一、实验目的
-
了解 Python 采集语音信号的原理及常用命令;
-
熟练掌握基于 Python 的语音文件的创建、读写等基本操作;
-
学会使用 plt.plot 命令来显示语音信号波形,并掌握基本的标注方法。
二、实验内容
- 编写 Python 程序实现录制语音信号“你好,欢迎”,并保存为 C2_1_y_1.wav 文件,要求采样频率为 16000Hz,采样精度
16bit; - 使用 wavfile.read 函数读取 C2_1_y_1.wav 文件,并使用 plt.plot
函数显示出来。要求:横轴和纵轴带有标注。横轴的单位为秒,纵轴显示的为归一化后的数值。 - 使用读取数据流函数播放录制的语音信号,并改变播放的采样频率为原始采样频率 的倍数,体验效果
import pyaudio
import wave
import time
from scipy.io import wavfile
#from speechlib import *
import numpy as np
import matplotlib.pyplot as plt
plt.rcParams['font.family'] = ['sans-serif'] #显示中文标签
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus']=False #用来正常显示负号
# 定义数据流参数信息
CHUNK = 1024
FORMAT = pyaudio.paInt16
CHANNELS = 1
RATE = 16000
RECORD_SECONDS = 5
nframes = int(RATE / CHUNK * RECORD_SECONDS) #计算出所需采集帧的数量
WAVE_OUTPUT_FILENAME = "C2_1_y_1.wav"
# 实例化一个 Pyaudio 对象
p = pyaudio.PyAudio()
# 使用该对象打开声卡,并用上述参数信息对数据流进行赋值
stream = p.open(format=FORMAT,
channels=CHANNELS,
rate=RATE,
input=True,
frames_per_buffer=CHUNK)
# 开始录音
print("* recording")
frames = []
for i in range(0, nframes):
data = stream.read(CHUNK)
frames.append(data)
print("* done recording")
# 关闭数据流,声卡;终止 Pyaudio
stream.stop_stream()
stream.close()
p.terminate()
# 设定存储录音的 WAV 文件的基本信息
wf = wave.open(WAVE_OUTPUT_FILENAME, 'wb')
wf.setnchannels(CHANNELS)
wf.setsampwidth(p.get_sample_size(FORMAT))
wf.setframerate(RATE)
wf.writeframes(b''.join(frames))
wf.close()
# 只读模式打开需要播放的文件
wf = wave.open(WAVE_OUTPUT_FILENAME, 'rb')
# 实例化一个 pyaudio 对象
p = pyaudio.PyAudio()
# 定义回调函数
def callback(in_data, frame_count, time_info, status):
data = wf.readframes(frame_count)
return (data, pyaudio.paContinue)
