迁移学习就是载入别人预训练好的权重,拿别人的训练好的参数作为我们自己模型的初始化参数,再在这个基础上继续优化。比起从头开始一点一点随机初始化,让模型胡乱地找梯度最优的方向,肯定是迁移学习快啦。
1.载入训练权重
载入别人预训练权重的时候,由于别人的数据预处理的方式与我们自己的可能不同、全连接层中最后分类的结点个数和你的数据集类别个数不同等情况,都会产生各种报错,我就说一下我会的方法,后面有会进行补充哒。
net = MobileNetV2(class_nums=5)
pre_weights = torch.load(pre_trained_pth) //(字典文件)这里载入别人训练好的预训练权重,此时只是导入内存中,还没加载到我们的网络中
下面的两种方法都是:载入预训练权重后,删除全连接层的参数
好处就是:在创建网络的时候,可以直接根据我们自己的数据集类别个数更改模型中最后一个全连接节点个数。
//方法一:
pre_dict = {k: v for k, v in pre_weights.items() if "fc" not in k}
//
//方法二:
//这里的想法是:拿出预训练权重(字典)的key和value,通过获取我们自己网络中与预训练权重中网络层名称一样的的层,拿到相同个数的网络层,删除不一致的
pre_dict = {k: v for k, v in pre_weights.items() if net.state_dict()[k].numel() == v.numel()}
missing_keys, unexpected_keys = net.load_state_dict(pre_dict, strict=False) //将特征提取层的权重送进网络,这里的strict设置为False后,就不用预训练权重的网络结构和我们自己的网络完全key值一致
而第三种方法,在创建网络时候,更改最后的全连接层节点个数,直接net.load_state_dict()方法载入会报错的
net = MobileNetV2()
net.load_state_dict(torch.load(pre_trained_pth), strict=False)
//方法三:
in_channel = net.fc.in_feacture
net.fc = nn.Linear(in_channel, 5) //这里为什么是.fc,道理同下,下面具体讲解了
这里另外说一下为什么删除预训练权重中全连接层的参数,上方代码的判断语句中必须是“fc”???
其实不然,取决于你搭建网络时类变量名称的定义,可以通过来查看每个网络层的名称:
net = MobileNetV2(class_nums=5)
print(net)
//或者
for name in net.named_modules():
print(name)
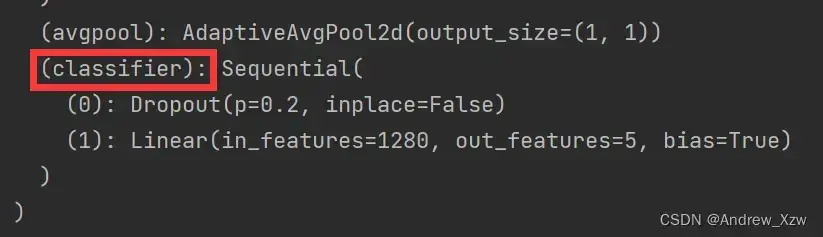
例如:上面的红框中网络的全连接层名称是classifier,那么我们在删除全连接层的参数的时候就是if “classifier” not in k。
或者把网络结构中的classifier改成fc。这里全连接层的名称完全取决于我们自己。
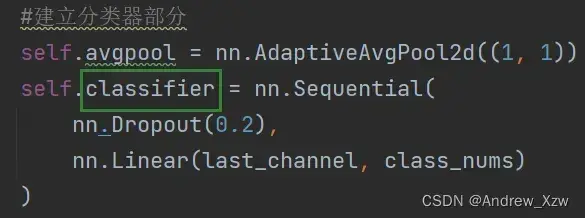
2.载入预训练权重后两种情况
特征层的权重参数在反向传播过程中会求导,冻结特征层,可以缩短训练时间。
2.1冻结全部的特征提取层,微调全连接层
我们如果想要在短时间内将我们的模型达到一个相对理想的效果,可以将特征层全部冻结(全部使用别人预训练权重),然后只训练全连接层,根据我们自己的数据集类别进行fine-tuning。
for param in net.parameters(): //这里的就遍历每个特征层上的权重参数了
param.requires_grad = False
2.2冻结部分的特征层
在卷积神经网络中,特征提取层就是卷积层的部分,因为一开始卷积得到的特征图上的信息多为一些简单的信息:边缘、转角等,这类简单的特征对于大多数的对象都是通用的,所以我们可以冻结低层的权重,以减少训练时间。
for param in net.xx特征层名称.parameters(): //这里的xx特征层名称取决于搭建网络时的定义
param.requires_grad = False
2.3不冻结特征提取层
我认为这能够取得比较好的效果,在以别人的预训练权重参数为基础,继续寻找梯度最优,但可能比起上面冻结特征层,会增加时间上的负担。
3.直观上的结果对比
红色曲线是:载入别人预训练权重后,冻结特征层的loss和精确率;
蓝色曲线是:载入别人预训练权重后,没有冻结特征层,在此基础上继续梯度优化;
黑色曲线是:没有采用迁移学习,让搭建的网络模型随机初始化权重开始训练。
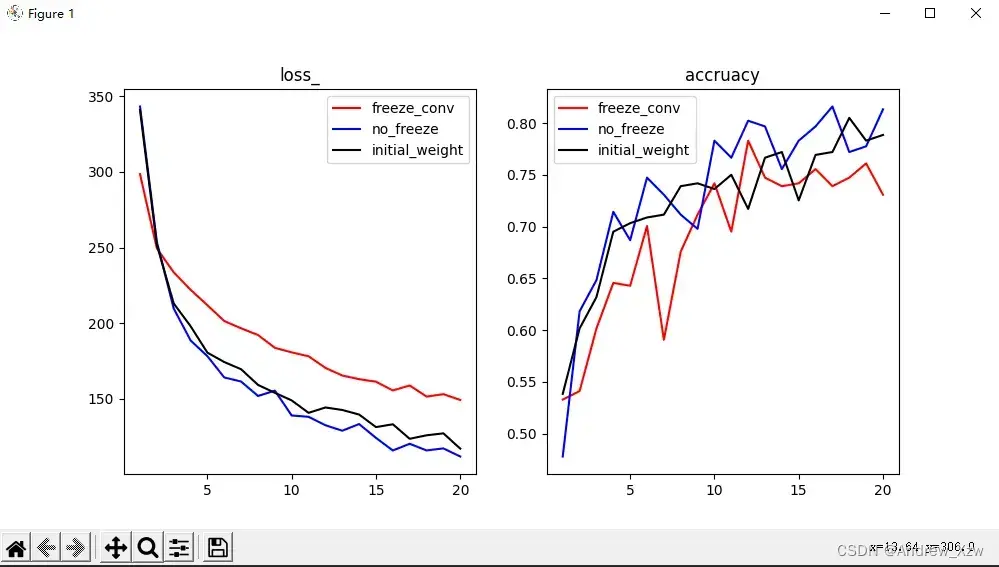
conclusion:
载入预训练权重,拿别人的参数作为一开始的初始化,更容易达到最优;而比起从头开始一点一点随机初始化,让模型胡乱地找梯度最优的方向。肯定迁移学习更好。
而冻结了特征层后,载入别人预训练权重后就不再继续优化了,效果肯定不如随机初始化后梯度下降后的效果,好比你原地踏步,别人在慢慢进步。
文章出处登录后可见!