更高FLOPS才是更快更强的底气,作者重新审视了现有的操作符,特别是DWConv的计算速度——FLOPS。作者发现导致低FLOPS问题的主要原因是频繁的内存访问。然后,作者提出了PConv作为一种竞争性替代方案,它减少了计算冗余以及内存访问的数量。
论文链接:https://paperswithcode.com/paper/run-don-t-walk-chasing-higher-flops-for
为了设计快速神经网络,许多工作都集中在减少浮点运算(FLOPs)的数量上。然而,作者观察到FLOPs的这种减少不一定会带来延迟的类似程度的减少。这主要源于每秒低浮点运算(FLOPS)效率低下。
为了实现更快的网络,作者重新回顾了FLOPs的运算符,并证明了如此低的FLOPS主要是由于运算符的频繁内存访问,尤其是深度卷积。因此,本文提出了一种新的partial convolution(PConv),通过同时减少冗余计算和内存访问可以更有效地提取空间特征。
基于PConv进一步提出FasterNet,这是一个新的神经网络家族,它在广泛的设备上实现了比其他网络高得多的运行速度,而不影响各种视觉任务的准确性。例如,在ImageNet-1k上小型FasterNet-T0在GPU、CPU和ARM处理器上分别比MobileVitXXS快3.1倍、3.1倍和2.5倍,同时准确度提高2.9%。
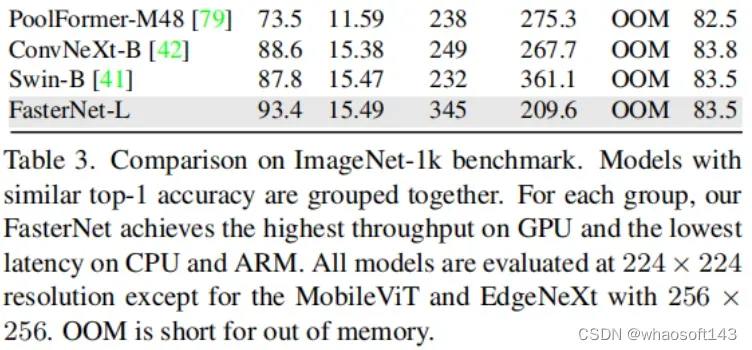
大模型FasterNet-L实现了令人印象深刻的83.5%的TOP-1精度,与Swin-B不相上下,同时GPU上的推理吞吐量提高了49%,CPU上的计算时间也节省了42%。
