借鉴 https://blog.csdn.net/qq_40716944/article/details/128648001
一、准备训练环境
安装 requirements.txt
下载:https://raw.githubusercontent.com/ultralytics/ultralytics/main/requirements.txt
然后在你 目录下执行
pip install -r requirements.txt
它的 requirements 主要是以下 包,用下面代码检查下自己还缺哪些,补上就好。
pip show matplotlib
pip show numpy
pip show opencv-python
pip show Pillow
pip show PyYAML
pip show requests
pip show scipy
pip show torch
pip show torchvision
pip show tqdm
pip show tensorboard
pip show pandas
pip show seaborn
pip show psutil
pip show thop
pip show certifi
安装ultralytics
pip install ultralytics二、 准备自己的数据集
dataSet
images
label
xml
先 把 用labelImage 标注 完的图片和xml文件 分别放到 images 和 xml 文件夹里,运行 split_train_val.py,切分好数据。再运行 voc2yolo.py ,把数据集格式转换成yolo_txt格式。
也可以通过聚类获得先验框
utils下有 autoanchor.py文件,那么就可以采用自动获取anchors。yolov8好像可以自动调用来获取先验框了,参考这篇
三、模型训练
1、下载预训练模型
在YOLOv8的GitHub开源网址上下载对应版本的模型
2、训练
接下来就可以开始训练模型了,命令如下:
yolo task=detect mode=train model=yolov8n.yaml data=mydata.yaml epochs=100 batch=16以上参数解释如下:
task:选择任务类型,可选[‘detect’, ‘segment’, ‘classify’, ‘init’]
mode: 选择是训练、验证还是预测的任务蕾西 可选[‘train’, ‘val’, ‘predict’]
model: 选择yolov8不同的模型配置文件,可选yolov8s.yaml、yolov8m.yaml、yolov8l.yaml、yolov8x.yaml
data: 选择生成的数据集配置文件
epochs:指的就是训练过程中整个数据集将被迭代多少次,显卡不行你就调小点。
batch:一次看完多少张图片才进行权重更新,梯度下降的mini-batch,显卡不行你就调小点。
更多参数的含义以及怎么调参,参考这篇
训练过程:
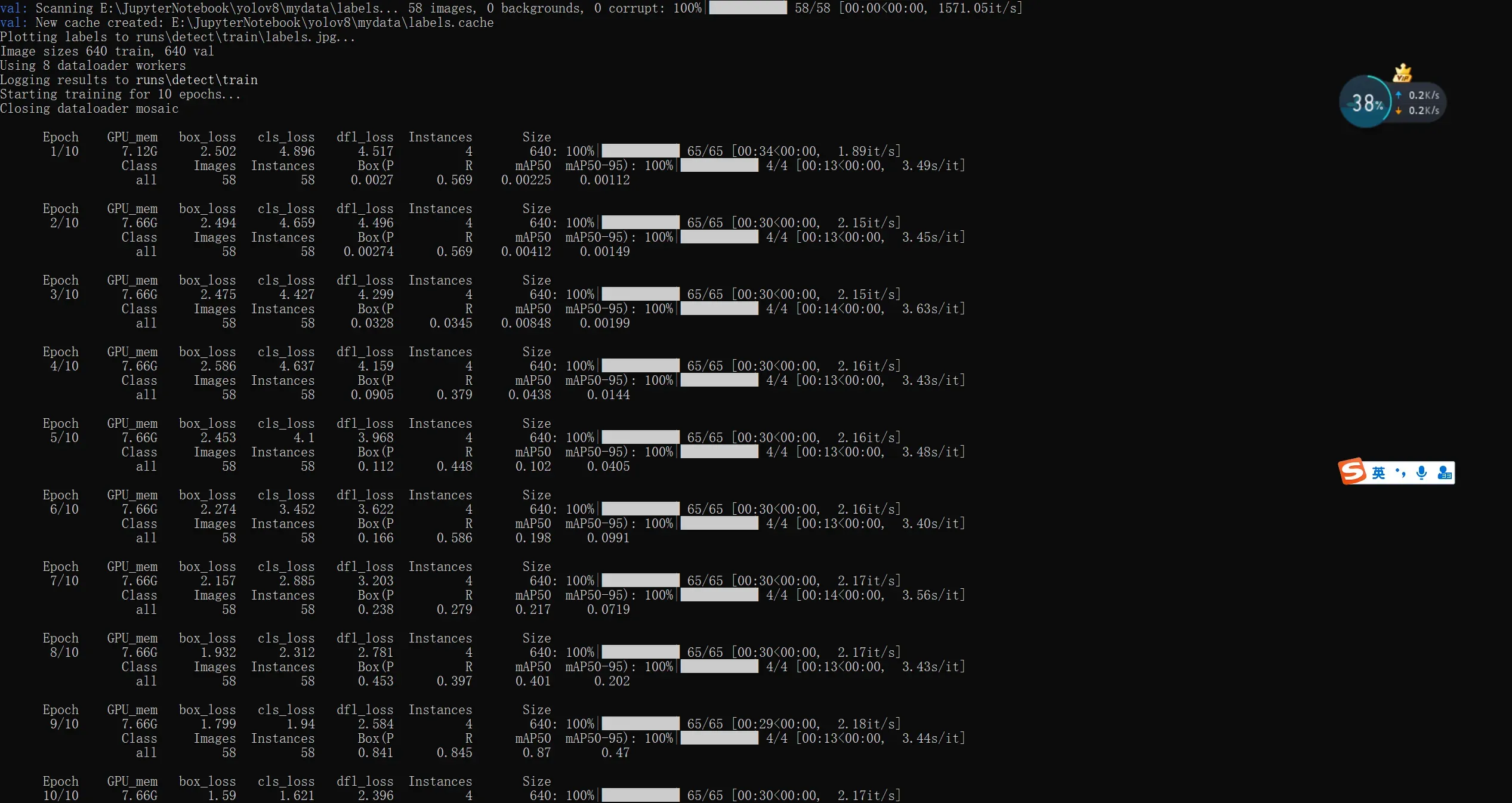
如果中途遇到 下载 Arial.ttf 文件的报错,是因为 训练时需要Arial.ttf字体,本地没有,但是下载网站有可能被 墙了,你只能下通过其他方法下载。
Downloading https://ultralytics.com/assets/Arial.ttf to C:\Users\Teddy\AppData\Roaming\Ultralytics\Arial.ttf…
