文章目录
本文参加新星计划人工智能(Pytorch)赛道:https://bbs.csdn.net/topics/613989052
一、PyTorch 简介

- PyTorch 是一个基于 Torch 的 Python 开源机器学习库,用于自然语言处理等应用程序。它主要由 Facebook 的人工智能小组开发,不仅能够实现强大的 GPU 加速,同时还支持动态神经网络,这一点是现在很多主流框架如 TensorFlow 都不支持的。
- PyTorch 提供了两个高级功能:
- (1) 具有强大的 GPU 加速的张量计算(如 Numpy 库等)。
- (2) 包含自动求导系统的深度神经网络。
- TensorFlow 和 Caffe 都是命令式的编程语言,而且是静态的,首先必须构建一个神经网络,然后一次又一次使用相同的结构,如果想要改变网络的结构,就必须从头开始。但是对于 PyTorch,通过反向求导技术,可以零延迟地任意改变神经网络的行为,而且实现速度快。
- 这一灵活性是 PyTorch 对比 TensorFlow 的最大优势。除此以外,PyTorch 的代码对比 TensorFlow 而言,更加简洁直观,底层代码也更容易看懂,这对于使用它的人来说理解底层肯定是一件令人高兴的事。
- 所以,总结一下 PyTorch 的优点:
- (1) 支持 GPU。
- (2) 灵活,支持动态神经网络。
- (3) 底层代码易于理解。
- (4) 命令式体验。
- (4) 自定义扩展。
当然,现今任何一个深度学习框架都有其缺点,PyTorch 也不例外,对比 TensorFlow,其全面性处于劣势,目前 PyTorch 还不支持快速傅里叶、沿维翻转张量和检查无穷与非数值张量;针对移动端、嵌入式部署以及高性能服务器端的部署其性能表现有待提升;其次因为这个框架较新,使得他的社区没有那么强大,在文档方面其大多数没有文档。
二、PyTorch 软件框架
1. Anaconda 下载
- 访问 Anaconda 官网,点击页面中的 Download,这个直接是 Windows 版本。
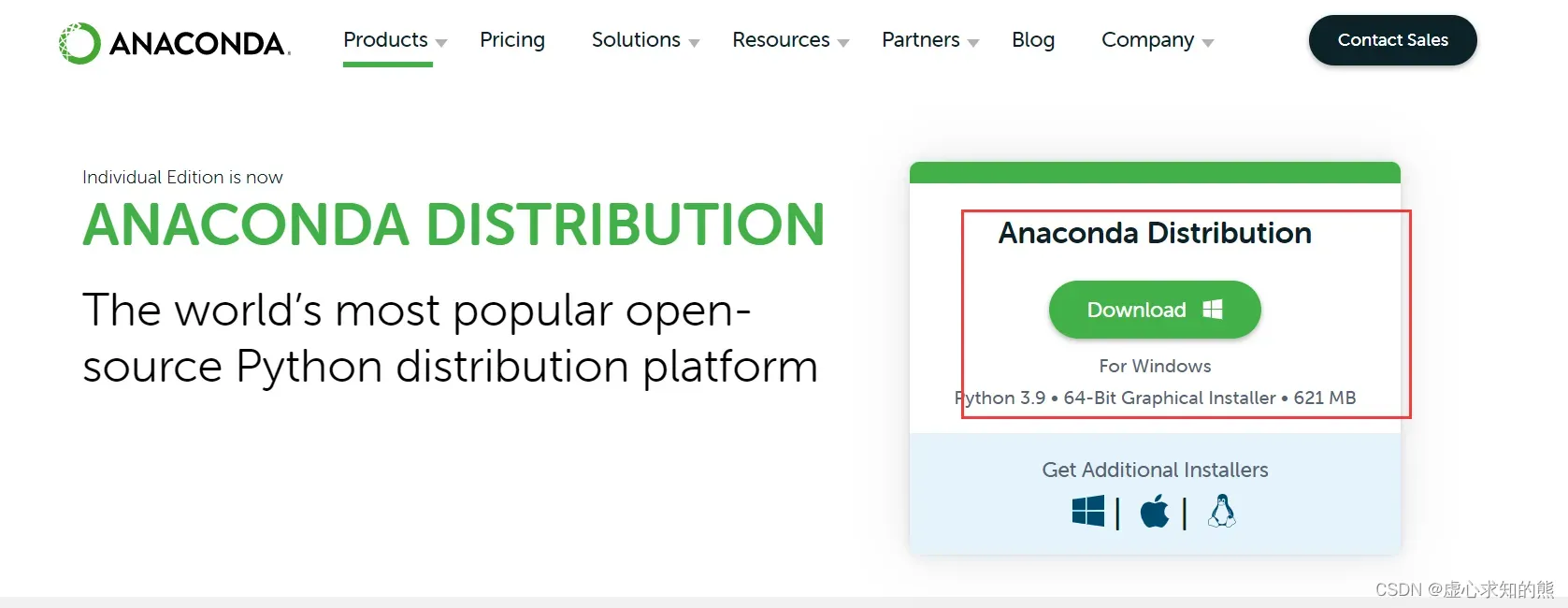
- 如果是其他版本的,点击 Download 下的三个按钮,分别对应 Windows,MacOS 和 Linux 三种。此时再下载对应的版本即可。

