CLIP模型解决了一个多模态问题
代码地址:
https://github.com/yyz159756/CLIP-VIT-
文章目录
- 概述
- CLIP
- 代码实现
- 划分训练集和测试集
- 统计所有图片的每个通道的均值和标准差
- 搜索图片引擎
- 边角料
概述
问题描述:输入一张照片,从数据库中找到最相近的一张照片
解决思路:将图片emb,用余弦 相似度计算图片emb,排序返回topk的图片
图片embbing预训练模型选择,图片表征模型那就有太多的选择了,一种是纯粹的图像分类的预训练模型,比如用resnet,VIT,VGG,纯粹基于图像识别得到的预训练模型,再或者是自监督学习的MAE得到的encoder emb,
这里我们使用CLIP模型,CLIP是基于图像和文本两个领域的数据训练出来的表征模型
为什么用CLIP模型,而不用视觉通用模型呢?
CLIP优点是同类型的文字和图像有着很高的相似度,所以可以完成一个多模态的搜索任务
CLIP项目地址:https://github.com/openai/CLIP
安装CLIP模型,注意要安装git
pip install git+https://github.com/openai/CLIP.git
CLIP是一个多模态的模型,它不仅仅能表征图像,还能够识别图像中的文字信息
果蔬分类数据集:
https://aistudio.baidu.com/aistudio/datasetdetail/119023/0
下载后解压到data/raw
只能下载数据集,只有train,因此我们还得自己构建测试集和验证集
CLIP
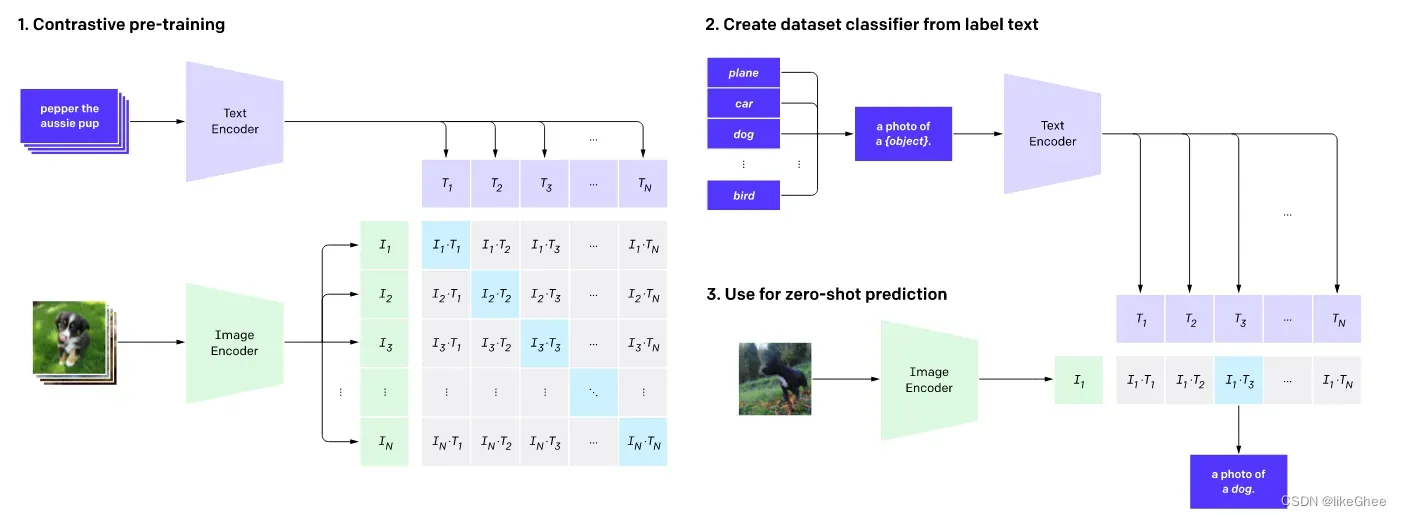
利用text信息监督视觉任务自训练,本质就是将分类任务化成了图文匹配任务,效果可与全监督方法相当
《Learning transferable visual models from natural language supervision》
核心思想:对比学习
I1是图片表征,T1是文字表征,我们希望In和Tn相似度尽可能的大,表示文字和图片是匹配的,要么相似要么不相似进行对比,学会如何将文字和图像连接起来的一个编码
一个是图像编码器(resnet或者vit模型),一个文本编码器(transformer模型),是一个经典的双塔模型
伪代码部分写的很清晰,图像经过图像编码器得到图像emb,文字经过编码器得到文字emb,经过l2正则化,直接对两个emb矩阵做dot矩阵乘法,做一个预测任务,预测这个图片是一个什么东西,loss计算交叉熵,总体模型十分的简单,所用的数据集比较大

应用的话,hugging face里面已经有CLIP的模型库了
https://huggingface.co/docs/transformers/model_doc/clip
或者用sentence_transformers库
代码实现
划分训练集和测试集
这部分代码挺常用了,一般图像分类任务数据集都是每个子文件名称表示类别名称,子文件夹中有具体的样本图片
预处理起码做两件事情,转化图片为RGB通道,图片大小规整到同样大小的形状如128×128(我电脑比较破,就64×64了)
split_data.py
统计所有图片的每个通道的均值和标准差
统计一个mean和var
statistic_mean_std.py
我提前统计好了
mean是[0.47043142, 0.43239759, 0.32576062]
var是[0.37251864, 0.35710091, 0.3417497]
因为resnet模型要求图片先归一化
搜索图片引擎