# 以回调函数的形式打开声卡,创建数据流
stream = p.open(format=p.get_format_from_width(wf.getsampwidth()),
channels=wf.getnchannels(),
rate=wf.getframerate(),
output=True,
stream_callback=callback)
# 打开数据流
stream.start_stream()
# 等待数据流停止
while stream.is_active():
time.sleep(0.1)
# 停止数据流,关闭声卡、音频文件;终止 Pyaudio
stream.stop_stream()
stream.close()
wf.close()
p.terminate()
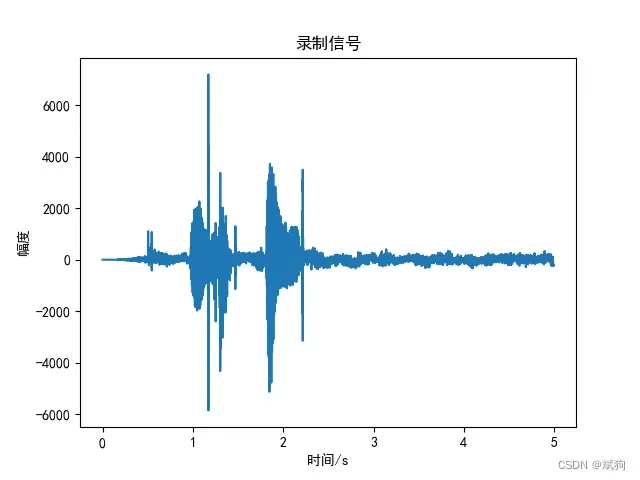
(fs, sound) = wavfile.read(WAVE_OUTPUT_FILENAME)
t = np.array([i/fs for i in range(sound.size)])
plt.plot(t,sound)
plt.title('录制信号')
plt.xlabel('时间/s')
plt.ylabel('幅度')
plt.show()
三、思考题
-
分析并解释实验要求 3)的现象原理。
-
自行录制一段语音,并存储为 wav 文件。要求:存储为 wav 文件时,分别以采样频率、2 倍采样频率和 1/2 采样频率存为三个 wav
文件,并使用 plt 库中的 plot 函数结合 subplot 函数在一副图上,显示 3
个波形。横轴和纵轴带有标注。横轴的单位为秒,纵轴显示的为归一化后的数值。
录音.py
作用:录制音频“你好,欢迎!”, 分别以采样频率、2 倍采样频率和 1/2 采样频率存为三个 wav 文件
import pyaudio # 导入 Pyaudio 库
import wave # 导入 wave 库
CHUNK = 1024 # 设定缓存区帧数为 1024
FORMAT = pyaudio.paInt16 # 设定数据流采样深度为 16 位
CHANNELS = 1 # 设置声卡通道为 1
RATE = 16000 # 设置采样率
RECORD_SECONDS = 5 # 设置记录秒数
pa = pyaudio.PyAudio() # 实例化一个 Pyaudio 对象
beipin = [1,2,0.5]
wavename = ['1.wav','2.wav','3.wav']
stream = pa.open( format=FORMAT, channels=CHANNELS, rate=RATE, input=True,
frames_per_buffer=CHUNK)
print("* recording") # 打印开始“录音”标志
frames = [] # 创建一个新列表,用于存储采集到的的数据
#开启循环采样直至采集到所需的样本数量
for i in range(0, int(RATE / CHUNK * RECORD_SECONDS)):
data = stream.read(CHUNK) # 从数据流中读取样本
frames.append(data) # 将该样本记录至列表中
print("* done recording") # 打印“完成录音”标志
stream.stop_stream() # 关闭数据流
stream.close() # 关闭声卡
pa.terminate() # 终止 PyAudio
for i in range(3):
# 设定存储录音的 WAV 文件的基本信息
WAVE_OUTPUT_FILENAME = wavename[i]