- 但是官网上的 Anaconda 下载会比较慢,因此,我们可以在镜像网站上进行下载,镜像网站的下载速度是高于官网的。
- 镜像网站:https://mirrors.tuna.tsinghua.edu.cn/anaconda/archive/

- 在其中选择适合我们的版本即可,镜像网站只有 5.3.1 之前的版本,建议下载 5.3.1 版本。
2. Anaconda 安装
- 下载完成后,即可开始安装。双击安装文件,进入欢迎界面,点击 Next。
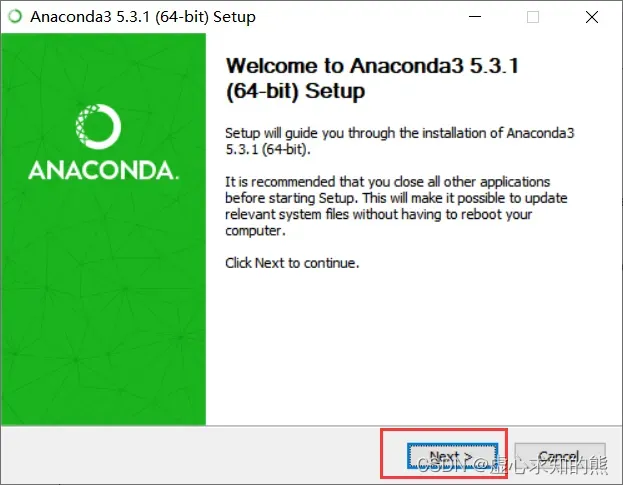
- 点击同意,进入到下一步。
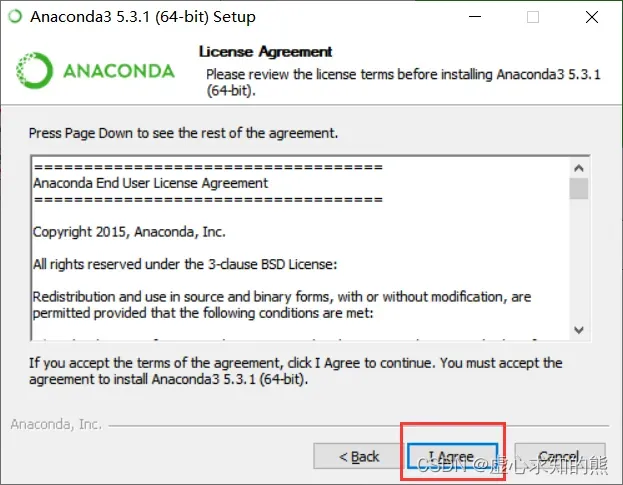
- 选择软件使用权限,是指针对当前登录用户还是所有用户,二者都行,无特殊要求。
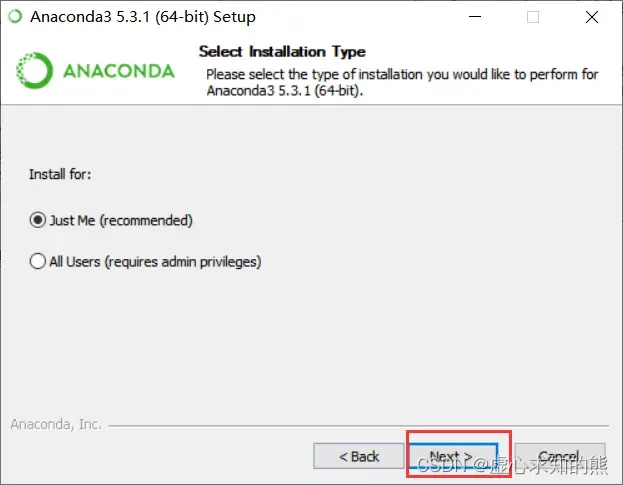
- 选择安装位置,完成安装。
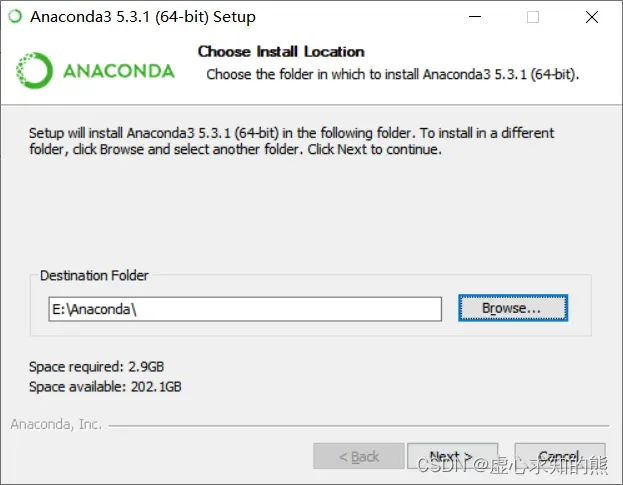
- 如果出现此页面,需要勾选配置环境变量选项。
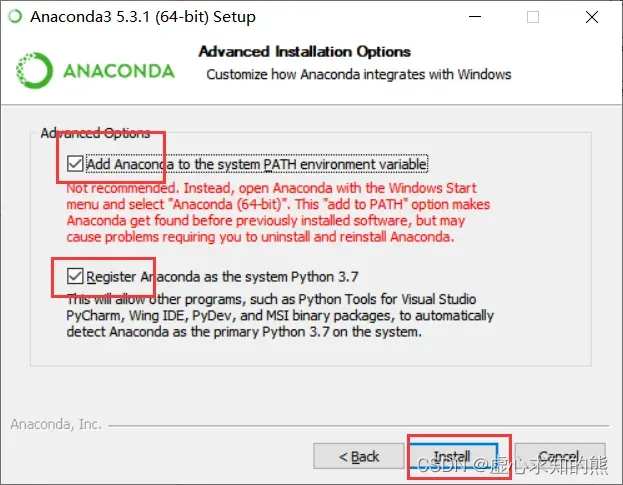
- 无需安装 VS Code,直接跳过即可。
- 之后便安装完成了。
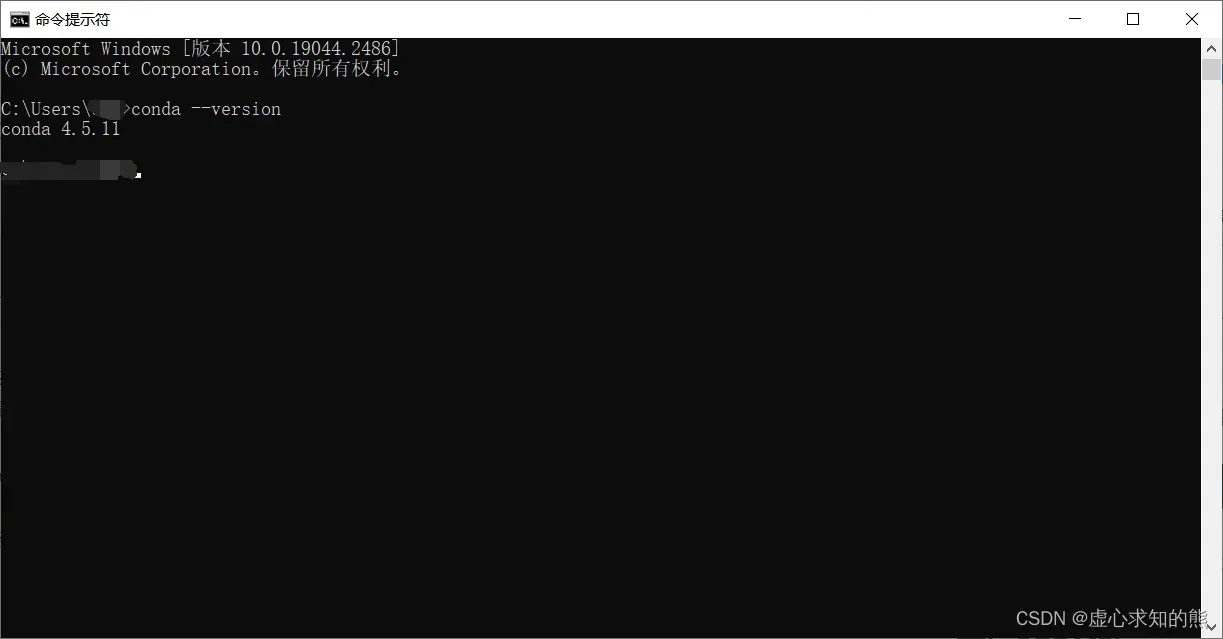
- 最后对是否安装成功进行验证,在 CMD 中输入
conda --version
- 若出现像这样的 conda 版本号即安装成功。
3. Anaconda Navigator 打不开问题(不适用所有)
- 当我们打开 Anaconda Navigator 先是出来几个命令框,然后就找不到 Anaconda Navigator 了,再点击 Anaconda Navigator 时,显示已经打开。
- 产生上述的问题主要是没更新客户端(-client),采取如下步骤解决问题。
- (1) 使用管理员运行:conda prompt。
- (2) 输入 conda update conda 更新 conda,再输入conda update anaconda-navigator 更新。
