Attention机制由来
注意力机制借鉴了人类注意力的说法,比如我们在阅读过程中,会把注意力集中在重要信息上,在训练过程中。输入的权重也都是不同的,注意力机制就是学习到这些权重,最开始attentionj机制在CV领域被提出来。但后面广泛应用在NLP领域。

图1形象化展示了人类在看到一幅图像时如何高效分配有限注意力资源的,其中红色区域表明视觉系统更加关注的目标,很明显对于图1所示的场景,人们会把注意力更多的投入到人的脸部。文本的标题以及文章的首句等位置。
深度学习中的注意力机制从本质上讲和人类的选择性注意力机制类似,核心目标也是从众多信息中选出对当前任务目标更加关键的信息。
Attention定义
Attention其本质就是加权,一般没有严格的定义:
Google 2017年论文Attention is All you need中,为Attention做了一个抽象定义:
An attention function can be described as mapping a query and a set of key-value pairs to an output, where the query, keys, values, and output are all vectors. The output is computed as a weighted sum of the values, where the weight assigned to each value is computed by a compatibility function of the query with the corresponding key.
注意力是将一个查询和键值对映射到输出的方法,Q、K、V均为向量,输出通过对V进行加权求和得到**,权重就是Q、K相似度**。
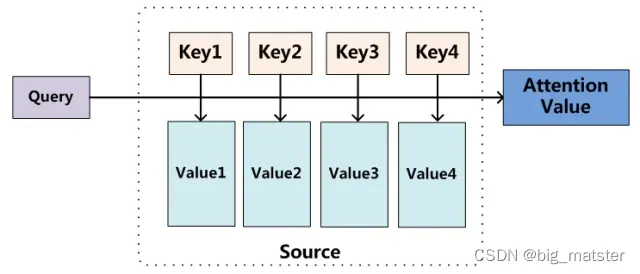 \
\
我们可以这样来看待attention机制:
将Source中的构成元素想象成由一系列 数据对构成,此时给定Target中的某个元素
,通过计算
和各个
的相似性和相关性。得到每个
值对应
值的权重系数,然后对Value进行加权求和。即得到最终的Attention数值。所以本质上的Attention机制是对
中的元素的
值进行加权求和,而
和
是用来计算对应
的权重系数的,即可以将本质思想改写为如下公式:
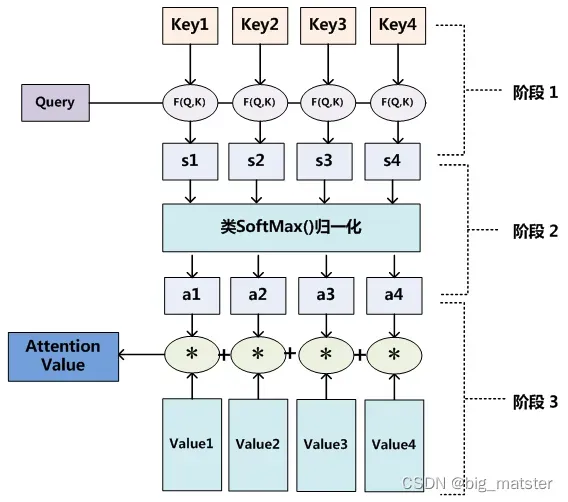
至于Attention机制的具体计算过程,如果对目前大多数方法进行抽象的话,可以将其归纳为三个过程:
- 第一阶段根据**
和
来计算两者的相似性**和相关性。可以引入不同的函数和计算机制,根据
计算两者的相似性或相关性。最常见的方法包括:求两者的向量的点积,求两者的向量Consine的相似性或者通过在引入额外的神经网络来求值:具体公式如下:
- *点积:
- Cosine相似性
- MLP网络
- 第二阶段对第一阶段的原始数值进行归一化处理,引入了类似SoftMax的计算方式对第一阶段的得分进行数值转换,一方面可以进行归一化,将原始计算的分值整理成所有元素权重和为1的概率分布,另一方面也可以通过SoftMax的内在机制更加突出重要元素的权重,即一般采用如下公式计算:
第三阶段根据权重系数对Value值进行加权求和:
通过如上三个阶段的计算,即可求出针对Query的Attention数值,目前绝大多数具体的注意力机制计算方法都符合上述的三阶段抽象计算过程:
Encoder-Decoder框架
要了解深度学习中的注意力模型,就不得不先谈Encoder-Decoder框架,因为目前大多数注意力模型附着在Encoder-Decoder框架下,当然,其实注意力模型可以看作一种通用的思想,本身并不依赖于特定框架,这点需要注意。
该框架可以看作是一种深度学习领域的一种研究模式,应用场景异常广泛。
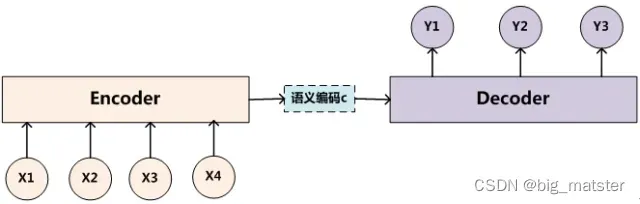
文本处理领域的Encoder-Decoder框架可以这么直观地去理解:
可以把它看作适合处理由一个句子(或篇章)生成另外一个句子(或篇章)的通用处理模型。对于句子对,我们的目标是给定
。Source和Target可以是同一种语言,也可以是两种不同的语言。而Source和Target分别由各自的单词序列构成:
Encoder顾名思义就是对输入的句子Source进行编码,将输入句子通过非线性变换转化为中间语义表示C:
对于解码器Decoder来说,其任务是根据句子的Source的中间语义表示C和之前已经生成的历史信息来生成时刻要生成的单词
每个都依次这么产生,那么看起来就是整个系统根据输入句子
生成了目标句子
,如果
是中文句子,
是英文句子,那么这就是解决机器翻译问题的Encoder-Decoer框架。如果Source是一篇文章**,Target是概括性的几句描述语句**,那么这是文本摘要的Encoder-Decoder框架;如果Source是一句问句,Target是一句回答,那么这是问答系统或者对话机器人的Encoder-Decoder框架。由此可见,在文本处理领域,Encoder-Decoder的应用领域相当广泛。
Attention机制的引入
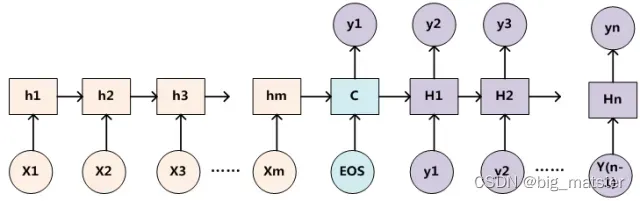
上图展示的Encoder-Decoder框架是没有体现出“注意力模型”的,所以可以把它看作是注意力不集中的分心模型。为什么说它注意力不集中呢?请观察下目标句子Target中每个单词的生成过程如下:
Encoder学习到中间语义表示C
其中F是Decoder的非线性变换函数,从这里可以看出,在生成目标句子单词时,不论生成那个单词,它们使用的输入句子的Source的语义编码C都是一样的,没有任何区别:
而语义编码C是由句子Source的每个单词经过Encoder的编码产生,这意味着不论是生成那个单词,,
,
. 其实句子Source中的任意单词对生成某个目标单词
来说影响力都是相同的,这是为何说这个模型没有体现出注意力的缘由。
目标句子中的每个单词都应该学会其对应的源语句子中单词的注意力分配概率信息,这意味着在生成单词的时候,原先都是相同的中间语义表示C,会被替换成根据当前生成单词而不断变化的
,l。理解Attention模型的关键就在这里,即有固定的中间语义表示C,换成了加入注意力机制变化的
,增加了注意力模型的Encoder-Decoder框架理解起来如图所示:
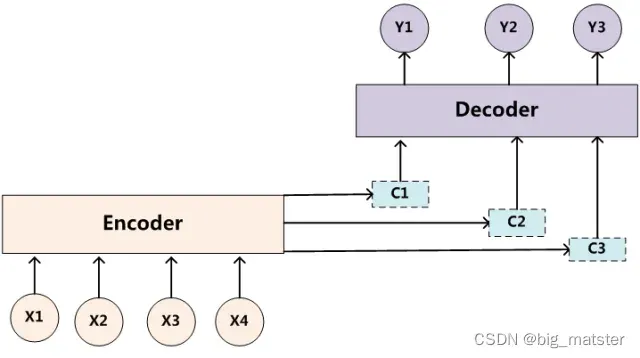
即生成目标句子单词的过程成了下面的形式:
‘
- 序列与序列信息
如果拿机器翻译来解释,比如输入的是英文句子:Tom chase Jerry,Encoder-Decoder框架逐步生成中文单词:“汤姆”,“追逐”,“杰瑞”。
