本文不使用“列”,“行”这样的方式描述合并。为了更加形象,采用“左右”,“上下”这样的措辞
1. append
append()函数用于将其他dataframe的行添加到给定dataframe的末尾,即上下连接,并返回一个新的dataframe对象。新列和新单元格将插入到原始DataFrame中,并用NaN值填充。
df1 = pd.DataFrame({"x":[15, 25, 37, 42],
"y":[24, 38, 18, 45]})
df2 = pd.DataFrame({"x":[15, 25, 37],
"y":[24, 38, 45]})
df = df1.append(df2)
print('******************df1*******************')
print(df1)
print('******************df2*******************')
print(df2)
print('******************df*******************')
print(df)

注意:使用append方法将会出现警告,因为append方法将弃用,在未来版本中从Panda中删除。官方推荐使用concat
替换方法
df = pd.concat([df1, df2], ignore_index=False)
df1 = pd.DataFrame({"x":[15, 25, 37, 42],
"y":[24, 38, 18, 45]})
df2 = pd.DataFrame({"x":[25, 15, 12],
"y":[47, 24, 17],
"z":[38, 12, 45]})
df = df1.append(df2)
print('******************df1*******************')
print(df1)
print('******************df2*******************')
print(df2)
print('******************df*******************')
print(df)

2. join
join()函数默认情况下以索引为基准,将索引相同的数据合并到一起,实行左右合并。没有的NAN补全。
df1 = pd.DataFrame({"A": ["A0", "A1", "A1"],
"B": ["B0", "B1", "B2"]},
index=["K0", "K1", "K2"])
df2 = pd.DataFrame({"C": ["C1", "C2", "C3"],
"D": ["D0", "D1", "D2"]},
index=["K0", "K1", "K3"])
df3 = df1.join(df2) # 以df1为基准,df2没有的索引,数据补NaN
df4 = df1.join(df2, how="outer") # 以df1和df2索引的并集为基准,同样的缺少的数据补NaN
df5 = df1.join(df2, how="inner") # 以df1和df2索引的交集为基准,即只筛选df1和df2相同索引的数据拼接
print("******************df1*******************")
print(df1)
print("******************df2*******************")
print(df2)
print("******************df3*******************")
print(df3)
print("******************df4*******************")
print(df4)
print("******************df5*******************")
print(df5)

3. concat
pandas.concat(objs, axis=0, join=‘outer’, ignore_index=False)
可以左右连接,可以上下连接(默认:axis=0)用法和append相似
df1 = pd.DataFrame({'A': ['A0', 'A1', 'A2', 'A3'],
'B': ['B0', 'B1', 'B2', 'B3'],
'C': ['C0', 'C1', 'C2', 'C3'],
'D': ['D0', 'D1', 'D2', 'D3'],
'E': ['E0', 'E1', 'E2', 'E3']
})
df2 = pd.DataFrame({ 'A': ['A4', 'A5', 'A6', 'A7'],
'B': ['B4', 'B5', 'B6', 'B7'],
'C': ['C4', 'C5', 'C6', 'C7'],
'D': ['D4', 'D5', 'D6', 'D7'],
'F': ['F4', 'F5', 'F6', 'F7']
})
df3 = pd.concat([df1, df2], ignore_index=True)
df4 = pd.concat([df1,df2], ignore_index=True, join="inner")
df5 = pd.concat([df1, df2], axis=1)
print("******************df1*******************")
print(df1)
print("******************df2*******************")
print(df2)
print("******************df3*******************")
print(df3)
print("******************df4*******************")
print(df4)
print("******************df5*******************")
print(df5)

