论文:https://arxiv.org/pdf/2210.02414.pdf
相关博客
【自然语言处理】【大模型】Chinchilla:训练计算利用率最优的大语言模型
【自然语言处理】【大模型】大语言模型BLOOM推理工具测试
【自然语言处理】【大模型】GLM-130B:一个开源双语预训练语言模型
【自然语言处理】【大模型】用于大型Transformer的8-bit矩阵乘法介绍
【自然语言处理】【大模型】BLOOM:一个176B参数且可开放获取的多语言模型
【自然语言处理】【大模型】PaLM:基于Pathways的大语言模型
【自然语言处理】【chatGPT系列】大语言模型可以自我改进
【自然语言处理】【ChatGPT系列】WebGPT:基于人类反馈的浏览器辅助问答
【自然语言处理】【ChatGPT系列】FLAN:微调语言模型是Zero-Shot学习器
【自然语言处理】【ChatGPT系列】ChatGPT的智能来自哪里?
【自然语言处理】【ChatGPT系列】大模型的涌现能力
一、简介
大语言模型(LLMs),特别是参数超过100B的模型呈现出诱人的scaling laws,其会突然涌现出zero-shot和few-shot能力。具有175B参数的GPT-3率先对100B尺度的LLM进行了研究:在各种基准上,使用32个标注示例可以显著超越全监督的BERT-Large模型。然而,GPT-3本身以及如何训练仍然是无法公开获得的。训练出如此规模的高质量LLM,并对每个人分享模型和训练过程非常的有价值。
我们的目标是预训练一个开源且高准确率的100B模型。在我们尝试的过程中,我们逐渐意识到相比于训练10B的模型,训练一个100B以上的稠密LLM面临着许多意想不到的技术和工程的挑战,例如预训练效率、稳定性和收敛等。类似的困难也发生在OPT-175B和BLOOM-176B的训练中,进一步证明了GPT-3作为先驱研究的重要性。
在本文中,我们介绍了100B规模模型GLM-130B的预训练,包括工程上的努力、模型设计选择、为了效率和稳定性的训练策略、用于降低推理成本的量化。因为人们已经普遍意识到,枚举训练100B规模LLM的所有可能设计在计算资源上无法负担,因此我们不仅程序训练GLM-130B成功的部分,也介绍许多失败的选择来吸取经验。训练稳定性是这种规模模型能够训练成功的关键因素。不同于OPT-175B中的人工调整学习率,以及BLOOM-176B中使用embedding norm,我们实验了各种选项并发现embedding梯度shrink策略可以显著稳定GLM-130B的训练。
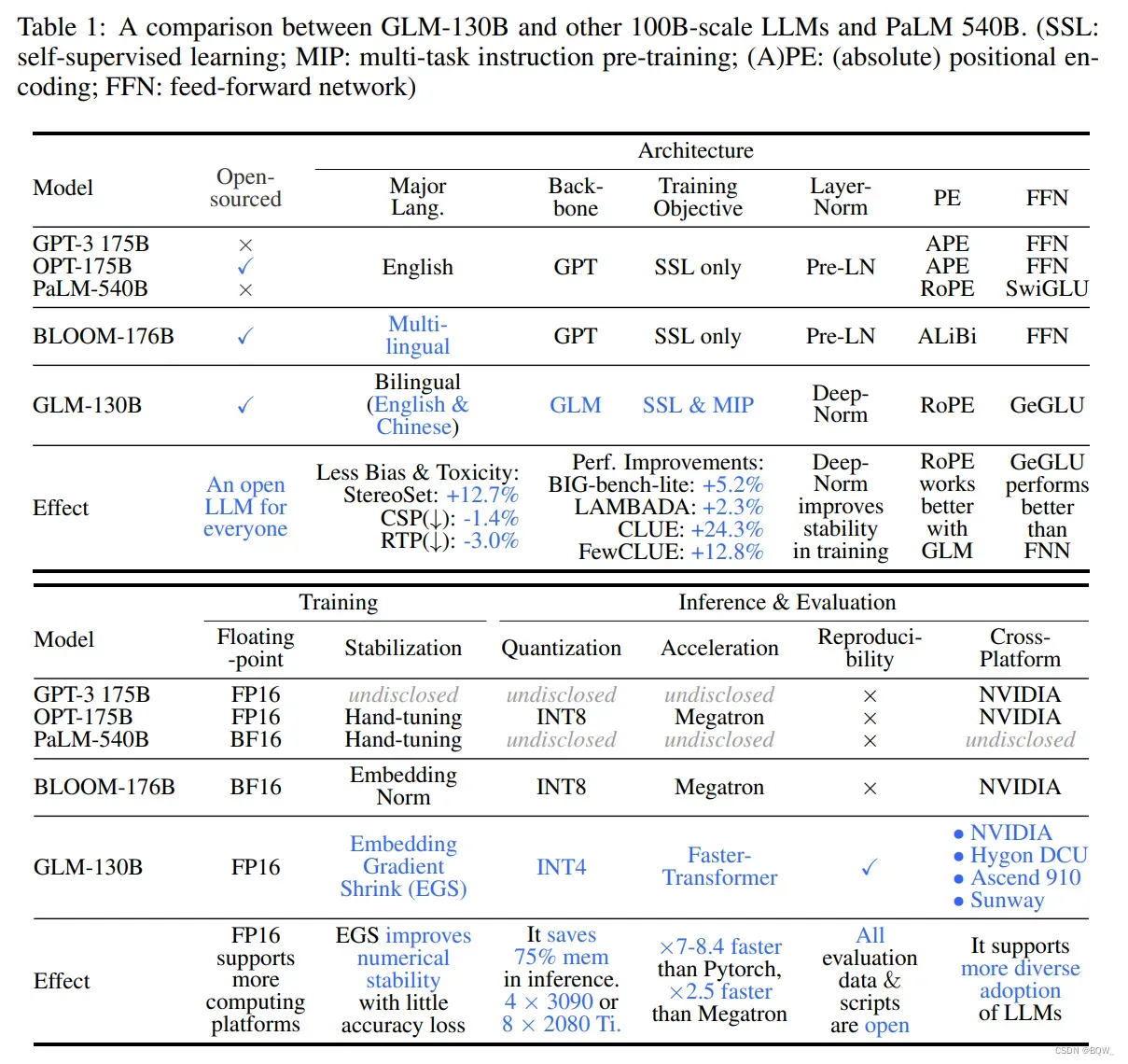
具体来说,GLM-130B是一个具有1300亿参数的双语双向稠密模型,其在96个NVIDIA DGX-100(8*40G)节点的集群上用400B的token进行了预训练,训练从2022年5月6日至2022年7月3日。相比于使用GPT风格的架构,我们采用General Language Model(GLM)算法来利用双向注意力优势和自回归空白填充目标函数。上表1比较了GLM-130B、GPT-3、OPT-175B、BLOOM-176B和PaLM540B。