神经网络在图像分类、检测和分割等各种计算机视觉任务中经历了快速发展。尽管其令人印象深刻的性能为许多应用程序提供了动力,但一个巨大的趋势是追求具有低延迟和高吞吐量的快速神经网络,以获得良好的用户体验、即时响应和安全原因等。
如何快速?研究人员和从业者不需要更昂贵的计算设备,而是倾向于设计具有成本效益的快速神经网络,降低计算复杂度,主要以浮点运算(FLOPs)的数量来衡量。
MobileNet、ShuffleNet和GhostNet等利用深度卷积(DWConv)和/或组卷积(GConv)来提取空间特征。然而,在减少FLOPs的过程中,算子经常会受到内存访问增加的副作用的影响。MicroNet进一步分解和稀疏网络,将其FLOPs推至极低水平。尽管这种方法在FLOPs方面有所改进,但其碎片计算效率很低。此外,上述网络通常伴随着额外的数据操作,如级联、Shuffle和池化,这些操作的运行时间对于小型模型来说往往很重要。
除了上述纯卷积神经网络(CNNs)之外,人们对使视觉Transformer(ViTs)和多层感知器(MLP)架构更小更快也越来越感兴趣。例如,MobileViT和MobileFormer通过将DWConv与改进的注意力机制相结合,降低了计算复杂性。然而,它们仍然受到DWConv的上述问题的困扰,并且还需要修改的注意力机制的专用硬件支持。使用先进但耗时的标准化和激活层也可能限制其在设备上的速度。
所有这些问题一起导致了以下问题:这些“快速”的神经网络真的很快吗?为了回答这个问题,作者检查了延迟和FLOPs之间的关系,这由
