前言
这篇博客主要是简单介绍一下如何改进yolov5,但是不会讲得太深,因为我也只是运用了几个月,并没有细读每一段代码,我只是为了改而改,不会深究他的代码逻辑,python代码他确实写的很优雅,但是我不打算学习这种优雅,能毕业就行,以后又不从事python工作,也不继续读博,所以用为主。
上述话是昨夜写了一半开的头,今早起来发现好像有人做过了,但是不想放弃这篇,所以打算继续写完,以自己的方式叙述,之前也没有看过任何讲解yolov5的,只在20年细读过bubbliiing的yolov3代码,然后改进yolov4代码,从那以后就踏上了自已改代码写代码的道路,尝试过各种,像mmdetection也用过,去年跑对比试验用过,现在早已经忘了,还有原版的yolox,那种编译的方式跑代码恶心死我了,现在我都没尝试过也不知道怎么debug,全靠print打印中间变量,到后来的分类网络,细粒度分类网络以及各种yolo,后面因为找工作所以一直没更新知识库,只看了些知识蒸馏的。最近也是因为用yolov5比较多,所以在此记录一下。
1、首先要学会看配置文件
# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
# Parameters
nc: 20 # number of classes
depth_multiple: 1.0 # model depth multiple
width_multiple: 1.0 # layer channel multiple
anchors:
- [10,13, 16,30, 33,23] # P3/8
- [30,61, 62,45, 59,119] # P4/16
- [116,90, 156,198, 373,326] # P5/32
# YOLOv5 v6.0 backbone
backbone:
# [from, number, module, args]
[[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2 0
[-1, 1, Conv, [128, 3, 2]], # 1-P2/4 1
[-1, 3, C3, [128]], # 2
[-1, 1, Conv, [256, 3, 2]], # 3-P3/8 3
[-1, 6, C3, [256]], # 4
[-1, 1, Conv, [512, 3, 2]], # 5-P4/16 5
[-1, 9, C3, [512]], # 6
[-1, 1, Conv, [1024, 3, 2]], # 7-P5/32 7
[-1, 3, C3, [1024]], # 8
[-1, 1, SPPF, [1024, 5]], # 9
]
# YOLOv5 v6.0 head
head:
[[-1, 1, Conv, [512, 1, 1]], # 10
[-1, 1, nn.Upsample, [None, 2, 'nearest']], 11
[[-1, 6], 1, Concat, [1]], # cat backbone P4 12
[-1, 3, C3, [512, False]], # 13
[-1, 1, Conv, [256, 1, 1]], # 14
[-1, 1, nn.Upsample, [None, 2, 'nearest']], # 15
[[-1, 4], 1, Concat, [1]], # cat backbone P3 16
[-1, 3, C3, [256, False]], # 17 (P3/8-small) 17
[-1, 1, Conv, [256, 3, 2]], # 18
[[-1, 14], 1, Concat, [1]], # cat head P4 19
[-1, 3, C3, [512, False]], # 20 (P4/16-medium) 20
[-1, 1, Conv, [512, 3, 2]], 21
[[-1, 10], 1, Concat, [1]], # cat head P5 22
[-1, 3, C3, [1024, False]], # 23 (P5/32-large) 23
[[17, 20, 23], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)] 24
如上是yolov5l的模型定义文件,前面的depth_multiple和width_multiple定义的是模型深度和宽度,这个值确定的是模型为n版、s版、m版还是l版,这里不用管。