- 如果出错,则需要修改 .condarc 文件,该文件的目录为:c:\user\你的用户名.condarc,如果没有打开方式就使用文本方式打开。
- 以文本方式打开 .condarc 文件后:先删除 default 那一行,然后将所有 https 都改成 http 即可。
- 接下来执行conda update anaconda-navigator,一般可以执行更新了
- (3) 重置 Navigator:anaconda-navigator –reset。
- (4) 执行命令:conda update anaconda-client,更新 Anaconda 客户端。
- (5) 执行命令:conda update -f anaconda-client。
- (6) 能打开 Navigator 了。
4. PyTorch 环境创建
- PyTorch 的环境创建分为如下几步。
- (1) 以管理员方式运行 Anaconda Prompt,在命令行格式下,输入代码,完成调用清华镜像、建立 PyTorch 环境、安装 PyTorch 、测试 PyTorch 过程。
- (2) 使用清华镜像源,分别输入以下四句代码。
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free/
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main/
conda config --set show_channel_urls yes
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/pytorch/
- (3) 创建 PyTorch 环境,这里我的 Python 版本是 3.7,输入如下代码。
conda create -n pytorch python=3.7
- 之后,弹出提示,输入 y,即可安装。然后,查看环境是否安装成功。
conda info --envs
- 这里我们可以看到 base 和 pytorch 两个环境,* 表示当前正处于的环境。
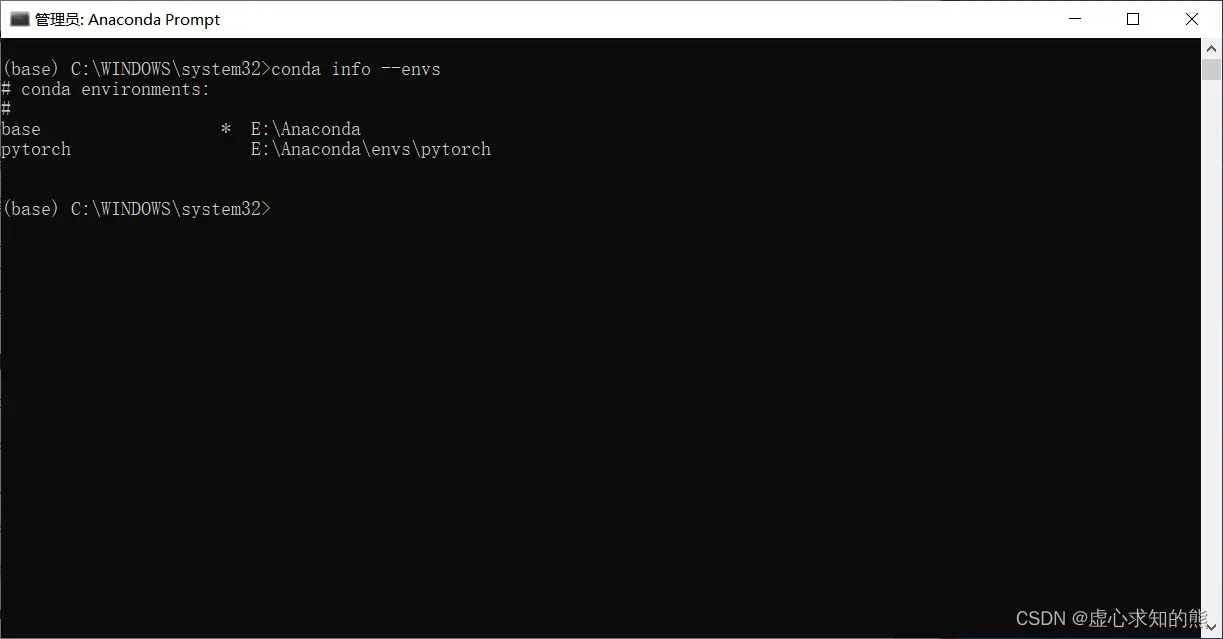
