
前言
在YOLOv5中网络结构采用yaml作为配置文件,之前我们也介绍过,YOLOv5配置了4种不同大小的网络模型,分别是YOLOv5s、YOLOv5m、YOLOv5l、YOLOv5x,这几个模型的结构基本一样,不同的是depth_multiple模型深度和width_multiple模型宽度这两个参数。 就和我们买衣服的尺码大小排序一样,YOLOv5s网络是YOLOv5系列中深度最小,特征图的宽度最小的网络。其他的三种都是在此基础上不断加深,不断加宽。所以,这篇文章我们就以yolov5s.yaml为例来介绍。
yaml这个文件在models文件夹下,我们了解这个文件还是很重要的,如果未来我们想改进算法的网络结构,需要通过yaml这种形式定义模型结构,也就是说需要先修改该文件中的相关参数,然后再修改common.py与yolo.py中的相关代码。(这两个文件下一篇会具体介绍噢~)
文章代码逐行手打注释,每个模块都有对应讲解,一文帮你梳理整个代码逻辑!
友情提示:可以先点 再慢慢看哦~
再慢慢看哦~
源码下载地址:mirrors / ultralytics / yolov5 · GitCode

 🍀本人YOLOv5源码详解系列:
🍀本人YOLOv5源码详解系列:
YOLOv5源码逐行超详细注释与解读(1)——项目目录结构解析
YOLOv5源码逐行超详细注释与解读(2)——推理部分detect.py
YOLOv5源码逐行超详细注释与解读(3)——训练部分train.py
YOLOv5源码逐行超详细注释与解读(4)——验证部分val(test).py
YOLOv5源码逐行超详细注释与解读(6)——网络结构(1)yolo.py
YOLOv5源码逐行超详细注释与解读(7)——网络结构(2)common.py
目录
前言
目录
🚀一、什么是YAML
🚀二、参数配置
🚀三、先验框配置
🚀四、backbone部分
🚀五、Head部分
🚀六、整体模型 编辑
🚀七、YOLOv5s、YOLOv5m、YOLOv5l、YOLOv5x对比

🚀一、什么是YAML
YAML,即“ YAML Ain’t a Markup Language(YAML 不是一种标记语言)”的递归缩写。YAML真实意思是 “Yet Another Markup Language(仍是一种标记语言)”。是专门用来写配置文件的语言,能很好的与当下的编程语言的一些任务相互协作,非常简洁和强大。
官网上的解释是:
“YAML is a human-friendly data serialization language for all programming languages.”
翻译:YAML 是一种适用于所有编程语言的人性化数据序列化语言。
提到数据序列化语言,我们之前可能比较熟悉的是JSON 和 XML ,YAML与它们类似,但它主要强调这种语言是以数据为中心,而不是以标记为中心,像 XML 语言就使用了大量的标记。并且远比这俩方便和更具可读性。
YAML的使用:
YAML的使用包括了两部分:一个是YAML数据的定义,一个是它在其他程序里如何被使用。
YAML 的基础语法:
- 大小写敏感
- 使用缩进表示层级关系
- 不允许使用tab,只允许空格
- 缩进的空格数量不重要,只要层级相同的元素左对齐即可
- ‘#’ 表示注释
🚀二、参数配置
# 1、参数配置
# Parameters
nc: 80 # 所判断目标类别的种类,此处80类
depth_multiple: 0.33 # 模型层数因子 控制模型的深度(BottleneckCSP个数)
width_multiple: 0.50 # 模型通道数因子 控制Conv通道channel个数(卷积核数量)这段代码有三个参数:
- nc: 数据集类别个数
- depth_multiple: 用于控制层的重复的次数(深度)。通过深度参数 depth gain 在搭建每一层的时候,子模块数量=int(number*depth),这样就可以起到一个动态调整模型深度的作用。
- width_multiple: 用于控制输出特征图的通道数(宽度)。在模型中间层的每一层的卷积核的数量=int(number*width),这样也可以起到一个动态调整模型宽度的作用。
这三个参数,我们会在下一篇模型搭建 yolo.py 文件介绍中见到,先混个眼熟吧:

🚀三、先验框配置
# 2、先验框配置
# anchors
anchors: # 9个anchor,其中P表示特征图的层级,P3/8该层特征图缩放为1/8,是第3层特征
- [10,13, 16,30, 33,23] # P3/8 FPN接主干网络下采样8倍后的anchor大小,检测小目标,10,13是一组尺寸,总共三组检测小目标
- [30,61, 62,45, 59,119] # P4/16 FPN接主干网络下采样4倍后的anchor大小,检测中目标,共三组
- [116,90, 156,198, 373,326] # P5/32 FPN接主干网络下采样2倍后的anchor大小,检测大目标,共三组
YOLOv5使用k-means聚类法来初始化了9个anchors,任意地选择了9个聚类和3个尺度,然后在各个尺度上均匀地划分聚类。在COCO数据集上,这9个聚类是(10 × 13),(16 × 30),(33 × 23),(30 × 61),(62 × 45),(59 × 119),(116 × 90),(156 × 198),(373 × 326)。
这9个anchor分别在三个Detect层的feature map中使用,每个feature map的每个grid_cell 都有三个anchor进行预测。
- 尺度越大的freature map分辨率越大,相对于原图的下采样越小,其感受野也就越小,那么设置的anchors自然越小,如[10,13, 16,30, 33,23],因此对原始图像中的小物体预测较好;
- 尺度越小的freature map分辨率越小,相对于原图的下采样越大,其感受野越大,设置的anchors自然也就越大,如[116, 90, 156,198, 373,326],因此对原始图像中的大物体预测较好。
如下图所示:

🚀四、backbone部分
