一、认识支持向量机
支持向量机(support vector machine,简称SVM),是一种解决二分类问题的机器学习模型,其基本模型定义为特征空间上的间隔最大的线性分类器,其学习策略便是间隔最大化,最终可转化为一个凸二次规划问题的求解。
要认识支持向量机,我们还需要了解几个概念。
1.1 线性可分/线性不可分
对于一个二维空间,每个样本就相当于平面上的一个点。如果能够找到一条线,可以把两种类别的样本划分至这条线的两侧,我们就称这个样本集线性可分,如下图所示。
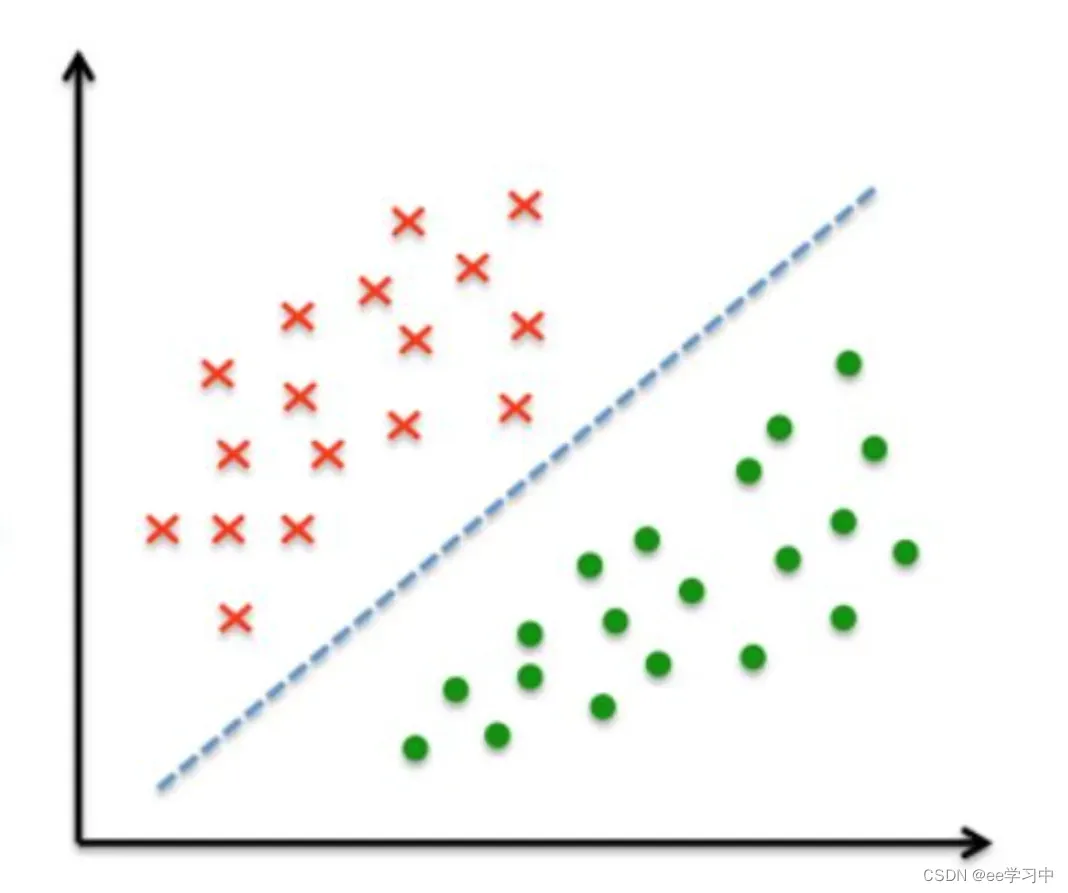
反之,若不能找到这样的直线,则称该样本集线性不可分。
1.2 超平面
显然,在上述的二维空间中,我们的目标就是找到这样的一条直线,能够把样本集划分成两部分,我们把这样的线称作线性模型。同理,在三维空间中,我们要找的线性模型就是一个平面。而对于更高的维度,虽然我们处在三维的世界,无法想象三维以上的世界,但我们可以使用数学方法描述更高维度,同样也可以使用数学方法推导出高维的线性模型。我们称超过三维的曲面为超平面,其方程为:
其中,,n表示特征数(维度数),b为常数。
所以我们可以这样描述SVM的目的:找到这样一个超平面wx+b=0,使得在超平面上方的点x代入函数y=wT x+b,y全部大于0,在超平面下方的点x代入函数y=wx+b,y全部小于0。
二、算法思想
2.1 线性可分的SVM
SVM要找到一个超平面,这个超平面要分开两种不同的样本,但符合这个条件的超平面不是唯一的。这要求我们使用一个标准,能够确认一个分类效果最好的超平面。
假设两类数据可以被分离,垂直于该超平面移动,直到碰到某个样本向量,这两个样本向量就是支持向量。得到的两个超平面
和
,称为支撑超平面,它们分别支撑两类数据。而位于
和
正中间的超平面就是分类效果最好的超平面。如下图所示。
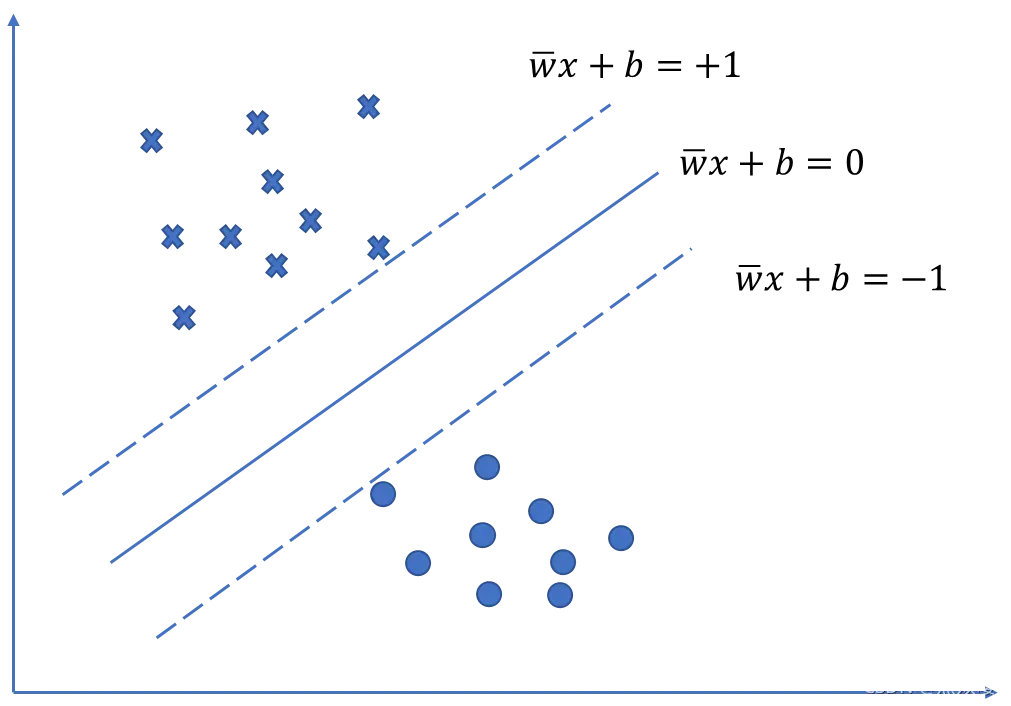
超平面和