- (4) 输入如下代码,进入 pytorch 环境当中,我们在此环境下安装 PyTorch。
activate pytorch
- 此时,如果我们每一行最初的(base)变为(pytorch )就说明上述步骤已完成。
5. PyTorch 下载
- (1) 进入到 PyTorch 的官网:https://pytorch.org/,选择对应的安装版本。由于电脑配置的相关问题,这里选择安装 PyTorch-CPU 版本。
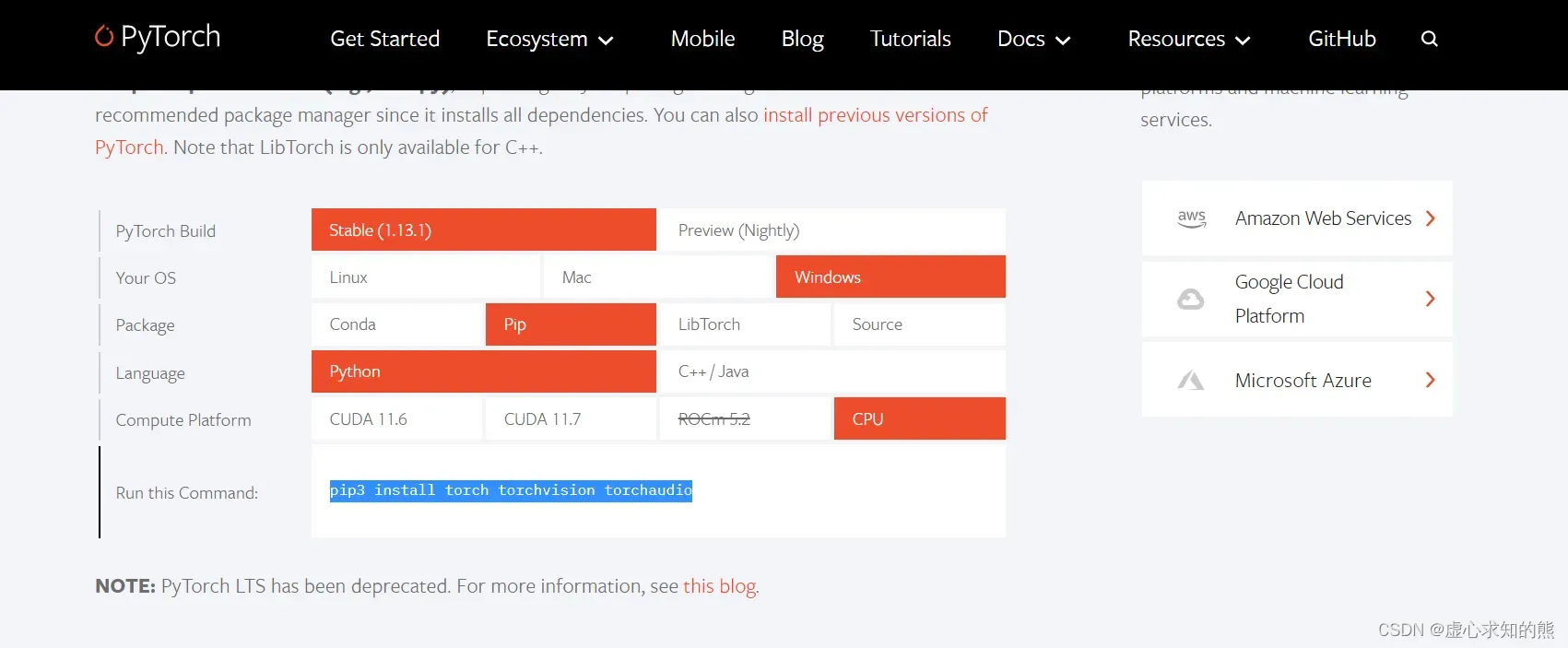
- (2) 输入官网提供的运行代码,这里每个人的运行代码都不相同,大家输入自己的即可,弹出提示,输入 y,即可完成安装,显示 done。
pip3 install torch torchvision torchaudio
- 跟 Anaconda 的问题相同,在官网上下载速度实在是过于缓慢,因此大家可以使用清华镜像源进行安装,此处就不过多叙述,本人直接官网下载安装的。
- (3) 在 PyTorch 下载完成后,对其是否安装完成进行测试。
- 激活 PyTorch :activate pytorch
- 进入 PyTorch :python
- 测试 numpy:import numpy
- 测试 PyTorch :import torch
- 如果以上步骤都没问题,那么安装成功。

6. Jupyter 中配置 PyTorch
- (1) 打开 Anaconda Prompt。
- (2) 进入安装好的 PyTorch 环境。
conda activate pytorch #pytorch3.8 是之前建立的环境名称,可修改为自己建立名称

- (3) 安装 package:nb_conda。
conda install nb_conda
- (4) 安装完成后,输入 jupyter notbook 就可以打开 Jupyter 了。
jupyter notbook
- 如果中间出现了解决 python.exe 无法找到程序输入点 … 于动态链接库 …pythoncom37.dll 的弹窗提示这类问题,只需要找到对应目录,将 pythoncom37.dll 删除即可。
三、PyTorch 基本使用方法
- 我们可以通过