解决方案:
点击这个Arial.ttf字体链接进行下载,然后上传到yolov5项目的根目录即可。
或者 它 提示的 :
C:\Users\Teddy\AppData\Roaming\Ultralytics\
训练完了之后,它的结果会保存在:
ultralytics\ultralytics\models\v8\runs\detect\
如果想断点续训:
大部分网上的教程目前只有以下这种,
yolo task=detect mode=train model=yolov8n.yaml data=mydata.yaml epochs=10 batch=8而没有如何断点续训的方法,当然可以参考 yolov5 的,我通过 查看 v8的 源代码,发现它命令的参数都在这个文件里。
.\ultralytics\ultralytics\yolo\cfg\default.yaml
注意里面有个参数 是 resume,将其设置为resume=True即可,
yolo task=detect mode=train model=yolov8n.yaml data=mydata.yaml epochs=3 batch=8 resume=True 博主运行后,便是接着上一次训练完10个epoch继续训练
model# 预训练模型或初始模型路径data# 上文 coco.yaml 的路径epochs# 迭代轮数batch# 根据显存调节device# 调用显卡数量,如:0,1,2,3workers# 调用 cpu 核心数)resume# 是否为断点续训,若是,则需把 model 路径改为上次保存的 best.pt 的路径3、训练过程的可视化
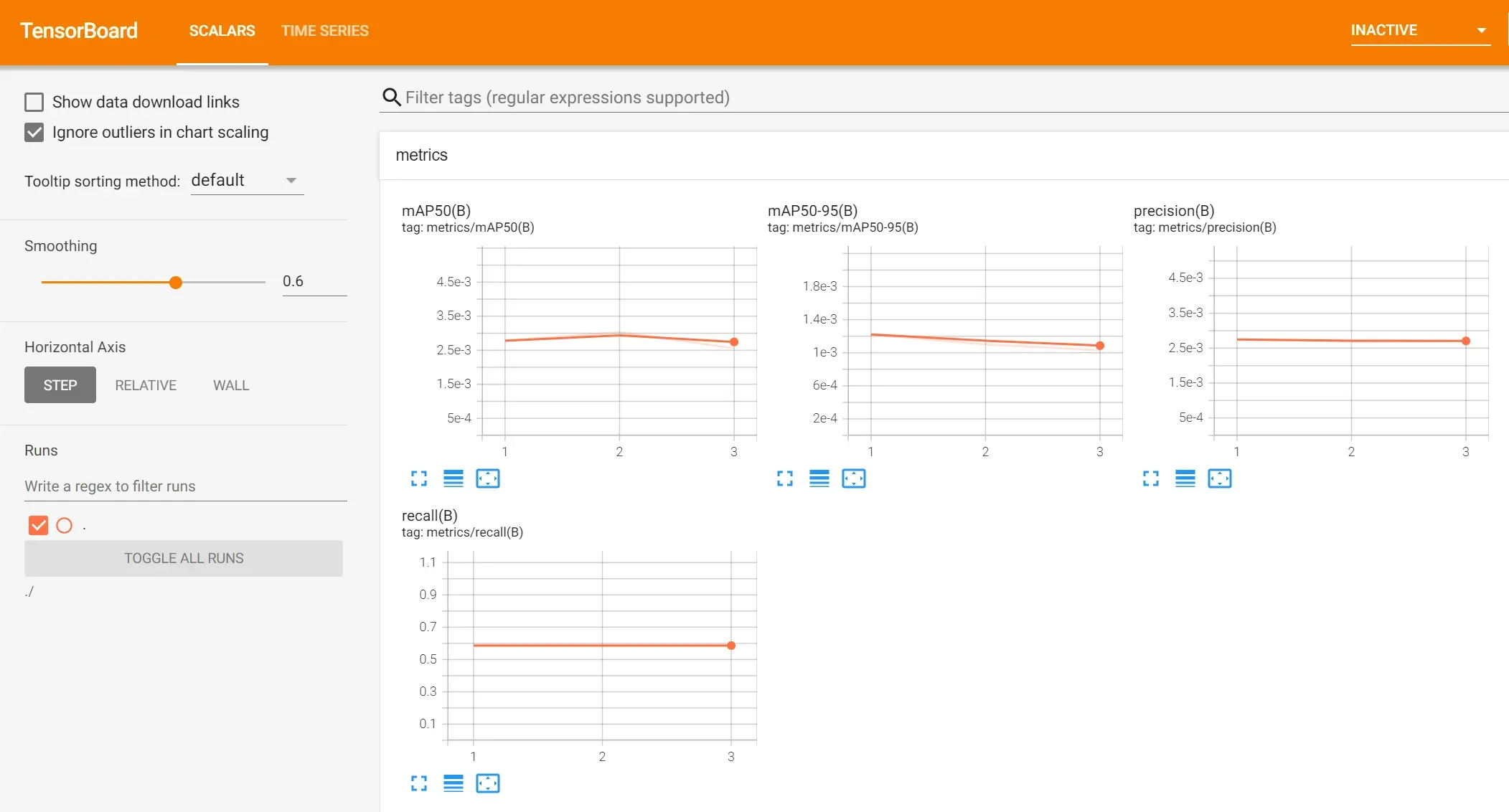
在训练过程的可视化tensorboard tensorboard –logdir ./ 然后打开localhost:6006即可,效果如下:
备注:
训练的一些参数解释
# Train settings -------------------------------------------------------------------------------------------------------
model: # 模型文件的路径,即yolov8n.pt, yolov8n.yaml
data: # 数据文件的路径,i.e. i.e. coco128.yaml
epochs: 100 # 训练的epoch数量
patience: 50 # 50个周期等待没有明显的改善,尽早停止训练
batch: 16 # number of images per batch (-1 for AutoBatch)
imgsz: 640 # #输入图像大小为整数或w,h
save: True #保存 checkpoints 并预测结果
save_period: -1 # 每x个epoch保存一次检查点 (disabled if < 1)
cache: False # True/ram, disk or False. 使用缓存进行数据加载
device: # 要运行的设备,即cuda Device =0或Device =0,1,2,3或Device =cpu
workers: 8 # 用于数据加载的工作线程数(如果是DDP,则为每个RANK)
project: # 项目名称
name: # 实验名称
exist_ok: False # 是否覆盖现有实验