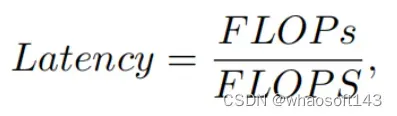
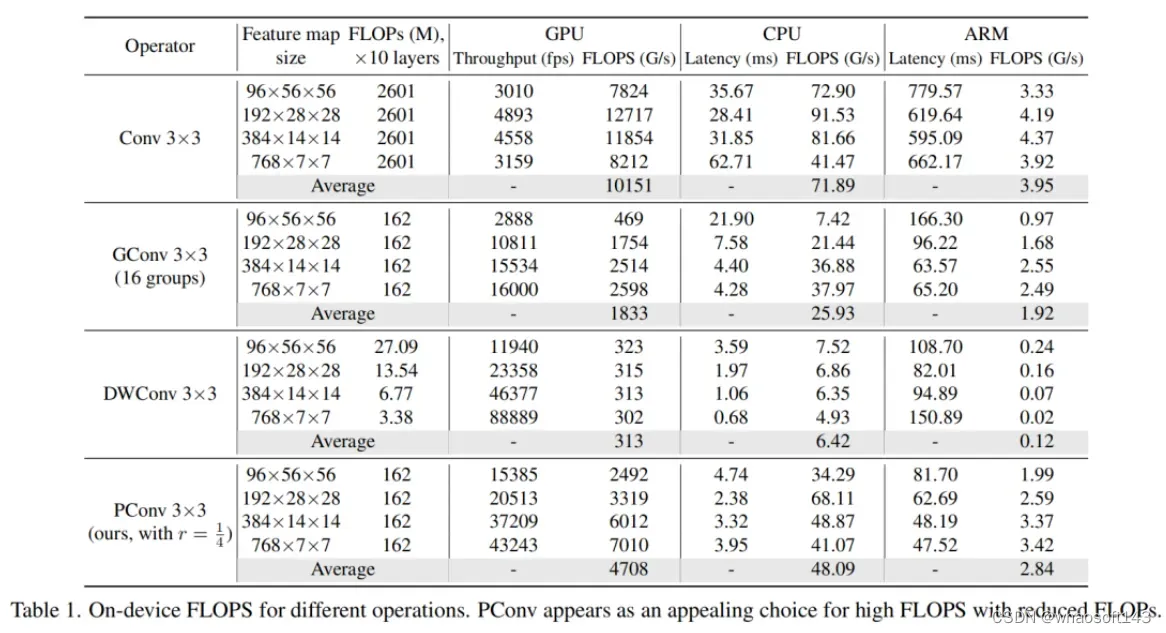
其中FLOPS是每秒浮点运算的缩写,作为有效计算速度的度量。虽然有许多减少FLOPs的尝试,但都很少考虑同时优化FLOPs以实现真正的低延迟。为了更好地理解这种情况,作者比较了Intel CPU上典型神经网络的FLOPS。
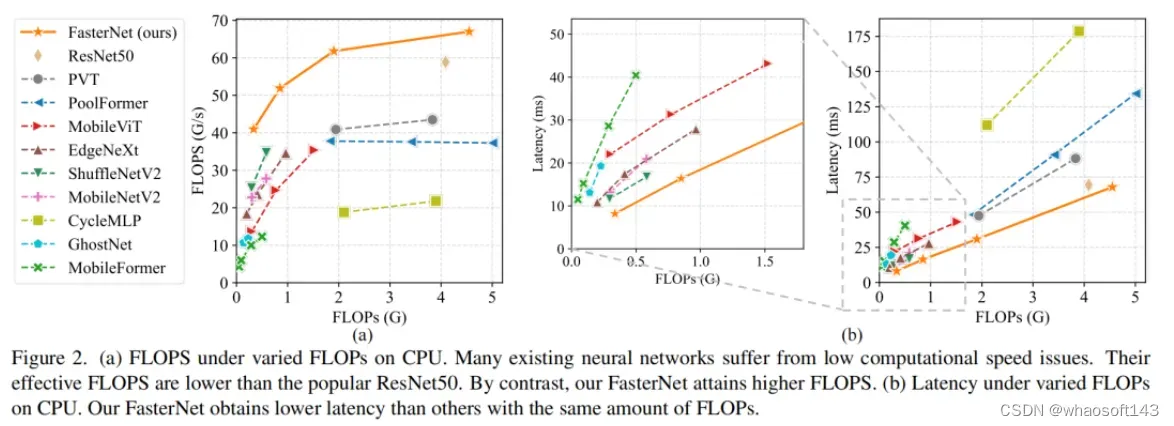
图2中的结果表明,许多现有神经网络的FLOPS较低,其FLOPS通常低于流行的ResNet50。由于FLOPS如此之低,这些“快速”的神经网络实际上不够快。它们的FLOPs减少不能转化为延迟的确切减少量。在某些情况下,没有任何改善,甚至会导致更糟的延迟。例如,CycleMLP-B1具有ResNet50的一半FLOPs,但运行速度较慢(即CycleMLPB1与ResNet50:111.9ms与69.4ms)。
请注意,FLOPs与延迟之间的差异在之前的工作中也已被注意到,但由于它们采用了DWConv/GConv和具有低FLOPs的各种数据处理,因此部分问题仍未解决。人们认为没有更好的选择。
本文旨在通过开发一种简单、快速、有效的运算符来消除这种差异,该运算符可以在减少FLOPs的情况下保持高FLOPS。具体来本文旨在通过开发一种简单、快速、有效的运算符来消除这种差异,该运算符可以在减少FLOPs的情况下保持高FLOPS。