torch.__version__查看自己的 PyTorch 版本,我的是 CPU 版本的 1.13.1,示例如下:
import torch
torch.__version__
#'1.13.1+cpu'
- 我们可以通过
torch.empty()生成一个矩阵,但未初始化。
x = torch.empty(5, 3)
x
#tensor([[8.9082e-39, 9.9184e-39, 8.4490e-39],
# [9.6429e-39, 1.0653e-38, 1.0469e-38],
# [4.2246e-39, 1.0378e-38, 9.6429e-39],
# [9.2755e-39, 9.7346e-39, 1.0745e-38],
# [1.0102e-38, 9.9184e-39, 6.2342e-19]])
- 我们可以通过
torch.rand()生成一个随机值的矩阵。
x = torch.rand(5, 3)
x
#tensor([[0.1452, 0.4816, 0.4507],
# [0.1991, 0.1799, 0.5055],
# [0.6840, 0.6698, 0.3320],
# [0.5095, 0.7218, 0.6996],
# [0.2091, 0.1717, 0.0504]])
- 我们可以通过
torch.zeros()生成一个全零矩阵。
x = torch.zeros(5, 3, dtype=torch.long)
x
#tensor([[0, 0, 0],
# [0, 0, 0],
# [0, 0, 0],
# [0, 0, 0],
# [0, 0, 0]])
- 我们可以直接将数据传入矩阵当中。
x = torch.tensor([5.5, 3])
x
#tensor([5.5000, 3.0000])
- 我们可以通过
size()查看矩阵的大小,也就是矩阵有几行几列。
x.size()
#torch.Size([5, 3])
- 我们可以通过
view()操作改变矩阵维度。
x = torch.randn(4, 4)
y = x.view(16)
z = x.view(-1, 8)
print(x.size(), y.size(), z.size())