# 3、backbone部分
# YOLOv5 v6.0 backbone
backbone:
# [from, number, module, args]
[[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2 [3, 32, 6, 2, 2]
[-1, 1, Conv, [128, 3, 2]], # 1-P2/4 [32, 64, 3, 2]
[-1, 3, C3, [128]], # 2 [64, 64, 1]
[-1, 1, Conv, [256, 3, 2]], # 3-P3/8 [64, 128, 3, 2]
[-1, 6, C3, [256]], # 4 [128, 128, 2]
[-1, 1, Conv, [512, 3, 2]], # 5-P4/16 [128, 256, 3, 2]
[-1, 9, C3, [512]], # 6 [256, 256, 3]
[-1, 1, Conv, [1024, 3, 2]], # 7-P5/32 [256, 512, 3, 2]
[-1, 3, C3, [1024]], # 8 [512, 512, 1]
[-1, 1, SPPF, [1024, 5]], # 9 [512, 512, 5]
]这段代码是YOLOv5s的backbone部分, 首先介绍四个参数:
[from, number, module, args]
- from : 表示当前模块的输入来自那一层的输出,-1表示将上一层的输出当做自己的输入(第0层的-1表示输入的图像)。
- number: 表示当前模块的重复次数,实际的重复次数还要由上面的参数depth_multiple共同决定,决定网络模型的深度。
- module: 表示该层模块的名称,这些模块写在common.py中,进行模块化的搭建网络。
- args: 表示类的初始化参数,用于解析作为 moudle 的传入参数,会在网络搭建过程中根据不同层进行改变,我们后面具体分析。
另外,注释中的#0-P1/2表示该层为第0层,输出后会变成原图的1/2
我们来解释一下每个层参数含义以及图片变化:
原始输入图片: 640*640*3
第0层:Conv层 [-1, 1, Conv, [64, 6, 2, 2]]
- -1: 输入是图片
- 1:网络模块数量为1
- Conv: 该层的网络层名字是Conv
- [64, 6, 2, 2]: Conv层的四个参数
- 64:channel=64
- 6:kernel_size=6
- 2:padding=2
- 2:stride=2
- 输出图片:320*320*64
第1层:Conv层 [-1, 1, Conv, [128, 3, 2]]
- -1: 输入是上一层的输出
- 1:网络模块数量为1
- Conv: 该层的网络层名字是Conv
- [128, 3, 2]: Conv层的三个参数
- 128:channel=128
- 3:kernel_size=3
- 2:stride=2
- 输出图片:160*160*128
第2层:C3层 [-1, 3, C3, [128]]