具体来说,作者重新审视了现有的操作符,特别是DWConv的计算速度——FLOPS。作者发现导致低FLOPS问题的主要原因是频繁的内存访问。然后,作者提出了PConv作为一种竞争性替代方案,它减少了计算冗余以及内存访问的数量。
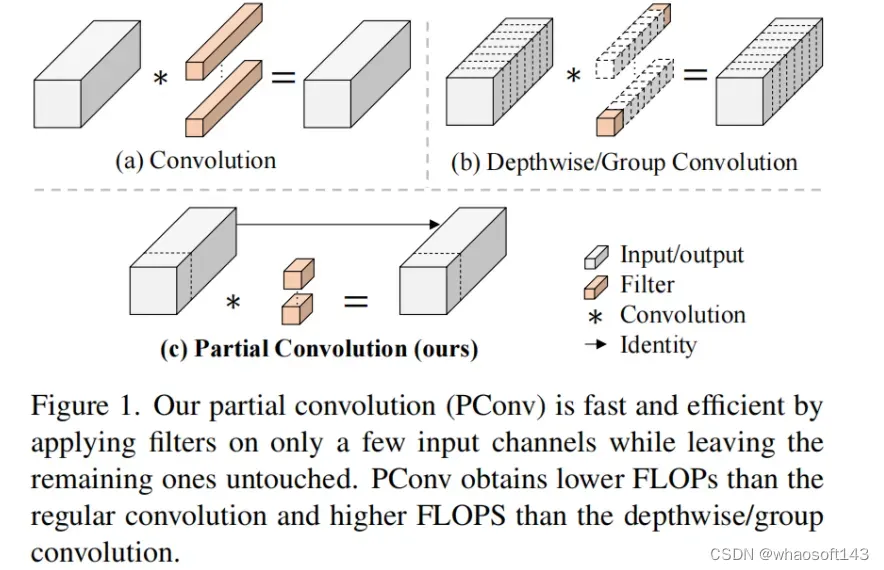
图1说明了PConv的设计。它利用了特征图中的冗余,并系统地仅在一部分输入通道上应用规则卷积(Conv),而不影响其余通道。本质上,PConv的FLOPs低于常规Conv,而FLOPs高于DWConv/GConv。换句话说,PConv更好地利用了设备上的计算能力。PConv在提取空间特征方面也很有效,这在本文后面的实验中得到了验证。
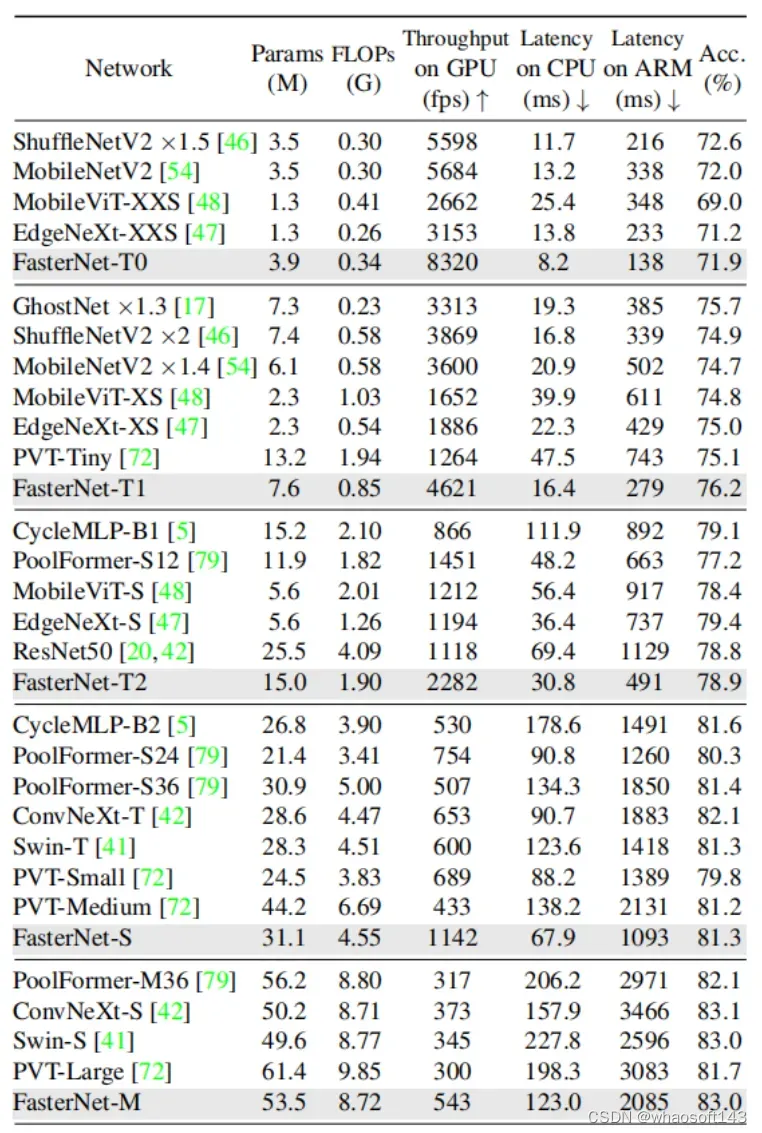
作者进一步引入PConv设计了FasterNet作为一个在各种设备上运行速度非常快的新网络家族。特别是,FasterNet在分类、检测和分割任务方面实现了最先进的性能,同时具有更低的延迟和更高的吞吐量。例如,在GPU、CPU和ARM处理器上,小模型FasterNet-T0分别比MobileVitXXS快3.1倍、3.1倍和2.5倍,而在ImageNet-1k上的准确率高2.9%。大模型FasterNet-L实现了83.5%的Top-1精度,与Swin-B不相上下,同时在GPU上提供了49%的高吞吐量,在CPU上节省了42%的计算时间。
总之,贡献如下:
-
指出了实现更高FLOPS的重要性,而不仅仅是为了更快的神经网络而减少FLOPs。
-
引入了一种简单但快速且有效的卷积PConv,它很有可能取代现有的选择DWConv。
