文章目录
1. 简明扼要
SAM(Segmentation Anything Model)废话少说,出色要点有:
⭐ 建立了迄今为止最大的分割数据集:Segment Anything 1-Billion(SA-1B),1100万张图像,超过10亿个掩码(比任何现有的分割数据集多400倍)
⭐ 和chatgpt的启发思想一样,模型可提示prompt
⭐ 建立了通用的,全自动的分割模型,零样本灵活转化新任务,新领域,结果甚至优于之前的监督结果
2. 分割效果




是!不!是!很!哇!塞!
3. 开始探索
如果整个能量都是激动热闹的,就没有能量被留下来进入思考—-我们来开始冷静探索⬇️
Segment Anything Model的核心愿景
减少对于特定任务的专业建模知识要求,减少训练计算需求,减少自己标注掩码的需求.也就是我不咋会,不咋标,不咋训(很环保♻️哈)就把目标分出来
Segment Anything Model已经实现的功能
⭐ SAM已经学会了物体的概念
⭐ 可以为图像或视频中的物体生成掩码,甚至是没遇见过的
⭐ 通用性很强,无论是水下照片还是细胞显微镜
通过官方给的demo,可以测试自己的图像,分为交互式分割和全自动分割0成本很方便,例如开头的微信图片,鼠标点击4️⃣次,就提取到了肿瘤区域❗
1.交互式分割
1️⃣登录,accept条款
2️⃣自定义图像分割点击Upload an image 
3️⃣直接在图像上点击想要分割的区域,会出现蓝色小点,代表前景,随着蓝色小点增多,分割的蓝色边缘越小越接近想分割的区域。
4️⃣也可以选择左侧remove area之后继续在图像上点击,会出现粉色小点(我爱粉色),代表背景,用来收缩图像边缘,结合蓝色和粉色小点,图像边缘进行加减法会接近目标区域。
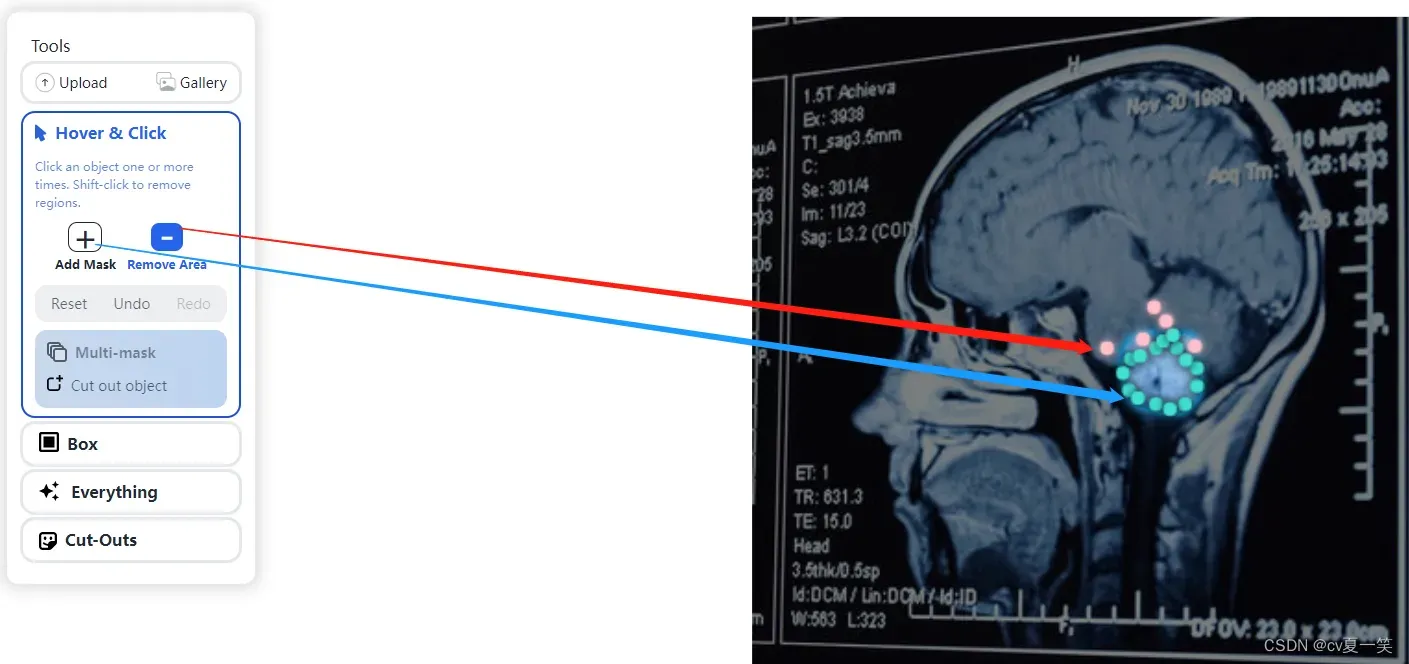
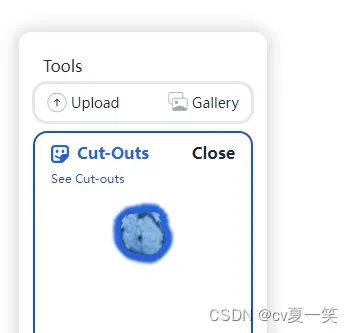
5️⃣差不多之后点Cut out object,就小功告成啦!
