不得不说,最近的AI技术圈很火热,前面的风头大都是chatGPT的,自从前提Meta发布了可以分割一切的CV大模型之后,CV圈也热起来了,昨天只是初步了解了一下SAM,然后写了一篇基础介绍说明的博客,早上一大早起来已经有2k左右的阅读量了。
我果断跑去官方项目地址看下:
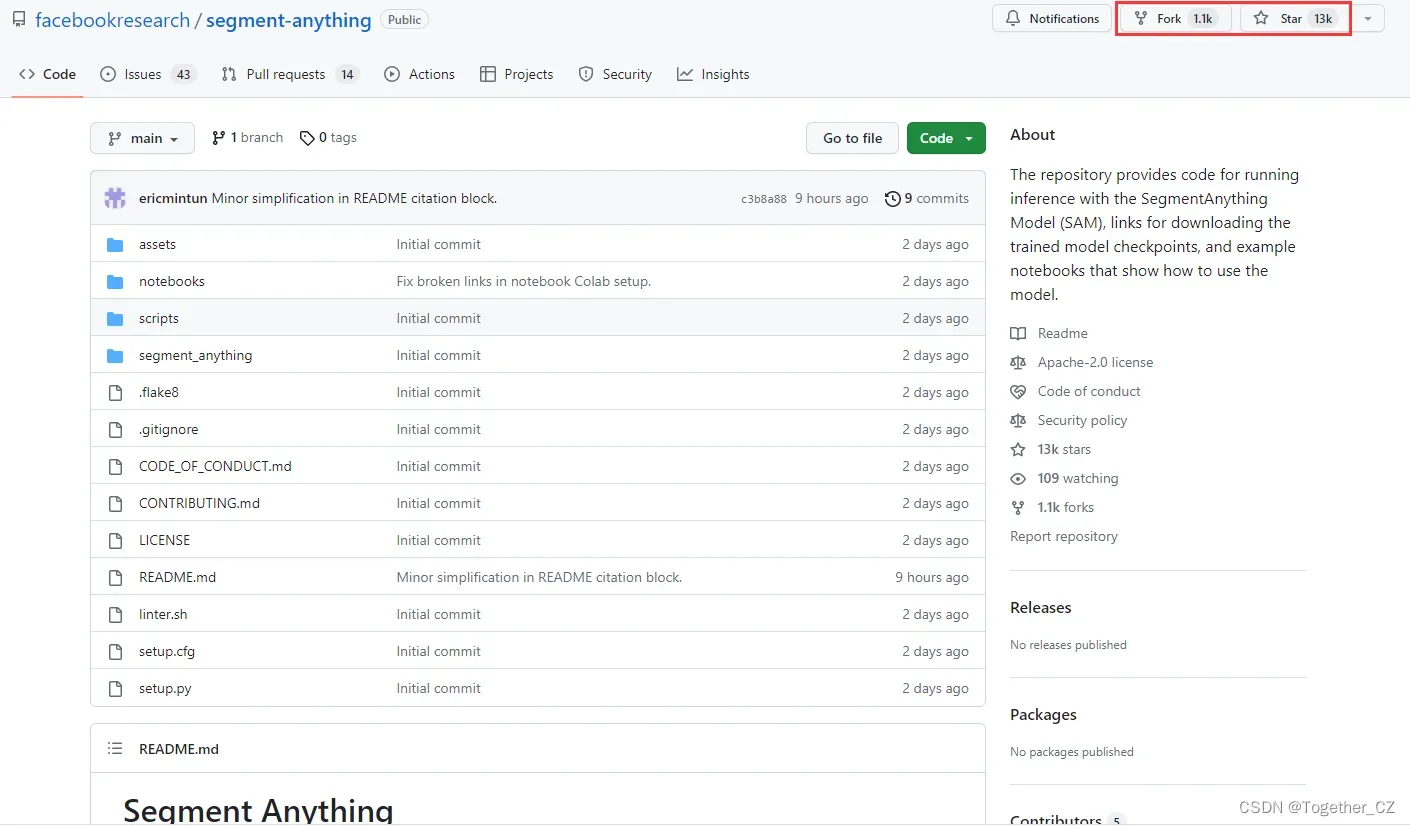
好恐怖的增长速度,昨天写博客的时候也不到6k,今天一早已经翻一倍,估计随着这波宣传推广后,会迎来更加恐怖的增长,说明大家对他还是满怀期待的。
今天主要是下载了官方的源码,想要自己实践使用一下预测提示输入这样的效果。
在官方的介绍中可以看到:
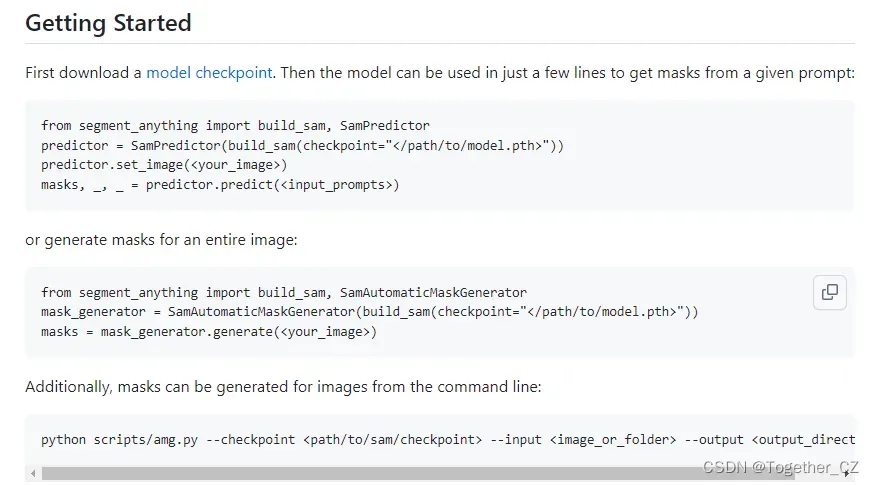
可以有两种使用当时,这里我先实践使用的是第一种的方式,我使用的测试图片也是官方源码附带的,如下:

这里可以下载三款模型,如下:
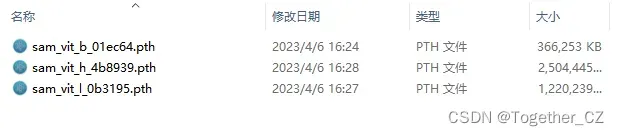
这里我遵从官方的指导,使用默认的H系列的模型也就是sam_vit_h_4b8939.pth
显示原图,如下:
image = cv2.imread('truck.jpg')
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
plt.figure(figsize=(10,10))
plt.imshow(image)
plt.axis('on')
plt.show()结果如下:

接下来可以加载所需要的模型权重,如下:
predictor = SamPredictor(build_sam(checkpoint="weights/sam_vit_h_4b8939.pth"))SAM预测对象掩码,给出预测所需对象的提示。该模型首先将图像转换为图像嵌入,该图像嵌入允许从提示有效地生成高质量的掩模。SamPredictor类为模型提供了一个简单的接口,用于提示模型。它允许用户首先使用set_image方法设置图像,该方法计算必要的图像嵌入。然后,可以通过预测方法提供提示,以根据这些提示有效地预测掩码。该模型可以将点提示和框提示以及上一次预测迭代中的掩码作为输入。
之后可以使用set_image喂入自己的图像数据,如下:
predictor.set_image(one_img)
masks, scores, logits = predictor.predict(
point_coords=input_point,
point_labels=input_label,
multimask_output=True,
)
print("masks.shape: ", masks.shape)运行输出如下所示:
masks.shape: (3, 1200, 1800)这是打印出来的掩码的size,我们接下来直观地展示出来掩码的效果:
图像中我加入了一片绿叶,用来标记自己加入的提示信息,这样更为明显一些
可以看到:一个点的标记提示,SAM分割出来了三种结果,最后一种是我们所需要的整车的分割,但是前面两种也是正确的,只是说是做的车窗的分割,那么如何能让SAM更加有效理解我们的实际意图呢?