- -1: 输入是上一层的输出
- 3:网络模块数量为3
- C3: 该层的网络层名字是C3
- [128]: C3层的参数
- 128:channel=128
- 输出图片:160*160*128
第3层:Conv层 [-1, 1, Conv, [256, 3, 2]]
- -1: 输入是上一层的输出
- 1:网络模块数量为1
- Conv: 该层的网络层名字是Conv
- [256, 3, 2]: Conv层的三个参数
- 256:channel=256
- 3:kernel_size=3
- 2:stride=2
- 图片变化:80*80*256
第4层:C3层 [-1, 6, C3, [256]]
- -1: 输入是上一层的输出
- 6:网络模块数量为6
- C3: 该层的网络层名字是C3
- [256]: C3层的参数
- 256:channel=256
- 图片变化:80*80*256
第5层:Conv层 [-1, 1, Conv, [512, 3, 2]]
- -1: 输入是上一层的输出
- 1:网络模块数量为1
- Conv: 该层的网络层名字是Conv
- [512, 3, 2]: Conv层的三个参数
- 512:channel=512
- 3:kernel_size=3
- 2:stride=2
- 输出图片:40*40*512
第6层:C3层 [-1, 9, C3, [512]]
- -1: 输入是上一层的输出
- 9:网络模块数量为9
- C3: 该层的网络层名字是C3
- [512]: C3层的参数
- 512:channel=512
- 输出图片:40*40*512
第7层:Conv层 [-1, 1, Conv, [1024, 3, 2]]
- -1: 输入是上一层的输出
- 1:网络模块数量为1
- Conv: 该层的网络层名字是Conv
- [1024, 3, 2]: Conv层的三个参数
- 1024:channel=1024
- 3:kernel_size=3
- 2:stride=2
- 输出图片:20*20*1024
第8层:C3层 [-1, 3, C3, [1024]]
- -1: 输入是上一层的输出
- 3:网络模块数量为3
- C3: 该层的网络层名字是C3
- [1024]: C3层的参数
- 1024:channel=1024
- 输出图片:20*20*1024
第9层:SPPF层 [-1, 1, SPPF, [1024, 5]]
- 主要是对不同尺度特征图的融合
- -1: 输入是上一层的输出
- 1:网络模块数量为1
- SPPF: 该层的网络层名字是SPPF
- [1024, 5]: SPPF层的两个参数
- 1024:channel=1024
- 5:kernel_size=5
- 输出图片:20*20*1024
到第9层为止,backbone部分就结束了,这个部分会形成三个接口:
- 第4层的输出:80*80*256
- 第6层的输出:40*40*512
- 第9层的输出:20*20*1024
结构示意图如下:
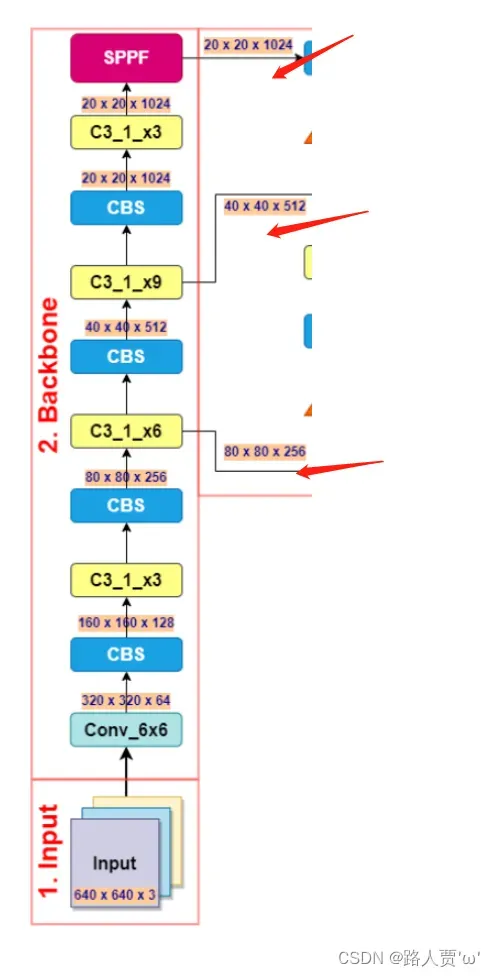
