论文地址:http://openaccess.thecvf.com/content_cvpr_2017/papers/Su_Deep_Video_Deblurring_CVPR_2017_paper.pdf
代码地址:https://github.com/shuochsu/DeepVideoDeblurring
Abstract
由于相机抖动引起的运动模糊是手持设备捕捉到的视频中存在的一个主要问题。然而,视频去模糊与单图像去模糊不同,基于视频的方法可以利用相邻帧中存在的丰富信息。因此,性能最好的方法依赖于附近帧的对齐。然而,图像对齐需要很高的计算成本。本文中引入一个视频去模糊的深度学习解决方案,其中CNN被训练去学习如何跨帧积累信息。为了训练这个网络,我们收集了一个用高帧率摄像机记录的真实视频的数据集,我们使用它来生成合成运动模糊以进行监督。
1. Introduction
最成功的视频去模糊方法利用来自相邻帧的信息来将模糊帧变清晰,即利用了大多数hand-shake运动模糊短且与时间不相关的性质。通过借用附近帧中的“清晰”像素,就有可能重建一个高质量的输出。
跨多个视频帧聚合信息的主要挑战之一是,不同的模糊帧必须对齐。可以使用[1,2]的方法来进行帧对齐操作。warping-based对齐方法在around disocclusions、areas with low texture、often yields warping artifacts方面鲁棒性不强。因此,我们提出了一个端到端的视频去模糊方法。我们主要是处理由于手持相机抖动而产生的模糊,即时间上不相关的,但是该方法也可以延伸到其他类型的模糊,包括物体运动的运动模糊。我们根据不同的对齐类型实验了许多不同的学习配置:1)no-alignment;2)frame-wise homography alignment;3)optical flow alignment。我们的方法还可以在不计算任何对齐或image warping的情况下生成高质量的结果,这使得它对于很多场景有着高效的性和鲁棒性。成功的关键是使用了一个具有跳跃连接的自编码器网络,增大了感受野,而且很容易训练。
本文的主要贡献是在给定模糊视频的相邻帧上训练端到端深度神经网络,以学习如何对图像进行去模糊以及我们从高帧率捕获中创建真实数据集的方法。
2.Method
图像对齐本身就具有挑战性,因为很难确定对齐的像素是否对应于不同图像中的相同场景内容。另一方面,高级特征提供了足够的额外信息来帮助将错误对齐的图像区域与正确对齐的图像区域区分开来(不太好理解)。为了同时利用低级和高级特征,我们训练了一个端到端的视频去模糊网络,其中输入是一些相邻帧,输出是这些相邻帧之间的中间帧的去模糊结果。
2.1.Network Architecture
我们使用了一个编码器-解码器网络,该网络在许多任务中可以产生很好的结果。在编码器与解码器这两部分中使用了全卷积模型,并在相应层之间增加了跳跃连接(如图1所示)。这显著地加速了收敛,并有助于生成更清晰地视频帧。我们通过将输入层中的所有图像连接起来(将相邻帧进行融合),这类似于FlowNetSimple模型[3]。文章中使用MSE作为损失函数。我们将这个网络称为DeBlurNet或DBN。网络中由三种类型地卷积层组成:1)down-convolutional layers(下采样层);2)flat-convolutional layers(增加非线性映射保持并保持图像大小);3)up-convolutional layers(上采样层)。(其中具体参数看表1)
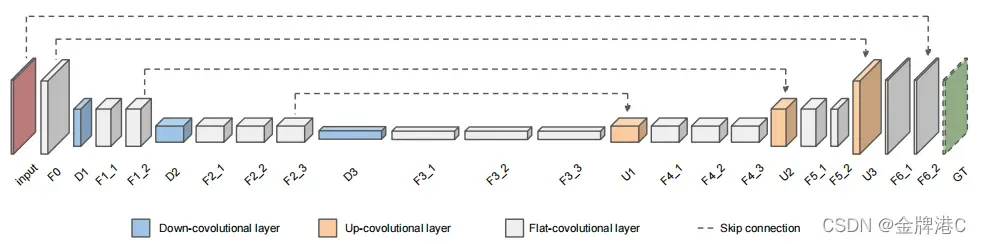
图1:网络结构
表1:网络具体细节
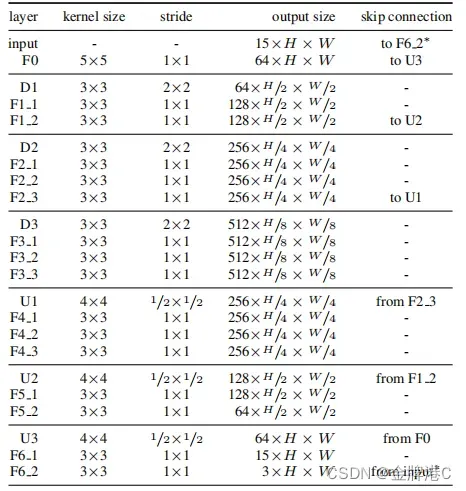
2.2. Alignment
我们的方法地一个主要优点之一是能够在没有精确的帧到帧对齐的情况下正常工作。因此,我们创建了三个具有不同程度对齐的数据集版本,并使用它们来训练DBN。第一种情况,我们根本不使用对齐,依赖于网络通过一系列的下采样来抽象空间信息。这样使得该方法速度快,因为在多帧聚合方法中,对齐操作通常主导运行时间。第二种情况,使用光流对齐的方法,它计算速度慢,而且还可能会产生伪影,但是它可以更容易地聚合像素。第三种情况,使用了一种single global homography对齐方法,它是在计算复杂度和对齐质量方面的一种折中的方法。
3.Experiments and Results
表2:实验结果




4. Conclusion
提出了一种基于学习的视频去模糊方法,无需参数调整,也无需明确需要具有挑战性的图像对齐。方法是利用帧之间的关系进行去模糊。由于所需的对齐质量相对宽松,因此它也非常有效。
当输入帧不是很模糊时网络表现良好,但当输入帧包含严重模糊时表现不佳。
References
[1] Cho S, Wang J, Lee S. Video deblurring for hand-held cameras using patch-based synthesis[J]. ACM Transactions on Graphics (TOG), 2012, 31(4): 1-9.
[2] Delbracio M, Sapiro G. Hand-held video deblurring via efficient fourier aggregation[J]. IEEE Transactions on Computational Imaging, 2015, 1(4): 270-283.
[3] Dosovitskiy A, Fischer P, Ilg E, et al. Flownet: Learning optical flow with convolutional networks[C]//Proceedings of the IEEE international conference on computer vision. 2015: 2758-2766.
文章出处登录后可见!