搜索图片引擎,顾名思义就是搜索图片用的,有两种搜索方式,一是以图搜图,二是文字搜图,我在github中实现的是以图搜图功能,文字搜图看最后的边角料就好了,官方给的例子就是以文字搜图的eg了,几行代码搞定,非常简单
下面开始以图搜图的实现
第一步,我们对图像计算表征向量
我们需要加载模型,加载模型可以使用timm和clip库
model = timm.create_model(args.model_name, pretrained=True)
model, preprocess = clip.load(model_name, device=device)
clip的多返回了一个preprocess预处理函数,我们就可以不用自己做预处理(Transformation)
加载好模型后我们需要对train数据集里面的所有的图片做一个表征
我们使用模型的某一层或者最后一层的特征作为图像的抽象表征
all_vectors = extract_features(args, model, image_path='data/val_images', preprocess=preprocess)
第二阶段,预测阶段,找到所有的测试图片,也做一个表征,对图片计算余弦相似度
similarity, keys = get_similarity_matrix(all_vectors)
我们都知道余弦相似度的计算公式
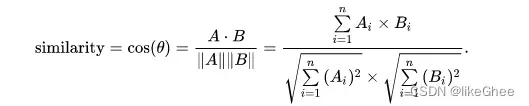
经过线性代数所学,分子可以矩阵×矩阵的转置
[num, dim] × [dim, num] = [num, num]
那么第一行就是第一张照片和所有照片表征的内积,以此类推
那么分母就是向量的模
我们用np的linalg.norm对每一列求一个范数([num, ]),同时维度保持不变,再和它自身转置相乘
那么第一行就是第一张照片的表征模和所有照片表征的模的乘积
计算完余弦相似度后,我们就是要对测试图片和其他图片的余弦相似度进行排序,排序后进行输出
以上是以图搜图的功能
边角料
如果要完成文字搜图的功能那是完全类似的,将文字编码,文字编码和所有图片做一个余弦相似度即可,我们返回topk个图片
下面直接给官方例子,非常的哇塞,也非常的简单有没有
import torch
import clip
from PIL import Image
device = "cuda" if torch.cuda.is_available() else "cpu"
model, preprocess = clip.load("ViT-B/32", device=device)
image = preprocess(Image.open("CLIP.png")).unsqueeze(0).to(device)
text = clip.tokenize(["a diagram", "a dog", "a cat"]).to(device)
with torch.no_grad():
image_features = model.encode_image(image)
text_features = model.encode_text(text)
logits_per_image, logits_per_text = model(image, text)
probs = logits_per_image.softmax(dim=-1).cpu().numpy()
print("Label probs:", probs) # prints: [[0.9927937 0.00421068 0.00299572]]
文章出处登录后可见!