pretrained: False # whether to use a pretrained model
optimizer: SGD # optimizer to use, choices=['SGD', 'Adam', 'AdamW', 'RMSProp']
verbose: True # whether to print 详细 output
seed: 0 # 随机种子的重现性
deterministic: True # 是否启用确定性模式
single_cls: False # 将多类数据训练为单个类
image_weights: False # 使用加权图像选择进行训练
rect: False # 如果模式为'train',则支持矩形训练;如果模式为'val',则支持矩形计算。
Mask_ratio: 4 #掩码下采样比(仅限段训练)
cos_lr: False # 使用余弦学习速率调度器
close_mosaic: 10 # 最后10个epoch 禁用 马赛克增强
resume: False # 从上一个检查点开始恢复培训
min_memory: False # 最小化内存占用损失函数,, choices=[False, True, <roll_out_thr>]
# Segmentation #分割
overlap_mask: True #掩码在训练过程中应该重叠(仅限训练段)
mask_ratio: 4 # #掩码下采样比(仅限段训练) (segment train only)
# Classification
dropout: 0.0 # 使用Dropout正则化(仅分类 train)4、多卡训练
多卡训练其实很简单,不需要使用繁琐的命令行指令,仅需把device=’0,1,2,3’即可,注意一定要加\和引号哦
yolo task=detect mode=val model=runs/detect/train3/weights/best.pt data=data/fall.yaml device=04、模型验证
使用如下命令,即可完成对验证数据的评估。
yolo task=detect mode=val model=runs/detect/train3/weights/best.pt data=data/fall.yaml device=05、模型测试
source需要指定为自己的图像路径,或者摄像头(0)。
yolo task=detect mode=predict model=runs/detect/train3/weights/best.pt source=data/images device=0
yolo task=detect mode=predict source=''...source: # source directory for images or videos
show: False # show results if possible
save_txt: False # save results as .txt file
save_conf: False # save results with confidence scores
save_crop: False # save cropped images with results
hide_labels: False # hide labels
hide_conf: False # hide confidence scores
vid_stride: 1 # video frame-rate stride
