卷友们好,我是rumor。
已经好久没看OpenAI的官网[1]了,但今天冥冥之中感觉受到了什么召唤,心想GPT4什么时候发布,莫名地就打开了,果然有料:

试用:https://chat.openai.com/
它把魔抓又伸向对话了!来一起看看官方放出的case吧:
帮人Debug代码,并进行多轮询问:
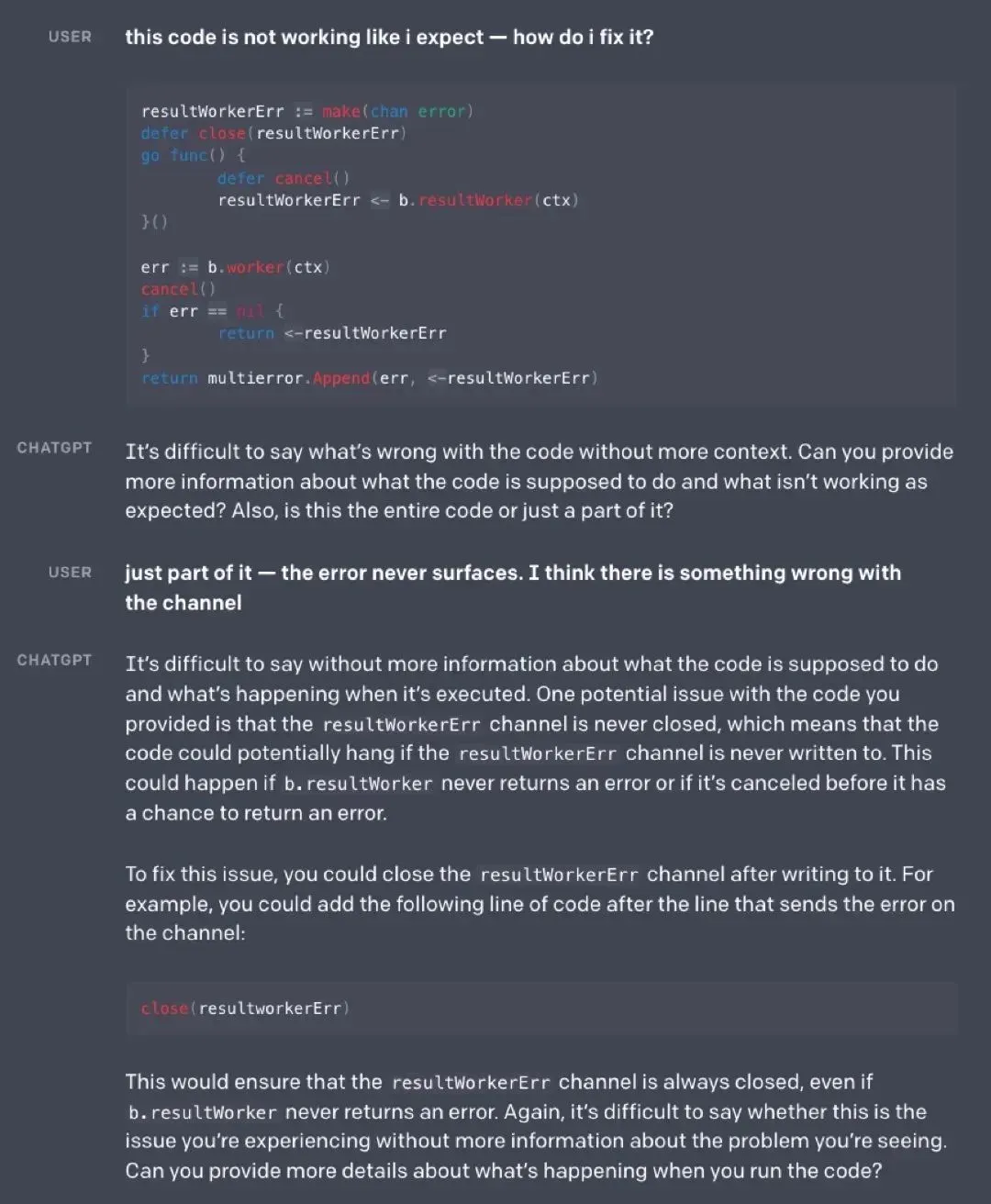
识别出危险问题并拒绝回答,但用户说明意图后给出了更好的回复:

执行指令,甚至改很多遍也不生气:

还有个指代消解的case太长就不放了,OpenAI在最后还拿InstructGPT做了对比,可以看到InstructGPT只是冰冷地执行指令,而ChatGPT则更有温度一些。
从上面的例子可以看到,对比今年其他厂的对话工作,ChatGPT有几项明显的优点:
基于GPT3.5,有着更多样的训练数据,别的我不知道,反正debug代码有点东西
强大的多轮上下文理解能力,从指代消解、写信的例子看出来的,如果对历史消息没有很好的记忆理解,可能就新起一个话题了
更像人。目前大部分模型都是直接回答,而ChatGPT显然跟用户有一个「Chat」的过程,比如debug代码的时候,上来先回复「很难说,再多给点信息」
更像人的对话策略,是很难做出来的,因为我们不知道怎么才算「像个人」。谷歌为了解决这个问题,曾经拆分出了一堆指标。
而这次OpenAI则是采用了和DeepMind Sparrow[2]一样的策略,既然不知道用哪些维度衡量对话的好坏,那直接基于用户的反馈去训练,让模型自己学就好了。
基于反馈的训练,那不就是宇宙的终点强化学习吗。
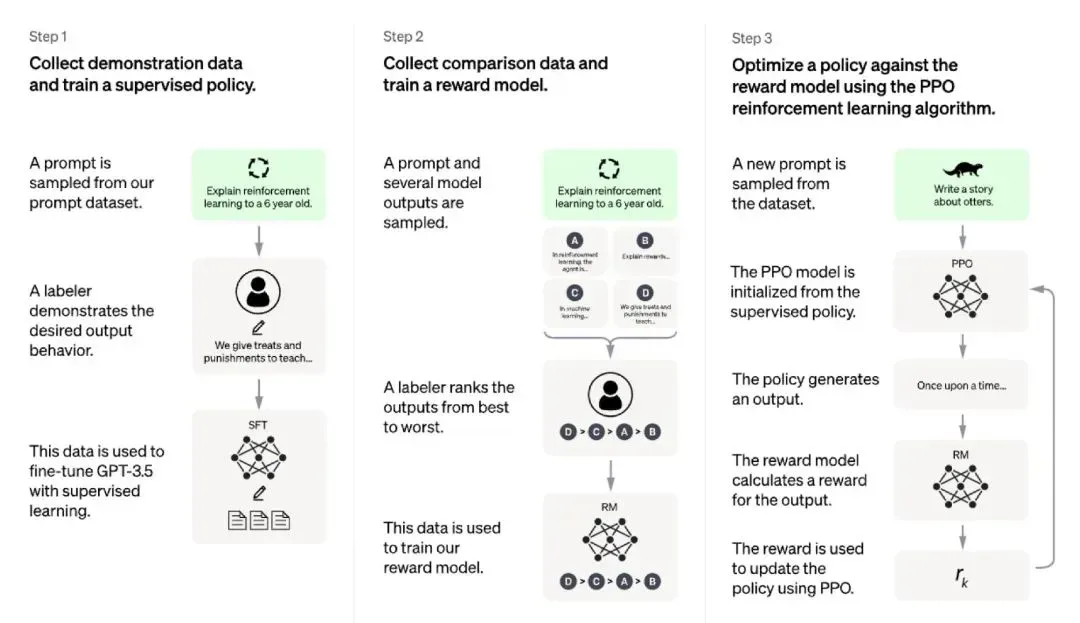
ChatGPT的制作分为如下几步:
用监督数据基于GPT3.5训练一个对话模型,训练数据是标注人员手把手写出来的
人工标注模型生成的多个结果,训练一个给对话回复打分的模型
用打分模型作为反馈,基于PPO算法训练一个对话模型
上面的步骤其实跟DeepMind的工作很像,也很直觉,但DeepMind额外针对黄赌毒对话做了些训练,目前还不知道ChatGPT是怎么实现的,不过以他们LM一把梭的性格,有可能全是数据堆出来的。。。
当然,ChatGPT还是有一些局限的,比如:
说一些不明所以毫无疑义的话
重复问相同的问题,或者轻微调整后答案变化很大
很啰嗦,从case里也看出来了,这主要是训练数据带来的偏差,标注同学会更倾向长句子
也不是所有模糊情况都会反问
有些黄赌毒问题还是没法识别,作者们在打算用API解决
目前,为了让大家给出更多的反馈,OpenAI顺势在11.30-12.30之间举行了一个反馈比赛[3],感兴趣的同学可以积极参与。
最后,让我们对应该过阵子就会发布的GPT4拭目以待吧!
参考资料
[1]
OpenAI Blog: https://openai.com/blog/
[2]Building safer dialogue agents: https://www.deepmind.com/blog/building-safer-dialogue-agents
[3]Feedback Contest: https://cdn.openai.com/chatgpt/ChatGPT_Feedback_Contest_Rules.pdf

我是朋克又极客的AI算法小姐姐rumor
北航本硕,NLP算法工程师,谷歌开发者专家
欢迎关注我,带你学习带你肝
一起在人工智能时代旋转跳跃眨巴眼
「不会debug代码的模型不是好AI」
文章出处登录后可见!