#torch.Size([4, 4]) torch.Size([16]) torch.Size([2, 8])
- 同时,torch 也可以和 numpy 进行协同操作,具体可见如下示例:
- 示例 1:
import numpy as np
a = torch.ones(5)
b = a.numpy()
b
#array([1., 1., 1., 1., 1.], dtype=float32)
- 示例 2:
import numpy as np
a = np.ones(5)
b = torch.from_numpy(a)
b
#tensor([1., 1., 1., 1., 1.], dtype=torch.float64)
四、tensor 的几种形状
- 由于要进行 tensor 的学习,因此,我们先导入我们需要的库。
import torch
from torch import tensor
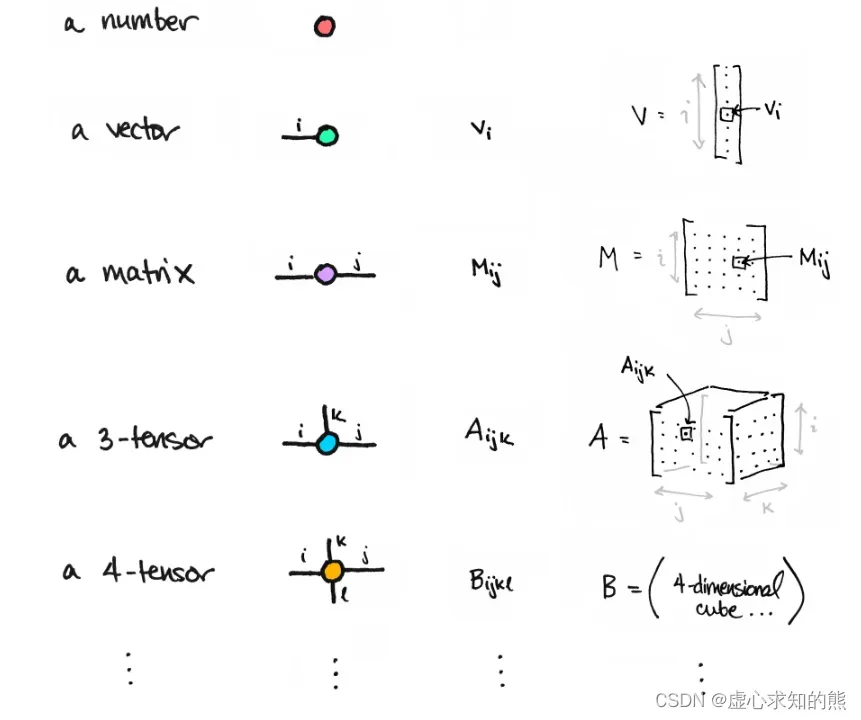
1. Scalar(标量)
- Scalar 通常就是一个数值。
- 我们可以先使用
tensor()生成一个数。
x = tensor(42.)
x
#tensor(42.)
- 我们可以通过
dim()查看他的维度。
x.dim()
#0
- 我们可以通过
item()将张量转变为元素。 - 就行 print(x) 和 print(x.item()) 值是不一样的,一个是打印张量,一个是打印元素。
x.item()
#42.0
2. Vector(向量)
- 例如:
[-5., 2., 0.],在深度学习中通常指特征,例如词向量特征,某一维度特征等
- Vector 的操作和 Scalar 是大同小异的,因此,我们便不过多叙述了。
- 示例 1:
v = tensor([1.5, -0.5, 3.0])
v
#tensor([ 1.5000, -0.5000, 3.0000])
- 示例 2:
v.dim()
#1
- 示例 3:
v.size()
#torch.Size([3])
3. Matrix(矩阵)
- Matrix 一般计算的都是矩阵,通常都是多维的。
- 关于矩阵的生成操作,与上述是大体一致的。
M = tensor([[1., 2.], [3., 4.]])