line_thickness: 3 # bounding box thickness (pixels)
visualize: False # visualize model features
augment: False # apply image augmentation to prediction sources
agnostic_nms: False # class-agnostic NMS
classes: # filter results by class, i.e. class=0, or class=[0,2,3]
retina_masks: False # use high-resolution segmentation masks
boxes: True # Show boxes in segmentation predictions主要填写:
source# 源文件路径,可以是图片或视频show# 是否展示图片或视频classes# 显示哪些类别,类别在上文的 coco.yaml 中列出例如:
yolo predict model=yolov8n.pt source="https://ultralytics.com/images/bus.jpg" show classes=0
这两个模型输出的结果保存在文件夹detect中
ultralytics\models\v8\runs\detect\train
视频测试
使用自己拍摄的一小段视频放入images文件夹中
在命令行中输入下面这行代码:
yolo task=detect mode=predict source=./data/images/IMG_7772.mp4然后在你命令行里会得到输出结果,以及保存的位置。
6、模型导出
使用如下命令,即可完成训练模型的导出。
yolo task=detect mode=export model=runs/detect/train3/weights/best.pt
7、模型格式转换
在export.py中,为了将pt文件转化成onnx,需要保证–include参数包括onnx,接着直接运行即可完成权重文件的格式转换。
8、使用yolov8n.onnx模型
推理代码参考https://blog.csdn.net/anny_jra/article/details/121950402,https://blog.csdn.net/qq_33934427/article/details/125252906 这两篇。
这里做了小改进,可以在不安装torch,torchvision情况下,使用numpy + onnxruntime-gpu,直接进行yolov5n.onnx模型的推理。
也可以转ncnn
ncnn 是一个为手机端极致优化的高性能神经网络前向计算框架。ncnn 从设计之初深刻考虑手机端的部署和使用。无第三方依赖,跨平台,手机端 cpu 的速度快于目前所有已知的开源框架。
怎么转,为了防止文章冗余,大家可以参考这篇
、电脑摄像头测试
使用本机摄像头测试Yolov8实时检测(),参考 这篇
yolo task=detect mode=predict source=0YOLOv8 也可以在 Python 中调用,详情可查看官方 Docs。
5 常见问题🌟
Q1:windows系统路径中不能出现中文,Linux可以出现
Q2:出现“页面太小,无法完成操作”
可能是虚拟内存不足,调大虚拟内存
Wiin系统可以尝试将线程 –workers设为0
Q3:memory error
内存超了,减小 –batch-size
文章出处登录后可见!