yaml文件
模型深度&宽度
nc: 3 # 类别数量
depth_multiple: 0.33 # model depth multiple
width_multiple: 0.50 # layer channel multiple
depth_multiple:控制子模块数量=int(number*depth)
width_multiple:控制卷积核的数量=int(number*width)
Anchor
anchors:
- [10,13, 16,30, 33,23] # P3/8,检测小目标,10,13是一组尺寸,总共三组检测小目标
- [30,61, 62,45, 59,119] # P4/16,检测中目标,共三组
- [116,90, 156,198, 373,326] # P5/32,检测大目标,共三组
该anchor尺寸是为输入图像640×640分辨率预设的,实现了即可以在小特征图(feature map)上检测大目标,也可以在大特征图上检测小目标。三种尺寸的特征图,每个特征图上的格子有三个尺寸的anchor。
Backbone
backbone:
# [from, number, module, args]
[[-1, 1, Focus, [64, 3]], # 0-P1/2
[-1, 1, Conv, [128, 3, 2]], # 1-P2/4
[-1, 3, C3, [128]],
[-1, 1, Conv, [256, 3, 2]], # 3-P3/8
[-1, 9, C3, [256]],
[-1, 1, Conv, [512, 3, 2]], # 5-P4/16
[-1, 9, C3, [512]],
[-1, 1, Conv, [1024, 3, 2]], # 7-P5/32
[-1, 1, SPP, [1024, [5, 9, 13]]],
[-1, 3, C3, [1024, False]], # 9
]
具体解释如下:
from:输入来自那一层,-1代表上一次,1代表第1层,3代表第3层
number:模块的数量,最终数量需要乘width,然后四舍五入取整,如果小于1,取1。
module:子模块
args:模块参数,channel,kernel_size,stride,padding,bias等
Focus:对特征图进行切片操作,[64,3]得到[3,32,3],即输入channel=3(RGB),输出为640.5(width_multiple)=32,3为卷积核尺寸。
Conv:nn.conv(kenel_size=1,stride=1,groups=1,bias=False) + Bn + Leaky_ReLu。[-1, 1, Conv, [128, 3, 2]]:输入来自上一层,模块数量为1个,子模块为Conv,网络中最终有1280.5=32个卷积核,卷积核尺寸为3,stride=2,。
BottleNeckCSP:借鉴CSPNet网络结构,由3个卷积层和X个残差模块Concat组成,若有False,则没有残差模块,那么组成结构为nn.conv+Bn+Leaky_ReLu
SPP:[-1, 1, SPP, [1024, [5, 9, 13]]]表示5×5,9×9,13×13的最大池化方式,进行多尺度融合。源代码如下:
k = [5, 9, 13]
self.m = nn.ModuleList([nn.MaxPool2d(kernel_size=x, stride=1, padding=x // 2) for x in k])
Head
head:
[[-1, 1, Conv, [512, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']], 上采样