(图片来源:【YOLO系列】YOLOv5、YOLOX、YOOv6、YOLOv7网络模型结构_DearAlbert的博客)
🚀五、Head部分
# 4、head部分
# YOLOv5 v6.0 head
head:
# 前两个阶段是向上concat
[[-1, 1, Conv, [512, 1, 1]], # 10 [512, 256, 1, 1]
# nn.upsample不改变channel但是会把图片宽和高都变为2倍
[-1, 1, nn.Upsample, [None, 2, 'nearest']], # 11 [None, 2, 'nearest']
# 与上面backbone中的 P4阶段的最后一个输出做一个concat
# 进行concat的两层必须大小相同、通道数相同 concat之后通道翻倍
[[-1, 6], 1, Concat, [1]], # 12 cat backbone P4 [1]
[-1, 3, C3, [512, False]], # 13 [512, 256, 1, False]
[-1, 1, Conv, [256, 1, 1]], # 14 [256, 128, 1, 1]
[-1, 1, nn.Upsample, [None, 2, 'nearest']], #15 [None, 2, 'nearest']
[[-1, 4], 1, Concat, [1]], # 16 cat backbone P3 [1]
[-1, 3, C3, [256, False]], # 17 (P3/8-small) [256, 128, 1, False]
# 后两个阶段是向下concat
[-1, 1, Conv, [256, 3, 2]], # 18 [128, 128, 3, 2]
[[-1, 14], 1, Concat, [1]], # 19 cat head P4 [1]
[-1, 3, C3, [512, False]], # 20 (P4/16-medium) [256, 256, 1, False]
[-1, 1, Conv, [512, 3, 2]], # 21 [256, 256, 3, 2]
[[-1, 10], 1, Concat, [1]], # 22 cat head P5 [1]
[-1, 3, C3, [1024, False]], # 23 (P5/32-large) [512, 512, 1, False]
# 有三个检测层,分别是在17层下面、20层下面、23层下面
[[17, 20, 23], 1, Detect, [nc, anchors]], # 24 [80,[[10,13,16,30,33,23],[30,61.[128.256.512]1
]YOLOv5中的Head包括Neck和Detect两部分。
Neck采用了FPN+PAN结构,Detect结构和YOLOv3中的Head一样。其中BottleNeckCSP带有False,说明没有使用残差结构,而是采用的backbone中的Conv。
