要想使用python去爬取互联网上的数据,尤其是要模拟登录操作。那么selenium包肯定是绕不过的。
selenium包本质上就是通过后台驱动的方式驱动浏览器去。以驱动chrome浏览器为例,搭建环境如下:
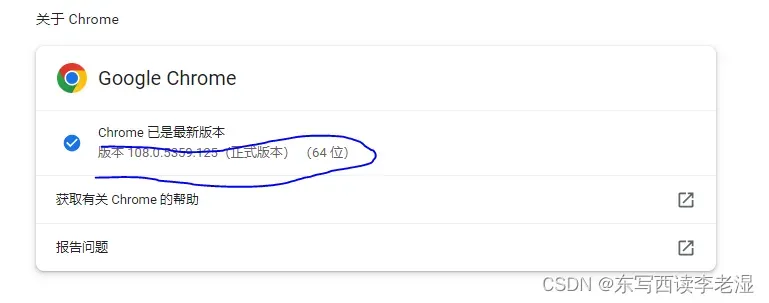
1、查看本机chrome浏览器的版本。
方式是:单击Chrome浏览器右上角三个点→帮助→关于 Google Chrome,查看Chrome版本。如图所示,我的是108.0.5359.125版本:
2、取驱动网站下载对应的驱动。网站地址:chrome浏览器驱动
一定要选择和浏览器对应的版本号,没有windows64位版本就直接选32位的。比如就选这个:
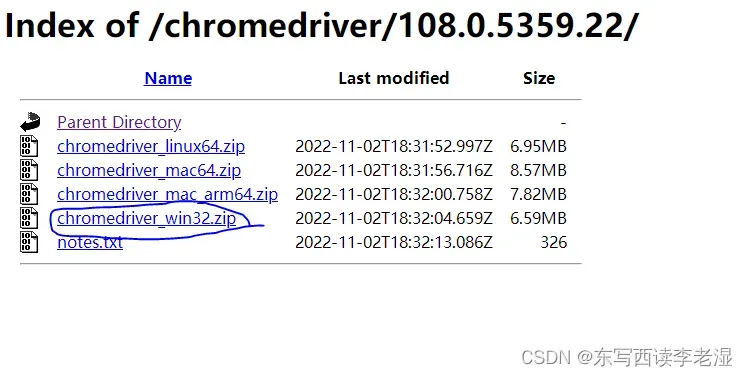
下载后解压,并放到对应的下去。
3、分别配置chrome浏览器和浏览器驱动的环境变量:
第一步:复制chrome浏览器的安装地址(找到chrome浏览器图标->右键->属性,复制“起始位置”的地址),我的是:C:\Program Files\Google\Chrome\Application
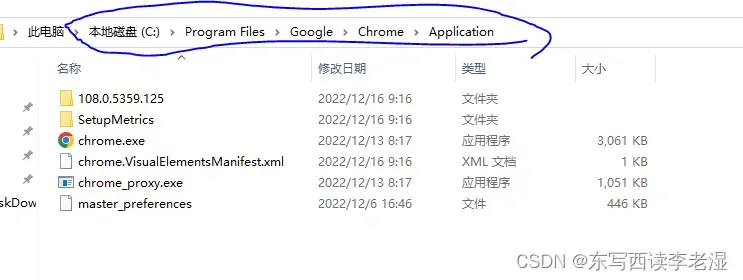
第二步:同样方法找到浏览器驱动的解压路径。
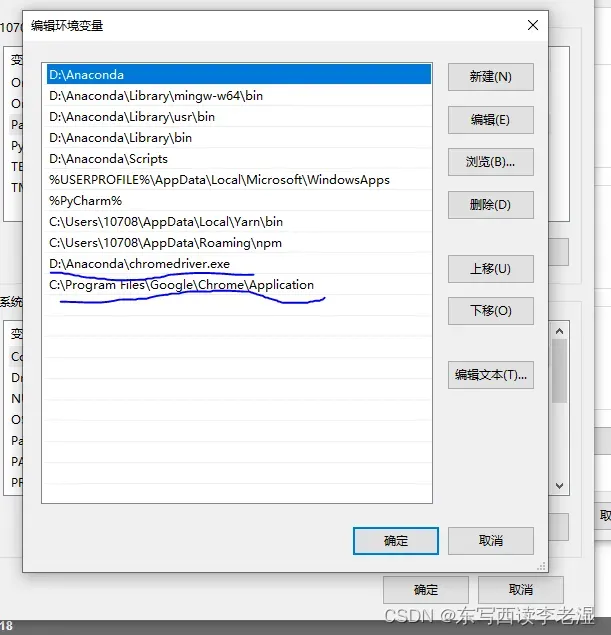
第三步:打开环境变量,在输入框输入环境变量,然后回车,点击“环境变量”,点击系统变量->Path->编辑->新建->粘贴Chrome浏览器的安装地址
4、测试环境变量配置是否成功。
之后,打开CMD
1)在CMD输入:chrome.exe --remote-debugging-port=9222,,如果能调起浏览器,说明chrome环境变量配置成功。
1)在CMD输入:chromedriver --version
如果显示以下信息,说明浏览器驱动配置成功:
ChromeDriver 90.0.4430.24
(4c6d850f087da467d926e8eddb76550aed655991-refs/branch-heads/4430@{#429})
5、pip install selenium。可以用以下示例代码进行测试,如果能正常调起浏览器,并打开百度页面,说明selenium包安装成功。
from selenium import webdriver
driver = webdriver.Chrome()
driver.get('https://www.baidu.com')
import time
time.sleep(5)
driver.quit()
文章出处登录后可见!