2.全自动分割
1️⃣登录,accept条款
2️⃣自定义图像分割点击Upload an image
3️⃣点击Everything 就完事啦
他先生成采样点,之后全自动分割,不需要任何点击啦
效果

可以看到房顶很多形状,一个是正方形,另一个也是😅。但是,但是,但是!有的被分割了,有的没有,真的太好了!模型还有进步的空间(我还有努力的时间😅)
在这里小小的插一嘴,AI取代人的问题,随着社会前进,必将更新,我在浪潮里面,没在浪潮之巅,我能做的仅仅是随机摸索方向,希望顺流而上,这种未知,使人兴奋。自古逢秋悲寂寥,我言秋日胜春朝。脱下孔乙己的长衫的前提是,先穿上。
Segment Anything Model官网
官方介绍SAM:
1️⃣ SAM允许用户只需点击一下就可以分割对象,或者通过交互式点击点来包括和排除对象。模型也可以用一个边界框来提示。
2️⃣ 当面临被分割的物体不明确时,SAM可以输出多个有效的掩码,这是解决现实世界中分割问题的重要和必要能力。
3️⃣SAM可以自动找到并屏蔽图像中的所有物体。
4️⃣SAM可以在预先计算图像嵌入后实时生成任何提示的分割掩码,允许与模型进行实时交互。
Segment Anything Model数据集
SAM使用数据集进行训练,标注着使用SAM交互式注释图像,反过来更新SAM。属实是闭环成长了。
有了SAM,收集新的分割掩码比以前更快
使用这种方法,通过模型辅助注释者,半自动半注释,模型全自动分割掩码这三个等级,造就了SAM数据集SA-1B达到1100万张图像,超过10亿个有效的高质量掩码, 比现有的分割数据集多400多倍,比COCO完全手动基于多边形的掩码注释快6.5倍。
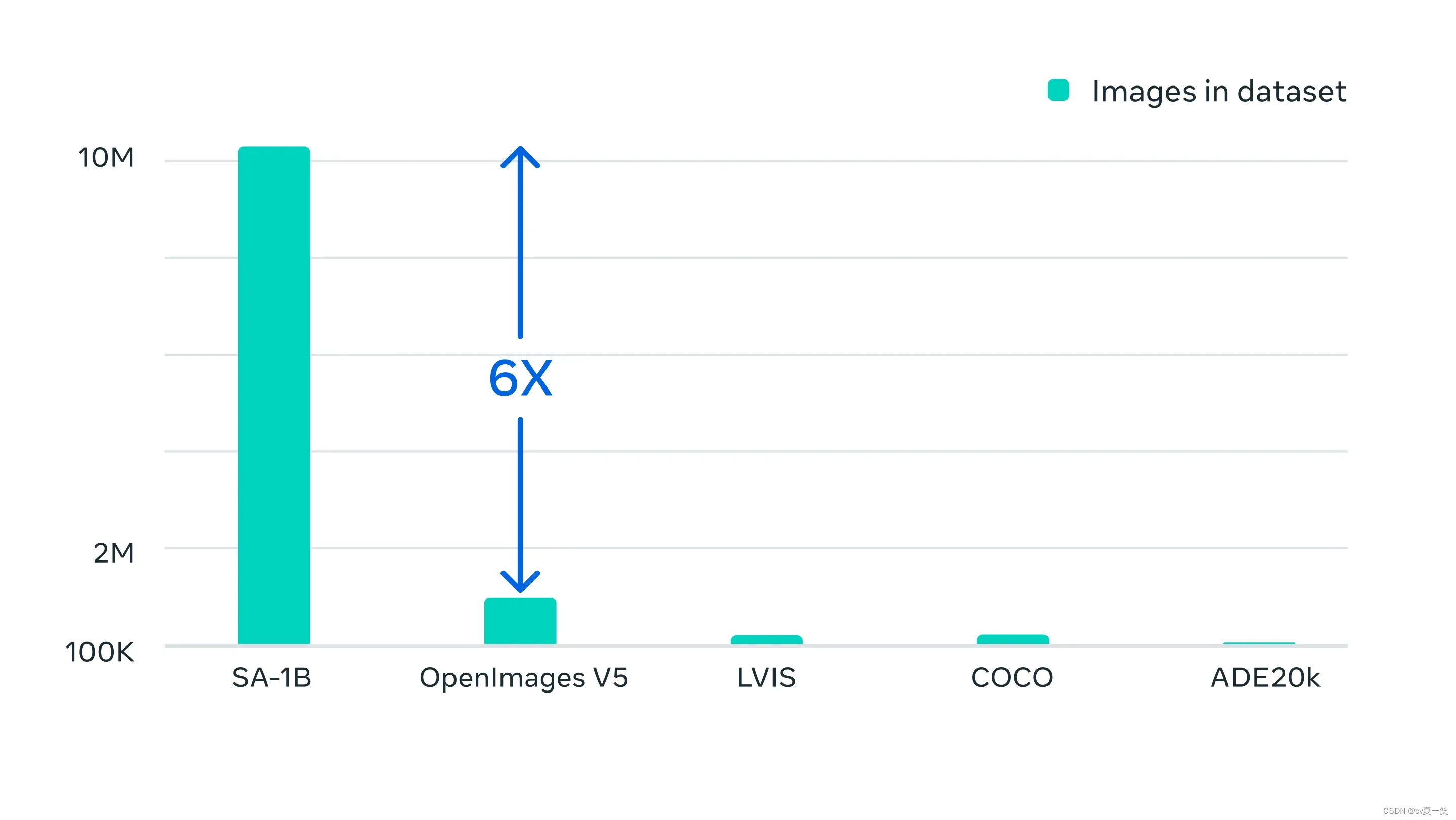
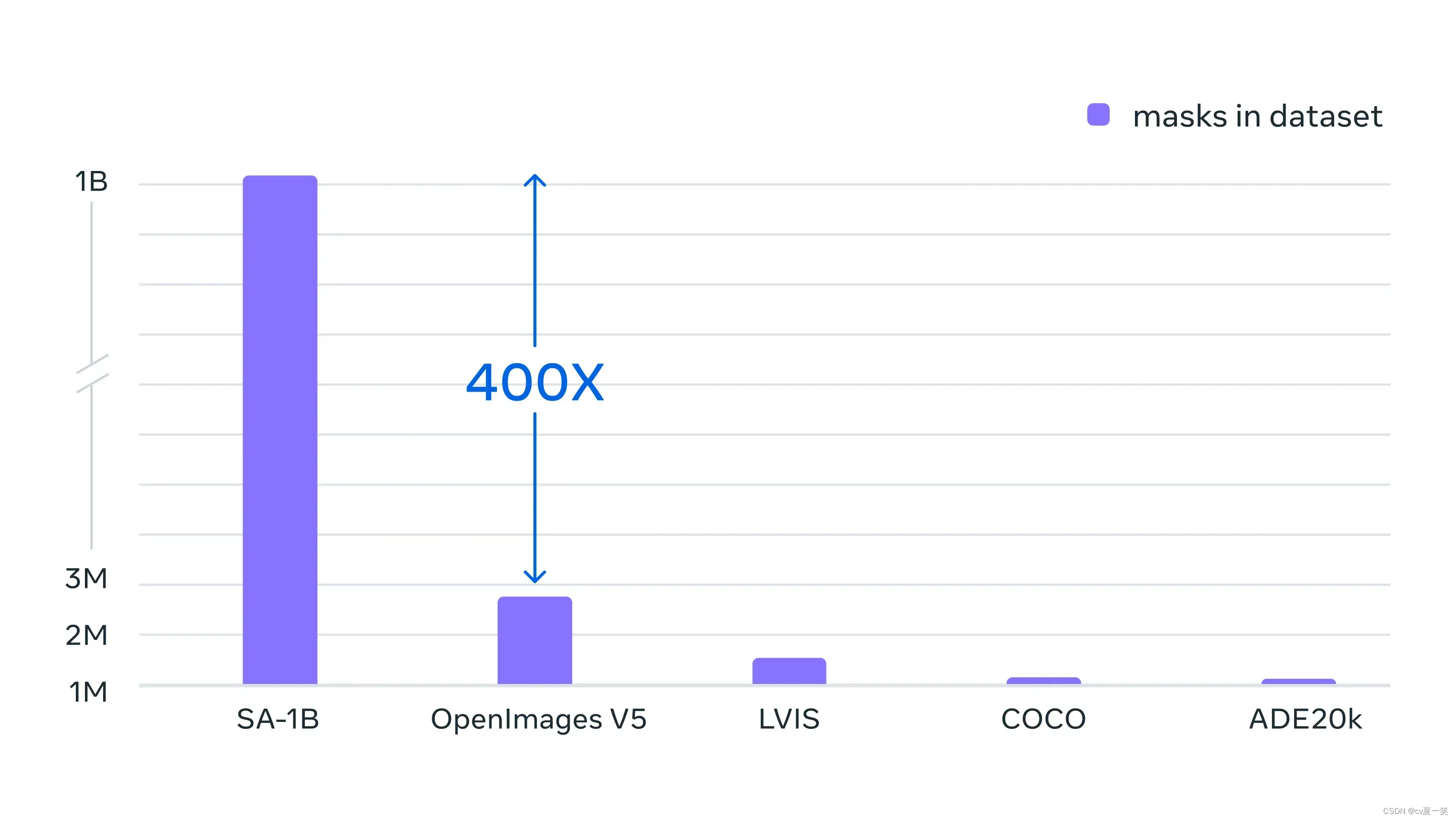
SA-1B数据集不仅能获取的更快 更多 更方便,也 更平均,来自不同国家地区🌏 不同收入🎫