-
推出FasterNet,它在GPU、CPU和ARM处理器等多种设备上运行良好且普遍快速。
-
对各种任务进行了广泛的实验,并验证了PConv和FasterNet的高速性和有效性。
PConv和FasterNet的设计
原理

PConv作为一个基本的算子
 在下面演示了通过利用特征图的冗余度可以进一步优化成本。如图3所示,特征图在不同通道之间具有高度相似性。许多其他著作也涵盖了这种冗余,但很少有人以简单而有效的方式充分利用它。
在下面演示了通过利用特征图的冗余度可以进一步优化成本。如图3所示,特征图在不同通道之间具有高度相似性。许多其他著作也涵盖了这种冗余,但很少有人以简单而有效的方式充分利用它。 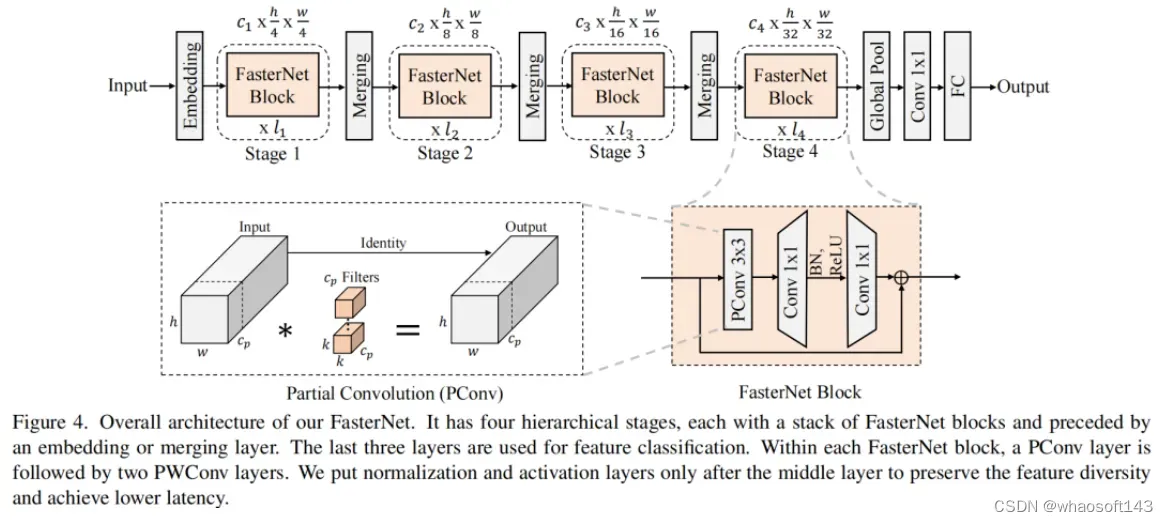

请注意,保持其余通道不变,而不是从特征图中删除它们。这是因为它们对后续PWConv层有用,PWConv允许特征信息流经所有通道。
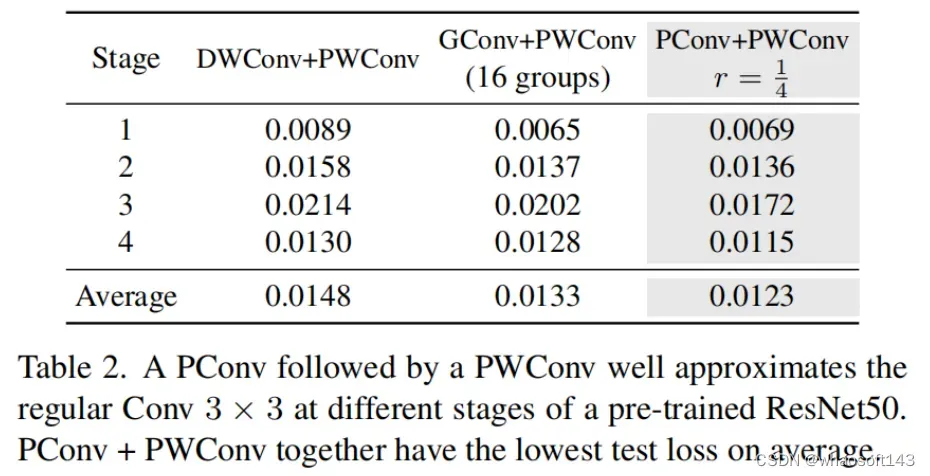
PConv之后是PWConv
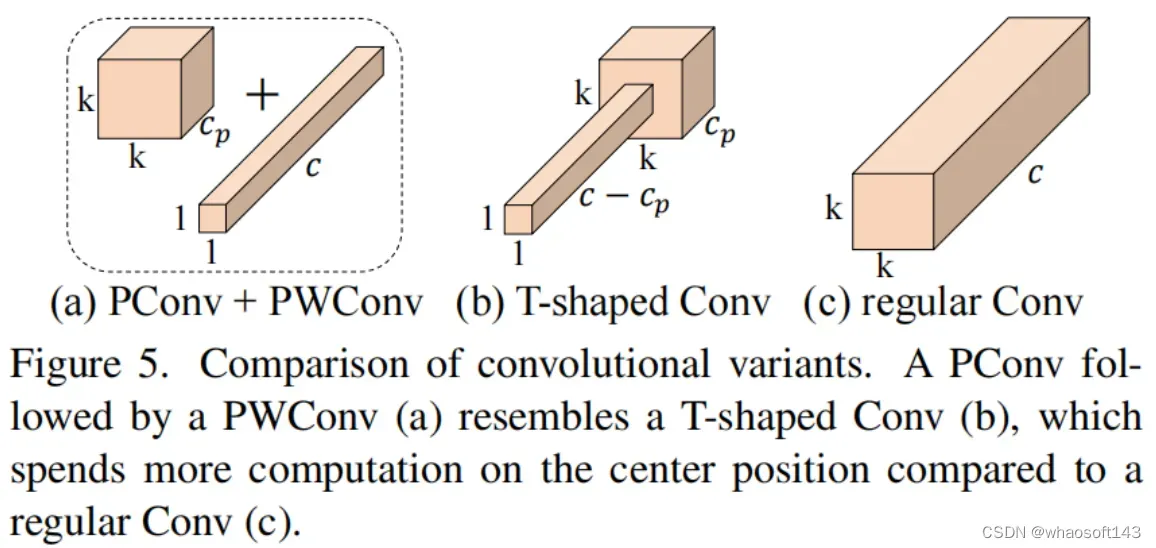 为了充分有效地利用来自所有通道的信息,进一步将逐点卷积(PWConv)附加到PConv。它们在输入特征图上的有效感受野看起来像一个T形Conv,与均匀处理补丁的常规Conv相比,它更专注于中心位置,如图5所示。为了证明这个T形感受野的合理性,首先通过计算位置的Frobenius范数来评估每个位置的重要性。
