本程序采用百度paddlepaddle深度学习框架,并在百度AI Studio平台上运行。
目录
1实验背景
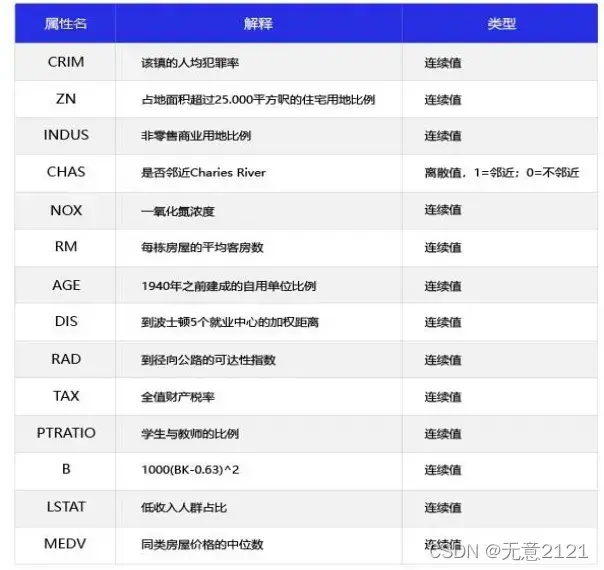
波士顿房价预测是一个经典的机器学习任务,类似于程序员世界的“Hello World”。和大家对房价的普遍认知相同,波士顿地区的房价是由诸多因素影响的。该数据集统计了13 种可能影响房价的因素和该类型房屋的均价,期望构建一个基于 13 个因素进行房价预测的模型,如图所示。
对于预测问题,可以根据预测输出的类型是连续的实数值,还是离散的标签,区分为回归任务和分类任务。因为房价是一个连续值,所以房价预测显然是一个回归任务。下面我们尝试用最简单的线性回归模型解决这个问题,并用神经网络来实现这个模型。
2 实验过程
2.1 数据处理
数据处理是解决问题的第一步,主要包含五个部分:
2.1.1数据集导入并按规定形状保存
先将数据集’housing.data’上传至平台, 并通过 fromfile 语句将数据集导入。由于读入的原始数据是 1 维的,系统默认将所有数据都是连在一起。因此需要我们将数据的形状进行变换,形成一个 2 维的矩阵,每行有一个数据样本的13 个特征(影响房价的特征)和 1 个该类型房屋的均价。
2.1.2数据集的划分(分为训练集和测试集)
数据集划分主要采用比例划分,本实验采取 80%为训练集,20%为测试集。
2.1.3 数据归一化处理
归一化处理十分有必要,既可以提高计算机的计算速度,提高模型训练效率, 而且可以减少量纲对结果的影响。本实验采用最大最小值归一化方法,它适用于数据分布有明显边界的情况。
2.1.4 数据集乱序分成批次(每次读入一个批次)
由于面对海量样本的数据集,如果每次计算都使用全部的样本来计算损失函数和梯度,性能很差(计算得慢)。所以我们需要分批读入数据。但越接近最后的几个批次数据对模型参数的影响可能越大,也就是说神经网络的记忆很有可能被最新的数据覆盖。如果训练数据天然的分布不好,比如做分类问题,第 0 类的数据在前,第 1 类的数据都在后面,那么模型肯定偏重第一类样本。所以有必要随机抽取样本进行训练。我们用 np.random.shuffle( )来打乱样本数据。这种方法称为小批量随机梯度下降法。
2.1.5 封装 load_data 函数
将一系列对数据的操作封装在 load_data 函数中,以便于后面函数的调用。load_data 函数代码如下
import numpy as np def load_data():
#将数据集导入
datafile = 'data/housing (1).data' data = np.fromfile(datafile, sep=' ') #数据集形状变化
feature_names = [ 'CRIM', 'ZN', 'INDUS', 'CHAS', 'NOX', 'RM', 'AGE','DIS',
'RAD', 'TAX', 'PTRATIO', 'B', 'LSTAT', 'MEDV' ]
feature_num = len(feature_names)
data = data.reshape([data.shape[0] // feature_num, feature_num]) maximums, minimums, avgs = \
data.max(axis=0), \ data.min(axis=0), \
data.sum(axis=0) / data.shape[0]
# 数据集的划分
ratio = 0.8
offset = int(data.shape[0] * ratio) training_data = data[:offset] test_data= data[offset:]
