视觉AIGC识别——人脸伪造检测、误差特征 + 不可见水印
- 前言
- 视觉AIGC识别
- 【误差特征】DIRE for Diffusion-Generated Image Detection
- 人脸伪造监测(Face Forgery Detection)
- 其他类型假图检测(Others types of Fake Image Detection)

前些天发现了一个人工智能学习网站,内容深入浅出、易于理解。如果对人工智能感兴趣,不妨点击查看。
前言
续篇:一文速览深度伪造检测(Detection of Deepfakes):未来技术的守门人
参考:https://mp.weixin.qq.com/s/inGjMdX9TTUa3hKWaMkd3A
视觉AIGC识别
根据已有的研究工作调研,将视觉AIGC识别粗略划分为:
- 人脸伪造检测(Face Forgery Detection):包含人脸的AIG图片/视频的检测,例如AI换脸、人脸操控等。此类方法主要关注带有人脸相关的检测方法,检测方法可能会涉及人脸信息的先验。
- AIG整图检测(AI Generated-images Detection):检测一整张图是否由AI生成,检测更加的泛化。这类方法相对更关注生成图与真实图更通用的底层区别,通常专注于整张图,比如近年爆火的SD、Midjounery的绘图;
- 其他类型假图检测(Others types of Fake Image Detection):此类方法更偏向于 局部伪造、综合伪造等一系列更复杂的图片造假,当然人脸伪造也属于局部、复杂,但是是人脸场景。将AIG图与真实图拼凑、合成的图片识别也属于这一类。
这三种类型之间划分并不明晰,很多方法同时具有多种检测能力,可划分为多种类型。严格意义上说AIG整图和其他造假图检测类型可能都会包含人脸信息,但三种类型方法往往技术出发点也不同。
【误差特征】DIRE for Diffusion-Generated Image Detection
Arxiv 2023
方法
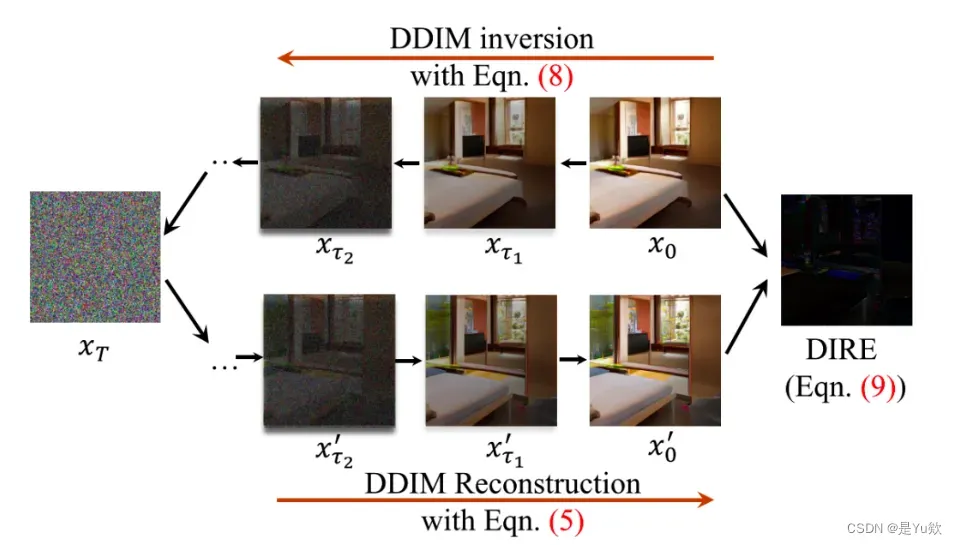
作者发现DM 图可以被近似地被扩散模型重建,但真实图片不行。将重建图和原图的图片差异记为扩散重建差(DIffusion Reconstruction Error,DIRE),则DIRE可以作为特征进行2分类训练,判断是否虚假,泛化性会高很多;
扩散模型的角色
扩散模型在这里充当了一种“数字时间机器”的角色,通过将图像“倒带”回过去的某个状态,然后再“快进”到现在,来重建图像。对于合成图像而言,这种“时间旅行”的过程中丢失的信息较少,因为它们本身就是由类似的深度学习模型生成的,因此它们与扩散模型重建的版本更为接近。相反,真实图像在这一过程中会丢失更多的细节,因为它们包含了更复杂和多样的信息,这些信息在通过扩散模型的“滤镜”时难以保留。
DIRE作为检测指标
将DIRE视作一种“指纹差异仪”,它可以测量一个图像经过时间机器旅行前后的变化量。对于合成图像,这种变化相对较小,因为它们本质上已经是“时间旅行”的产物。对于真实图像,变化较大,因为时间旅行过程中它们失去了更多的原始信息。
重建图像差DIRE可以区分真实图和合成图的原因如下图:
- 合成图在重建后变化往往较小;
- 真实图在重建后变化相对较大;
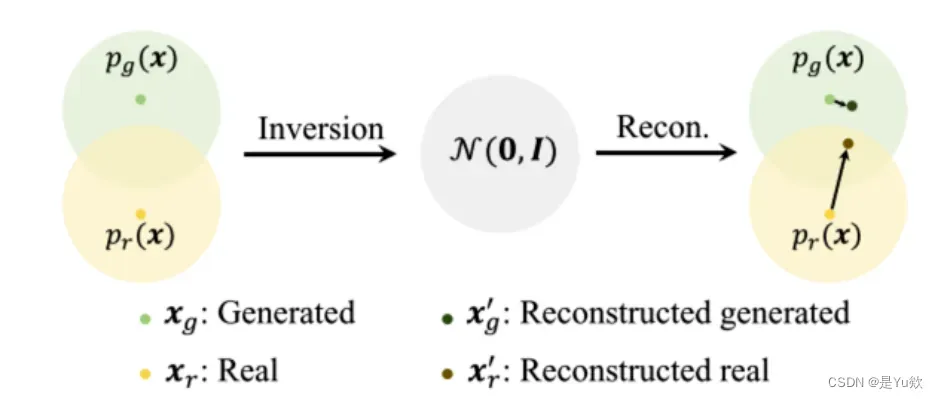
我的理解是,真实图在重建时会丢失很多信息,而生成图由于本身就是模型生成的,重建时信息变化相对不大。因此差异可以反映其真假。
该方法通过预训练的扩散模型(Denoising Diffusion Implicit Models,DDIMs[7])对图片进程重建,测量输入图像与重建图像之间的误差。其实这个方法和梯度特征的方法LGrad很像,区别在于上面是通过 Transformation Model转换模型获得图像梯度,这里通过 DDIM 重建图计算差。