安装官方的说法是可以加入多提示,在这里这个例子的话我们就可以再加入别的点就行,如下:
我额外标记了一点,“误导”模型,如下:

红色的小花我标记为不属于车身,模型最终分割的效果就是只有车窗了。
接下来,我将其标记改为属于目标对象,效果如下:

可以看到:这次模型只返回了一个结果,而且是我们自己想要的结果。
当然了,如果已经亲身体验过官方开源的Demo网站的话,应该就知道官方也提供了可以画Box指定区域实现分割,这里也是可以的。
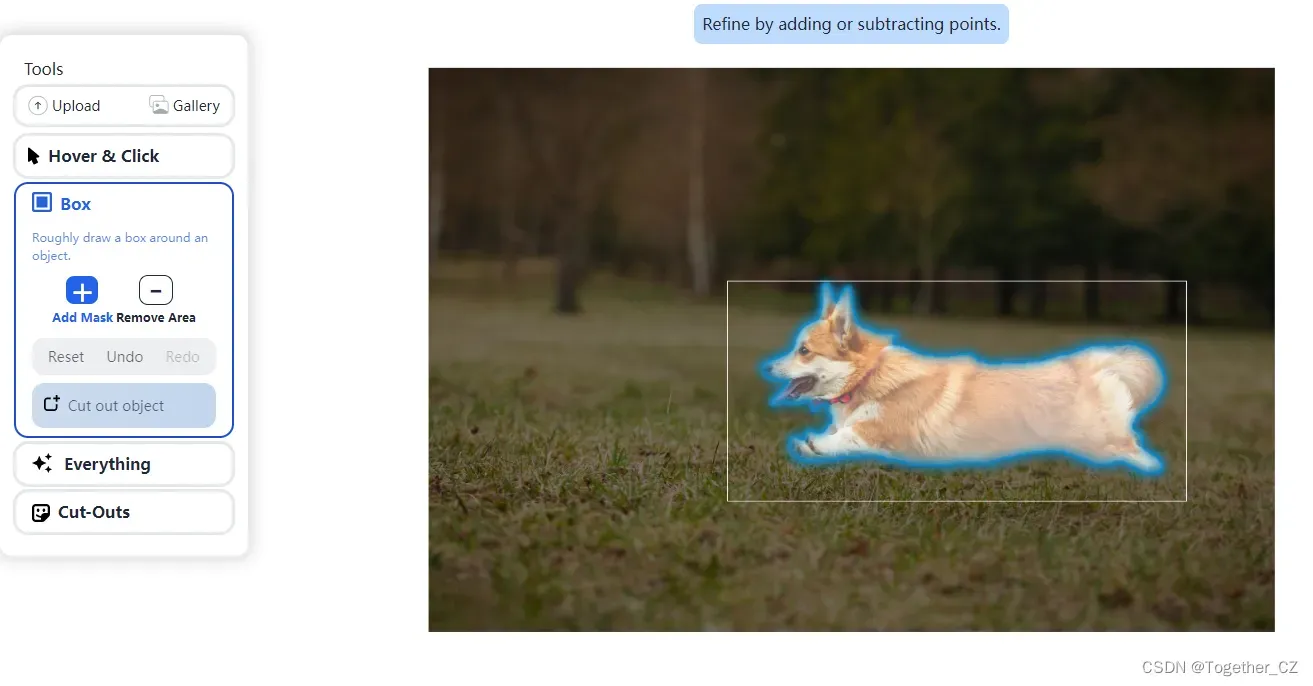
接下来来看实践代码,如下:
predictor.set_image(one_img)
input_box = np.array([425, 600, 700, 875])
masks, _, _ = predictor.predict(
point_coords=None,
point_labels=None,
box=input_box[None, :],
multimask_output=False,
)
plt.clf()
plt.figure(figsize=(20, 10))
plt.subplot(121)
plt.imshow(one_img)
plt.title("originalImage")
plt.subplot(122)
plt.imshow(one_img)
show_mask(masks[0], plt.gca())
show_box(input_box, plt.gca())
plt.axis('off')
plt.title("segmentImage")
plt.show()效果如下:

还是很不错的。
我这里之所以直接使用源码内置的数据,主要就是不想再麻烦去自己标注这些点或者是画框,本来就是为了演示实践功能的。
到此为止是不是觉得也就这样的,其实还有,单独提示输入点或者框都是可以完美分割的,那么同时输入点和框呢?答案是肯定也可以,官方的Demo已经证实了,如下:
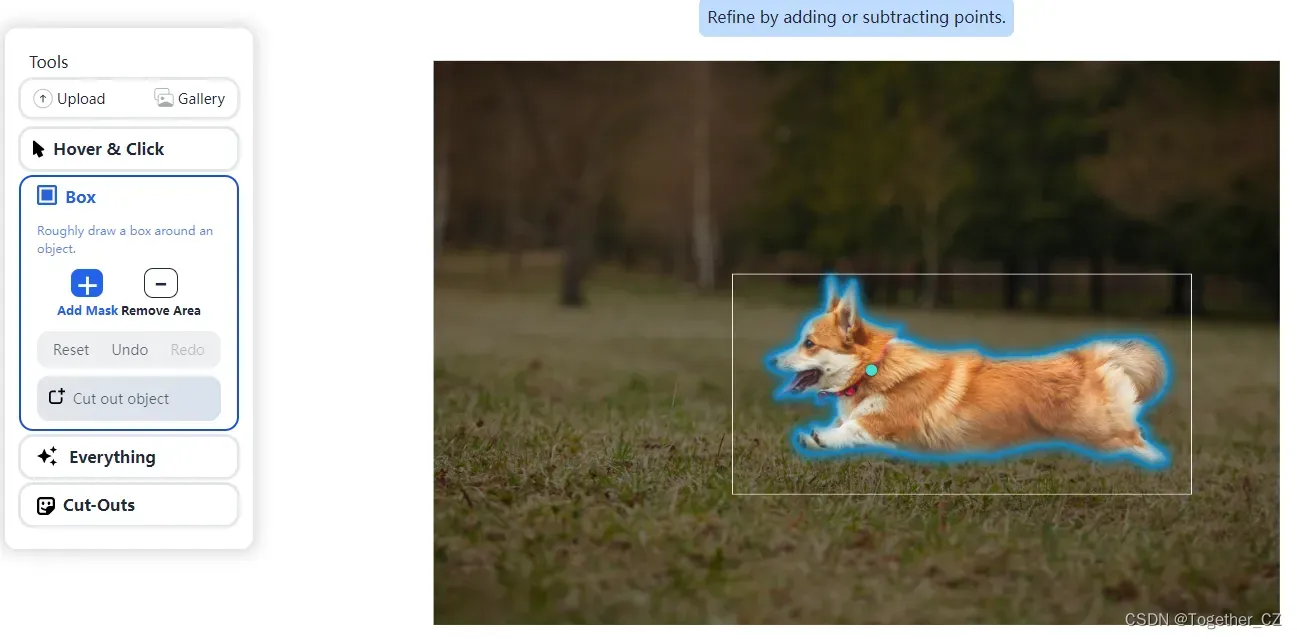
接下来就是看如何用代码实现了,如下:
#点+框分割
predictor.set_image(one_img)
masks, _, _ = predictor.predict(
point_coords=input_point,
point_labels=input_label,
box=input_box,
multimask_output=False,
)
plt.clf()
plt.figure(figsize=(20, 10))
plt.subplot(121)
plt.imshow(one_img)
plt.title("originalImage")
plt.subplot(122)
plt.imshow(one_img)
show_mask(masks[0], plt.gca())
show_box(input_box, plt.gca())
show_points(input_point, input_label, plt.gca())
plt.axis('off')
plt.title("segmentImage")