总的来说,概念独立性和工程上的努力使得GLM-130B在广泛的基准上展现出了超过GPT-3的性能,在许多例子中也超过了PaLM540B,而OPT-175B和BLOOM-176B并没有展现出超越GPT-3的性能。对于zero-shot的表现,在LAMBADA上GLM-130B优于GPT-3 175B(+5.0%)、OPT-175B(+6.5%)和BLOOM-176B(+13.0%),并在BIG-Bench-Lite上优于GPT-3三倍。对于5-shot MMLU任务,其优于GPT-3 175B(+0.9%)和BLOOM-176B(+12.7%)。由于一个包含中文的双语LLM,其显著的优于ERNIE TITAN 3.0 260B,在7 zero-shot CLUE数据集上(+24.26%),以及5 zero-shot FewCLUE(+12.75%)。重要的是,GLM-130B作为一个开放模型,相比于其他100B模型,其偏见和毒性明显小很多。
最后,我们设计GLM-130B的目标是让更多的人进行100B LLM的研究。首先,相比于175B+参数的OPT和BLOOM,130B尺寸能够在单台A100(8*40G)服务器上进行推理。其次,为了进一步减低对GPU的需要,我们在不使用量化感知训练的情况下将GLM-130B量化至INT4的精度,而OPT和BLOOM仅能够达到INT8。由于GLM-130B架构的独特性,GLM-130B的INT4量化引入了可以忽略不计的性能下降,例如LAMBADA的-0.74%甚至在MMLU上+0.05%,使其仍然优于未压缩的GPT-3。这使得GLM-130B在保证性能的情况下,在4xRTX3090(24G)或者8xRTX2080 Ti(11G)上进行快速推理,迄今为止100B LLM所需的最实惠GPU。
二、GLM-130B的设计选择
1. GLM-130B的架构
**GLM作为主干。**大多数近期的100B规模的LLM,例如GPT-3、PaLM、OPT和BLOOM遵循GPT风格的架构,decoder-only自回归语言模型。在GLM-130B中,我们尝试利用双向GLM的潜力作为主干网络。
GLM是一种基于transformer的语言模型,利用自回归空白填充作为训练目标。简单来说,对于文本序列,从其中采样文本片段
,每个
表示连续tokens片段
并被替换为单个mask token,从而形成
。模型被要求使用自回归的方式进行恢复。为了允许被破坏的片段间交互,彼此之间的可见性由一个随机采样的排列决定。预训练目标定义为:
其中,表现序列所有排列的集合,
表示
。
GLM在unmaksed上下文上的双向注意力机制,使GLM-130B与使用单向注意力机制的GPT风格LLM。为了同时支持理解和生成,其混合了两种破坏目标函数,每个由特殊的mask token表示:
- [MASK]:句子中的短空白,其长度被添加至输入的某一个部分;
- [gMASK]:句尾随机长度的长空格,并提供前缀上下文;
概念上来将,具有双向注意力的空白填充目标函数要比GPT风格的模型更有效的压缩上下文:当使用[MASK]时,GLM-130B的行为同BERT和T5;当使用[gMASK]时,GLM-130B的行为类似于PrefixLM。
经验上来说,GLM-130B在zero-shot LAMBADA上实现了创记录的80.2%准确率,优于GPT-3和PaLM。通过设置注意力mask,GLM-130B单向变体可以与GPT-3和OPT-175B媲美。
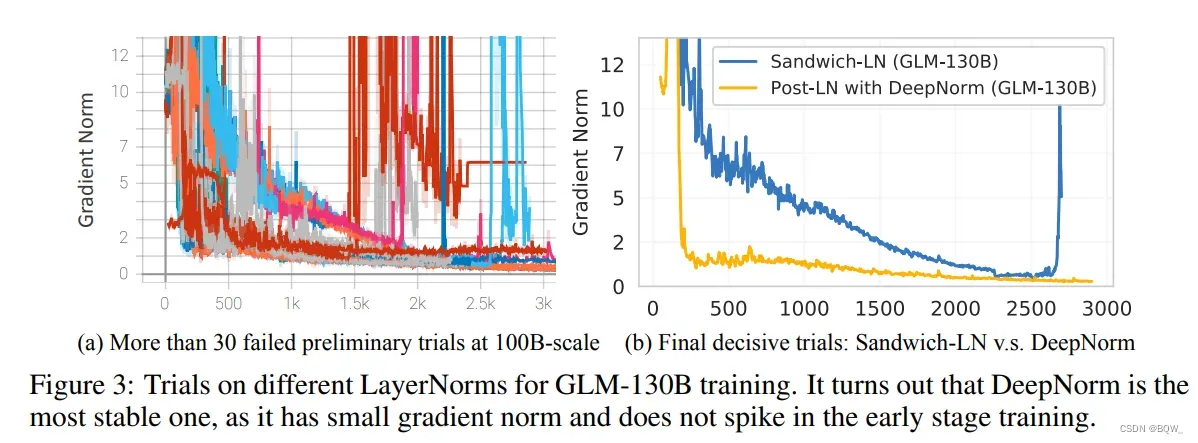
Layer Normalization. 训练LLM的主要挑战是训练不稳定。LN的合适选择有助于稳定LLM的训练。我们对现有的实践进行了实验,Pre-LN、Post-LN和Sandwich-LN,这些都不适合稳定GLM-130B。
我们后面的研究重点放在了Post-LN上,因为其在下游任务上效果很好,虽然其在GLM-130B上不稳定。幸运地是,新提出的DeepNorm产生了很好的训练稳定性。具体来说,给定GLM-130B层的数量N,我们采用
其中,。并在
ffn、v_proj和out_proj上应用了缩放因子为的Xavier初始化。此外,所有的偏差项被初始化为0。上图3展示了GLM-130B的训练稳定性。
位置编码和FFN。我们针对训练稳定性和下游表现,测试了位置编码(PE)和FFN的不同选项。GLM-130B中的位置编码选择了Rotary Positional Encding(RoPE),而不是ALiBi。为了改善Transformer中的FFN,我们选择GLU和GeLU作为激活的替代。
2. GLM-130的预训练设置
受最近工作的启发,GLM-130B预训练目标不仅包含了自监督的GLM自回归空白填充,而且对一小部分token进行了多任务学习。这有助于改善下游的zero-shot表现。
**自监督空白填充(97%tokens)。**回想一下,GLM-130B在这个任务中同时使用了[MASK]和[gMASK]。具体来说,[MASK]用于遮蔽训练token30%的连续片段用于空白填充。片段的长度遵循Poisson分布(),并且添加至输入的15%。对于其他70%的tokens,每个序列的前缀被保留为上下文,[gMASK]被用于遮蔽余下的部分。遮蔽的长度从均匀分布中采样。预训练数据包括1.2T Pile英文语料、1.0T中文Wudao语料和从网络上爬取的250G中文语料(包括在线论坛、百科和问答)。
多任务Instruction预训练(MIP,5%的token)。T5和ExT5建议在预训练中进行多任务学习有助于微调,因此我们提出在GLM-130B预训练中包含各种语言理解、生成和信息抽取的instruction prompted数据集。