实验结果
此外,作者提出了一个数据集 DiffusionForensics,同时复现了8个扩散模型对提出方法进行识别(ADM、DDPM、iDDPM, PNDM, LDM, SD-v1, SD-v2, VQ-Diffusion);
- 跨模型泛化较好:比如ADM的DIRE 对 StyleGAN 也支持,
- 跨数据集泛化:LSUN-B训练模型在ImageNet上也很好;
- 抗扰动较好:对JPEG压缩 和 高斯模糊的图,性能很好;
最后看下实验指标,看起来在扩散模型上效果很好,这ACC/AP都挺高的,不知道在GAN图上效果如何。
实验结果显示,这种基于扩散重建差的方法在区分真实与合成图像上表现出色,这就像是在深度伪造的海洋中拥有了一张精确的导航图。这种方法在不同的扩散模型上都展现了高度的准确性,这表明了它作为一种检测工具的潜力。
总的来说,这篇研究为深度伪造检测领域提供了一个新的视角和工具,其通过利用扩散模型的独特能力,提出了一个既直观又有效的方法来区分真实与合成图像。这种方法的成功展示了深度学习领域中“以毒攻毒”的潜力,即使用生成技术的原理来反击深度伪造的问题。
泛化能力和抗扰动
这一方法之所以具有较好的跨模型和跨数据集泛化能力,可以类比于一种“通用翻译器”,它不仅能理解不同语言(即由不同模型生成的图像)之间的差异,还能在不同的环境(即不同的数据集)中有效工作。此外,其良好的抗扰动性能表明,这种方法像是具有一种“稳定的免疫系统”,能够在面对图像质量下降(如JPEG压缩)或视觉干扰(如高斯模糊)时,依然保持高效的检测能力。
人脸伪造监测(Face Forgery Detection)
人脸伪造图生成
人脸伪装图根据身份信息是否更改划分为身份信息不变类和身份替换类。
身份不变类伪造图在图片修改/生成时不修改图片中人物的身份信息,包括:
- 人脸编辑:编辑人脸的外部属性,如年龄、性别或种族等。
- 人脸再制定:保留源主体的身份,但操纵其口部或表情等固有属性;
https://github.com/harlanhong/awesome-talking-head-generation
https://github.com/Rudrabha/Wav2Lip - 身份替换类伪造图在图片修改时同时改变其中人的身份信息:
- 人脸转移:它将源脸部的身份感知和身份不相关的内容(例如表情和姿势)转移到目标脸部,换脸也换表情等等,相当于把自己脸贴在别人的头上;
- 换脸:它将源脸部的身份信息转移到目标脸部,同时保留身份不相关的内容。即换脸,但不换表情,自己的脸在别人脸上做不变的事情;
- 人脸堆叠操作(FSM):指一些方法的集合,其中部分方法将目标图的身份和属性转移到源图上,而其他方法则在转移身份后修改交换后图的属性,多种方法的复合;
其他类型假图检测(Others types of Fake Image Detection)
- 社交媒体中发的篡改图:Robust Image Forgery Detection Against Transmission Over Online Social Networks, CVPR 2022: Paper Github
- 通用图片造假检测(局部造假等):Hierarchical Fine-Grained Image Forgery Detection and Localization, CVPR 2023: Paper Github
版权声明:本文为博主作者:是Yu欸原创文章,版权归属原作者,如果侵权,请联系我们删除!
原文链接:https://blog.csdn.net/wtyuong/article/details/136387976