后面的backbone和head定义了模型的整个结构,一共24层,其中,backbone10层,head14层,head综合定义了颈部网络和头部网络。
其中,每一层都有如下四个参数组成,f,n,m,args。
f为from,表示这一层的输入从哪一层来,因为整个模型采用的是nn.Sequential定义,因此需要知道每一层的索引,才能从模型中取出指定层数的输出,不然就会默认取出上一层,由于颈部网络有torch.cat融合两层,所以需要这个索引功能;
n为number,表示这一层连续用几次。
m为module,表示这一层的名字,一般就是模块的名字
args就是模块定义的参数列表,一般在这里定义一些模块需要的参数。注意,这里不会定义模块需要的输入通道数,因为他会自己计算上一层传来的特征为多少通道数。
举个例子,[-1, 1, Conv, [256, 1, 1]]表示:这一层的输入从上一层来,-1就表示为上一层,模型从前到后定义的,会一一赋值一个索引,就是前面所说的24层这个索引,从零开始;1表示这个模块运用1次;Conv表示为yolov5自己定义的卷积模块;Conv定义时的参数列表为:
class Conv(nn.Module):
# Standard convolution
def __init__(self, c1, c2, k=1, s=1, p=None, g=1, act=True): # ch_in, ch_out, kernel, stride, padding, groups
c1为输入通道,这里不用管,c2为输出通道,所以在这里他就是256,k为1,s为1,后面没有了,那就是采用默认的了。
再举个例子 [[-1, 4], 1, Concat, [1]],表示:从上一层和索引为4的那一层获得两层输入,然后模块采用1次,模块为 Concat,参数列表为 [1]。表示torch.cat操作在维度1上进行,Concat的定义如下:
class Concat(nn.Module):
# Concatenate a list of tensors along dimension
def __init__(self, dimension=1):
super().__init__()
self.d = dimension
def forward(self, x):
return torch.cat(x, self.d)
其他的模块大同小异,很快就能搞懂,至于你想知道他怎么计算的输入通道数,在models.yolo.py文件里有个parse_model函数,如果是Conv模块,通过如下计算输入通道
c1, c2 = ch[f], args[0]
ch保存了每一层的输出通道,通过f索引即可获得f层的输出通道,也就是当前层的输入通道。
如果是Concat层,通过如下计算输入通道
elif m is Concat:
c2 = sum(ch[x] for x in f)
Concat的f为[-1, 4],所以这里会将保存下的上一层的通道数和索引4层的通道数相加作为当前层的输入通道数。
好了,到了这里,我想我们应该能大致了解了如何定义一个模块加进去了,由于我只是想改,所以我不会太多修改他的代码,所以如果有些模块不需要c2的话我也会放进去,只需要模块的定义文件里不用他就行了。
2、简单尝试定义一个4层yolov5模型
首先,我们把原始yolov5的结构索引图画出来,这样会帮助我们定义模型结构。这里不再纠结每一层是什么意思,自己可以对着表看看,反正大概就是yolo的通用结构,可能这个定义模块跟一般的讲解不太一样,因为有些讲解把它综合了一下,想要知道每一块具体是什么,可以去看yolov5l.yaml的配置列表。

暂不考虑每一块代表什么意思,我想大家应该都要有一些基础,就是yolo基本上都是颈部网络加上头部网络组成了预测网络。颈部网络一半就是各种fpn变体,如bifpn,或者panet,主要是加强特征融合,以及跨尺度传递信息,或者是多尺度预测,这已经是yolo的标配了,这一部分也可以看作是编码网络;而头部网络则负责将加强特征进行预测,可以理解为解码,从特征中提出最后每一个特征上的每一个网络中是否有目标,目标种类是什么,有目标的概率是多大。
颈部网络基本就是上采样和下采样构成,如果是bifpn可能更多,但他们都是有迹可循,我们甚至不需要了解它每一块是什么意思,大致就可以画出4层yolov5的结构索引图。从上图可以看出,上采样需要4块,下采样需要3块,那我们画出图来,就变成了下面这样子:
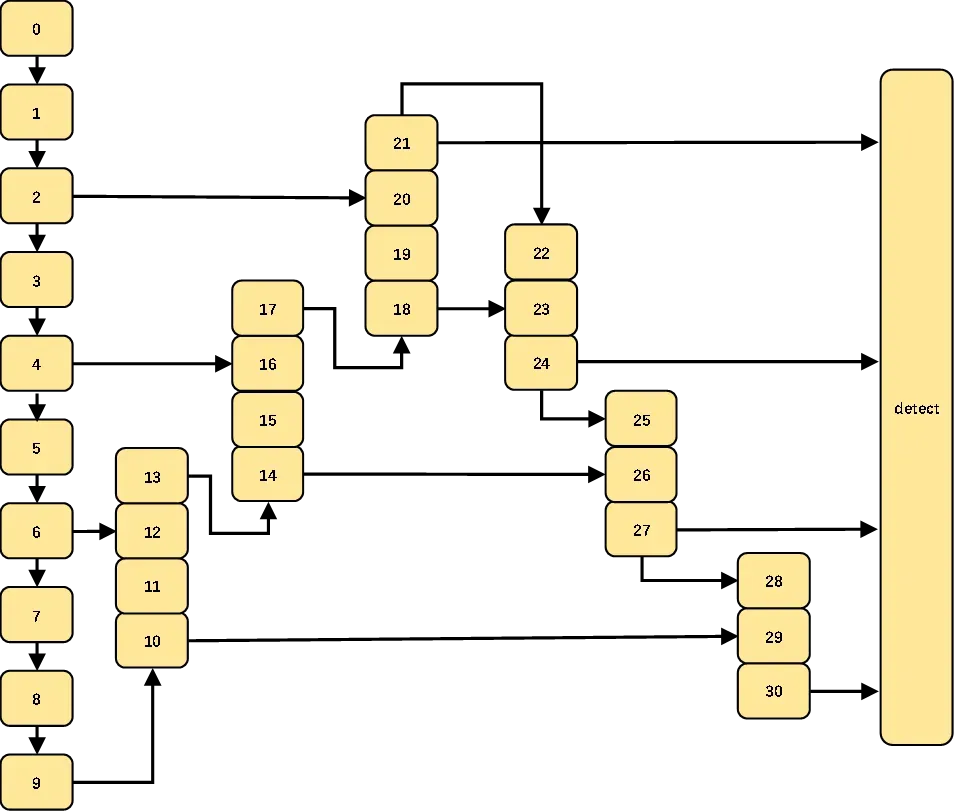