相比于近期利用多任务prompted微调来改善zero-shot任务的迁移, MIP仅考虑5%的token且设置在预训练阶段来防止破坏LLM的其他一般性能力,例如:无条件自由生成。具体来说,我们包括了74个prompted数据集。
3. 平台感知的并行策略和模型配置
GLM-130B在96个DGX-A100 GPU(8x40G)的集群上训练了60天。目标是尽可能多的训练tokens,近期的研究表明大多数的LLM是训练不足的。
3D并行策略。数据并行和张量并行是训练10亿级参数模型的标准实践。为了进一步处理巨大的GPU显存需求,以及在节点之间进行张量并行导致的整体GPU利用率下降。我们合并了流水线模型并行,从而形成3D并行的策略。
流水线并行将模型划分为每个并行组的顺序阶段,并进一步最小化由流水线引入的“气泡”,我们利用由DeepSpeed实现的PipeDream-Flush来训练GLM-130B,并使用全局batch size为4224来检索时间和GPU显存的浪费。我们采用4路张量并行和8路管道并行,达到135 TFLOP/s perGPU(40G)。
GLM-130B配置。我们的目标是确保100B的LLM能够以FP16精度运行在单个DGX-A100上。基于我们从GPT-3中获得的hidden state维度12288,得到的模型尺寸必须不大于130B参数。为了最大化GPU利用率,我们基于平台和对应的并行策略来配置模型。为了避免由于两端额外的word embedding导致中间阶段的显存利用率不足,我们从中移除一层来平衡流水线划分,使得GLM-130B中有的transformer层。
在对集群的60天访问中,我们以固定每个样本长度为2048的情况下,在400B的tokens上训练了GLM-130B。对于[gMASK]训练目标,我们使用2048 tokens的上下文窗口。对于[MASK]和多任务目标,我们使用512的上下文窗口,并将4个样本拼接为2048长度。我们在前2.5%的样本上将batch size从192 warm-up至4224。我们使用AdamW作为优化器,和
设置为0.9和0.95,权重衰减值为0.1。在前0.5%的样本上,我们将学习率从
warm up至
,然后通过
consine调度进行衰减。我们使用的dropout率为0.1,裁剪梯度的值使用1.0。
三、GLM-130B的训练稳定性
训练稳定性是GLM-130B质量的绝对因素,这很大程度上受到其通过的token数量影响。因此,考虑到计算使用的限制,对于浮点数(FP)格式必须进行效率和稳定性的权衡:低精度浮点数格式能够改善计算效率,但是可能会导致上溢和下溢问题,从而导致训练崩溃。
**混合精度。**我们遵循混合精度的常见实践,即FP16用于前、后向传播,FP32用于优化器状态和主要的权重,从而减少GPU显存使用并改善训练效率。类似于OPT-175B和BLOOM-176B,由于这种选择导致训练GLM-130B面临频繁的loss峰值,并且随着训练的进行会变得越来越频繁。与精度相关的峰值通常没有明确的原因:一些会自己恢复;另一些则会伴随着突然飙升的梯度范数,最终loss出现峰值或者NaN。
OPT-175B通过人工跳过数据和调整超参数来解决这个问题;BLOOM-176B则是通过embedding norm技术。我们花费了数个月来研究峰值并意识到当transformer变大时会有一些问题:
首先,若使用Pre-LN,transformer主要分支的值尺寸在更深的层可能非常大。在GLM-130B中使用基于Post-LN的DeepNorm来解决,其会使得值的尺度总是有边界的。
其次,随着模型规模的增大,注意力分数变得非常大以至于超过了FP16的范围。在LLM中没有什么选项来克服这个问题。在BLOOM-176B中,使用BF16格式来替换FP16,由于其在NVIDIA Ampere GPUs上有更加广的范围。但是由于BF16在梯度累加中转换为FP32,导致在我们的实验中比FP16多消耗约15%的显存,更重要的是其不支持其次的GPU平台。另一个来自BLOOM-176B的选择是应用embedding norm,但是对模型的表现有损坏。
Embedding层梯度收缩。我们的经验研究表明,梯度范数(gradient norm)可以作为训练崩溃的信息指标。具体来说,我们发现训练崩溃通常滞后于梯度范数峰值几个训练steps。这种峰值通常是由embedding层的异常梯度导致的,因为我们观察到在GLM-130B早期训练阶段,其梯度范数比其他层高几个数量级。此外,在训练早期其波动很大。在视觉模型中处理这个问题是通过固定patch投影层。不幸的是,我们不能固定语言模型中的embedding层。
最终,我们发现在embedding层的梯度收缩(gradient shrink)有助于克服loss峰值,并且稳定GLM-130B的训练。这最早是在多模态transformer模型CogView中使用。具体来说,令是收缩因子,可以通过下面的方式来轻易实现
根据经验来看,将设置有助于避免大多数的峰值,速度的损失可以忽略不计。
事实上,最早GLM-130B训练仅在后期经历了3次loss发散,由于硬件故障而失败了无数次。
四、在RTX 2080 Ti上推理GLM-130B
GLM-130B的主要目标是在不减低效率和有效性的情况下,降低访问100B规模LLM的硬件需求。
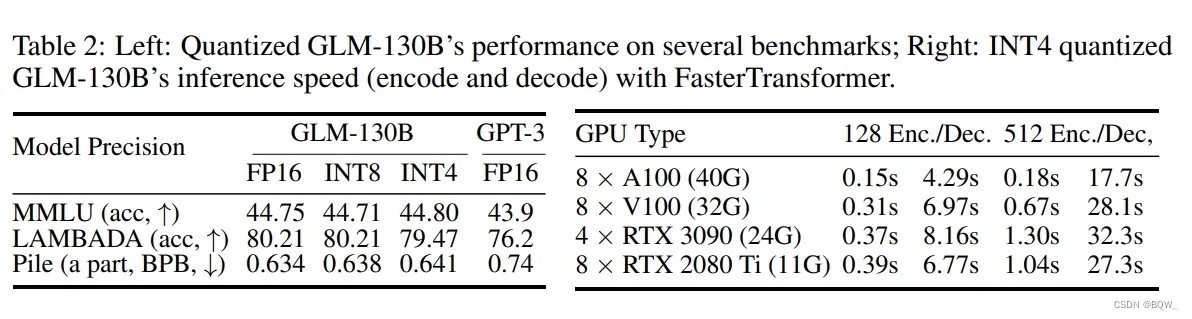
130B的模型尺寸可以使得在单个A100(40G*8)机器上运行完整的GLM-130B,而不是像OPT-175B和BLOOM-176B那样运行在高端A100(80G*8)机器上。为了加速GLM-130B的推理,我们也利用FasterTransformer来实现GLM-130B。相比于Huggingface中Pytorch实现的BLOOM-176B,GLM-130B在相同的单A100服务器上解码推理快7-8.4倍。
用于RTX 3090/2080的INT4量化。为了进一步支持流行的GPU,在保存性能优势的前提下尽可能的压缩GLM-130B,特别是通过量化。
