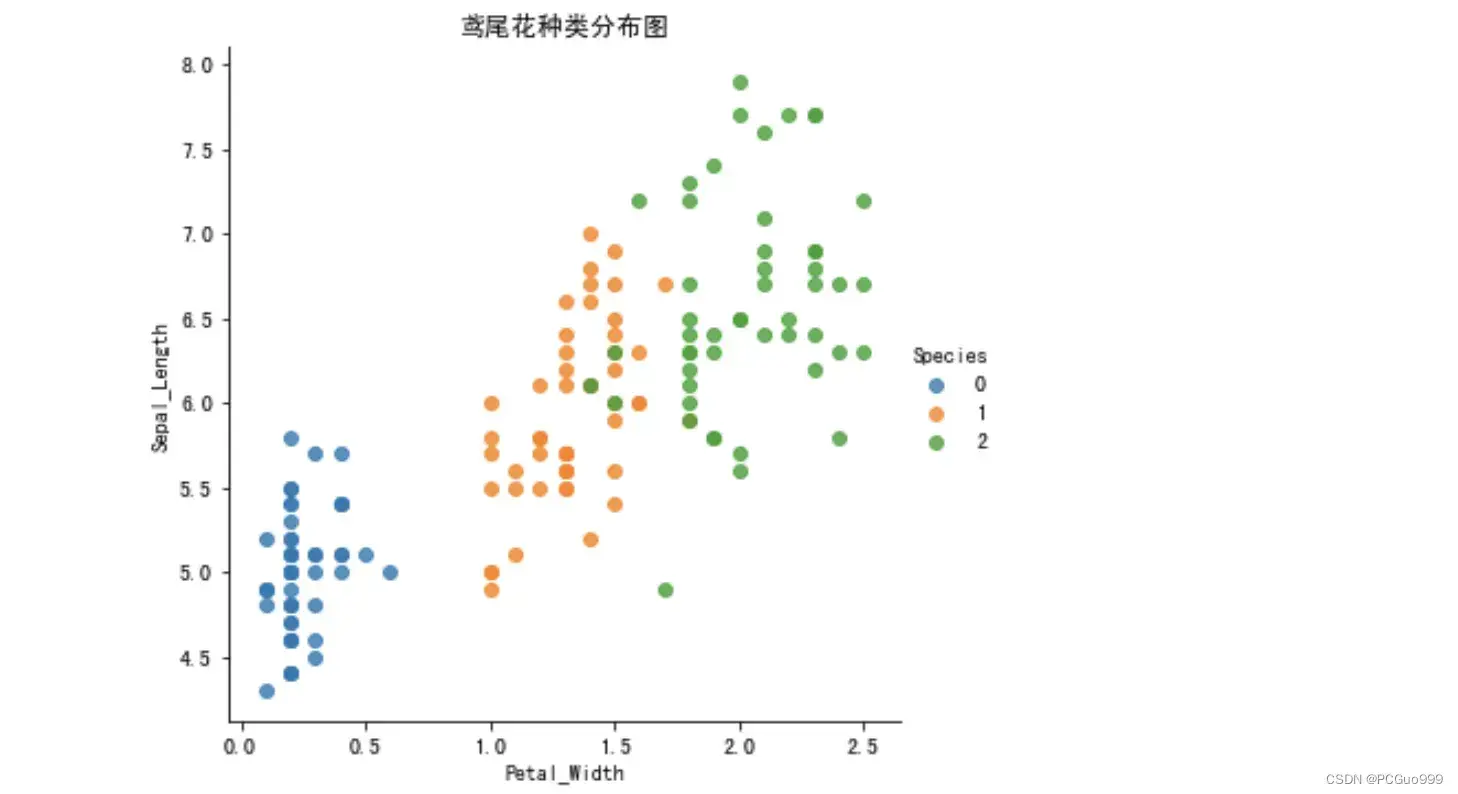
def plot_iris(iris, col1, col2):
# hue表示目标值,fit_reg = False表示不线性拟合,即不要线段
sns.lmplot(x = col1, y = col2, data = iris, hue = "Species", fit_reg = False)
# x,y轴标签
plt.xlabel(col1)
plt.ylabel(col2)
# 表格标题
plt.title('鸢尾花种类分布图')
plt.show()
plot_iris(iris_d, 'Petal_Width', 'Sepal_Length')
(6)数据集的划分—train_test_split(arrays, *options)
机器学习一般的数据集会划分为两个部分:
- 训练数据:用于训练,构建模型
- 测试数据:在模型检验时使用,用于评估模型是否有效
划分比例:
- 训练集:70% 80% 75%
- 测试集:30% 20% 25%
数据集划分api
sklearn.model_selection.train_test_split(arrays, *options)- 参数:
- x 数据集的特征值
- y 数据集的标签值
- test_size 测试集的大小,一般为float,比如测试集是0.2,则表示测试集是20%,那么训练集是0.8,即80%
- random_state 随机数种子,不同的种子会造成不同的随机采样结果。相同的种子采样结果相同。
- return
- x_train, x_test, y_train, y_test
- 对应:特征值训练集,特征值的测试集,目标值的训练集,目标值的测试集
- 参数:
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
# 1.获取鸢尾花数据集
iris = load_iris()
# 2.对鸢尾花数据集进行分割
# 训练集的特征值x_train 测试集的特征值x_test 训练集的目标值y_train 测试集的目标值y_test。test_size=0.2,训练集是0.2,则测试集是0.8
x_train, x_test, y_train, y_test = train_test_split(iris.data, iris.target, test_size=0.2, random_state=22)
# print("训练集特征值:\n",x_train)
# print("训练集目标值:\n",y_train)
# print("测试集特征值:\n",x_test)
# print("测试集目标值:\n",y_test)
# 可以通过.shape看形状,测试集30,训练集120
print("x_train:\n", x_train.shape) #x_train:(120, 4)
print("x_test:\n", x_test.shape) #x_test:(30, 4)
# 2.2随机数种子不同的情况下结果不同
x_train1, x_test1, y_train1, y_test1 = train_test_split(iris.data, iris.target, test_size=0.2, random_state=6)
x_train2, x_test2, y_train2, y_test2 = train_test_split(iris.data, iris.target, test_size=0.2, random_state=6)
print("如果随机数种子不一致:\n", x_train == x_train1)
print("如果随机数种子一致:\n", x_train1 == x_train2)