M
#tensor([[1., 2.],
# [3., 4.]])
- 我们可以使用
matmul()进行矩阵的乘法运算。
M.matmul(M)
#tensor([[ 7., 10.],
# [15., 22.]])
- 也可以直接进行矩阵内元素的乘法运算。
M * M
#tensor([[ 1., 4.],
# [ 9., 16.]])
五、PyTorch 的 autograd 机制
1. autograd 机制
- PyTorch 框架最厉害的一件事就是帮我们把返向传播全部计算好了。
- 如果需要求导,我们可以手动定义:
- 示例 1:
x = torch.randn(3,4,requires_grad=True)
x
#tensor([[-0.4847, 0.7512, -1.0082, 2.2007],
# [ 1.0067, 0.3669, -1.5128, -1.3823],
# [ 0.8001, -1.6713, 0.0755, 0.9826]], requires_grad=True)
- 示例 2:
x = torch.randn(3,4)
x.requires_grad=True
x
#tensor([[ 0.6438, 0.4278, 0.8278, -0.1493],
# [-0.8396, 1.3533, 0.6111, 1.8616],
# [-1.0954, 1.8096, 1.3869, -1.7984]], requires_grad=True)
- 示例 3:
b = torch.randn(3,4,requires_grad=True)
t = x + b
y = t.sum()
y
#tensor(7.9532, grad_fn=<SumBackward0>)
- 示例 4:(y.backward() 时,如果 y 是标量(scalar),则不需要为 backward() 传入任何参数;如果 y 是张量(tensor),需要传入一个与 y 同形的 tensor(张量))
y.backward()
b.grad
#tensor([[1., 1., 1., 1.],
# [1., 1., 1., 1.],
# [1., 1., 1., 1.]])
- 虽然我们没有指定 t 的 requires_grad 但是需要用到它,也会默认为 True 的。
x.requires_grad, b.requires_grad, t.requires_grad
#(True, True, True)
2. 举例说明
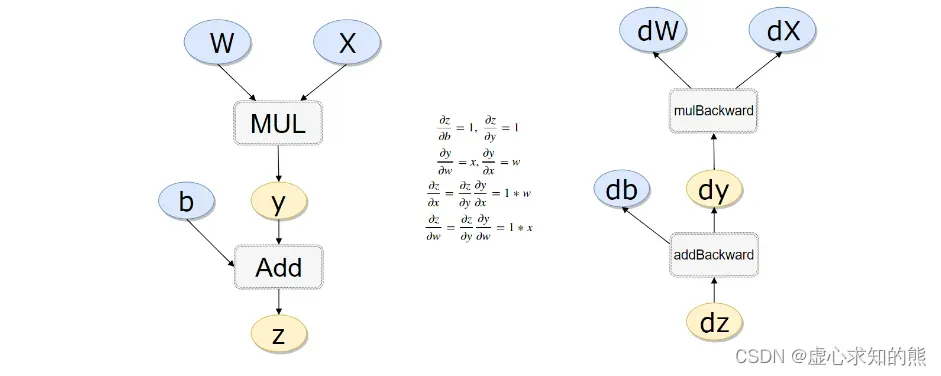
- 整体的计算流程如下:
x = torch.rand(1)
b = torch.rand(1, requires_grad = True)
w = torch.rand(1, requires_grad = True)
y = w * x
z = y + b
x.requires_grad, b.requires_grad, w.requires_grad, y.requires_grad#注意y也是需要的
#(False, True, True, True)
x.is_leaf, w.is_leaf, b.is_leaf, y.is_leaf, z.is_leaf
#(True, True, True, False, False)
- 返向传播计算。
z.backward(retain_graph=True)#如果不清空会累加起来
w.grad
#tensor([0.7954])
b.grad
#tensor([1.])