# 对数据进行归一化处理(最值归一化)
for i in range(feature_num):
training_data[:, i] = (training_data[:, i] - avgs[i]) / (maximums[i] - minimums[i]) for i in range(feature_num):
test_data[:, i] = (test_data[:, i] - avgs[i]) / (maximums[i] - minimums[i])
return training_data,test_data2.2 神经网络的设计
2.2.1神经网络的结构
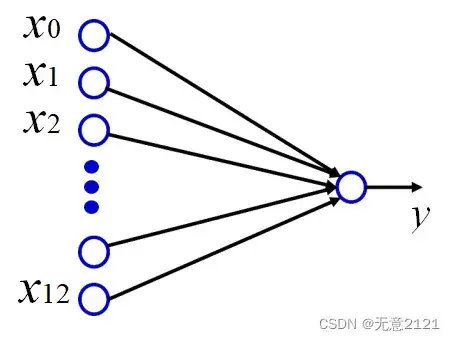
本实验需要通过 13 个输入预测一个输出,因此我们构建 13 输入 1 输出的神经元,由于我们采用多元线性回归来进行预测,该神经网络不需要激活函数并且不需要隐藏层。结构如下图所示。
2.2.2 神经网络的初始化
因为模型的初值直接影响模型参数的优化过程的效率与精确性。因此我们需要给模型的权重一组符合正态分布的初值。
2.2.3 神经网络的前向计算和反向传播
将数据读入后我们可以进行神经网络的前向计算,w 和 b 分别表示该线性模型的权重和偏置,公式如下
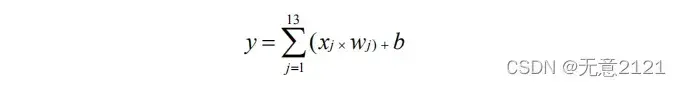
此时算出的 y 是神经网络的预测值,我们需要其与真实值进行比较,通过均方误差和来表示多样本下神经网络预测结果的误差,L 代表损失函数,n 代表样本数目,公式如下
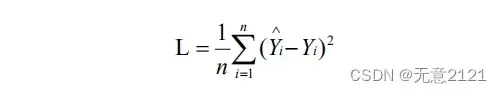
2.2.4 优化算法
假如模型就前向计算一次,预测结果一定是不准确的,因为这是一个开环系统, 我们需要设计一个闭环系统,能够反馈得到的误差,然后去矫正,最终预测值逼近真实值。此时问题相当于转换为计算损失函数的全局最小值,但在多元函数的情形下,求极值需要解线性方程组,计算量较大,因此我们采用数值优化的方法, 通过迭代的思想逼近极值。本实验采用小批量随机梯度下降法进行极值近似解的求解。负梯度方向是多元函数某点下降最快的方向,但由于面对海量样本的数据集,如果每次计算都使用全部的样本来计算损失函数和梯度,性能很差(计算得慢)。所以我们需要分批读入数据,也就是只计算一批数据的平均梯度,同时数据的分布、先后对实验结果会有影响,所以我们随机抽取样本进行训练
该损失函数 L 相对权重 w 的梯度与相对偏置 b 的定义如下
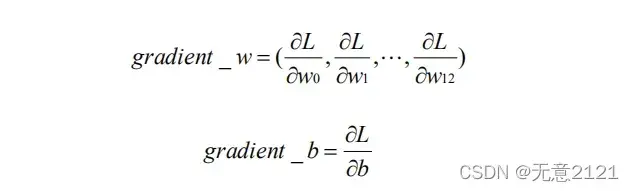
为了便于梯度的计算,我们将损失函数除以 2,梯度的分量可以应用链式求导法则计算,此处不再赘述。求出某个点的梯度意味着得到了该点下降最快的方向向量,通过将该点向最快下降方向移动一定步长损失函数就能够下降。此时函数的变量为权重与偏置,所以一下 x 为权重与偏置组成的向量,eta 代表步长(本实验取 0.01),gradient 代表在 x 这个点的梯度向量,迭代公式如下
![]()
采用这种迭代的方式求解是无止境的,因此我们需要设定一个终止的准则,本实验为计算方便,采用迭代次数终止准则,下面列举几种终止准则公式

代码如下
class Network(object):
def init__(self, num_of_weights): # 初始化权重值
# 随机产生 w 的初始值,为了保持程序每次运行结果的一致性,设置固定的随机数种子
np.random.seed(0)
self.w = np.random.randn(num_of_weights, 1) #初始参数一般符合标准正态分布self.b = 0.