为了充分有效地利用来自所有通道的信息,进一步将逐点卷积(PWConv)附加到PConv。它们在输入特征图上的有效感受野看起来像一个T形Conv,与均匀处理补丁的常规Conv相比,它更专注于中心位置,如图5所示。为了证明这个T形感受野的合理性,首先通过计算位置的Frobenius范数来评估每个位置的重要性。
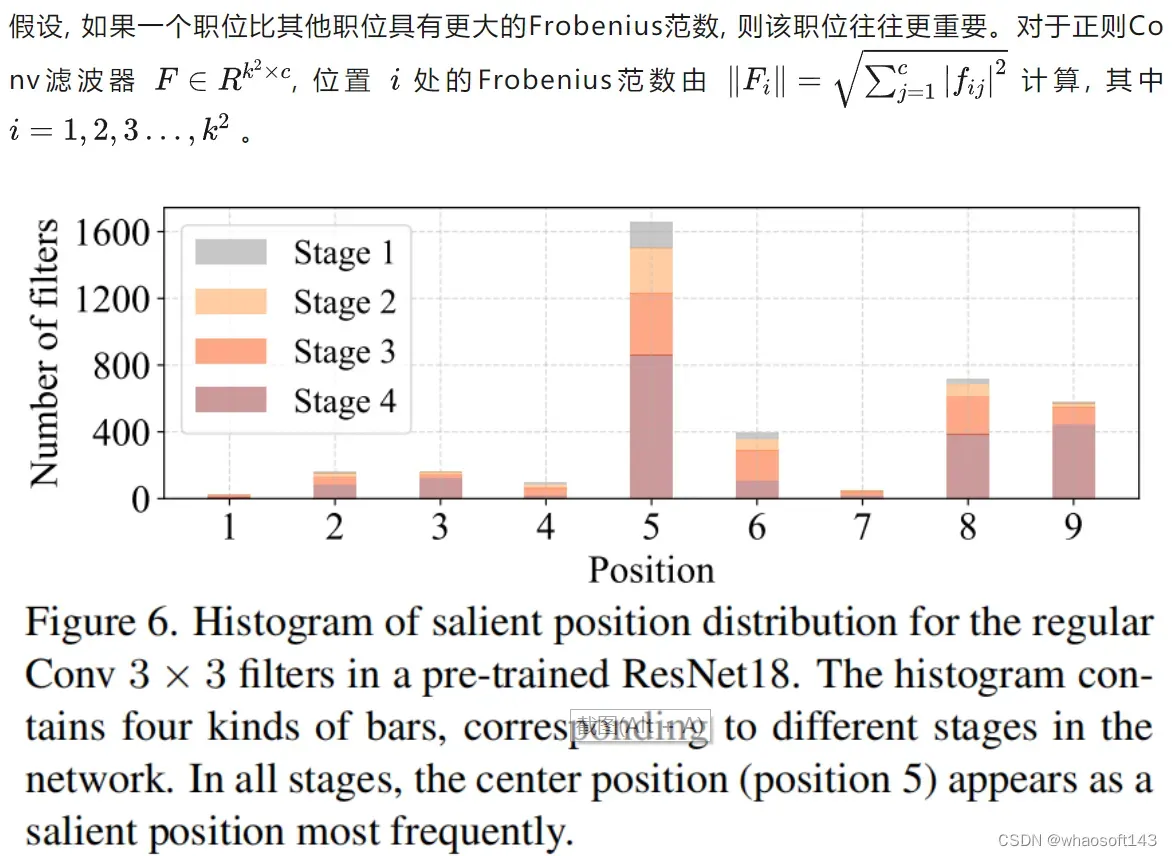 作者认为一个显著位置是具有最大Frobenius范数的位置。然后,在预训练的ResNet18中集体检查每个过滤器,找出它们的显著位置,并绘制显著位置的直方图。图6中的结果表明,中心位置是过滤器中最常见的突出位置。换句话说,中心位置的权重比周围的更重。这与集中于中心位置的T形计算一致。
作者认为一个显著位置是具有最大Frobenius范数的位置。然后,在预训练的ResNet18中集体检查每个过滤器,找出它们的显著位置,并绘制显著位置的直方图。图6中的结果表明,中心位置是过滤器中最常见的突出位置。换句话说,中心位置的权重比周围的更重。这与集中于中心位置的T形计算一致。

FasterNet作为Backbone
鉴于新型PConv和现成的PWConv作为主要的算子,进一步提出FasterNet,这是一个新的神经网络家族,运行速度非常快,对许多视觉任务非常有效。作者的目标是使体系结构尽可能简单,使其总体上对硬件友好。