通常的实践是将模型权重和激活都量化为INT8。然而,我们的分析表明LLM的激活可能包含极端异常值。同时,在OPT-175B和BLOOM-176B中也发现了涌现的异常值,其仅影响0.1%的特征维度,因此可以通过矩阵乘法分解来解决问题。
不同的是,GLM-130B的激活中存在约30%的异常值,使得上述的技术效率大大降低。因此,我们决定专注在良好模型权重,而保持模型激活为FP16精度。我们简单的使用训练后absmax量化,在运行时权重动态转换为FP16精度,引入了少量的计算开销,但是大幅度的降低了GPE显存的使用。
令人兴奋的是,GLM-130B达到了INT4全量量化,而现有成功案例仅实现了INT8级别。相比于INT8,INT4版本有助于额外节约所需显存的一半至70GB,这样就允许GLM-130B在4 x RTX 3090 Ti(24)或者8 x RTX 2080 Ti(11G)上进行推理。上表2左侧表明,没有使用任何的后训练,INT4版本的GLML-130B几乎没有性能的下降,在常见基准上维持对GPT-3的优势。
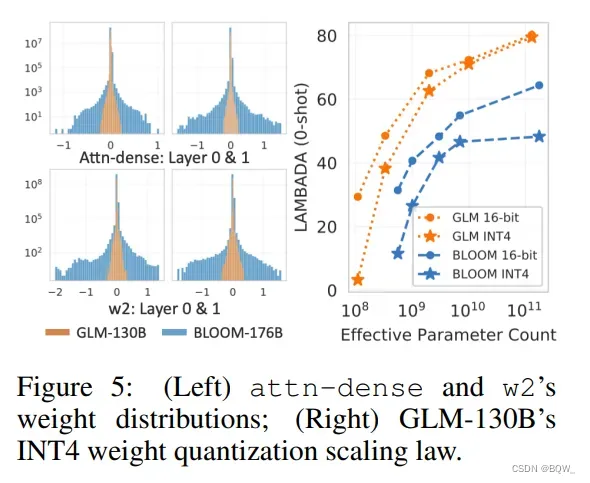
GLM INT4全量量化scaling law。上图5右侧展示了性能随模型尺寸增加的趋势,表明GLM INT4权重量化性能存在scaling law。我们评测了GLM中这种唯一的潜在机制。上图5左侧绘制了权重值分布,其表明了对量化质量的直接影响。具体来说,值分布根据广泛的的线性层需要更大的bins进行量化,否则会导致更多的精度损失。值广泛分布的attn-dense和w2矩阵解释了BLOOM的INT4量化失败原因。相反地,GLM相比于类似尺寸的GPT,有着更窄的值分布。随着GLM模型尺寸的增大,INT4和FP16版本的差距进一步减小。
五、结果
我们遵循GPT-3和PaLM等LLM的常用设置来评估GLM-130B。GLM-130B除了在英文上进行评估,作为双语模型也会在中文基准上进行评估。
GLM-130B中Zero-shot Learning范围讨论。因为GLM-130B已经使用MIP进行训练,这里明确了zero-shot评估的范围。事实上,“zero-shot”似乎有着争议性的解释,在社区没有达成共识。我们遵循一个重要的相关综述,其中“zero-shot learning设置在测试时,其目标是为测试图像分配一个未见过的类别标签”,其中涉及到未见过的类别标签是关键。因此,我们得出选择GLM-130B zero-shot数据集的准则是:
- 英语:1) 对于那些带有固定标签的任务(如自然语言推断),不应该对此类任务中的任务数据集进行评估;2) 对于没有固定标签的任务(问答、主题分类):只有与MIP有明确领域迁移的数据集被考虑;
- 中文:所有数据集多可以被评估,因为存在zero-shot跨语言迁移;
**过滤测试数据集。**遵循先前工作的实践和上面提及的准则,我们过滤并避免报告可能受到污染的数据集评估结果。对于LAMBADA和CLUE,我们发现在13-gram设定下是最小的覆盖。Pile、MMLU和BIG-bench要么被留出一部分,或者在爬取语料之后发布。
1. 语言建模