很简单,就是照葫芦画瓢,原来的17层那里,不再是下采样,而是继续上采样,获得更大尺寸的特征图,也就是18-21的操作,然后我们模仿原始的yolov5的操作,再来下采样,也就是现在的22-24,就顺利的在结构图上添上了我们想要的4层。然后,就需要我们写出配置文件了,如下:
# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
# Parameters
nc: 8 # number of classes
depth_multiple: 1.0 # model depth multiple
width_multiple: 1.0 # layer channel multiple
anchors:
- [5,6, 8,14, 15,11]
- [10,13, 16,30, 33,23] # P3/8
- [30,61, 62,45, 59,119] # P4/16
- [116,90, 156,198, 373,326] # P5/32
# YOLOv5 v6.0 backbone
backbone:
# [from, number, module, args]
[[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2
[-1, 1, Conv, [128, 3, 2]], # 1-P2/4
[-1, 3, C3, [128]],
[-1, 1, Conv, [256, 3, 2]], # 3-P3/8
[-1, 6, C3, [256]],
[-1, 1, Conv, [512, 3, 2]], # 5-P4/16
[-1, 9, C3, [512]],
[-1, 1, Conv, [1024, 3, 2]], # 7-P5/32
[-1, 3, C3, [1024]],
[-1, 1, SPPF, [1024, 5]], # 9
]
# YOLOv5 v6.0 head
head:
[[-1, 1, Conv, [512, 1, 1]], # 10
[-1, 1, nn.Upsample, [None, 2, 'nearest']], # 11
[[-1, 6], 1, Concat, [1]], # cat backbone P4 12
[-1, 3, C3, [512, False]], # 13
[-1, 1, Conv, [256, 1, 1]], # 14
[-1, 1, nn.Upsample, [None, 2, 'nearest']], # 15
[[-1, 4], 1, Concat, [1]], # cat backbone P3 16
[-1, 3, C3, [256, False]], # 17 (P3/8-small) 17
[ -1, 1, Conv, [ 128, 1, 1 ] ], # 18
[ -1, 1, nn.Upsample, [ None, 2, 'nearest' ] ], # 19
[ [ -1, 2 ], 1, Concat, [ 1 ] ], # cat backbone P2 20
[ -1, 3, C3, [ 128, False ] ], # 21 (P2/4-xsmall) 21
[-1, 1, Conv, [128, 3, 2]], # 22
[[-1, 18], 1, Concat, [1]], # cat head P3 23
[-1, 3, C3, [256, False]], # 24 (P3/8-small) 24
[-1, 1, Conv, [256, 3, 2]], # 25
[[-1, 14], 1, Concat, [1]], # cat head P4 26
[-1, 3, C3, [512, False]], # 27 (P4/16-medium) 27
[-1, 1, Conv, [512, 3, 2]], # 28
[[-1, 10], 1, Concat, [1]], # cat head P5 # 29
[-1, 3, C3, [1024, False]], # 30 (P5/32-large) 30
[[21, 24, 27, 30], 1, Detect, [nc, anchors]], # Detect(P2, P3, P4, P5)
]
本来是要计算模块定义的所需通道数的,因为我们加了一层,虽然模块跟之前的一样,但是通道数是要变的。但是只要观察规律都可以看出来18和21就是128,22和24分别是128和256。这里就算通道数错了也没事,能跑通,因为之前说过,后面的层会自己计算你这一层的输出通道是多少,自适应的修改。所以一定要检查,否则都不会报错的!!!