在翻译**“杰瑞”这个中文单词的时候,模型里面的每个英文单词对于翻译目标单词“杰瑞”贡献是不相同的,显然“Jerry”对于翻译成“杰瑞”更重要,如果引入Attention模型的话,应该在翻译“杰瑞”的时候,体现出英文单词对于翻译当前中文单词不同的影响程度**,比如给出类似下面一个概率分布值:(Tom,0.3)(Chase,0.2) (Jerry,0.5)
而每个可能对应着不同的源语句子单词的注意力分配的概率分布,比如对于上面的英法翻译来说,其对应的信息可能如下:

其中函数代表Encoder对于输入英文单词的某种变换函数,比如如果encoder是用RNN模型的话,这个
函数的结果往往是某个时刻输入
后隐层节点的状态值,
代表Encoder根据单词中间表示合成整个句子语义表示的变换函数,一般做法中,
函数是对构成元素的加权求和,即下列公式:
翻译中文单词“汤姆”的时候,数学公式对应的中间语义表示形成过程如下图:
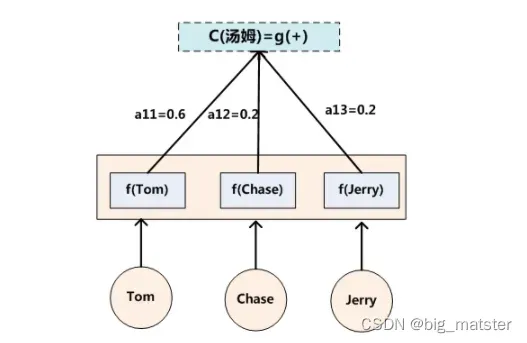
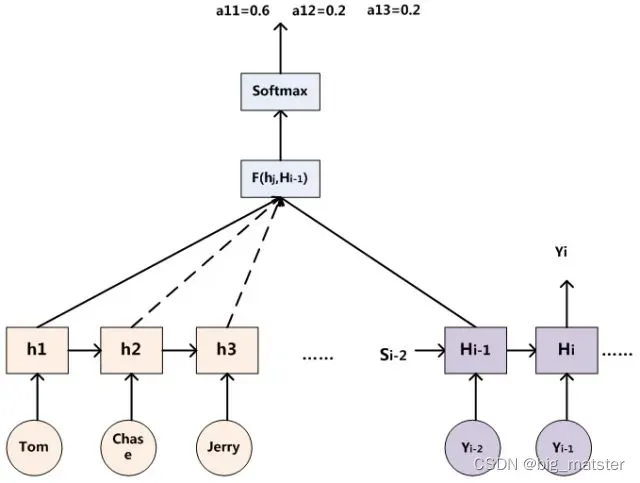
这里还有一个问题:生成目标句子某个单词,比如“汤姆”的时候,如何知道Attention模型所需要的输入句子单词注意力分配概率分布值呢?就是说“汤姆”对应的输入句子Source中各个单词的概率分布:(Tom,0.6)(Chase,0.2)(Jerry,0.2) 是如何得到的呢?
(输入句子单词注意力分配概率分布值)
为了便于说明,我们假设对图2的非Attention模型的Encoder-Decoder框架进行细化,Encoder采用RNN模型,Decoder也采用RNN模型,这是比较常见的一种模型配置,则框架转换为下图:
用下图可以更为便捷地说明注意力分配概率分布值得通用计算过程:
Attention机制得类别
负载几篇常见得Attention学习,后续自己一个一个地研究,将Attention研究透彻都行啦:
Hard Attention
论文:Show, Attend and Tell:Neural Image Caption Generation with Visual Attention
Soft Attention
论文:Show, Attend and Tell:Neural Image Caption Generation with Visual Attention
Global Attention
论文:Show, Attend and Tell:Neural Image Caption Generation with Visual Attention
Local Attention
论文:Show, Attend and Tell:Neural Image Caption Generation with Visual Attention
Self Attention
论文:attention is all you need
Multi-head Attention
Attention机制得应用
自然语言处理领域
- 机器翻译
- 摘要生成
- 图文互搜
- *文本蕴含
- 阅读理解
- 文本分类
- 序列标注
- 关系抽取。
今天,介绍得attention机制就到这里,慢慢地将各种Attention以及如何将Attention加入Encoder-Decoder框架中,会用数学公式推导。
总结
现在所有创新想法,只能总结与记录,没有电脑尝试都是零。
先大致理解下框架,后续展开各个模型得细节,理解Attention得机制,以及如何将Attention加入各种模型当中,全部都将其搞定都行啦得样子与打算。
文章出处登录后可见!