# 输出结果:
# 如果随机数种子不一致:
# [[ True False False False]
# [False False False False]
# [False False False False]
# [False False False False]...
# 如果随机数种子一致:
# [[ True True True True]
# [ True True True True]
# [ True True True True]
# [ True True True True]...
三、特征工程-特征预处理
1.特征预处理
通过一些转换函数将特征数据转换成更加适合算法模型的特征数据过程。
2.归一化/标准化
(1)为什么需要归一化/标准化?
特征的单位或者大小相差较大,或者某特征的方差相比其他的特征要大出几个数量级,容易影响(支配)目标结果,使得一些算法无法学习到其它的特征
我们需要用到一些方法进行无量纲化,使不同规格的数据转换到同一规格
(2)包含内容(数值型数据的无量纲化)
①最小值最大值归一化处理—MinMaxScaler()
定义:
- 对原始数据进行变换把数据映射到(默认为[0,1])之间
公式:
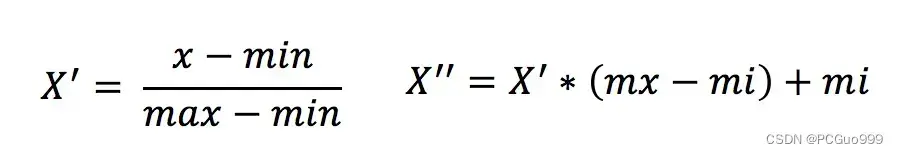
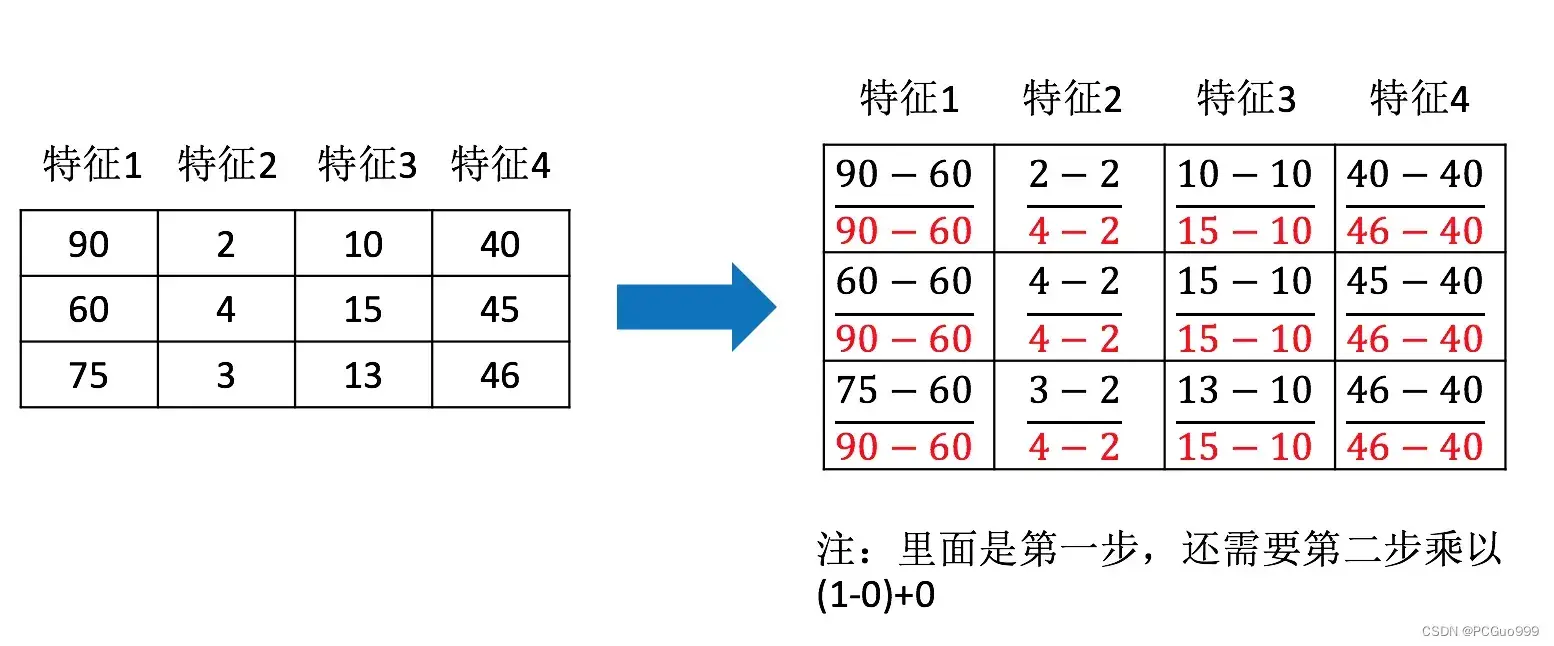
作用于每一列,max为一列的最大值,min为一列的最小值,那么X’’为最终结果,mx,mi分别为指定区间值默认mx为1,mi为0
举例:
api:
- 实例化一个转换器类
sklearn.preprocessing.MinMaxScaler (feature_range=(0,1)… ) - 参数:feature_range – 自己指定范围,默认0-1
- 归一化转换:
MinMaxScalar.fit_transform(X)- X:numpy array格式的数据[n_samples,n_features]
- 返回值:转换后的形状相同的array
数据:dating.txt
milage,Liters,Consumtime,target
40920,8.326976,0.953952,3
14488,7.153469,1.673904,2
26052,1.441871,0.805124,1
75136,13.147394,0.428964,1
38344,1.669788,0.134296,1
步骤分析
1、实例化MinMaxScalar
2、通过fit_transform转换
import pandas as pd
from sklearn.preprocessing import MinMaxScaler
# 归一化
def MinMax_Test():
# 获取数据
data = pd.read_csv("./data/dating.txt")
print(data)
# 1.实例化一个转换器类
transfer = MinMaxScaler(feature_range=(0, 1))
# 2、调用fit_transform
data = transfer.fit_transform(data[['milage', 'Liters', 'Consumtime']])
print("最小值最大值归一化处理的结果:\n", data)
return None
MinMax_Test()
返回结果:
milage Liters Consumtime target
0 40920 8.326976 0.953952 3
1 14488 7.153469 1.673904 2
2 26052 1.441871 0.805124 1
3 75136 13.147394 0.428964 1
4 38344 1.669788 0.134296 1
最小值最大值归一化处理的结果:
[[0.43582641 0.58819286 0.53237967]
[0. 0.48794044 1. ]
[0.19067405 0. 0.43571351]
[1. 1. 0.19139157]
[0.3933518 0.01947089 0. ]]
总结:
- 鲁棒性比较差(容易受到异常点的影响)
- 只适合传统精确小数据场景(以后不会用你了)
②标准化—StandardScaler()
定义:
- 对原始数据进行变换把数据变换到均值为0,标准差为1范围内
公式:
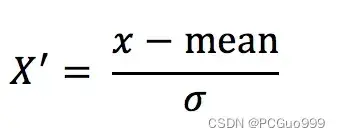
作用于每一列,mean为平均值,σ为标准差
api:
-
实例化一个转换器类:
sklearn.preprocessing.StandardScaler( )- 处理之后每列来说所有数据都聚集在均值0附近标准差差为1
-
表转化转换:
StandardScaler.fit_transform(X)-
X:numpy array格式的数据[n_samples,n_features]
-
返回值:转换后的形状相同的array
-
步骤分析
1、实例化MinMaxScalar
2、通过fit_transform转换
import pandas as pd
from sklearn.preprocessing import StandardScaler
def Standard_Test():
# 获取数据
data=pd.read_csv("./data/dating.txt")