四个参数和上面backbone一样就不再解释了,我们来继续解释一下每个层参数含义以及图片变化:
上一个阶段输出大小:20*20*1024
首先前两个阶段是向上concat
第10层:Conv层 [-1, 1, Conv, [512, 1, 1]]
- -1: 输入是上一层的输出
- 1:网络模块数量为1
- Conv: 该层的网络层名字是Conv
- [512, 1, 1]: Conv层的三个参数
- 512:channel=512
- 1:kernel_size=1
- 1:stride=1
- 输出图片:20*20*512
第11层:Upsample层 [-1, 1, nn.Upsample, [None, 2, ‘nearest’]]
- -1: 输入是上一层的输出
- 1:网络模块数量为1
- nn.Upsample: 该层的网络层名字是Upsample
- [None, 2, ‘nearest’]: Upsample层的三个参数
- None:size=None(指定输出的尺寸大小)
- 2:scale_factor=2(指定输出的尺寸是输入尺寸的倍数)
- ‘nearest’:mode=‘nearest’(默认: ‘nearest’)
- 输出图片:通过该层之后特征图不改变通道数,特征图的长和宽会增加一倍——40*40*512
第12层:Concat层 [[-1, 6], 1, Concat, [1]]
- [-1, 6]: 输入是上一层和第6层的输出
- 1:网络模块数量为1
- Concat: 该层的网络层名字是Concat
- [1]: Concat层的参数
- [1]:拼接的维度=1
- 输出图片:通过该层之后特征图与第6层(p4阶段)的输出进行特征图的融合——40*40*1024(即输出40×40×512contact40×40×512=40×40×1024)
第13层:C3层 [-1, 3, C3, [512, False]]
- -1: 输入是上一层的输出
- 3:网络模块数量为1
- C3: 该层的网络层名字是C3
- [512, False]: C3层的两个参数
- 512:channel=512
- False:没有残差模块
- 输出图片:40*40*512
第14层:Conv层 [-1, 1, Conv, [256, 1, 1]]
- -1: 输入是上一层的输出
- 1:网络模块数量为1
- Conv: 该层的网络层名字是Conv
- [256, 1, 1]: Conv层的三个参数
- 256:channel=256
- 1:kernel_size=1
- 1:stride=1
- 输出图片:40*40*256
第15层:Upsample层 [-1, 1, nn.Upsample, [None, 2, ‘nearest’]]
- -1: 输入是上一层的输出
- 1:网络模块数量为1
- nn.Upsample: 该层的网络层名字是Upsample
- [None, 2, ‘nearest’]: Upsample层的三个参数
- None:size=None(指定输出的尺寸大小)