之间的距离d称为间隔,这个间隔是
的函数,分类效果最好的超平面应该使d最大,我们的目的就是寻找这样的
使得间隔达到最大。
经过公式推导,实际上,最大化d可以转化成最小化1/2||w||2,限制条件为s.t. yi(wTxi+b)>=1, i=1,2,…,m。
2.2 线性不可分的SVM
对于线性不可分的样本集,我们无法找到这样的一个超平面分割不同类型的样本,但这并不意味着我们无法使用SVM方法。
一个线性不可分的样本集,只是在当前维度下线性不可分,但它在高维空间中能够线性可分。如下图所示,在二维空间线性不可分样本集,但是在三维空间中,有可能找到这样一个平面将其分隔开来。
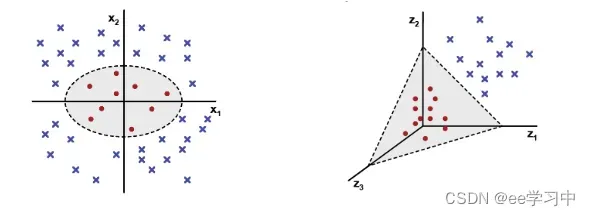
我们可以使用核函数的方法,将数据映射到高维空间。下面给出一些常见的核函数:
线性核(Linear Kernel)
多项式核(Polynomial Kernel)
高斯核(Gaussian Kernel)
拉普拉斯核(Laplacian Kernel)
Sigmoid核(Sigmoid Kernel)
需要特别指出的是,特征空间的选择对模型最后的性能至关重要,所以要多尝试不同的核函数,找到最合适的一个特征空间。
2.3 软间隔
上述的SVM方法考虑了所有的样本点,对于有噪声的情况可能会使这个问题无解。此外,即使我们选择的核函数能够分别两种不同的数据类型,我们也很难判断这是否是过拟合导致。
为了缓解上面的问题,可以使用软间隔方法,即我们允许最终找到的超平面发生少量的分类错误,只要它能够保证将大多数样本分类正确就可以了。
优化后的目标函数如下所示:
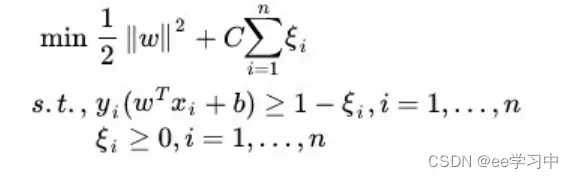
其中正则项由惩罚系数C和松弛变量![]() 组成,C是超参数由我们自行修改,松弛变量对应数据点允许偏移的量。
组成,C是超参数由我们自行修改,松弛变量对应数据点允许偏移的量。
参考资料
文章出处登录后可见!