print(data)
# 1.实例化一个转换器类
transfer = StandardScaler()
# 2.调用fit_transform
data = transfer.fit_transform(data[['milage','Liters','Consumtime']])
print("标准化的结果:\n", data)
print("每一列特征的平均值:\n", transfer.mean_)
print("每一列特征的方差:\n", transfer.var_)
return None
Standard_Test()
milage Liters Consumtime target
0 40920 8.326976 0.953952 3
1 14488 7.153469 1.673904 2
2 26052 1.441871 0.805124 1
3 75136 13.147394 0.428964 1
4 38344 1.669788 0.134296 1
标准化的结果:
[[ 0.0947602 0.44990013 0.29573441]
[-1.20166916 0.18312874 1.67200507]
[-0.63448132 -1.11527928 0.01123265]
[ 1.77297701 1.54571769 -0.70784025]
[-0.03158673 -1.06346729 -1.27113187]]
每一列特征的平均值:
[3.8988000e+04 6.3478996e+00 7.9924800e-01]
每一列特征的方差:
[4.15683072e+08 1.93505309e+01 2.73652475e-01]
总结:
-
异常值影响小
-
适合现代嘈杂大数据场景(以后就是用你了)
-
对于归一化来说:如果出现异常点,影响了最大值和最小 值,那么结果显然会发生改变
-
对于标准化来说:如果出现异常点,由于具有一定数据量,少量的异常点对于平均值的影响并不大,从而方差改变较小。
四、案例1:鸢尾花种类预测–流程实现
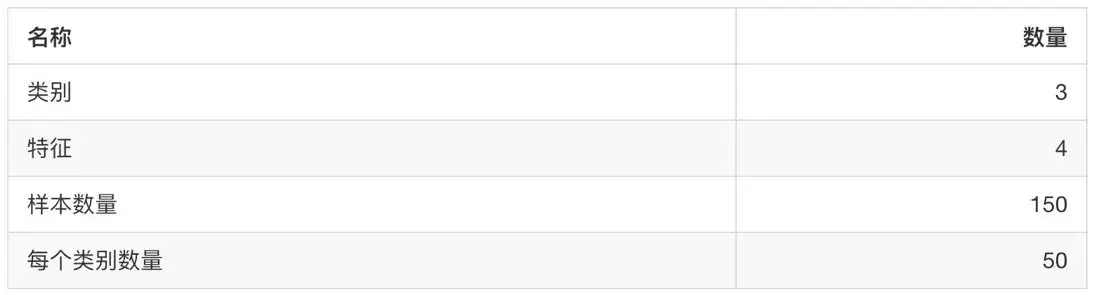
1.数据集介绍
实例属性:150(三个类各有50个)
属性数量:4(数值型、数值型、帮助预测的属性和类)
属性信息:
- sepal length 萼片长度
- sepal width 萼片宽度
- petal length 花瓣长度
- petal width 花瓣宽度
- class:
- Iris-Setosa 山鸢尾
- Iris-Versicolour 变色鸢尾
- Iris-Virginica 维吉尼亚鸢尾
2.步骤分析
- 1.获取数据集
- 2.数据基本处理
- 3.特征工程
- 4.机器学习(模型训练)
- 5.模型评估
# 导入模块
# 鸢尾花数据
from sklearn.datasets import load_iris
# 分割数据集
from sklearn.model_selection import train_test_split
# 特征预处理
from sklearn.preprocessing import StandardScaler
# KNN API
from sklearn.neighbors import KNeighborsClassifier
# 1.获取数据集
iris = load_iris()
# 2.数据基本处理
# x_train,x_test,y_train,y_test为训练集特征值、测试集特征值、训练集目标值、测试集目标值
x_train, x_test, y_train, y_test = train_test_split(iris.data, iris.target, test_size=0.2, random_state=22)
# 3.特征工程:标准化
# 实例化
transfer = StandardScaler()
# 转换标准化
x_train = transfer.fit_transform(x_train)
x_test = transfer.transform(x_test)
# 4.机器学习(KNN模型训练)
# 实例化一个估计器
estimator = KNeighborsClassifier(n_neighbors=9)
# 模型训练fit方法
estimator.fit(x_train, y_train)
# 5.模型评估
# 预测值结果输出:比对真实值和预测值
y_predict = estimator.predict(x_test)
print("预测结果为:\n", y_predict)
print("比对真实值和预测值:\n", y_predict == y_test)
# 准确率计算
score = estimator.score(x_test, y_test)
print("准确率为:\n", score)
预测结果为:
[0 2 1 2 1 1 1 1 1 0 2 1 2 2 0 2 1 1 1 1 0 2 0 1 2 0 2 2 2 2]
比对真实值和预测值:
[ True True True True True True True False True True True True
True True True True True True False True True True True True