wf = wave.open(WAVE_OUTPUT_FILENAME, 'wb')
wf.setnchannels(CHANNELS)
wf.setsampwidth(pa.get_sample_size(FORMAT))
wf.setframerate(RATE * beipin[i])
wf.writeframes(b''.join(frames))
wf.close()
画图函数
from scipy.io import wavfile
#from speechlib import *
import numpy as np
import matplotlib.pyplot as plt
plt.rcParams['font.family'] = ['sans-serif'] #显示中文标签
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus']=False #用来正常显示负号
WAVE_OUTPUT_FILENAME = ['1.wav','2.wav','3.wav']
xtext = ['录制信号(采样频率)','录制信号(2倍采样频率)','录制信号((1/2))倍采样频率']
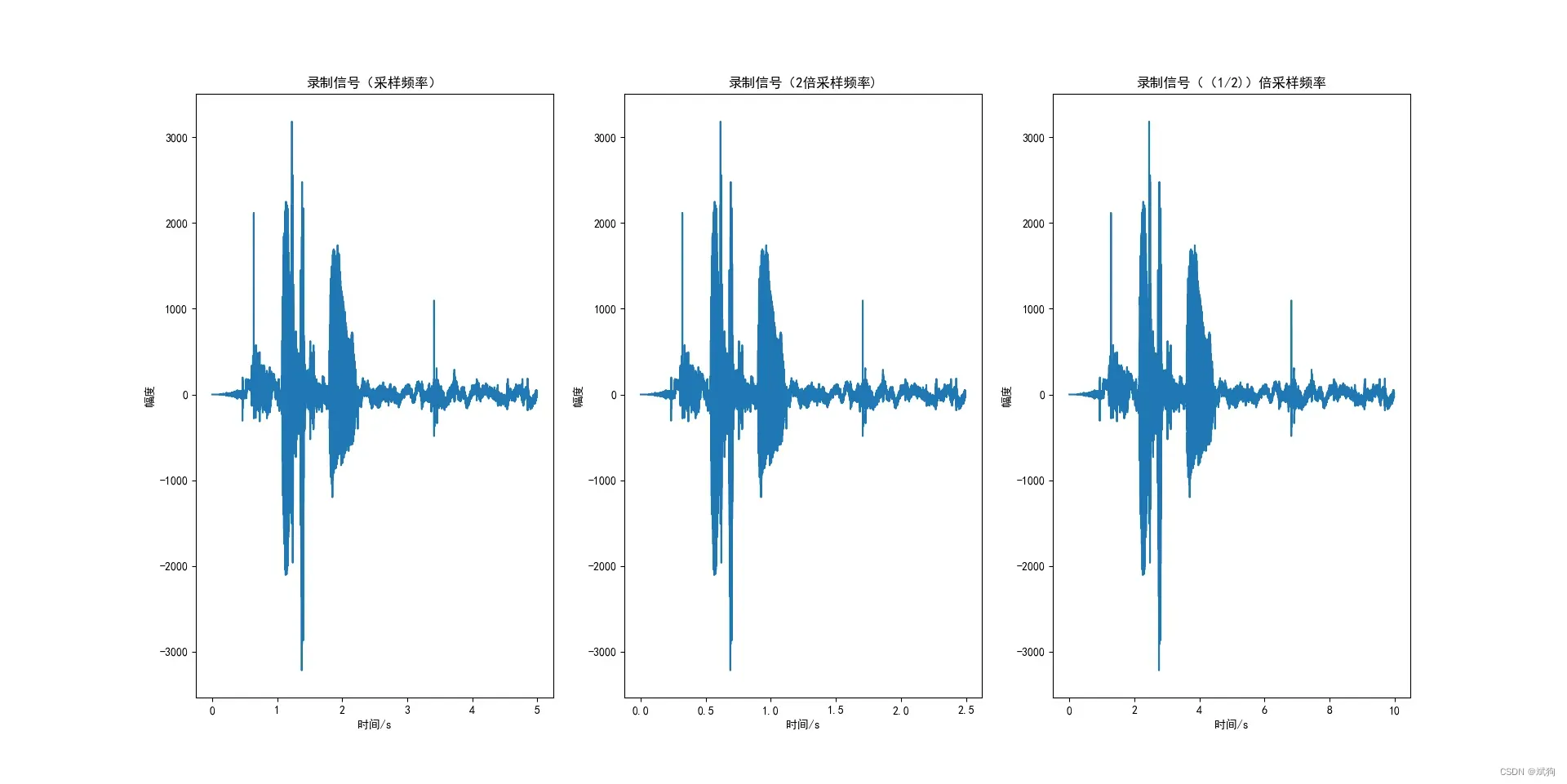
for i in range(len(WAVE_OUTPUT_FILENAME)):
(fs, sound) = wavfile.read(WAVE_OUTPUT_FILENAME[i])
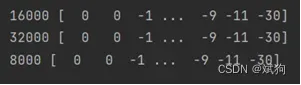
print(fs,sound)
t = np.array([i/fs for i in range(sound.size)])
plt.subplot(1,3,i+1)
plt.plot(t,sound)
plt.title(xtext[i])
plt.xlabel('时间/s')
plt.ylabel('幅度')
plt.show()
三幅图像对应的采样频率以及采样点
播放音频.py
作用:可以听一下录制好的音频
import pyaudio # 导入 Pyaudio 库
import wave # 导入 wave 库
CHUNK = 1024 # 定义数据流块
wf = wave.open('1.wav', 'rb') # 以只读方式打开需要播放的文件
pa = pyaudio.PyAudio() # 实例化一个 Pyaudio 对象
# 使用该对象打开声卡,并从 wf 中获取采样深度
stream = pa.open( format= pa.get_format_from_width(wf.getsampwidth()), channels=
wf.getnchannels(), rate= wf.getframerate(), output=True)
data = wf.readframes(CHUNK) # 读取数据
while data != b'': # 开始循环以播放音频
stream.write(data) # 向数据流中写入数据
data = wf.readframes(CHUNK) # 再次读取数据
print('while 循环中!') # 设定循环标语
stream.stop_stream() # 停止数据流
stream.close() # 关闭声卡
pa.terminate() # 终止 PyAudio
print(wf.getframerate())
总结
- 可以很明显看出来,2倍采样频率时间为原频率的一半,1/2采样频率的时间为原采样频率的两倍
- 2倍采样频率播放速度快,1/2采样频率播放速度慢
- 波形都一样
文章出处登录后可见!
已经登录?立即刷新