plt.show()效果如下所示:

因为标注了红色小花为北京区域,这里SAM直接分割出来的就是轮胎轮廓了,而不是整体了还是很不错的了。
点+框的组合都可以,那么如果想批量输入提示信息是否也是可以的呢?答案也是可以的,这里我们就看代码如何实现:
predictor.set_image(one_img)
input_box = np.array([425, 600, 700, 875])
transformed_boxes = predictor.transform.apply_boxes_torch(input_boxes, one_img.shape[:2])
masks, _, _ = predictor.predict_torch(
point_coords=None,
point_labels=None,
boxes=transformed_boxes,
multimask_output=False,
)
print("masks_shape: ", masks.shape)
plt.clf()
plt.figure(figsize=(20, 10))
plt.subplot(121)
plt.imshow(one_img)
plt.title("originalImage")
plt.subplot(122)
plt.imshow(one_img)
for mask in masks:
show_mask(mask.cpu().numpy(), plt.gca(), random_color=True)
for box in input_boxes:
show_box(box.cpu().numpy(), plt.gca())
plt.axis('off')
plt.title("segmentImage")
plt.show()
效果如下所示:

官方同样实现了更加高效简洁的端到端推理方式,如果所有提示都提前可用,则可以以端到端的方式直接运行SAM。这也允许对图像进行批处理。
图像和提示都作为PyTorch张量输入,这些张量已经转换为正确的帧。输入被打包为图像上的列表,每个元素都是一个dict,它采用以下键:
image:以CHW格式作为PyTorch张量的输入图像。
original_size:转换为SAM输入之前的图像大小,格式为(H,W)。
point_coords:点提示的批量坐标。
point_labels:点提示的批处理标签。
boxes:批量输入框。
mask_inputs:批量输入掩码。
如果没有提示,则可以排除该键。
输出是每个输入图像的结果列表,其中列表元素是具有以下键的字典:
掩码:预测的二进制掩码的批量火炬张量,即原始图像的大小。
iou_predictions:模型对每个遮罩的质量的预测。
low_res_logits:每个掩码的低分辨率logits,可以在以后的迭代中作为掩码输入传回模型。
代码实例如下:
image1 = image # truck.jpg
image1_boxes = torch.tensor([
[75, 275, 1725, 850],
[425, 600, 700, 875],
[1375, 550, 1650, 800],