True True True True True True]
准确率为:
0.9333333333333333
扩展:fit_transform,fit,transform区别和作用
fit和transform没有任何关系,仅仅是数据处理的两个不同环节,之所以出来fit_transform这个函数名,仅仅是为了写代码方便,会高效一点。
sklearn里的封装好的各种算法使用前都要fit,fit相对于整个代码而言,为后续API服务。fit之后,然后调用各种API方法,transform只是其中一个API方法,所以当你调用transform之外的方法,也必须要先fit。
fit原义指的是安装、使适合的意思,其实有点train的含义,但是和train不同的是,它并不是一个训练的过程,而是一个适配的过程,过程都是确定的,最后得到一个可用于转换的有价值的信息。
-
fit():
简单来说,就是求得训练集X的均值,方差,最大值,最小值,这些训练集X固有的属性。
-
transform():
在fit的基础上,进行标准化,降维,归一化等操作(看具体用的是哪个工具,如PCA,StandardScaler等)。
-
fit_transform():
fit_transform是fit和transform的组合,既包括了训练又包含了转换。
-
transform()和fit_transform()
二者的功能都是对数据进行某种统一处理(比如标准化~N(0,1),将数据缩放(映射)到某个固定区间,归一化,正则化等)
fit_transform(trainData)对部分数据先拟合fit,找到该part的整体指标,如均值、方差、最大值最小值等等(根据具体转换的目的),然后对该trainData进行转换transform,从而实现数据的标准化、归一化等等。
五、k近邻算法优缺点
1.优点
(1)简单有效
(2)重新训练的代价低
(3)适合类域交叉样本
KNN方法主要靠周围有限的邻近的样本,而不是靠判别类域的方法来确定所属类别的,因此对于类域的交叉或重叠较多的待分样本集来说,KNN方法较其他方法更为适合。
(4)适合大样本自动分类
该算法比较适用于样本容量比较大的类域的自动分类,而那些样本容量较小的类域采用这种算法比较容易产生误分。
2.缺点
(1)惰性学习
KNN算法是懒散学习方法(lazy learning,基本上不学习),一些积极学习的算法要快很多
(2)类别评分不是规格化
不像一些通过概率评分的分类
(3)输出可解释性不强
例如决策树的输出可解释性就较强
(4)对不均衡的样本不擅长
当样本不平衡时,如一个类的样本容量很大,而其他类样本容量很小时,有可能导致当输入一个新样本时,该样本的K个邻居中大容量类的样本占多数。该算法只计算“最近的”邻居样本,某一类的样本数量很大,那么或者这类样本并不接近目标样本,或者这类样本很靠近目标样本。无论怎样,数量并不能影响运行结果。可以采用权值的方法(和该样本距离小的邻居权值大)来改进。
(5)计算量较大
目前常用的解决方法是事先对已知样本点进行剪辑,事先去除对分类作用不大的样本。
六、交叉验证、网格搜索
1.介绍
之前将数据分为训练集和测试集,但是为了让从训练得到模型结果更加准确。又将拿到的训练数据,分为训练和验证集。
- 训练集:训练集+验证集
- 测试集:测试集
4折交叉验证:
将数据分成4份,其中1份作为验证集。然后经过4次(组)的测试,每次都更换不同的验证集。即得到4组模型的结果,取平均值作为最终结果。

交叉验证目的:为了让被评估的模型更加准确可信,并不能提高模型准确率,想要选择或者调优参数,需要使用网格搜索
2.网格搜索
通常情况下,有很多参数是需要手动指定的(如k-近邻算法中的K值),这种叫超参数。
网格搜索就是把这些超参数的值,通过字典的形式传递进去,每组超参数都采用交叉验证来进行评估。最后选出最优参数组合建立模型。

3.交叉验证,网格搜索(模型选择与调优)API
sklearn.model_selection.GridSearchCV(estimator, param_grid=None,cv=None)
-
对估计器的指定参数值进行详尽搜索
参数
-
estimator:估计器对象
-
param_grid:估计器参数(dict){“n_neighbors”:[3,5,7]}
-
cv:指定几折交叉验证
-
fit:输入训练数据
-
score:准确率
-
属性:
- bestscore__:在交叉验证中验证的最好结果
- bestestimator:最好的参数模型
- cvresults:每次交叉验证后的验证集准确率结果和训练集准确率结果
4.鸢尾花案例增加K值调优
只用将之前KNeighborsClassifier()中的参数删除,并手动添加超参数进行交叉验证
之前:
# 实例化一个估计器
estimator = KNeighborsClassifier(n_neighbors=9)
现在:
# 实例化一个估计器
estimator = KNeighborsClassifier()
# 模型选择与调优——网格搜索和交叉验证
# 准备要调的超参数
param_dict = {"n_neighbors": [1, 3, 5]}
estimator = GridSearchCV(estimator, param_grid=param_dict, cv=3)
全部代码:
# 导入模块
# 鸢尾花数据
from sklearn.datasets import load_iris