- 2:scale_factor=2(指定输出的尺寸是输入尺寸的倍数)
- ‘nearest’:mode=‘nearest’(默认: ‘nearest’)
- 输出图片:通过该层之后特征图不改变通道数,特征图的长和宽会增加一倍——80*80*256
第16层:Concat层 [[-1, 4], 1, Concat, [1]]
- [-1, 4]: 输入是上一层和第4层的输出
- 1:网络模块数量为1
- Concat: 该层的网络层名字是Concat
- [1]: Concat层的参数
- [1]:拼接的维度=1
- 输出图片:通过该层之后特征图与第4层(p3阶段)的输出进行特征图的融合——80*80*512(即输出80×80×256contact80×80×256=80×80×512)
第17层:C3层 [-1, 3, C3, [256, False]]
- -1: 输入是上一层的输出
- 3:网络模块数量为1
- C3: 该层的网络层名字是Conv
- [256, False]: C3层的两个参数
- 256:channel=256
- False:没有残差模块
- 输出图片:80*80*256
后两个阶段是向下concat
第18层:Conv层 [-1, 1, Conv, [256, 3, 2]]
- -1: 输入是上一层的输出
- 1:网络模块数量为1
- Conv: 该层的网络层名字是Conv
- [256, 1, 1]: Conv层的三个参数
- 256:channel=256
- 3:kernel_size=3
- 2:stride=2
- 输出图片:40*40*256
第19层:Concat层 [[-1, 14], 1, Concat, [1]]
- [-1, 14]: 输入是上一层和第14层的输出
- 1:网络模块数量为1
- Concat: 该层的网络层名字是Concat
- [1]: Concat层的参数
- [1]:拼接的维度=1
- 输出图片:通过该层之后特征图与第14层的输出进行特征图的融合——40*40*512(即输出40×40×256contact40×40×256=40×40×512)
第20层:C3层 [-1, 3, C3, [512, False]]
- -1: 输入是上一层的输出
- 3:网络模块数量为3
- C3: 该层的网络层名字是C3
- [512, False]: C3层的两个参数
- 512:channel=512
- False:没有残差模块
- 输出图片:40*40*512
第21层:Conv层 [-1, 1, Conv, [512, 3, 2]]
- -1: 输入是图片
- 1:网络模块数量为1
- Conv: 该层的网络层名字是Conv
- [512, 3, 2]: Conv层的三个参数
- 512:channel=512
- 3:kernel_size=3
- 2:stride=2
- 输出图片:20*20*512
第22层:Concat层 [[-1, 10], 1, Concat, [1]]
- [-1, 10]: 输入是上一层和第10层的输出
- 1:网络模块数量为1
