论文主要是通读一遍,把我认为是重点的部分写下来。当然,也欢迎指正。
1.摘要
主要提到作者用了较多的tricks与一些结构:
(1)Weighted-Residual-Connections (WRC)
(2)Cross-Stage-Partial-connections (CSP)
(3)Cross mini-Batch Normalization (CmBN)
(4)Self-adversarial-training (SAT)
(5)Mish-activation
(6)Mosaic data augmentation
(7)DropBlock regularization
(8)CIoU loss
在MS COCO数据集上达到了精度43.5%AP (65.7% AP50),在Tesla v100上达到65FPS的速度。
以及代码地址:https://github.com/AlexeyAB/darknet
2.介绍
作者以推荐系统的例子,以及很多任务需要多张昂贵的GPU显卡来完成。表明自己的检测算法目标:简单、易用、性能好、单卡运行。
贡献:
(1)开发一个高效也性能强的检测算法,在1080单卡就能训练一个很好的模型。
(2)验证了最先进的 “免费袋 “和 “特殊袋 “方法在检测器训练期间对物体检测的影响。免费袋和特殊袋是什么?
(3)通过开发,使得一些tricks能够在单卡上有效的使用。
3.相关工作
针对目标检测领域不同的输入、backbone、neck、head结果等,做了一些总结,看了下,还挺清晰的。

3.1 Bag of freebies
终于在这里找到了bag of freebies的答案。
Bag of freebies:目标检测中能够提高性能,推理时不增加额外的速度消耗时。
(1)数据增强
(2)解决类别不均衡的方法,focal loss、label smoothing、knowledge distillation
(3)解决Bounding Box (BBox) 回归问题,一些损失函数GIoU loss、DIoU loss、CIoU loss等