[1240, 675, 1400, 750],
], device=device)
image2 = cv2.imread('truck.jpg')
image2 = cv2.cvtColor(image2, cv2.COLOR_BGR2RGB)
image2_boxes = torch.tensor([
[450, 170, 520, 350],
[350, 190, 450, 350],
[500, 170, 580, 350],
[580, 170, 640, 350],
], device=device)
from segment_anything.utils.transforms import ResizeLongestSide
resize_transform = ResizeLongestSide(sam.image_encoder.img_size)
batched_input = [
{
'image': prepare_image(image1, resize_transform, sam),
'boxes': resize_transform.apply_boxes_torch(image1_boxes, image1.shape[:2]),
'original_size': image1.shape[:2]
},
{
'image': prepare_image(image2, resize_transform, sam),
'boxes': resize_transform.apply_boxes_torch(image2_boxes, image2.shape[:2]),
'original_size': image2.shape[:2]
}
]
batched_output = sam(batched_input, multimask_output=False)
print(batched_output[0].keys())
fig, ax = plt.subplots(1, 2, figsize=(20, 20))
ax[0].imshow(image1)
for mask in batched_output[0]['masks']:
show_mask(mask.cpu().numpy(), ax[0], random_color=True)
for box in image1_boxes:
show_box(box.cpu().numpy(), ax[0])
ax[0].axis('off')
ax[1].imshow(image2)
for mask in batched_output[1]['masks']:
show_mask(mask.cpu().numpy(), ax[1], random_color=True)
for box in image2_boxes:
show_box(box.cpu().numpy(), ax[1])
ax[1].axis('off')
plt.tight_layout()
plt.show()结果如下:

花了基本上一早上把预测提示输入的实践走了一遍感觉还是可圈可点的,后面再继续研究吧。
文章出处登录后可见!