3. 一个简单的线性回归模型
- 我们构造一组输入数据 X 和其对应的标签 y。
x_values = [i for i in range(11)]
x_train = np.array(x_values, dtype=np.float32)
x_train = x_train.reshape(-1, 1)
x_train.shape
#(11, 1)
y_values = [2*i + 1 for i in x_values]
y_train = np.array(y_values, dtype=np.float32)
y_train = y_train.reshape(-1, 1)
y_train.shape
#(11, 1)
- 导入线性回归模型需要的库。
import torch
import torch.nn as nn
- 其实线性回归就是一个不加激活函数的全连接层。
class LinearRegressionModel(nn.Module):
def __init__(self, input_dim, output_dim):
super(LinearRegressionModel, self).__init__()
self.linear = nn.Linear(input_dim, output_dim)
def forward(self, x):
out = self.linear(x)
return out
input_dim = 1
output_dim = 1
model = LinearRegressionModel(input_dim, output_dim)
model
#LinearRegressionModel(
# (linear): Linear(in_features=1, out_features=1, bias=True)
#)
- 指定好参数和损失函数。
epochs = 1000
learning_rate = 0.01
optimizer = torch.optim.SGD(model.parameters(), lr=learning_rate)
criterion = nn.MSELoss()
- 在指定好参数和损失函数后,就可以训练模型了。
for epoch in range(epochs):
epoch += 1
# 注意转行成tensor
inputs = torch.from_numpy(x_train)
labels = torch.from_numpy(y_train)
# 梯度要清零每一次迭代
optimizer.zero_grad()
# 前向传播
outputs = model(inputs)
# 计算损失
loss = criterion(outputs, labels)
# 返向传播
loss.backward()
# 更新权重参数
optimizer.step()
if epoch % 50 == 0:
print('epoch {}, loss {}'.format(epoch, loss.item()))
#epoch 50, loss 0.22157077491283417
#epoch 100, loss 0.12637567520141602
#epoch 150, loss 0.07208002358675003
#epoch 200, loss 0.04111171141266823
#epoch 250, loss 0.023448562249541283
#epoch 300, loss 0.01337424572557211
#epoch 350, loss 0.007628156337887049
#epoch 400, loss 0.004350822884589434
#epoch 450, loss 0.0024815555661916733
#epoch 500, loss 0.0014153871452435851
#epoch 550, loss 0.000807293108664453
#epoch 600, loss 0.00046044986811466515
#epoch 650, loss 0.00026261876337230206
#epoch 700, loss 0.0001497901976108551
#epoch 750, loss 8.543623698642477e-05
#epoch 800, loss 4.8729089030530304e-05
#epoch 900, loss 1.58514467329951e-05
#epoch 950, loss 9.042541933013126e-06
#epoch 1000, loss 5.158052317710826e-06
- 得到测试模型的预测结果。
predicted = model(torch.from_numpy(x_train).requires_grad_()).data.numpy()
predicted
#array([[ 0.9957756],
# [ 2.9963837],
# [ 4.996992 ],
# [ 6.9976 ],
# [ 8.998208 ],
# [10.9988165],
# [12.999424 ],
# [15.000032 ],
# [17.00064 ],
# [19.00125 ],
# [21.001858 ]], dtype=float32)
- 将得到模型进行保存与读取。
torch.save(model.state_dict(), 'model.pkl')
model.load_state_dict(torch.load('model.pkl'))
#<All keys matched successfully>
- 如果使用 GPU 进行模型训练,只需要把数据和模型传入到 cuda 里面就可以了。
import torch
import torch.nn as nn
import numpy as np
class LinearRegressionModel(nn.Module):
def __init__(self, input_dim, output_dim):
super(LinearRegressionModel, self).__init__()
self.linear = nn.Linear(input_dim, output_dim)
def forward(self, x):
out = self.linear(x)
return out
input_dim = 1
output_dim = 1
model = LinearRegressionModel(input_dim, output_dim)
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
model.to(device)
criterion = nn.MSELoss()
learning_rate = 0.01
optimizer = torch.optim.SGD(model.parameters(), lr=learning_rate)
epochs = 1000
for epoch in range(epochs):
epoch += 1
inputs = torch.from_numpy(x_train).to(device)
labels = torch.from_numpy(y_train).to(device)
optimizer.zero_grad()
outputs = model(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
if epoch % 50 == 0:
print('epoch {}, loss {}'.format(epoch, loss.item()))
#epoch 50, loss 0.057580433785915375
#epoch 100, loss 0.03284168243408203
#epoch 150, loss 0.01873171515762806
#epoch 200, loss 0.010683886706829071
#epoch 250, loss 0.006093675270676613
#epoch 300, loss 0.0034756092354655266
#epoch 350, loss 0.0019823340699076653
#epoch 400, loss 0.0011306683300063014
#epoch 450, loss 0.0006449012435041368
#epoch 500, loss 0.0003678193606901914
#epoch 550, loss 0.0002097855758620426
#epoch 600, loss 0.00011965946032432839
#epoch 650, loss 6.825226591899991e-05
#epoch 700, loss 3.892400854965672e-05
#epoch 750, loss 2.2203324988367967e-05
#epoch 800, loss 1.2662595509027597e-05
#epoch 850, loss 7.223141892609419e-06
#epoch 900, loss 4.118806373298867e-06
#epoch 950, loss 2.349547230551252e-06
#epoch 1000, loss 1.3400465377344517e-06
文章出处登录后可见!
已经登录?立即刷新