# 分割数据集,网格搜索和交叉验证
from sklearn.model_selection import train_test_split, GridSearchCV
# 特征预处理
from sklearn.preprocessing import StandardScaler
# KNN API
from sklearn.neighbors import KNeighborsClassifier
# 1.获取数据集
iris = load_iris()
# 2.数据基本处理
# x_train,x_test,y_train,y_test为训练集特征值、测试集特征值、训练集目标值、测试集目标值
x_train, x_test, y_train, y_test = train_test_split(iris.data, iris.target, test_size=0.2, random_state=22)
# 3.特征工程:标准化
# 实例化
transfer = StandardScaler()
# 转换标准化
x_train = transfer.fit_transform(x_train)
x_test = transfer.transform(x_test)
# 4.机器学习(KNN模型训练)
# 实例化一个估计器
estimator = KNeighborsClassifier()
# 增加:
# 模型选择与调优——网格搜索和交叉验证
# 准备要调的超参数
param_dict = {"n_neighbors": [1, 3, 5]}
estimator = GridSearchCV(estimator, param_grid=param_dict, cv=3)
# 模型训练fit方法
estimator.fit(x_train, y_train)
# 5.模型评估
# 预测值结果输出:比对真实值和预测值
y_predict = estimator.predict(x_test)
print("预测结果为:\n", y_predict)
print("比对真实值和预测值:\n", y_predict == y_test)
# 准确率计算
score = estimator.score(x_test, y_test)
print("准确率为:\n", score)
# 评估查看最终选择的结果和交叉验证的结果
print("在交叉验证中验证的最好结果:\n", estimator.best_score_)
print("最好的参数模型:\n", estimator.best_estimator_)
print("每次交叉验证后的准确率结果:\n", estimator.cv_results_)
# 输出结果:
预测结果为:
[0 2 1 2 1 1 1 1 1 0 2 1 2 2 0 2 1 1 1 1 0 2 0 1 2 0 2 2 2 2]
比对真实值和预测值:
[ True True True True True True True False True True True True
True True True True True True False True True True True True
True True True True True True]
准确率为:
0.9333333333333333
在交叉验证中验证的最好结果:
0.975
最好的参数模型:
KNeighborsClassifier()
每次交叉验证后的准确率结果:
{'mean_fit_time': array([0.00199429, 0.00133077, 0.00066384]), 'std_fit_time': array([0.00081323, 0.00046957, 0.00046941]), 'mean_score_time': array([0.00533168, 0.00366902, 0.00198976]), 'std_score_time': array([0.0012504 , 0.0004784 , 0.00081452]), 'param_n_neighbors': masked_array(data=[1, 3, 5],mask=[False, False, False],fill_value='?',dtype=object), 'params': [{'n_neighbors': 1}, {'n_neighbors': 3}, {'n_neighbors': 5}], 'split0_test_score': array([1. , 0.975, 1. ]), 'split1_test_score': array([0.925, 0.975, 0.975]), 'split2_test_score': array([0.95, 0.9 , 0.95]), 'mean_test_score': array([0.95833333, 0.95 , 0.975 ]), 'std_test_score': array([0.03118048, 0.03535534, 0.02041241]), 'rank_test_score': array([2, 3, 1])}
可以明显看到准确率提高
之前准确率为:0.9333333333333333
在交叉验证中验证的最好结果: 0.975