[[-1, 6], 1, Concat, [1]], # cat backbone P4 代表concat上一层和第6层
[-1, 3, C3, [512, False]], # 13 说明该层是第13层网络
[-1, 1, Conv, [256, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 4], 1, Concat, [1]], # cat backbone P3
[-1, 3, C3, [256, False]], # 17 (P3/8-small)
[-1, 1, Conv, [256, 3, 2]],
[[-1, 14], 1, Concat, [1]], # cat head P4
[-1, 3, C3, [512, False]], # 20 (P4/16-medium)
[-1, 1, Conv, [512, 3, 2]],
[[-1, 10], 1, Concat, [1]], # cat head P5
[-1, 3, C3, [1024, False]], # 23 (P5/32-large)
[[17, 20, 23], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5),[17, 20, 23]说明输入来自第17,20,23层
YOLOv5中的Head包括Neck和Detect_head两部分。Neck采用了PANet机构,Detect结构和YOLOv3中的Head一样。其中BottleNeckCSP带有False,说明没有使用残差结构,而是采用的backbone中的Conv。
超参数
初始化超参
YOLOv5的超参文件见data/hyp.finetune.yaml(适用VOC数据集)或者hyo.scrach.yaml(适用COCO数据集)文件
lr0: 0.01 # 初始学习率 (SGD=1E-2, Adam=1E-3)
lrf: 0.2 # 循环学习率 (lr0 * lrf)
momentum: 0.937 # SGD momentum/Adam beta1 学习率动量
weight_decay: 0.0005 # 权重衰减系数
warmup_epochs: 3.0 # 预热学习 (fractions ok)
warmup_momentum: 0.8 # 预热学习动量
warmup_bias_lr: 0.1 # 预热初始学习率
box: 0.05 # iou损失系数
cls: 0.5 # cls损失系数
cls_pw: 1.0 # cls BCELoss正样本权重
obj: 1.0 # 有无物体系数(scale with pixels)
obj_pw: 1.0 # 有无物体BCELoss正样本权重
iou_t: 0.20 # IoU训练时的阈值
anchor_t: 4.0 # anchor的长宽比(长:宽 = 4:1)
# anchors: 3 # 每个输出层的anchors数量(0 to ignore)
#以下系数是数据增强系数,包括颜色空间和图片空间
fl_gamma: 0.0 # focal loss gamma (efficientDet default gamma=1.5)
hsv_h: 0.015 # 色调 (fraction)
hsv_s: 0.7 # 饱和度 (fraction)
hsv_v: 0.4 # 亮度 (fraction)
degrees: 0.0 # 旋转角度 (+/- deg)
translate: 0.1 # 平移(+/- fraction)
scale: 0.5 # 图像缩放 (+/- gain)
shear: 0.0 # 图像剪切 (+/- deg)
perspective: 0.0 # 透明度 (+/- fraction), range 0-0.001
