文档地址:https://platform.openai.com/docs/
接口说明:https://platform.openai.com/docs/api-reference
一、概览
OpenAI API 可直接调用模型接口,也可在线微调(不过只能微调GPT-3系列模型)。
本小节主要介绍 tokenizer 和 model。
- Tokens:对于英语,1个token平均是4个字符,0.75个单词;中文大概是2个token一个汉字。API限制了 prompt+生成内容 的 token 总数不能超过模型的最大上下文长度(大多数上限都是 2048 个token,大约 1500 个单词)。这个地址 可以测试 token 数量。这里用的和 GPT2 类似的 tokenizer。也可以用 openai 开源的 tokenize 工具
tiktoken(真是起名鬼才)。
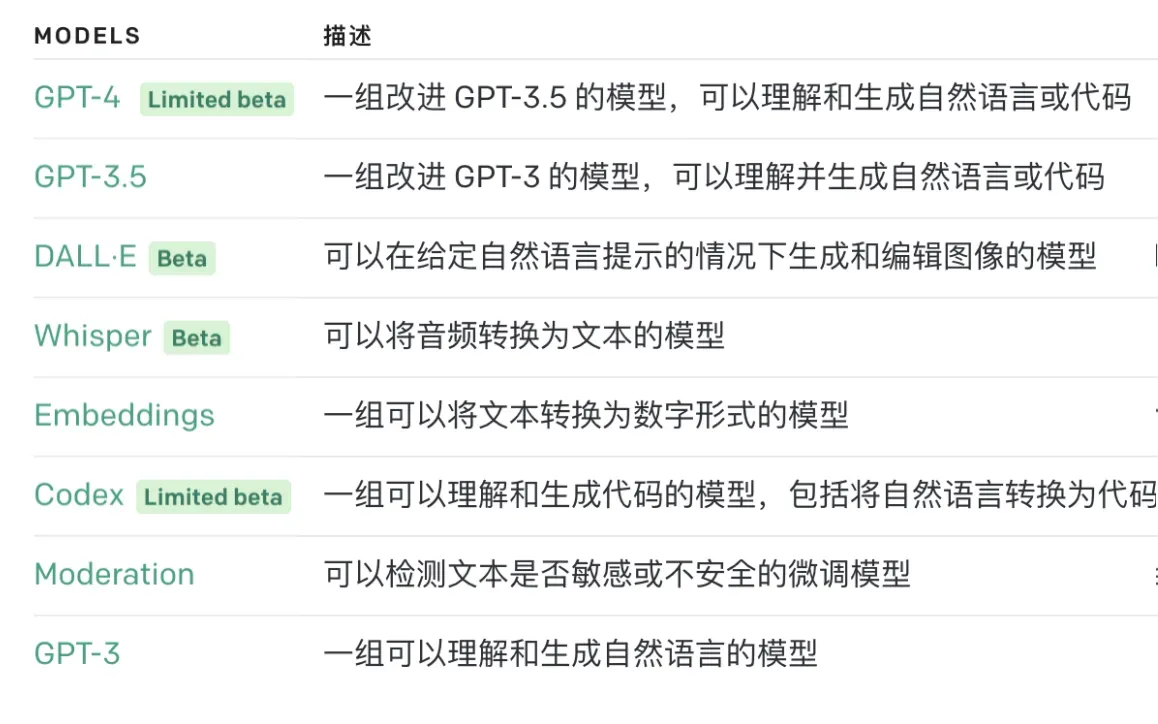
- Models:详细模型列表点击这里。可用 gpttools 对比各个model的输出及相应时间。
几个常用的:gpt-4:更擅长推理,8192 tokensgpt-4-32k: 更大窗口,32768 tokensgpt-3.5-turbo:GPT-3.5的对话版,4096 tokens,对话时可以先通过传入类似{"role": "system", "content":"你是一个程序员"}引导模型身份, 然后再通过user和assistant交替的形式实现多轮对话text-davinci-003:指令微调+RLHF,4097 tokenstext-davinci-002:只有指令微调,4097 tokenscode-davinci-002:代码生成,8001 tokenstext-embedding-ada-002:详见官网,用于文本向量化,窗口 8192 tokens,维度 1536
text-moderation-latest:文本审核模型,包括 hate, hate/threatening, self-harm, sexual, sexual/minors, violence, and violence/graphic 这几个类- 其他模型性能一般的就不过多介绍了。