分析模型在人们感知的性别表现、感知的肤色和感知的年龄范围方面的潜在偏差,发现SAM在不同群体中的表现相似
Segment Anything Model提示性分割
受到nlp领域的prompt思想,对新的数据集和任务进行零次和少数次学习,SAM可以使用前景/背景点、一个粗糙的盒子或掩码、自由形式的文本,或者,一般来说,任何指示图像中分割内容的信息,都可以当做SAM的prompt
过程:1.图像编码器为图像产生一个一次性嵌入向量 2.轻量级编码器将prompt实时转换为嵌入向量3.结合之后送入轻量级解码器中得到掩码
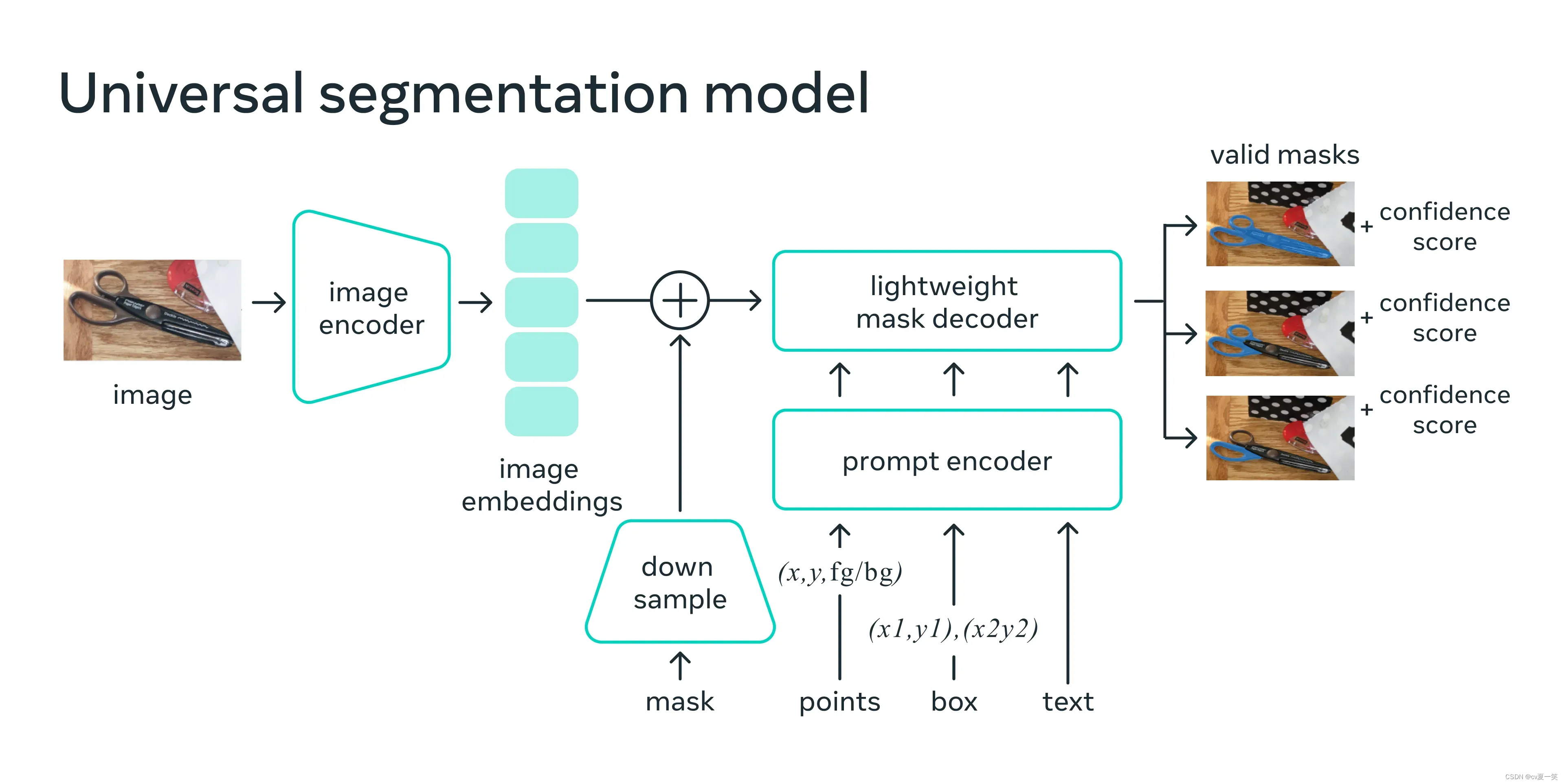
4.文章
5.未来可能
因为他是启发式模型,可以和用户互动
- 在AR/VR领域,SAM可以根据用户的目光来选择一个物体,将其提升到3D空间
- 在创作领域,提取图像区域进行拼贴或视频编辑
- 在研究领域,通过定位动物或物体来研究和跟踪视频
文章出处登录后可见!