3.2 Bag of specials
Bag of specials:目标检测中推理成本会有少量的增加,但可以显著提高准确性。
(1)增加感受野:SPP , ASPP , and RFB 。
(2)注意力机制模块:SAM,SE。
(3)特征融合:SFAM , ASFF , and BiFPN .
(4)更好的激活函数:LReLU , PReLU , ReLU6 , Scaled Exponential,Linear Unit (SELU) , Swish , hard-Swish , and Mish。
(5)后处理:nms、DIoU nms。
可以看出这一章其实写的很有条理,通过分析成本区分了本文后面需要用到的一些结构。可以为后续的精度提升和速度提升做更清晰的准备。
4.方法
先亮一下最重要的部分,YOLOv4使用了下面这些结构与tricks。

5.实验性能
作者做了很多消融实验,来验证哪些性能比较好。(在深度学习的tricks里面很多都是这样,一个策略有效可能就是通过多个对比实验发现的,有一部分理论性质的论文就会通过数学理论来进行推导验证)
(1)Bag of Freebies消融实验
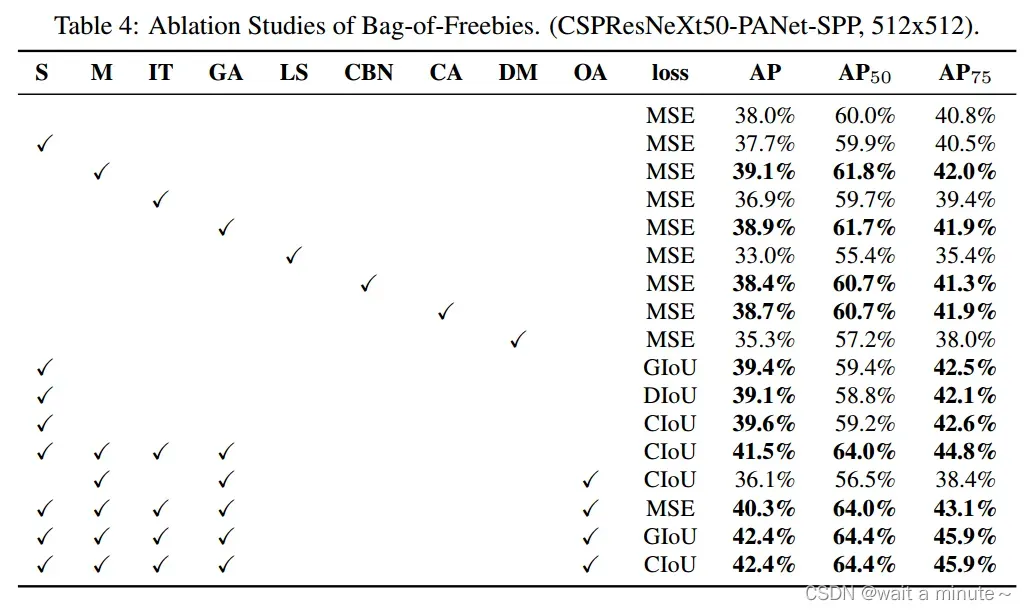
(2)Bag of Specials消融实验
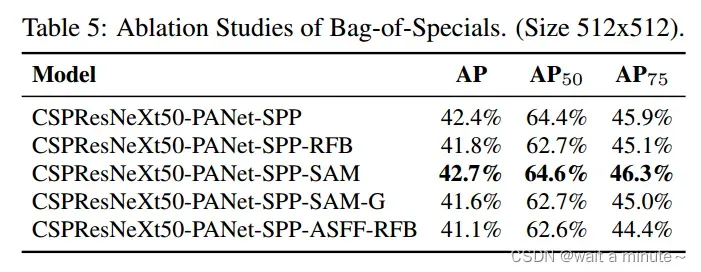
(3)不同backbone与预训练模型
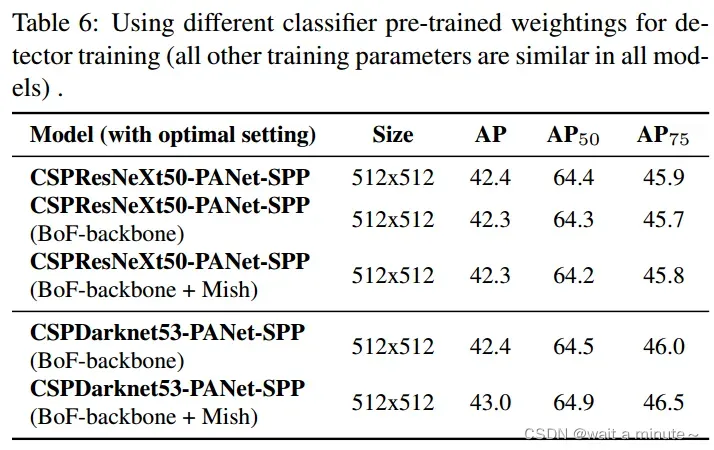
(4)不同batch-size与输入图片大小
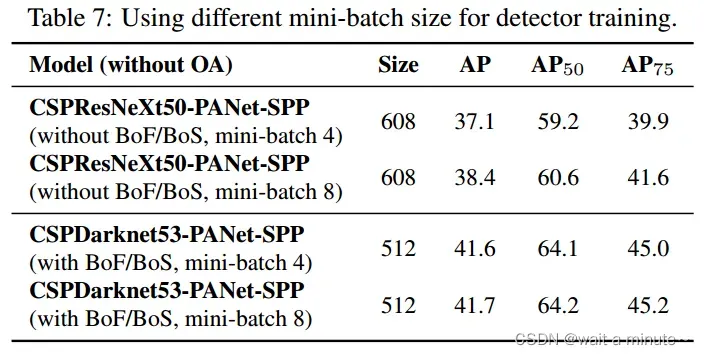
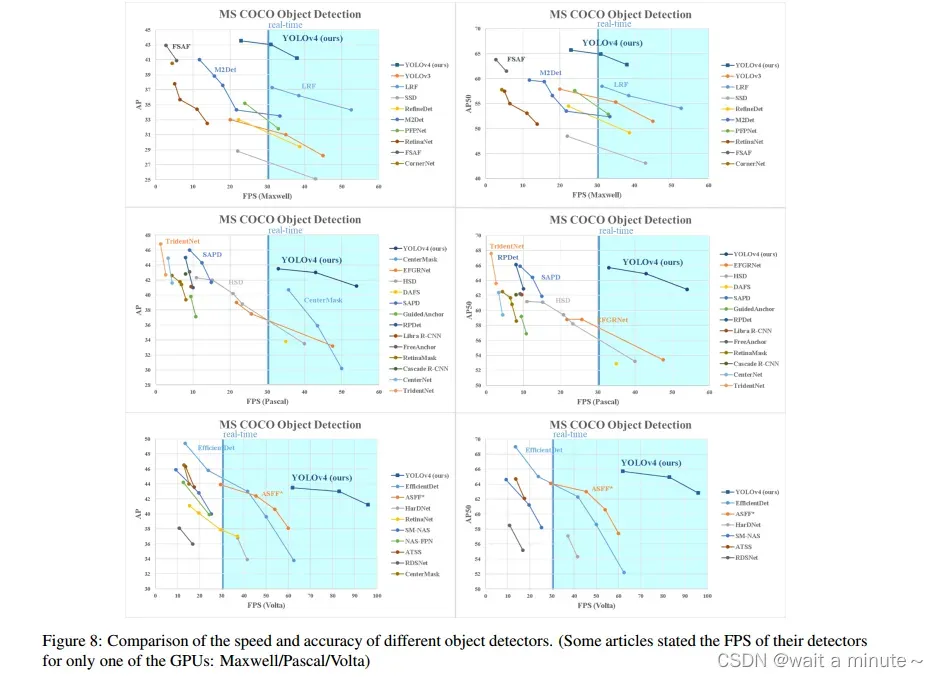
6.所有的对比结果
版权声明:本文为博主wait a minute~原创文章,版权归属原作者,如果侵权,请联系我们删除!
原文链接:https://blog.csdn.net/qq_35975447/article/details/123077062