注:当数据集过大时,超参数尽量不要选则太多,否则跑起来非常慢,效果非常低
七、案例2:预测facebook签到位置kaggle
1.项目介绍
本次比赛的目的是预测一个人将要签到的地方。 为了本次比赛,Facebook创建了一个虚拟世界,其中包括10公里*10公里共100平方公里的约10万个地方。 对于给定的坐标集,您的任务将根据用户的位置,准确性和时间戳等预测用户下一次的签到位置。 数据被制作成类似于来自移动设备的位置数据。 请注意:您只能使用提供的数据进行预测。
数据从kaggle获取,官网:https://www.kaggle.com/c/facebook-v-predicting-check-ins
2.数据集介绍
文件说明:train.csv, test.csv
-
训练.csv、测试.csv
- row_id:签到事件的id
- xy:坐标
- 精度:定位精度
- 时间:时间戳,是指格林威治时间1970年01月01日00时00分00秒(北京时间1970年01月01日08时00分00秒)起至现在的总秒数
- place_id:签到的id,这是你需要预测的目标
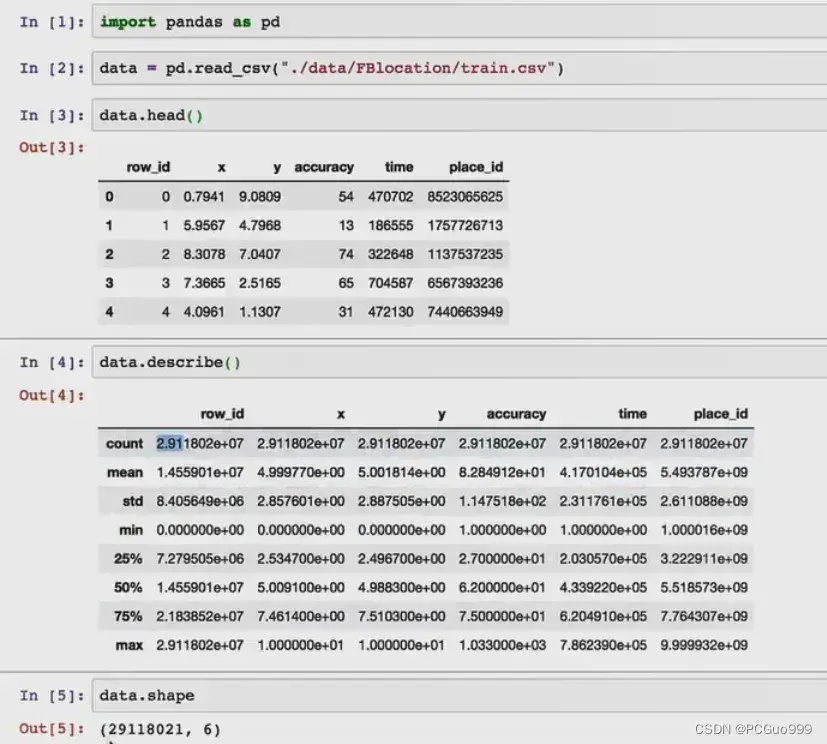
3.步骤分析
- 对于数据做一些基本处理(这里所做的一些处理不一定达到很好的效果,我们只是简单尝试,有些特征我们可以根据一些特征选择的方式去做处理)
- 1 缩小数据集范围 DataFrame.query()
- 2 选取有用的时间特征
- 3 将签到位置少于n个用户的删除
- 分割数据集
- 标准化处理
- k-近邻预测
import pandas as pd
from sklearn.model_selection import train_test_split, GridSearchCV
from sklearn.neighbors import KNeighborsClassifier
from sklearn.preprocessing import StandardScaler
# 1.获取数据集
facebook = pd.read_csv("data/FaceBook-predicting-check-ins/train.csv")
# 2.基本数据处理
# 2.1 缩小数据范围,选择x>2.0 & x<2.5 & y>2.0 & y<2.5的数据
facebook_data = facebook.query("x>2.0 & x<2.5 & y>2.0 & y<2.5")
# 2.2 选择时间特征,因为数据中时间是时间戳,所以转换成时间
time = pd.to_datetime(facebook_data["time"], unit="s")
time = pd.DatetimeIndex(time)
facebook_data["day"] = time.day
facebook_data["hour"] = time.hour
facebook_data["weekday"] = time.weekday
# 2.3 去掉签到较少的地方
place_count = facebook_data.groupby("place_id").count()
place_count = place_count[place_count["row_id"]>3]
facebook_data = facebook_data[facebook_data["place_id"].isin(place_count.index)]
# 2.4 确定特征值和目标值
x = facebook_data[["x", "y", "accuracy", "day", "hour", "weekday"]]
y = facebook_data["place_id"]
# 2.5 分割数据集
x_train, x_test, y_train, y_test = train_test_split(x, y, random_state=22)
# 3.特征工程 -- 特征预处理(标准化)
transfer = StandardScaler()
x_train = transfer.fit_transform(x_train)
x_test = transfer.transform(x_test)
# 4.机器学习 -- knn+cv
# 4.1 实例化一个估计器
estimator = KNeighborsClassifier()
# 4.2 调用gridsearchCV
param_grid = {"n_neighbors": [1, 3, 5, 7, 9]}
# 因为需要测试15次,n_jobs指定用几个CPU进行跑,n_jobs=-1表示用所有的CPU跑程序,n_jobs=k表示用k个CPU跑程序
# 比如电脑是8核CPU,那么可以设置到8,推荐设置为6或者7
estimator = GridSearchCV(estimator, param_grid=param_grid, cv=5,n_jobs=-1)
# 4.3 模型训练
estimator.fit(x_train, y_train)
# 5.模型评估
# 5.1 基本评估方式
score = estimator.score(x_test, y_test)
print("最后预测的准确率为:\n", score)
y_predict = estimator.predict(x_test)