LAMBADA。LAMBADA是测试最后一个单词语言建模能力的数据集。GLM-130B使用双向注意力实现了80.2的zero-shot准确率,在LAMBADA上实现了新的记录。
Pile。Pile的测试集中包含了一系列的语义建模准则。与GPT-3和Jurassic-1相比,GLM-130B在18个加权BPB的共享测试集上实现了最好的表现,证明了其强大的语义能力。
2. 大规模多任务语言理解(MMLU)
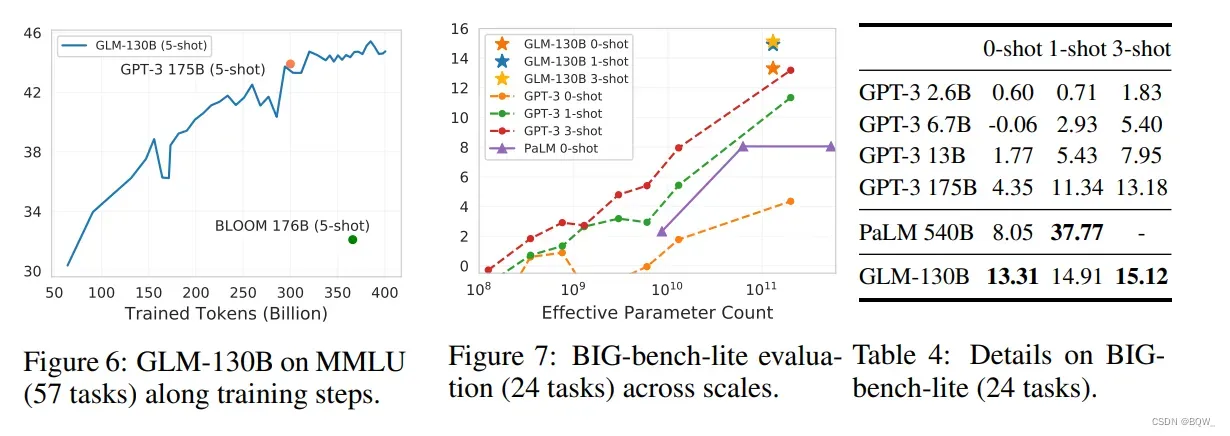
MMLU是一个包含了57个多项选择问答任务的多样性基准,主要是从高中水平至专家水平的人类知识。其是在Pile爬取之后发布的,是一个LLM few-shot learning的理想测试基准。GPT-3的结果来自于MMLU,BLOOM-176B则是使用与GLM-130B相同的prompts来测试。
如上图6所示,在见过大约300B的tokens后,GLM-130B在MMLU上的few-shot(5-shot)性能接近GPT-3(43.9)。随着训练的进行其会继续的上升,当训练结束是实现准确率44.8。这与观察结果一致,大多数现有的LLM远远没有得到充分的训练。
3. BIG-bench
BIG-bench对涉及模型推理、知识和常识能力的挑战性任务上进行基准测试。对于LLM来说,在150个任务上进行评估是耗时的,因此我们报告了BIE-bench-list,一个官方包含24个任务的子集合。观察上图7和表4,GLM-130B在zero-shot上优于GPT-3 175B,甚至是PaLM 540B。这可能要归功于GLM-130B的双向上下文注意力和MIP,其被证明能够在未见过的任务上改善zero-shot结果。随着shot的数量增加,GLM-130B的效果持续增加,并依旧领先于GPT-3。
限制与讨论。在上面的实验中,我们观察到GLM-130B随着few-shot样本增加而改善的性能没有GPT-3显著。这里从直觉上尝试理解这个现象。
首先,GLM-130B的双向本质能够带来很强的zero-shot效果,使其能够接近相同规模的few-shot上界。其次,这可以是因为现有的MI范式缺陷,其仅涉及在训练中的zero-shot预测并导致GLM-130B偏向于更强的zero-shot学习能力,但是相对较弱的in-context few-shot效果。为了纠正这个偏差,我们提出的潜在解决方案是,若我们有机会为GLM-130B继续预训练,那么MIP会使用不同in-context样本的各种shot,而不仅仅是zero-shot样本。
最后,尽管采用了与GPT-3相同的GPT架构,PaLM 540B在in-context learning中的few-shot相对增长要比GPT-3显著的多。我们推测,这种性能增长的进一步加速是PaLM高质量且多样化的私有训练语料导致的。
4. 中文语言理解评估(CLUE)

文章出处登录后可见!