我们可以简单分析一下,原始的17层得到的通道数为256的特征,然后直接被送入头部网络,在我们4层里,这里先进行通道压缩为128,也就是18层的操作;19层将18层的特征上采样,不改变通道数,仍然是128,至于特征尺寸,则会增加一倍;然后20层将19层和第二层的128通道相加,得到的是256通道数的特征,19层和2层的特征尺寸是一样大的,可以自行算算;然后21层压缩通道数变成了128。22层的就是用卷积替代了下采样的作用,通道数仍为128,尺寸缩小至原来的0.5;然后23和24也没什么区别,简单的特征拼接和特征整理,没有压缩通道数的操作。
至此,模型修改完毕,然后最后的31层就是头部网络,也就是Detect层,改成现在的需要预测的4层特征索引即可,然后对应的配置文件最开始的anchors也要改成4层,这里可以自己聚类,也可以运行起来自动聚类,yolov5有这个功能,默认自动聚类,但是anchor层数一定要写对。
训练的时候,我们在train.py函数里指定我们定义的模型结构配置文件,也就是要修改如下代码:
parser.add_argument('--cfg', type=str, default='my_yolov5l_01.yaml', help='model.yaml path')
我的配置文件改名成了’my_yolov5l_01.yaml’,它应该会自己搜索models路径下的这个配置文件,如果找不到这个,可以改成绝对路径。
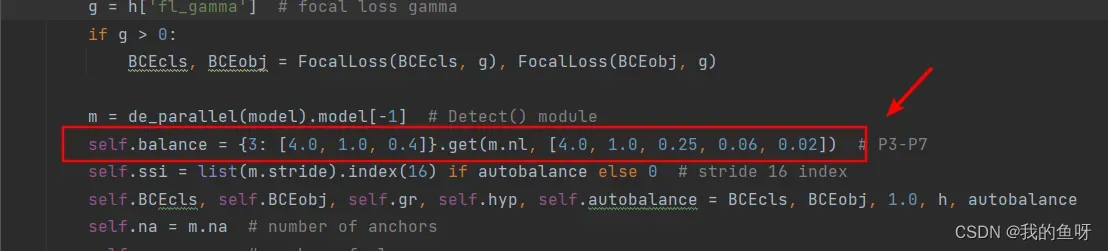
如果数据集中大目标不多但是也有一些,改完之后发现大目标的检测效果变差了,可以修改utils/loss.py中的ComputeLoss类中中的这个地方,yolov5已经帮你自适应的定义好了每一层目标框回归损失所占的比重。由于大目标的尺寸较大,同样个数的大小目标,大目标的目标框损失更大,所以这个给每一层设置了不同的权重,如果为默认的3层,则为3: [4.0, 1.0, 0.4],从左到右依次是最低层到最高层,这里的高层是指特征尺寸最小的一层。如果不为3层则会取值为
m.nl:[4.0, 1.0, 0.25, 0.06, 0.02],nl就是特征层数,这里为4,也就是计算损失的时候,特征尺寸最小的所占权重为0.06,特征尺寸最大的那一层的权重为4.0.可以看出,改完的4层大目标所占的权重变得更小了,只有0.06,如果正好大目标样本较少,那么就无法有效训练了,所以可以将其改为m.nl:[4.0, 1.0, 0.4, 0.4, 0.02],当然也可以自己调参改改,我只是保持了跟原来的3层的一样;后面的0.02不会用到,如果改成了5层,才会用到,最高0.02就是给最高一层了,那这样的话就更小了。
修改完上述所有地方后,就可以照常训练了,加载的预训练权重可以用原始的yolov5.pt,他会加载共有部分的权重。
3、尝试加入一个CA注意力模块
CA注意力模块的官方代码如下:
import torch
import torch.nn as nn
import math
import torch.nn.functional as F
class h_sigmoid(nn.Module):
def __init__(self, inplace=True):
super(h_sigmoid, self).__init__()
self.relu = nn.ReLU6(inplace=inplace)
def forward(self, x):
return self.relu(x + 3) / 6
class h_swish(nn.Module):
def __init__(self, inplace=True):
super(h_swish, self).__init__()
self.sigmoid = h_sigmoid(inplace=inplace)
def forward(self, x):
return x * self.sigmoid(x)
class CoordAtt(nn.Module):
def __init__(self, inp, oup, reduction=32):
super(CoordAtt, self).__init__()
self.pool_h = nn.AdaptiveAvgPool2d((None, 1))
self.pool_w = nn.AdaptiveAvgPool2d((1, None))
mip = max(8, inp // reduction)
