初入菜鸟,希望能通过做笔记的方式记录下自己学到的东西,也希望能对同样入门的人有所帮助。希望大佬们帮忙指正错误~侵权立即删除。
内容
一、图像分割的介绍与分类
二、图像分割的基本结构
1、编码器
2、解码器
三、图像分割 Vs 图像分类
四、基础网络框架——FCN
五、U-Net
六、SegNet
七、金字塔场景分析网络——PSPNet
八、deeplab-v3系列
一、图像分割的介绍与分类
🌳 图像分割:将图像分成几个具有独特属性的特定区域,并提出感兴趣的对象。简单来说就是对图像中的物体进行分割
🌳 常用方法:基于阈值的分割方法;基于区域的分割方法;基于边缘的分割方法;基于具体理论的分割方法等(本文只介绍神经网络实现的图像分割方法)
🌳 图像分割的类型:语义分割和实例分割
- 语义分割:所有相同类型的对象都用一个类标签进行标记
- 实例分割:相似的对象也使用自己的标签,即不同的个体使用不同的标签
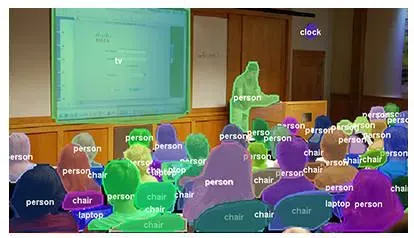
具体示例如下:(图片来源于网络,如有侵权,将立即删除)
左图是语义分割(人都是红色的),右图是实例分割(不同的人有不同的颜色)

二、图像分割的基本结构
1、编码器
通过过滤器从图像中提取特征(这里替换为各种熟悉的特征提取网络)
2、解码器
生成最终输出,通常是包含对象轮廓的分割掩码
三、图像分割 Vs 图像分类
图像分类在图像级别,而图像分割在像素级别
图像分类只需要对那些抽象特征进行分类,而图像分割则需要确定图像每个像素的类别才能进行准确的分割
图像分类一般使用CNN为基础框架进行分类,图像分割一般使用FCN作为分割的基础框架
原因:
(1)CNN在进行卷积和池化过程中丢失了图像细节,即feature map size渐渐减小,因此不能很好指出物体的具体轮廓,指出每个像素具体属于哪个物体,从而无法做到精确的分割。
(2)一般CNN分类网络都会在最后加入一些全连接层,经过softmax后就可以获得类别概率。但是这个概率是一维的,就是说只能标识整个图片(或整个网格内对象)的类别,不能标识每个像素点的类别,所以全连接方法并不适用于图像分割
四、基础网络框架——FCN
详见往期博文全卷积网络FCN详解_tt丫的博客-CSDN博客
五、U-Net
U-Net和FCN都是很小的分割网络,既没有使用空洞卷积,也没有后接CRF,结构比较简单。
U-Net最初是为分割生物医学图像而开发的。当它被可视化的时候,它的架构看起来像字母U,所以被命名为U-Net。
详见往期博文U-Net详解_tt丫的博客-CSDN博客
六、SegNet
SegNet是为了解决自动驾驶或者智能机器人问题而提出的图像语义分割深度网络。SegNet基于FCN,也属于Encoder-Decoder 结构。
🌳Encoder network使用的是经过修改的VGG16中的前13层卷积网络结构
🌳Decoder network还是和之前两个网络一样:将原图像经由Encoder network计算出的feature maps映射到和原图尺寸一致的分辨率以便于做逐像素的分类处理。
🌳创新点:Pooling Indices方式来保存池化点的来源信息,供Decoder network使用
Pooling Indices:在Encoder的池化层处理中,会记录每一个池化后的1×1特征点来源于之前的2×2的哪个区域
因为SegNet是一个对称网络,那么在Decoder中需要对特征图进行上采样的时候,我们就可以利用它对应的池化层的Pooling Indices来确定某个1×1特征点应该放到上采样后的2×2区域中的哪个位置,这也让它的计算量变大了些。
七、金字塔场景分析网络——PSPNet
🌳 说出理由
为了解决场景解析错误的问题,比如水上的船被预测为汽车,但一般汽车不会浮在水面上,所以表示目标所在场景的信息识别时没有好好考虑,只关注目标本身的外观信息。
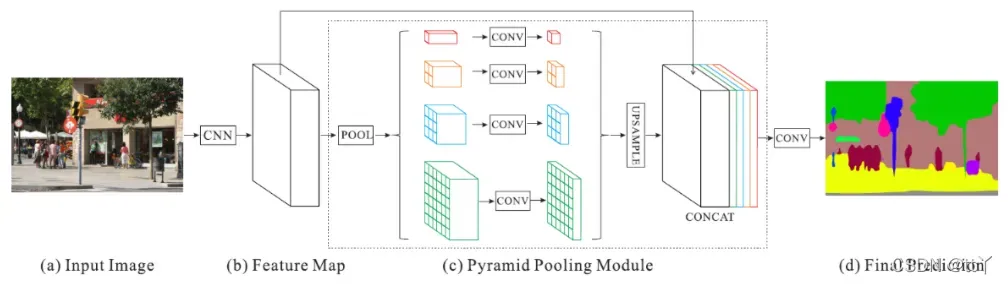
🌳PSPNet最主要的特点是提出了金字塔池化模块(pyramid pooling module)——PSP模块
PSP模块的原理与SPP相似
有关SPP的介绍可以看往期文章YOLOv5中的SPP/SPPF结构详解_tt丫的博客-CSDN博客_yolov5中的spp
PSP结构的作用是将得到的特征层划分成不同大小的网格,每个网格内部各自进行平均池化。这样可以实现聚合不同区域的上下文信息,从而提高获取全局信息的能力(加强特征提取)。
🌳在PSPNet中,PSP结构典型情况下,会将输入进来的特征层划分成6×6,3×3,2×2,1×1的网格,对应了下图中的绿色、蓝色、橙色、红色的输出
里面的操作说明:
红色:整个输入要素层的平均池化。
橙色:将输入进来的特征层划分为2×2个子区域,然后对每个子区域进行平均池化。
蓝色:将输入进来的特征层划分为3×3个子区域,然后对每个子区域进行平均池化。
绿色:将输入进来的特征层划分为6×6个子区域,然后对每个子区域进行平均池化。
八、deeplab-v3系列
这里只介绍deeplab-v3+网络
它采用空间金字塔池模块或编解码结构二合一的方式,并且通过添加一个简单有效的Decoder来细化分割结果,尤其是沿着目标对象边界的分割结果。
详情可以看看博主往期文章deeplab-v3+原理详解_tt丫的博客-CSDN博客
欢迎大家在评论区批评指正,谢谢~
版权声明:本文为博主tt丫原创文章,版权归属原作者,如果侵权,请联系我们删除!
原文链接:https://blog.csdn.net/weixin_55073640/article/details/123039854