- Concat: 该层的网络层名字是Concat
- [1]: Concat层的参数
- [1]:拼接的维度=1
- 输出图片:通过该层之后特征图与第10层的输出进行特征图的融合——20*20*1024(即输出20×20×512contact20×20×512=20×20×1024)
第23层:C3层 [-1, 3, C3, [1024, False]]
- -1: 输入是上一层的输出
- 3:网络模块数量为3
- C3: 该层的网络层名字是C3
- [1024, False]: C3层的两个参数
- 1024:channel=1024
- False:没有残差模块
- 输出图片:20*20*1024
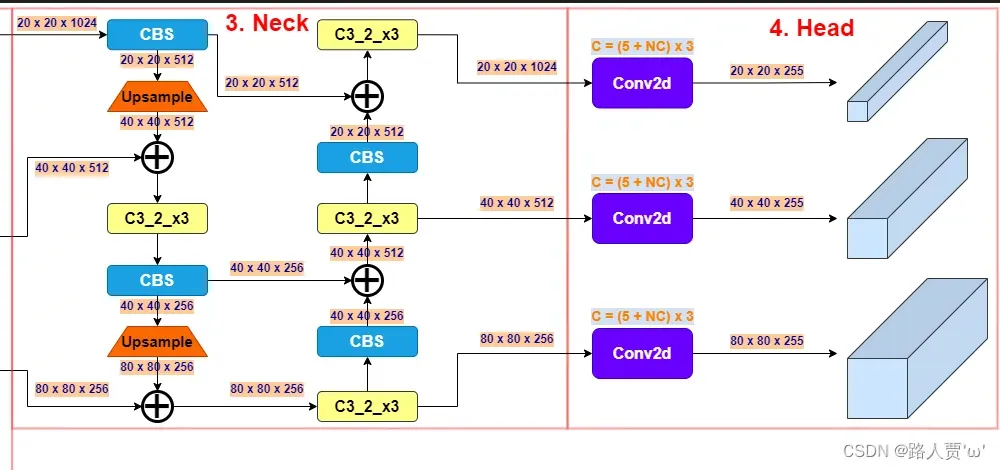
第24层:Detect层 [[17, 20, 23], 1, Detect, [nc, anchors]]
- [17, 20, 23]: 表示把第17、20和23三层作为Detect模块的输入
- 1:网络模块数量为1
- Detect: 该层的网络层名字是Detect
- [nc, anchors]: 初始化Detect模块的参数
- nc:类别个数
- anchors:超参数 anchors的值
- 输出图片:20*20*1024
结构示意图如下:
🚀六、整体模型 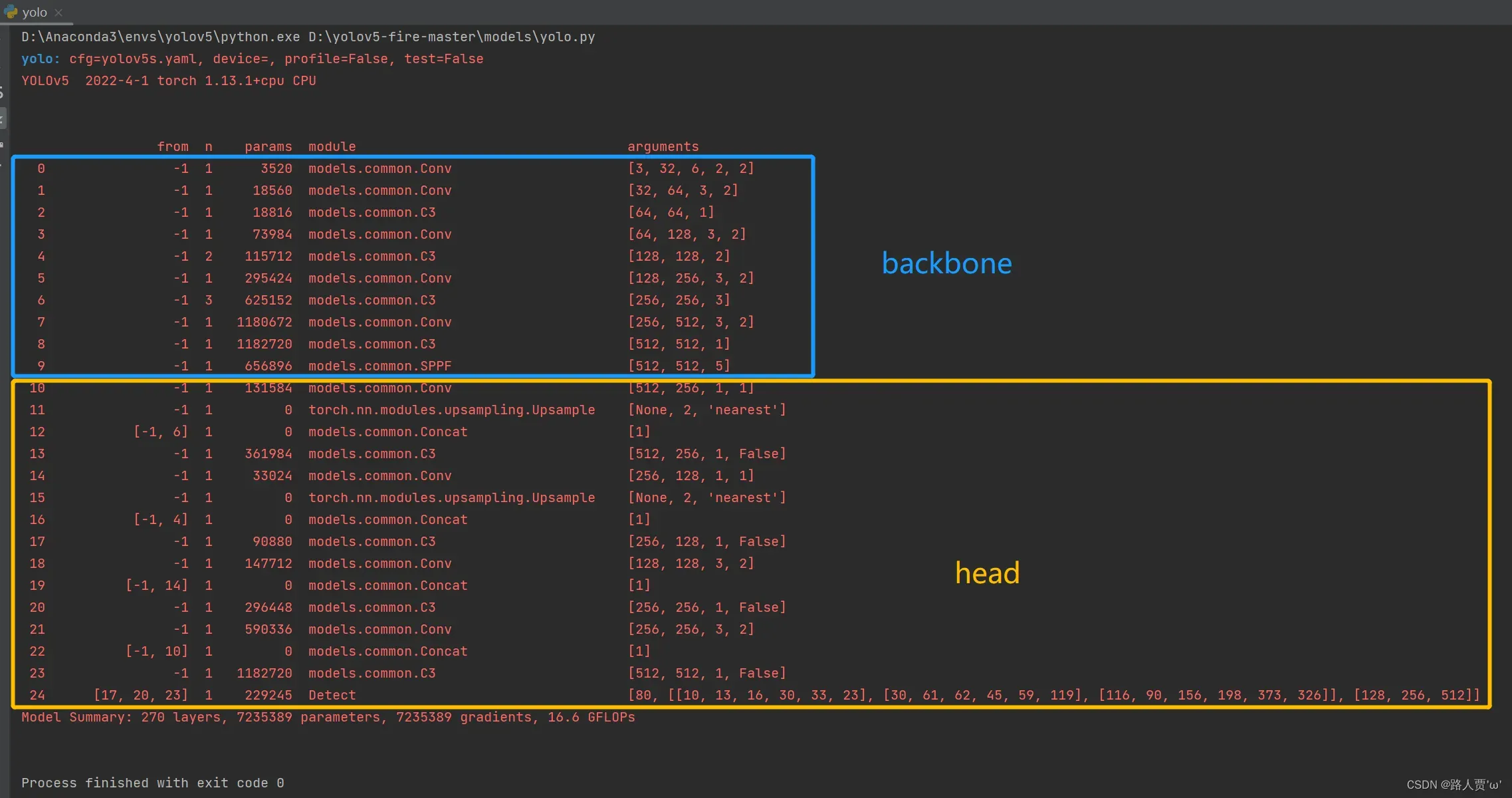
🚀七、YOLOv5s、YOLOv5m、YOLOv5l、YOLOv5x对比
精确度对比
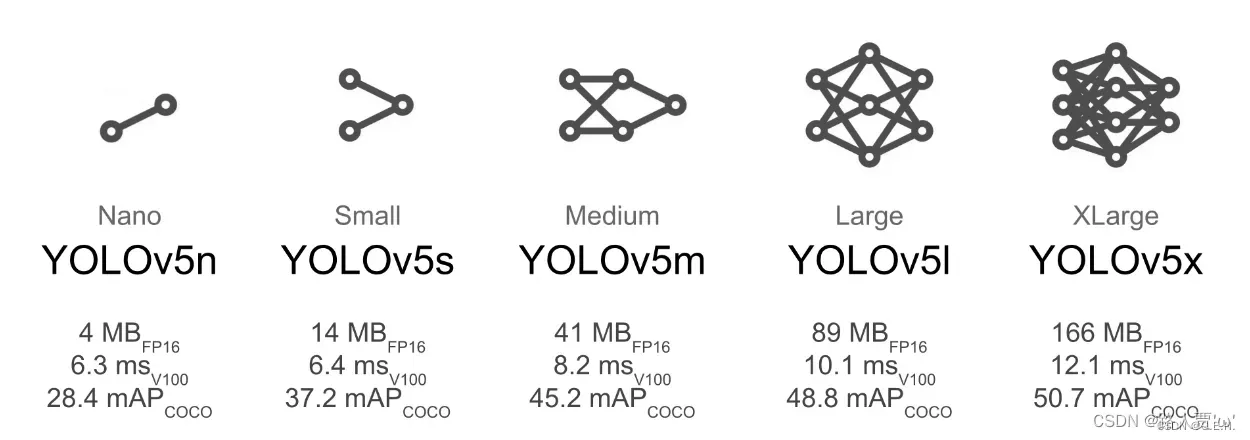 配置对比
配置对比
|
| YOLOv5s | YOLOv5m | YOLOv5l | YOLOv5x |
| depth_multiple | 0.33 | 0.67 | 1.0 | 1.33 |
| width_multiple | 0.50 | 0.75 | 1.0 | 1.25 |
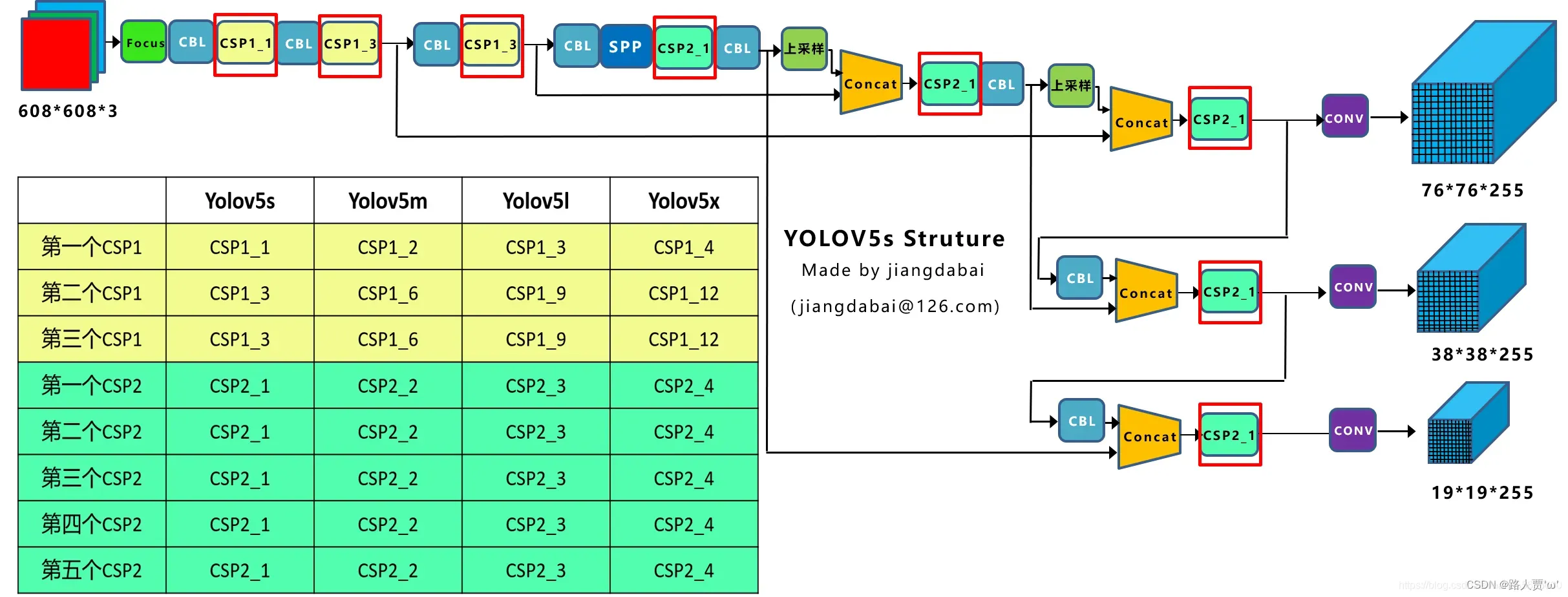
| BottleneckCSP数 BCSPn(True) | 1,3,3 | 2,6,6 | 3,9,9 | 4,12,12 |
| BottleneckCSP数BCSPn(False) | 1 | 2 | 3 | 4 |
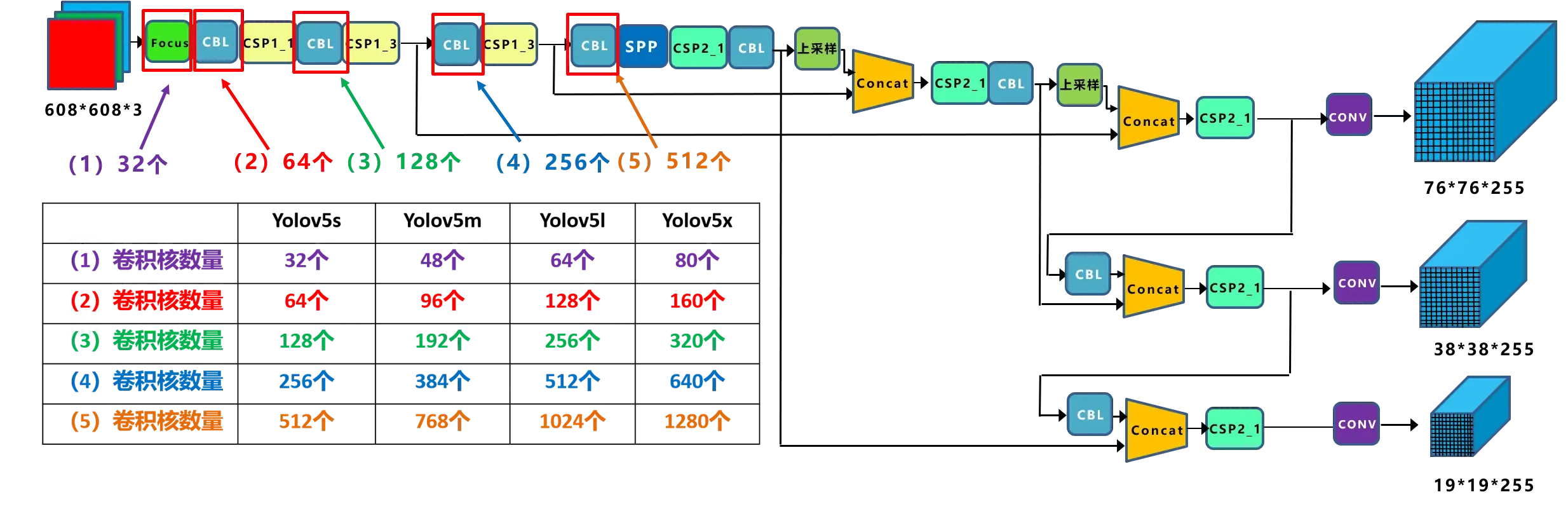
| Conv卷积核数量 | 32,64,128, 256,512 | 48,96,192, 384,768 | 64,128,256, 512,1024 | 80,160,320, 640,1280 |
深度对比
宽度对比
本文到这里就结束了,有很多参数具体如何使用可以参见下一篇yolo.py的介绍(点这里直达!
另外,想更加深入学习yaml文件的话,推荐看这篇→CSDN独家首发!万字长文,YOLOv5/v7/v8算法模型yaml文件史上最详细解析与教程!小白也能看懂!掌握了这个就掌握了魔改YOLO的核心!_迪菲赫尔曼的博客-CSDN博客

文章出处登录后可见!