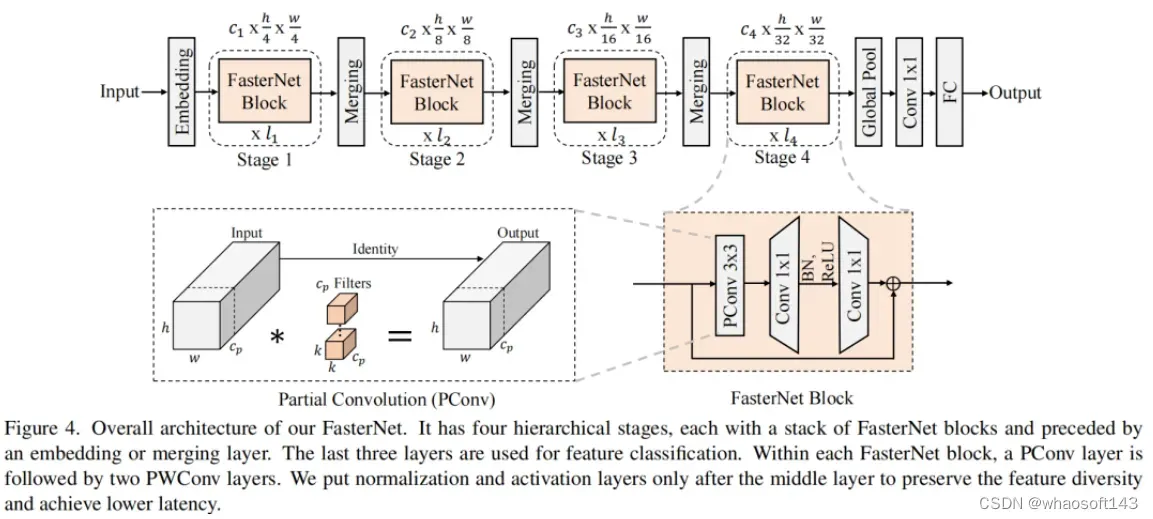 在图4中展示了整体架构。它有4个层次级,每个层次级前面都有一个嵌入层(步长为4的常规4×4卷积)或一个合并层(步长为2的常规2×2卷积),用于空间下采样和通道数量扩展。每个阶段都有一堆FasterNet块。作者观察到,最后两个阶段中的块消耗更少的内存访问,并且倾向于具有更高的FLOPS,如表1中的经验验证。因此,放置了更多FasterNet块,并相应地将更多计算分配给最后两个阶段。每个FasterNet块有一个PConv层,后跟2个PWConv(或Conv 1×1)层。它们一起显示为倒置残差块,其中中间层具有扩展的通道数量,并且放置了Shorcut以重用输入特征。
在图4中展示了整体架构。它有4个层次级,每个层次级前面都有一个嵌入层(步长为4的常规4×4卷积)或一个合并层(步长为2的常规2×2卷积),用于空间下采样和通道数量扩展。每个阶段都有一堆FasterNet块。作者观察到,最后两个阶段中的块消耗更少的内存访问,并且倾向于具有更高的FLOPS,如表1中的经验验证。因此,放置了更多FasterNet块,并相应地将更多计算分配给最后两个阶段。每个FasterNet块有一个PConv层,后跟2个PWConv(或Conv 1×1)层。它们一起显示为倒置残差块,其中中间层具有扩展的通道数量,并且放置了Shorcut以重用输入特征。
除了上述算子,标准化和激活层对于高性能神经网络也是不可或缺的。然而,许多先前的工作在整个网络中过度使用这些层,这可能会限制特征多样性,从而损害性能。它还可以降低整体计算速度。相比之下,只将它们放在每个中间PWConv之后,以保持特征多样性并实现较低的延迟。