二、使用
可以直接python安装openai库,也可以发送post请求
2.1 方式一:openai python 库
安装:
$ pip install openai
运行:
import os
import openai
# Load your API key from an environment variable or secret management service
openai.api_key = os.getenv("OPENAI_API_KEY")
response = openai.Completion.create(
model="text-davinci-003",
prompt="Say this is a test",
temperature=0, # 控制多样性,越接近1 多样性越大
max_tokens=7
)
2.2 方式二:post请求
post请求接口调用,可参考下面这个表:

以 gpt-3.5-turbo 的调用方式为例:
curl https://api.openai.com/v1/chat/completions \
-H "Content-Type: application/json" \
-H "Authorization: Bearer $OPENAI_API_KEY" \
-d '{
"model": "gpt-3.5-turbo",
"messages": [{"role": "user", "content": "Hello!"}]
}'
必填参数是 model 和 message,可选参数如下:
-
temperature:float 类型,默认值为 1。控制采样,可选0-2之间的值,小于0.2生成的东西就很确定,大于0.8就很多样。建议和下面top_p二选一,不要一起用。 -
top_p:float 类型,默认值为 1。控制采样前 top_p 概率的token,可选0-1之间的值。 -
n:int 类型,默认值为 1。一次性生成多少个可选结果。 -