def forward(self, x):
z = np.dot(x, self.w) + self.b return z
def loss(self, z, y): error = z - y
cost = error * error cost = np.mean(cost) return cost
def gradient(self, x, y, z): gradient_w = (z - y) * x
gradient_w = np.mean(gradient_w, axis=0) gradient_w = gradient_w[:, np.newaxis] gradient_b = (z - y)
gradient_b = np.mean(gradient_b) return gradient_w,gradient_b
def update(self, gradient_w,gradient_b, eta=0.01): self.w = self.w - eta * gradient_w
self.b = self.b - eta * gradient_b
def train(self, training_data, epoch_num=100, batch_size=10, eta=0.01): n=len(training_data)
losses = []
for epoch in range(epoch_num): #打乱数据集并分批
np.random.shuffle(training_data) for k in range(0,n,batch_size):
mini_batches=[training_data[k:k+batch_size]]
for iter_id, mini_batch in enumerate(mini_batches): x=mini_batch[:,:-1]
y=mini_batch[:,-1:] z = self.forward(x) L = self.loss(z, y)
gradient_w, gradient_b = self.gradient(x, y, z) self.update(gradient_w, gradient_b, eta) losses.append(L)
return losses3 测试结果
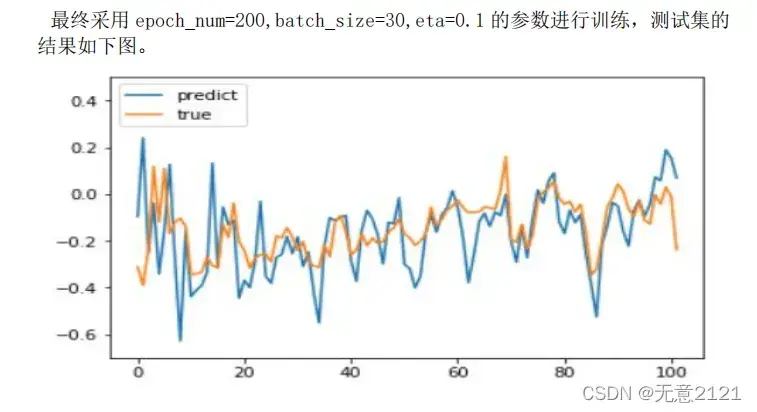
4 完整源程序
源程序包含了对不同epoch和batch_size的调参,神经网络的训练过程,以及预测结果及误差。
#对数据的处理
import numpy as np
def load_data():
#将数据集导入
datafile = 'data/housing (1).data'
data = np.fromfile(datafile, sep=' ')
#数据集形状变化
feature_names = [ 'CRIM', 'ZN', 'INDUS', 'CHAS', 'NOX', 'RM', 'AGE','DIS',
'RAD', 'TAX', 'PTRATIO', 'B', 'LSTAT', 'MEDV' ]
feature_num = len(feature_names)
data = data.reshape([data.shape[0] // feature_num, feature_num])
maximums, minimums, avgs = \
data.max(axis=0), \
data.min(axis=0), \
data.sum(axis=0) / data.shape[0]
# 数据集的划分
ratio = 0.8
offset = int(data.shape[0] * ratio)
training_data = data[:offset]
test_data= data[offset:]
# 对数据进行归一化处理(最值归一化)
for i in range(feature_num):
training_data[:, i] = (training_data[:, i] - avgs[i]) / (maximums[i] - minimums[i])
for i in range(feature_num):
test_data[:, i] = (test_data[:, i] - avgs[i]) / (maximums[i] - minimums[i])
return training_data,test_data
#定义神经网络
class Network(object):
def __init__(self, num_of_weights): # 初始化权重值
# 随机产生w的初始值,为了保持程序每次运行结果的一致性,设置固定的随机数种子
np.random.seed(0)
self.w = np.random.randn(num_of_weights, 1) #初始参数一般符合标准正态分布
self.b = 0.