此外,使用批次归一化(BN)代替其他替代方法。BN的优点是,它可以合并到其相邻的Conv层中,以便更快地进行推断,同时与其他层一样有效。对于激活层,根据经验选择了GELU用于较小的FasterNet变体,而ReLU用于较大的FasterNet变体,同时考虑了运行时间和有效性。最后三个层,即全局平均池化、卷积1×1和全连接层,一起用于特征转换和分类。
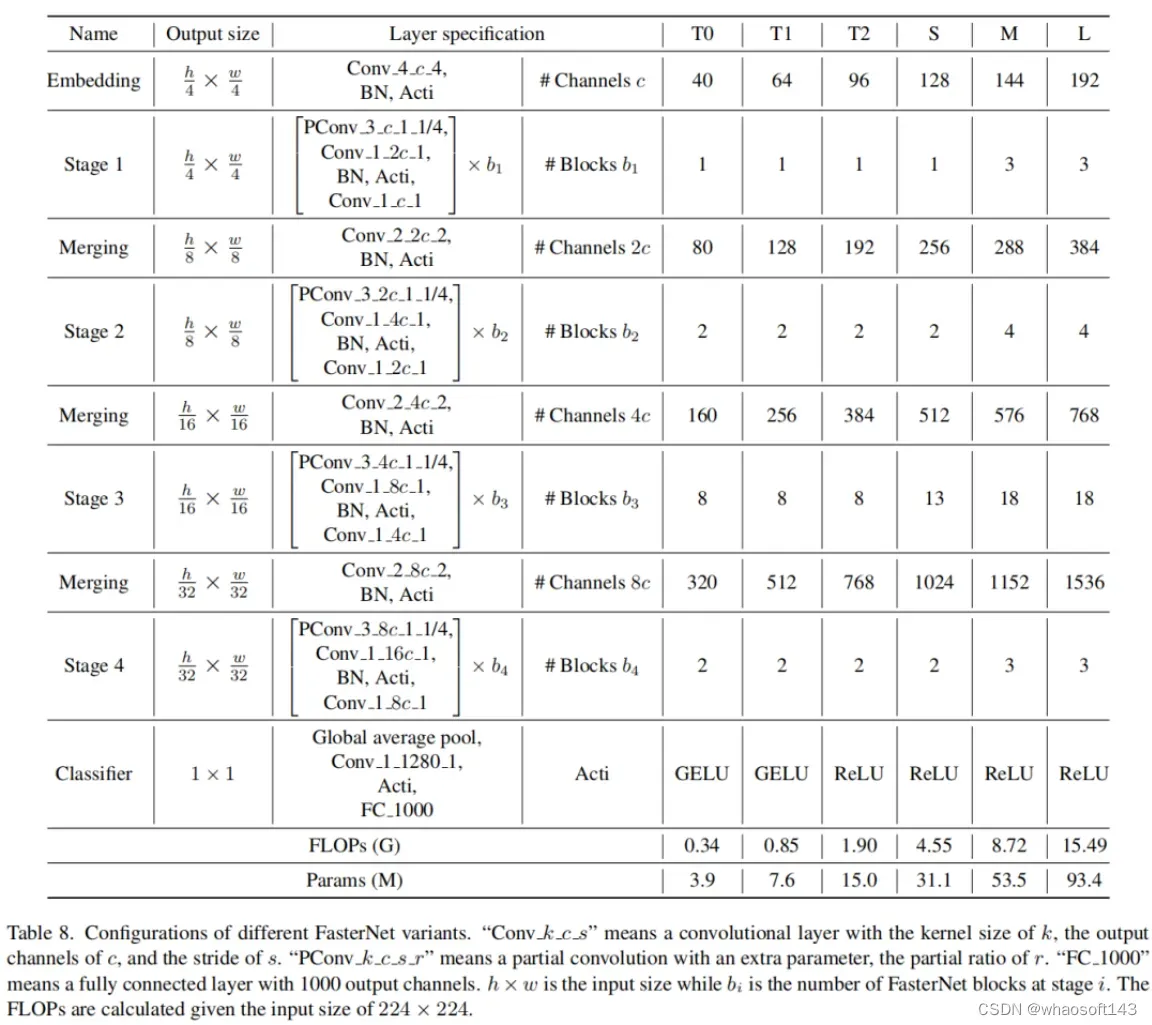
为了在不同的计算预算下提供广泛的应用,提供FasterNet的Tiny模型、Small模型、Medium模型和Big模型变体,分别称为FasterNetT0/1/2、FasterNet-S、FasterNet-M和FasterNet-L。它们具有相似的结构,但深度和宽度不同。
架构规范如下:
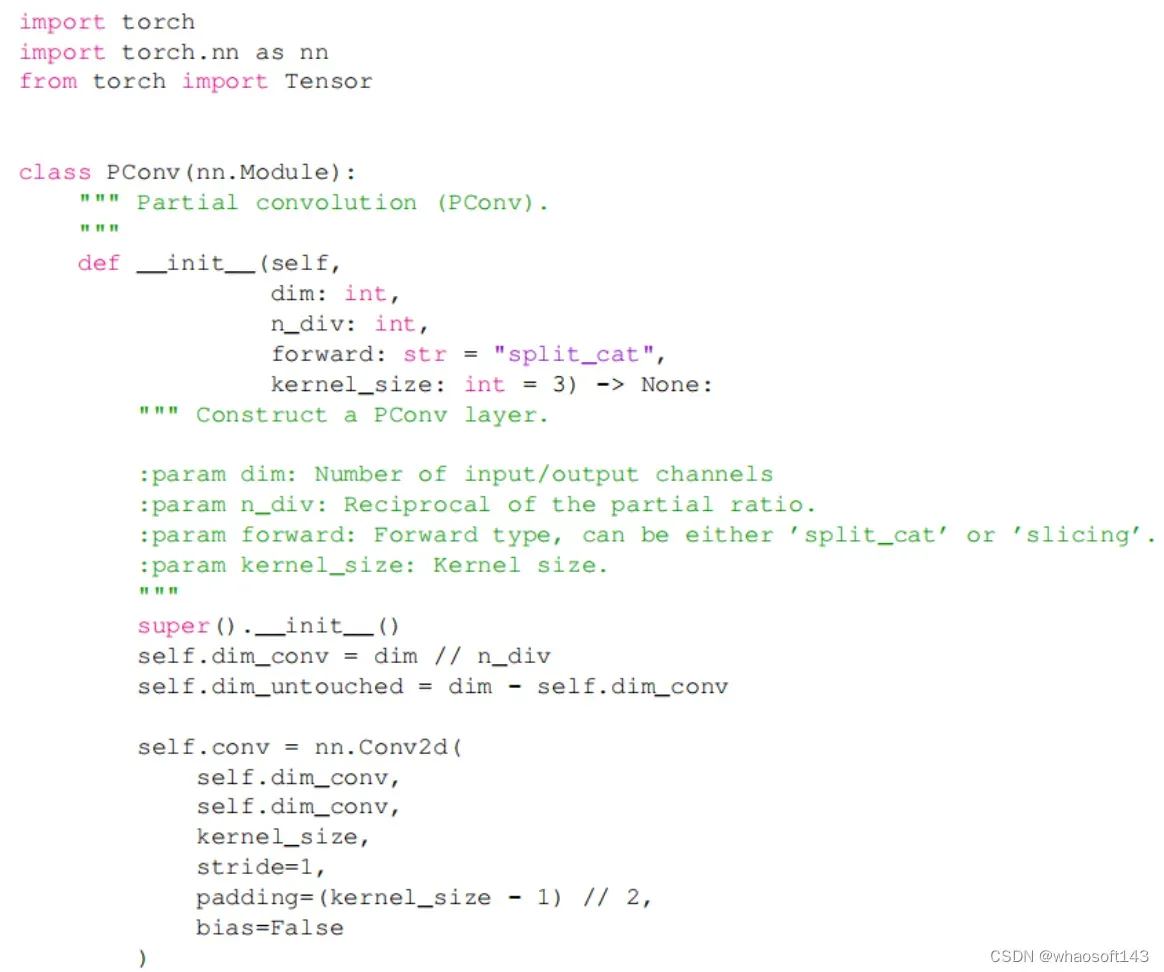
代码实现
 实验
实验
PConv的快速性与高Flops
PConv与PWConv一起有效
FasterNet on ImageNet-1k
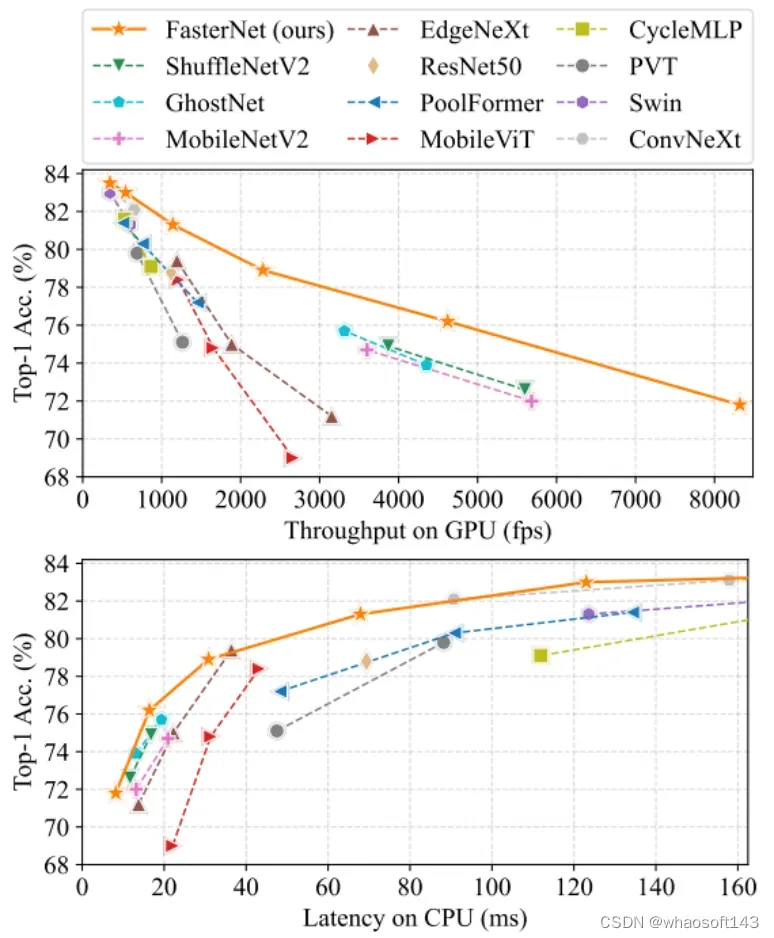
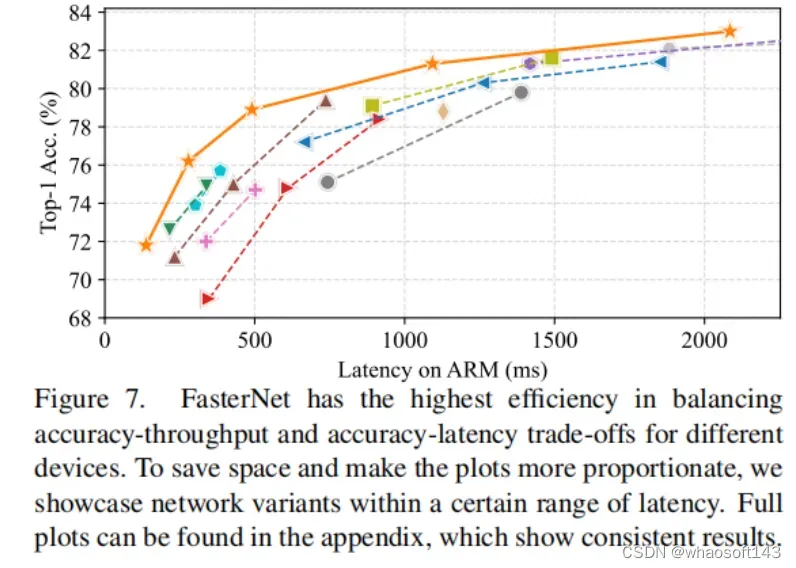 FasterNet在下游任务的表现
FasterNet在下游任务的表现
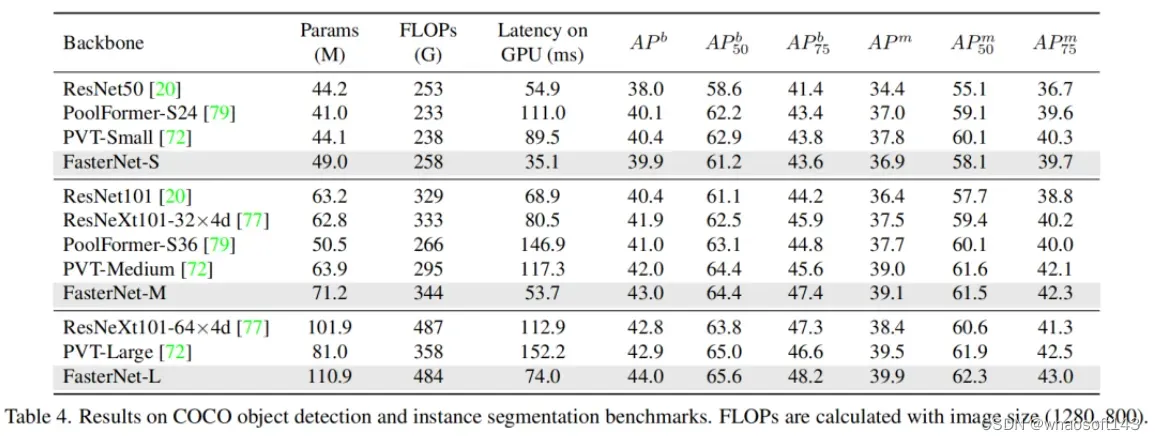
1、目标检测
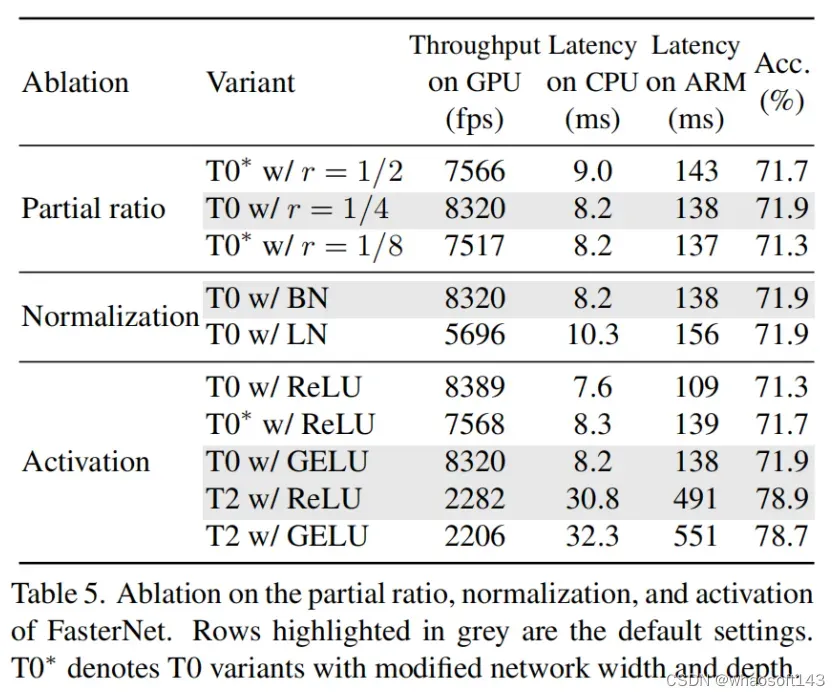
消融实验
whaosoft aiot http://143ai.com
文章出处登录后可见!