max_tokens:int 类型,默认值为inf。生成的最大token数量。 -
stop:str 或 list 类型,默认值为null。用于早停,生成内容包含stop时停止生成。 -
stream:bool 类型,默认值为false。如果开启,就会流式返回,就跟chatGPT似的一个字儿一个字儿往外出。 -
presence_penalty:float 类型,默认值为 0。可选 -2.0 到 2.0。若为正数,越大越禁止模型生成输入中包含的重复内容,用于主题发散。 -
logit_bias:json 类型,默认值为null。用来控制某些 token 的生成概率。数值是 -100 到 100,-100 相当于尽量别生成这个词,100 相当于一定要生成这个词。 -
frequency_penalty:float 类型,默认值为 0。可选 -2.0 到 2.0。若为正数,越大越禁止模型生成整体高频词,用于避免重复生成。 -
user:str 类型,可自己定义并标识用户id以防滥用。
此外,关于 bearer token 用于认证,可参考这篇文章。
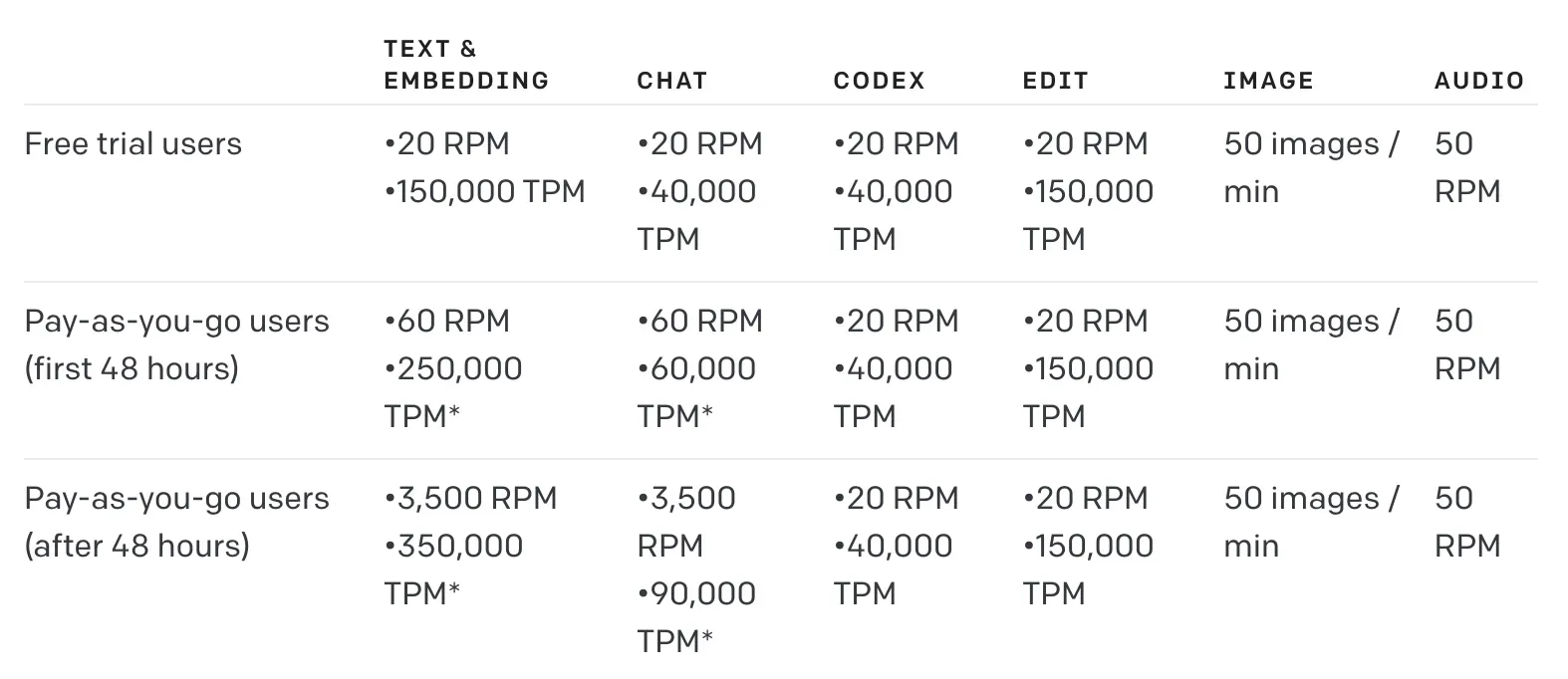
三、限制
两者限制方式:RPM(每分钟request数)和 TPM(每分钟token数)
四、定价
详见:https://openai.com/pricing
常用的几个:
-
gpt-4和gpt-4-32k:8k版本平均 $0.045 / 1000 tokens,差不多 3 毛钱 500 汉字
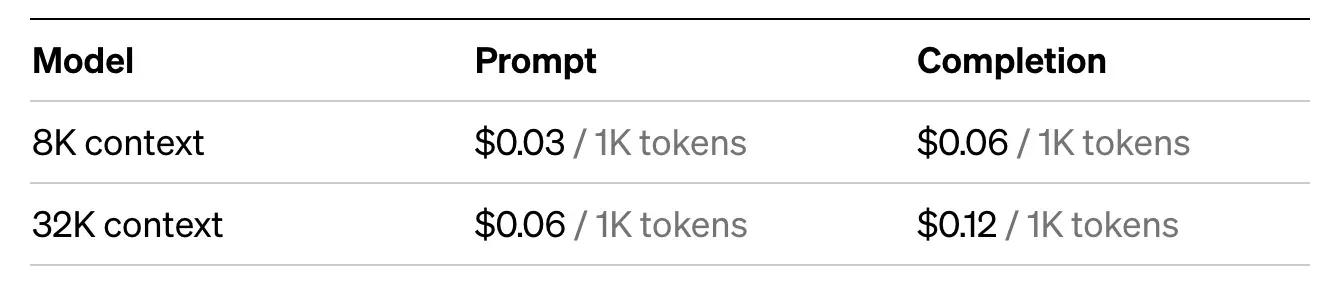
-
gpt-3.5-turbo:ChatGPT,大约 0.0138 元 1000 tokens,差不多 1.38 元 5w 汉字

-
text-davinci-003:$0.02 / 1K tokens(比 gpt-3.5-turbo 贵 10 倍) -
text-embedding-ada-002:$0.0004 / 1K tokens(差不多 2.8 元 100w token,50w汉字)
文章出处登录后可见!