print("最后的预测值为:\n", y_predict)
print("预测值和真实值的对比情况:\n", y_predict == y_test)
# 5.2 使用交叉验证后的评估方式
print("在交叉验证中验证的最好结果:\n", estimator.best_score_)
print("最好的参数模型:\n", estimator.best_estimator_)
print("每次交叉验证后的验证集准确率结果和训练集准确率结果:\n",estimator.cv_results_)
# 输出结果:
最后预测的准确率为:
0.36515361515361516
最后的预测值为:
[9983648790 6329243787 9674001925 ... 2990018952 4830766946 7065571836]
预测值和真实值的对比情况:
24703810 True
19445902 False
18490063 True
7762709 False
6505956 False
...
27632888 False
23367671 False
6692268 True
25834435 False
13319005 False
Name: place_id, Length: 17316, dtype: bool
在交叉验证中验证的最好结果:
0.3546044971864908
最好的参数模型:
KNeighborsClassifier(n_neighbors=1)
每次交叉验证后的验证集准确率结果和训练集准确率结果:
{'mean_fit_time': array([0.20372453, 0.13444033, 0.12627945, 0.1162303 , 0.14007068]), 'std_fit_time': array([0.03891364, 0.03487368, 0.01710955, 0.00849831, 0.01045492]), 'mean_score_time': array([0.84785113, 0.81870608, 0.66817446, 0.85298319, 0.77952976]), 'std_score_time': array([0.01394286, 0.15851887, 0.01958566, 0.10105889, 0.05515816]), 'param_n_neighbors': masked_array(data=[1, 3, 5, 7, 9],mask=[False, False, False, False, False],fill_value='?',dtype=object), 'params': [{'n_neighbors': 1}, {'n_neighbors': 3}, {'n_neighbors': 5}, {'n_neighbors': 7}, {'n_neighbors': 9}], 'split0_test_score': array([0.35948027, 0.34311838, 0.35235804, 0.35303176, 0.34927815]), 'split1_test_score': array([0.35466795, 0.34369586, 0.35563041, 0.35370549, 0.34821944]), 'split2_test_score': array([0.35524543, 0.34119346, 0.3506256 , 0.35129933, 0.34860443]), 'split3_test_score': array([0.3514294 , 0.34141881, 0.35681971, 0.35537588, 0.35075561]), 'split4_test_score': array([0.35219944, 0.34161132, 0.35152565, 0.34757917, 0.34132255]), 'mean_test_score': array([0.3546045 , 0.34220757, 0.35339188, 0.35219832, 0.34763604]), 'std_test_score': array([0.00283032, 0.00100506, 0.00240687, 0.00265359, 0.00327312]), 'rank_test_score': array([1, 5, 2, 3, 4])}
八、扩展:再议数据分割
前面已经讲过,我们可通过实验测试来对学习器的泛化误差进行评估并进而做出选择。
为此,需使用一个“测试集”( testing set)来测试学习器对新样本的判别能力,然后以测试集上的“测试误差” (testing error)作为泛化误差的近似。
通常我们假设测试样本也是从样本真实分布中独立同分布采样而得。但需注意的是,测试集应该尽可能与训练集互斥。
那如何将数据集进行适当处理,划分出训练集S和测试集T,常见的方法有以下几种:
- 留出法
- 交叉验证法
- 自助法
1.留出法
“留出法”(hold-out)直接将数据集D划分为两个互斥的集合,其中一个集合作为训练集S,另一个作为测试集T
常见做法是将大约2/3~4/5的样本用于训练,剩余样本用于测试
代码如二、2、(6)
from sklearn.model_selection import train_test_split