self.conv1 = nn.Conv2d(inp, mip, kernel_size=1, stride=1, padding=0)
self.bn1 = nn.BatchNorm2d(mip)
self.act = h_swish()
self.conv_h = nn.Conv2d(mip, oup, kernel_size=1, stride=1, padding=0)
self.conv_w = nn.Conv2d(mip, oup, kernel_size=1, stride=1, padding=0)
def forward(self, x):
identity = x
n,c,h,w = x.size()
x_h = self.pool_h(x)
x_w = self.pool_w(x).permute(0, 1, 3, 2)
y = torch.cat([x_h, x_w], dim=2)
y = self.conv1(y)
y = self.bn1(y)
y = self.act(y)
x_h, x_w = torch.split(y, [h, w], dim=2)
x_w = x_w.permute(0, 1, 3, 2)
a_h = self.conv_h(x_h).sigmoid()
a_w = self.conv_w(x_w).sigmoid()
out = identity * a_w * a_h
return out
它里面自定义了两个操作,这里不用管,到时候一起复制过去就行了。这里不再赘述原理,只是从怎么分析然后动手改进来讲起。我们可以看到他的 def __init__(self, inp, oup, reduction=32):这里,我们需要传入两个参数,一个inp,也就是输入通道,一个oup,也就是输出通道,分别对应yolov5的c1,c2。正常情况下,ca一般不改变通道数,所以c1传入的通道数直接赋值给了inp,那么oup就不需要传入了,但是ca里面最后又要用到oup了,那怎么办呢?简单,把所有的oup换成inp就行了,前提是你的模块输入输出通道数一样!!!!也就是下面的样子:
class CoordAtt(nn.Module):
def __init__(self, inp, oup, reduction=32):
super(CoordAtt, self).__init__()
self.pool_h = nn.AdaptiveAvgPool2d((None, 1))
self.pool_w = nn.AdaptiveAvgPool2d((1, None))
mip = max(8, inp // reduction)
self.conv1 = nn.Conv2d(inp, mip, kernel_size=1, stride=1, padding=0)
self.bn1 = nn.BatchNorm2d(mip)
self.act = h_swish()
# 这里变了!!!!!
self.conv_h = nn.Conv2d(mip, inp, kernel_size=1, stride=1, padding=0)
self.conv_w = nn.Conv2d(mip, inp, kernel_size=1, stride=1, padding=0)
def forward(self, x):
identity = x
n,c,h,w = x.size()
x_h = self.pool_h(x)
x_w = self.pool_w(x).permute(0, 1, 3, 2)
y = torch.cat([x_h, x_w], dim=2)
y = self.conv1(y)
y = self.bn1(y)
y = self.act(y)
x_h, x_w = torch.split(y, [h, w], dim=2)
x_w = x_w.permute(0, 1, 3, 2)
a_h = self.conv_h(x_h).sigmoid()
a_w = self.conv_w(x_w).sigmoid()
out = identity * a_w * a_h
return out
这样子的话,那我们在配置文件中传入的输出通道数就可以随便定义了。
或者,不采用上述方法,那么就老老实实的计算出输出通道数为多少,然后好好的填进去!一定不要弄错了,我是为了偷懒,所以才像上述那样做!!!!