4. merge
pd.merge(left, right, how=‘inner’, on=None, left_on=None, right_on=None)
df1 = pd.DataFrame({"key": ["one", "two", "two"],
"data1": np.arange(3)})
df2 = pd.DataFrame({"key": ["one", "three", "three"],
"data2": np.arange(3)})
df3 = pd.merge(df1, df2) # 默认以内连接合并,只保留两个df相同列中元素值相同的记录行
print("******************df1*******************")
print(df1)
print("******************df2*******************")
print(df2)
print("******************df3*******************")
print(df3)
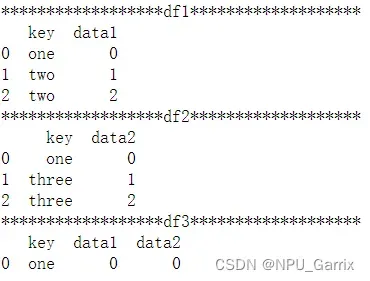
df1 = pd.DataFrame({"key": ["one", "two", "two"],
"data1": np.arange(3)})
df2 = pd.DataFrame({"key": ["one", "three", "three"],
"data2": np.arange(3)})
df3 = pd.merge(df1, df2, how="left") # 以左连接的方式合并,保留左数据框df1的所有记录行,若右数据框df2中没有相应数据则用NaN填充
df4 = pd.merge(df1, df2 ,how="right") # 以右连接的方式合并,保留右数据框df2的所有记录行,若左数据框df1中没有相应数据则用NaN填充。
df5 = pd.merge(df1, df2 ,how="outer") # 以外连接的方式合并,保留左右数据框的所有记录行,缺失的数据用NaN填充
print("******************df1*******************")
print(df1)
print("******************df2*******************")
print(df2)
print("******************df3*******************")
print(df3)
print("******************df4*******************")
print(df4)
print("******************df5*******************")
print(df5)

上述情况是两个dataframe中都存在相同列名,当两个DataFrame中不存在相同列名的情况,但是又希望依据第一个DataFrame中的列A和第二个DataFrame中的列B进行两个DataFrame合并(组合查询)的时候,可以使用left_on和right_on参数实现。
df1 = pd.DataFrame({'key1':['X','Y','Z'], 'value1':[1,2,3]})
df2 = pd.DataFrame({'key2':['A','B','Z'], 'value2':[4,5,6]})
df3 = pd.merge(df1, df2, left_on='key1', right_on='key2')
print("******************df1*******************")
print(df1)
print("******************df2*******************")
print(df2)
print("******************df3*******************")
print(df3)

4.1 one-to-one 一对一
left = pd.DataFrame({'sno': [11, 12, 13, 14],
'name': ['name_a', 'name_b', 'name_c', 'name_d']
})
right = pd.DataFrame({'sno': [11, 12, 13, 14],
'age': ['21', '22', '23', '24']
})
df = pd.merge(left, right, on='sno')
print("******************left*******************")
print(left)
print("******************right*******************")
print(right)
print("******************df*******************")
print(df)

4.2 one-to-many 一对多关系的
left = pd.DataFrame({'sno': [11, 12, 13, 14],
'name': ['name_a', 'name_b', 'name_c', 'name_d']
})
right = pd.DataFrame({'sno': [11, 11, 11, 12, 12, 13],
'grade': ['语文88', '数学90', '英语75','语文66', '数学55', '英语29']
})
df = pd.merge(left, right, on='sno') # 数目以多的一边为准, 结果数量会出现乘法
print("******************left*******************")
print(left)
print("******************right*******************")
print(right)
print("******************df*******************")
print(df)

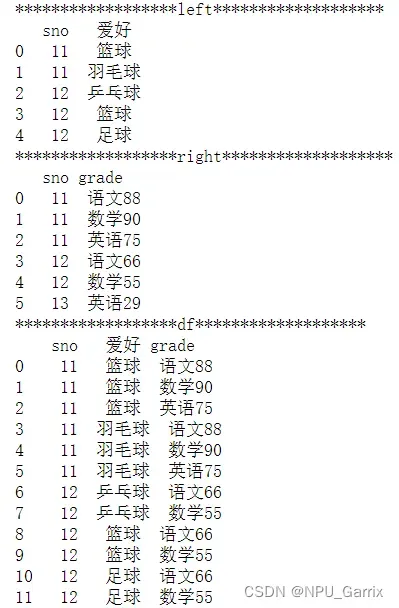
4.3 many-to-many 多对多关系
left = pd.DataFrame({'sno': [11, 11, 12, 12,12],
'爱好': ['篮球', '羽毛球', '乒乓球', '篮球', "足球"]
})
right = pd.DataFrame({'sno': [11, 11, 11, 12, 12, 13],
'grade': ['语文88', '数学90', '英语75','语文66', '数学55', '英语29']
})
df = pd.merge(left, right, on='sno')
print("******************left*******************")
print(left)
print("******************right*******************")
print(right)
print("******************df*******************")
print(df)
文章出处登录后可见!
已经登录?立即刷新