def forward(self, x):
z = np.dot(x, self.w) + self.b
return z
def loss(self, z, y):
error = z - y
cost = error * error
cost = np.mean(cost)
return cost
def gradient(self, x, y, z):
gradient_w = (z - y) * x
gradient_w = np.mean(gradient_w, axis=0)
gradient_w = gradient_w[:, np.newaxis]
gradient_b = (z - y)
gradient_b = np.mean(gradient_b)
return gradient_w,gradient_b
def update(self, gradient_w,gradient_b, eta=0.01):
self.w = self.w - eta * gradient_w
self.b = self.b - eta * gradient_b
def train(self, training_data, epoch_num=100, batch_size=10, eta=0.01):
n=len(training_data)
losses = []
for epoch in range(epoch_num):
#打乱数据集并分批
np.random.shuffle(training_data)
for k in range(0,n,batch_size):
mini_batches=[training_data[k:k+batch_size]]
for iter_id, mini_batch in enumerate(mini_batches):
x=mini_batch[:,:-1]
y=mini_batch[:,-1:]
z = self.forward(x)
L = self.loss(z, y)
gradient_w, gradient_b = self.gradient(x, y, z)
self.update(gradient_w, gradient_b, eta)
losses.append(L)
return losses
#参数的调试
plot_y3=[]
for i in range(1,100,3):
losses=net.train(training_data,epoch_num=200,batch_size=i,eta=0.1)
# 画出损失函数的变化趋势
plot_x3=range(1,100,3)
l=losses[-1]
plot_y3.append(l)
plt.plot(plot_x3,plot_y3)
plt.xlabel('batch_size')
plt.ylabel('final losses')
plt.show()
#参数的调试
plot_y3=[]
for i in range(50,1000,20):
losses=net.train(training_data,epoch_num=i,batch_size=30,eta=0.1)
# 画出损失函数的变化趋势
plot_x3=range(50,1000,20)
l=losses[-1]
plot_y3.append(l)
plt.plot(plot_x3,plot_y3)
plt.xlabel('epoch_num')
plt.ylabel('final losses')
plt.show()
# 画出最优参数下损失函数的变化趋势
import matplotlib.pyplot as plt
training_data, test_data = load_data()
x = training_data[:, :-1]
y = training_data[:, -1:]
# 创建网络
net = Network(13)
# 启动训练
losses = net.train(training_data, epoch_num=200, batch_size=30, eta=0.1)
# 画出损失函数的变化趋势
plot_x = np.arange(len(losses))
plot_y = np.array(losses)
plt.plot(plot_x, plot_y)
plt.xlabel('Iteration order')
plt.ylabel('loss')
plt.show
#可视化测试的结果
import matplotlib.pyplot as plt
training_data,test_data=load_data()
x=test_data[:,:-1]
y=test_data[:,-1:]
y_predict=net.forward(x)
plot_x=np.arange(len(y_predict))
plot_y=np.array(y_predict)
plt.plot(plot_x,plot_y)
plot_y1=np.array(y)
plt.plot(plot_x,plot_y1)
plt.legend(['predict','true'],loc='upper left')
plt.ylim([-0.7,0.5])
plt.show()
plot_y2=np.array(y-y_predict)
plt.plot(plot_x,plot_y2)
plt.ylabel('predict error')
plt.show()
文章出处登录后可见!