分析好了源代码,以及配置文件,我们就可以开始改进了。
首先,我们要把导入的包和源代码都拷入models/conmon.py文件中,就采用原始的ca代码吧,不偷懒。
然后,我们要修改models/yolo.py下的parse_model函数,这个函数负责将yaml模型配置文件解析成nn.Sequential形式的模型,我们需要修改里面的代码,才能让我们自己定义的模块被识别。这里不用管导入问题,他自己导入了common中的所有模块。
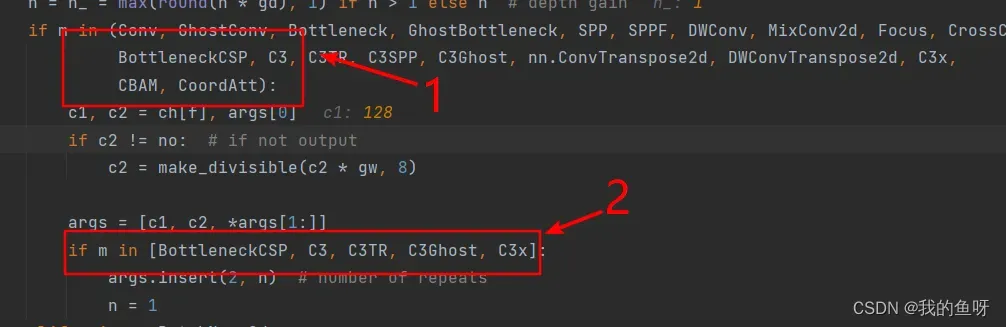
如果仔细看了我前面所说的,这里应该不难理解这些参数的意义,上图中1处只是添加进去,并被识别,不传入n到模块里,也就是连续运行几次,如果需要修改n,则需要在2处也改了,否则默认就是1,C3或者其他模块需要传入n,表示里面的某一模块连续运行n次,所以这里设置了这个功能。这里我们的原始ca是没有这个参数的所以是不需要在第二处添加CoordAtt,因为有些人需要在C3模块里添加ca,所以如果有这样的操作的话,记得在第二处那里把你需改好的C3CA模块放进去。改完这里之后,我们定义的模块就可以被识别并解析了,然后接下来需要写好我们的模型配置定义文件就好了。如下所示:
# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
# 4层+ca
# Parameters
nc: 20 # number of classes
depth_multiple: 1.0 # model depth multiple
width_multiple: 1.0 # layer channel multiple
anchors:
- [5,6, 8,14, 15,11]
- [10,13, 16,30, 33,23] # P3/8
- [30,61, 62,45, 59,119] # P4/16
- [116,90, 156,198, 373,326] # P5/32
# YOLOv5 v6.0 backbone
backbone:
# [from, number, module, args]
[[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2
[-1, 1, Conv, [128, 3, 2]], # 1-P2/4
[-1, 3, C3, [128]],
[-1, 1, Conv, [256, 3, 2]], # 3-P3/8
[-1, 6, C3, [256]],
[-1, 1, Conv, [512, 3, 2]], # 5-P4/16
[-1, 9, C3, [512]],
[-1, 1, Conv, [1024, 3, 2]], # 7-P5/32
[-1, 3, C3, [1024]],
[-1, 1, CoordAtt, [1024]],
[-1, 1, SPPF, [1024, 5]], # 10
]
# YOLOv5 v6.0 head
head:
[[-1, 1, Conv, [512, 1, 1]], # 11
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[6, 1, CoordAtt, [512]],
[[-2, -1], 1, Concat, [1]], # cat backbone P4
[-1, 3, C3, [512, False]], # 15
[-1, 1, Conv, [256, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[ 4, 1, CoordAtt, [ 256 ] ],
[[-2, -1], 1, Concat, [1]], # cat backbone P3
[-1, 3, C3, [256, False]], # 20 (P3/8-small)
[ -1, 1, Conv, [ 128, 1, 1 ] ],
[ -1, 1, nn.Upsample, [ None, 2, 'nearest' ] ],
[ 2, 1, CoordAtt, [ 128 ] ],
[ [ -2, -1 ], 1, Concat, [ 1 ] ], # cat backbone P2
[ -1, 3, C3, [ 128, False ] ], # 25 (P2/4-xsmall)
[-1, 1, Conv, [128, 3, 2]],
[[-1, 21], 1, Concat, [1]], # cat head P3
[-1, 3, C3, [256, False]], # 28 (P3/8-small)
[-1, 1, Conv, [256, 3, 2]],
[[-1, 16], 1, Concat, [1]], # cat head P4
[-1, 3, C3, [512, False]], # 31 (P4/16-medium)
[-1, 1, Conv, [512, 3, 2]],
[[-1, 11], 1, Concat, [1]], # cat head P5
[-1, 3, C3, [1024, False]], # 34 (P5/32-large)
[[25, 28, 31, 34], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)
]
我跟别人加注意力的地方不太一样,我喜欢把它添加在主干网络引出到颈部网络的部分,我想让它自适应的筛选一下主干网络中提取的特征中比较重要的特征。结构图如下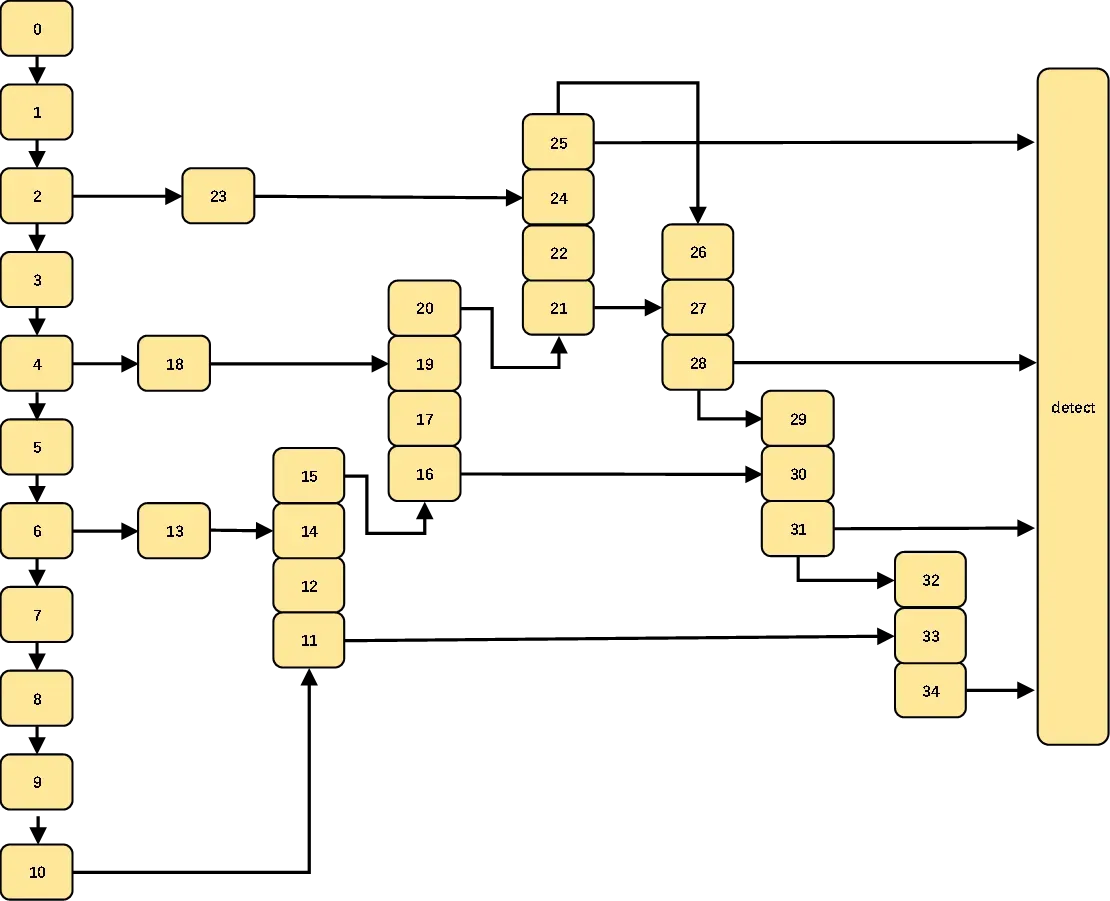
至此,所有地方修改完毕,修改好train.py中的配置文件及其他对应地方即可运行训练,如果是linux的在命令行尝试一下输入就行了,我喜欢用pycharm,所以用的不多,就算是用linux,我也会先把代码修改好,然后直接python3 train.py,多快乐。
文章出处登录后可见!