flipud: 0.0 # 进行上下翻转概率 (probability)
fliplr: 0.5 # 进行左右翻转概率 (probability)
mosaic: 1.0 # 进行Mosaic概率 (probability)
mixup: 0.0 # 进行图像混叠概率(即,多张图像重叠在一起) (probability)
训练超参
训练超参数包括:yaml文件的选择,和训练图片的大小,预训练,batch,epoch等。
可以直接在train.py的parser中修改,也可以在命令行执行时修改,如:$ python train.py –data coco.yaml –cfg yolov5s.yaml –weights ‘’ –batch-size 64
–data指定训练数据文件 –cfg设置网络结构的配置文件 –weihts加载预训练模型的路径
优化策略
1)数增强策略
从数据角度,我们通过粘贴、裁剪、mosaic、仿射变换、颜色空间转换等对样本进行增强,增加目标多样性,以提升模型的检测与分类精度。
2)SAM优化器
SAM优化器[4]可使损失值和损失锐度同时最小化,并可以改善各种基准数据集(例如CIFAR-f10、100g,ImageNet,微调任务)和模型的模型泛化能力,从而产生了多种最新性能。另外, SAM优化器具有固有的鲁棒性。
经实验对比,模型进行优化器梯度归一化和采用SAM优化器,约有0.027点的提升。
3)Varifocal Loss损失函数
Varifocal Loss主要训练密集目标检测器使IOU感知的分类得分(IASC)回归,来提高检测精度。而目标遮挡是密集目标的特征之一,因此尝试使用该loss来缓解目标遮挡造成漏检现象。并且与focal loss不同,varifocal loss是不对称对待正负样本所带来的损失。
4)冻结训练
在训练过程中采取常规训练与冻结训练想相结合的方式迭代,进一步抑制训练过程中容易出现的过拟合现象,具体训练方案是:1)常规训练;2)加入冻结模块的分步训练1;3)加入冻结模块的分步训练2。
我们详细讲解以上步骤。第一步:从训练数据中随机选取一半,进行yolov5常规训练,该过程中所有的参数是同时更新的。具体流程如下:
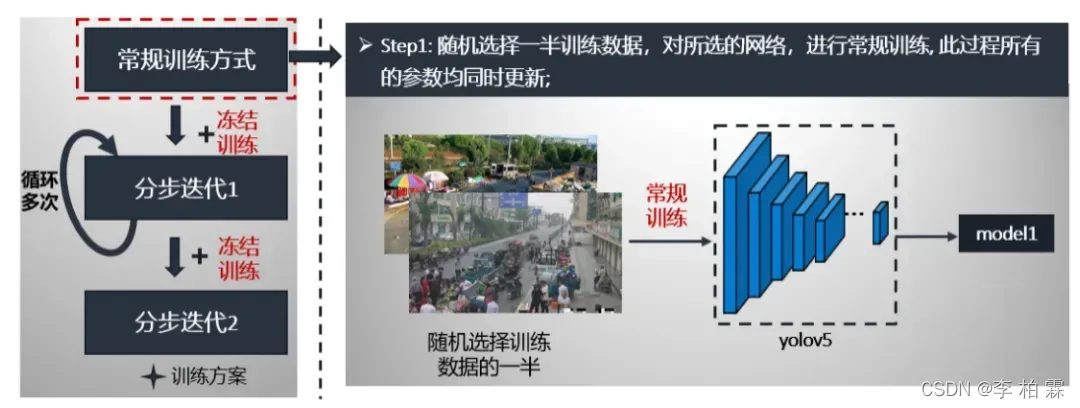 第二步分布迭代1就是采用的冻结模块进行,数据是随机选取训练数据的一半,预训练模型是第一步常规训练的最好模型,按照冻结训练方式进行训练。这个流程循环多次,获得model2。
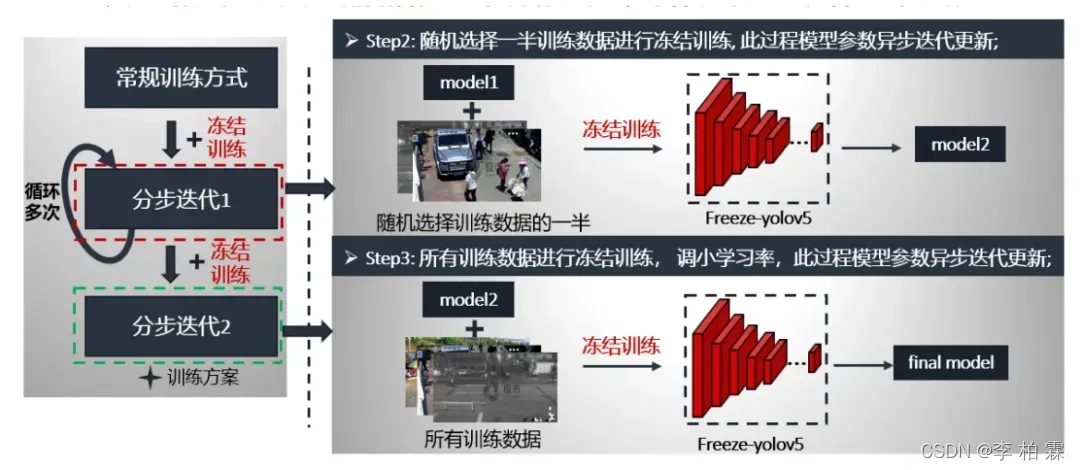
第二步分布迭代1就是采用的冻结模块进行,数据是随机选取训练数据的一半,预训练模型是第一步常规训练的最好模型,按照冻结训练方式进行训练。这个流程循环多次,获得model2。
第三步分布迭代2同样采用的是冻结模块进行,数据是所有训练数据,由于参数已经学过,这时我们将学习率调小一个量级,同样也是按照冻结训练方式进行训练。这个流程只循环一次,获得最终的模型。
两步的具体流程如下:
5)训练时间优化
最初我们直接采用yolov5训练,这种数据加载方式是以张为单位,基于像素的访问,但是训练时速度很慢,可能受其他线程影响造成的,大概一轮要40分钟左右。然后我们就尝试了cache这种方式,它是将所有训练数据存入到内存中,我们以6406403的输入图像为例,占道数据总共有10147张,全部读进去大约占11.6G的内存,平台是提供12G的内存,几乎将内存占满,也会导致训练变慢;于是我们就尝试改进训练读取数据方式,我们采用的是cache+图像编解码的方式,内存占用仅是cache的1/6,由于添加了编解码,速度比cache慢点,但从数据比较来看,相差无几。这样既能节省内存又能加快训练速度。节省了我们训练过程的极力值和加快实验的步伐。
文章出处登录后可见!