我的个人博客主页:如果’’真能转义1️⃣说1️⃣的博客主页
关于Python基本语法学习—->可以参考我的这篇博客:《我在VScode学Python》
随着人工智能技术的发展,挖掘和分析商业运用大数据已经成为一种推动应用,
推动社会发展起着重要作用,大数据分析已经成为一个快速发展的新型学科。
Python 在开发领域、数据采集与存储、数据预处理、数据分析、数据可视化、数据挖掘等技术,
在人工智能及大数据分析中,Python 以简洁、丰富的第三方库被广泛采用。
常用的Python 标准库
- Python 衍生的数据技术。
- 1.数据采集技术
- 2.数据预处理技术
- 3.数据存储技术
- 4.数据可视化:
- 其他:
Python 衍生的数据技术。
我们身处在一个大数据的时代。大数据作为一种数字资源,已经成为行业领域和社会发展的重要基础和驱动力。Python简洁、丰富的库资源推动了大数据处理技术快速发展,下面介绍 Python 衍生的数据技术。
1.数据采集技术
在互联网时代,数据采集面临着诸多文件的形式(文档、图片、音频、视频等非结构化数据。)以其数据量巨大、数据协议、传输、安全性等问题,且增加了爬虫处理获取网页数据的能力。
2.数据预处理技术
数据预处理常用的框架有Apache+Hadoop,Storm,Samza,Spark,Flink 等,可分为批处理、流处理、混合处理 3种模式,涉及MapReduce、HDFS、Stream 等技术。
在数据预处理前一般需要安装或导入所需的库文件。数据预处理的流程,一般包含数据集 1 导入、数据清洗(处理缺失的数据)、特征选择(编码分类数据),然后生成加工好的,计算好的,分组好的新数据。
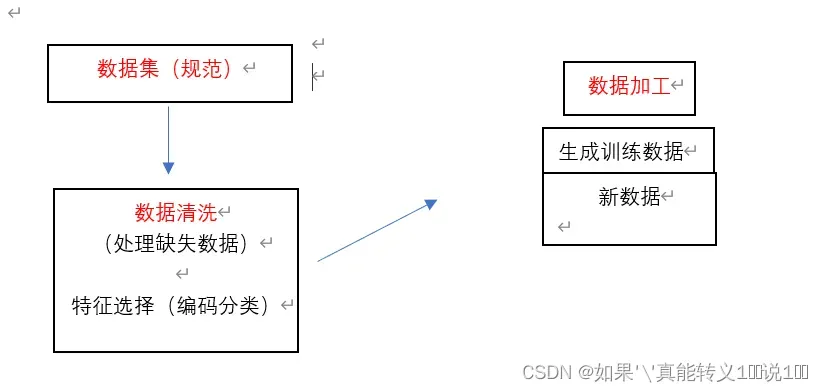
Python提供了一些预处理的库(Numpy,pandas、sklearn等等)使其标准化,归一化、二值化、标记编码、数据集拆分等等。
标准化:将数据转换为均值为0,标准差为1的数据。
当数据的特征具有不同的尺度时,标准化是有用的,以便在模型中给它们相同的重要性。
归一化:将数据缩放到固定范围内,通常在0到1之间。
当数据的分布不是高斯分布或者当您想要比较具有不同单位的特征时,归一化是有用的。
二值化:通过设置阈值将数值数据转换为二进制数据。
当您想要将连续特征转换为分类特征时,二值化是有用的。
标签编码:将分类数据转换为数字数据,为每个类别分配一个唯一的整数。
当模型需要数字输入时,标签编码是有用的。
数据集拆分:将数据拆分为训练集和测试集。
当您想要在未见过的数据上评估模型的性能时,数据集拆分是有用的。
3.数据存储技术
数据存储有多种方式,根据数据的规模和应用,可以采用文件存储、二进制存储、数套主储等。文件存储可分为 TXT 纯文本形式、CSV 格式Excel 格式、JSON 格式等:而在PY中常用的大数据库及表存储有 MongoDB、Redis、SQLite等。
在Python中,文本文件可使用 open()方法、read()方法、pickle 模块等进行读写,
还有pandas、xlrd、xlwt、os 等库也可实现文件的读写
4.数据可视化:
pygal,matplotlib 等等工具
其他:
数据集应用:经济,交通,医疗,生活质量中智能分析。
嵌入式: web、其他语言、智能控制。
数据挖掘:朴素贝叶斯算法,神经网络,决策树等方面。
将一类信息或数值称为“数据”,这些数据可以是数字、文本、图像、音频等形式【列表、元组、字典,也可以指来自数据库、文件、API等数据源】称为数据集。 ↩︎
文章出处登录后可见!