#使用train_test_split划分训练集和测试集
train_X , test_X, train_Y ,test_Y = train_test_split(
X, Y, test_size=0.2,random_state=0)
留一法:
即每次抽取一个样本做为测试集
显然,留一法不受随机样本划分方式的影响,因为m个样本只有唯一的方式划分为m个子集一每个子集包含个样本;
from sklearn.model_selection import LeaveOneOut
data = [1, 2, 3, 4]
loo = LeaveOneOut()
for train, test in loo.split(data):
print("%s %s" % (train, test))
# 输出结果
[1 2 3] [0]
[0 2 3] [1]
[0 1 3] [2]
[0 1 2] [3]
留一法优缺点:
优点:
- 留一法使用的训练集与初始数据集相比只少了一个样本,这就使得在绝大多数情况下,留一法中被实际评估的模型与期望评估的用D训练出的模型很相似。因此,留一法的评估结果往往被认为比较准确。
缺点:
- 留一法也有其缺陷:在数据集比较大时,训练m个模型的计算开销可能是难以忍受的(例如数据集包含1百万个样本,则需训练1百万个模型,而这还是在未考虑算法调参的情况下。
2.交叉验证法-KFold和StratifiedKFold
交叉验证实现方法,除了咱们前面讲的GridSearchCV(见六、)之外,还有KFold, StratifiedKFold
交叉验证法通常K设置为10
from sklearn.model_selection import KFold,StratifiedKFold
KFold(n_splits, random_state, shuffle)
sStratifiedKFold(n_splits, random_state, shuffle)
- 用法:
- 将训练/测试数据集划分n_splits个互斥子集,每次用其中一个子集当作验证集,剩下的n_splits-1个作为训练集,进行n_splits次训练和测试,得到n_splits个结果
- StratifiedKFold的用法和KFold的区别是:KFold是将测试机随机分割。SKFold是分层采样,确保训练集,测试集中,各类别样本的比例是和原始数据集中的一致。
- 注意点:
- 对于不能均等分数据集,其前n_samples % n_splits子集拥有n_samples // n_splits + 1个样本,其余子集都只有n_samples // n_splits样本
- 参数说明:
- n_splits:表示划分几等份
- shuffle:在每次划分时,是否进行洗牌
- ①若为Falses时,其效果等同于random_state等于整数,每次划分的结果相同
- ②若为True时,每次划分的结果都不一样,表示经过洗牌,随机取样的
- 属性:
- ①split(X, y=None, groups=None):将数据集划分成训练集和测试集,返回索引生成器
import numpy as np
from sklearn.model_selection import KFold,StratifiedKFold
X = np.array([
[1,2,3,4],
[11,12,13,14],
[21,22,23,24],
[31,32,33,34],
[41,42,43,44],
[51,52,53,54],
[61,62,63,64],
[71,72,73,74]
])
y = np.array([1,1,0,0,1,1,0,0])
# 实例化KFold和StratifiedKFold
folder = KFold(n_splits = 4, shuffle = False)
sfolder = StratifiedKFold(n_splits = 4, shuffle = False)
print('KFold')
# 分割数据
for train, test in folder.split(X, y):
print('train:%s | test:%s' %(train, test))
print('SKFold')
for train, test in sfolder.split(X, y):
print('train:%s | test:%s'%(train, test))
# 输出结果:
KFold
train:[2 3 4 5 6 7] | test:[0 1]
train:[0 1 4 5 6 7] | test:[2 3]
train:[0 1 2 3 6 7] | test:[4 5]
train:[0 1 2 3 4 5] | test:[6 7]
SKFold
train:[1 3 4 5 6 7] | test:[0 2]
train:[0 2 4 5 6 7] | test:[1 3]
train:[0 1 2 3 5 7] | test:[4 6]
train:[0 1 2 3 4 6] | test:[5 7]
3.自助法
综上所述:
- 当我们数据量足够时,选择留出法简单省时,在牺牲很小的准确度的情况下,换取计算的简便;
- 当我们的数据量较小时,我们应该选择交叉验证法,因为此时划分样本集将会使训练数据过少;
- 当我们的数据量特别少的时候,我们可以考虑留一法。
文章出处登录后可见!