介绍
ChatGLM-6B是开源的文本生成式对话模型,基于General Language Model(GLM)框架,具有62亿参数,结合模型蒸馏技术,实测在2080ti显卡训练中上显存占用6G左右,
优点:1.较低的部署门槛: FP16 半精度下,ChatGLM-6B 需要至少 13GB 的显存进行推理,结合模型量化技术,一需求可以进一步降低到 10GB(INT8) 和 6GB(INT4), 使得 ChatGLM-6B 可以部署在消费级显卡上。
2,更长的序列长度: 相比 GLM-10B(序列长度1024),ChatGLM-6B 序列长度达 2048,支持更长对话和应用。
3,人类意图对齐训练: 使用了监督微调(Supervised Fine-Tuning)、反馈自助(Feedback Bootstrap)、人类反馈强化学习(Reinforcement Learning from Human Feedback) 等方式,使模型初具理解人类指令意图的能力。输出格式为 markdown,方便展示。目前已开源监督微调方法,
不足:1,模型容量较小: 6B 的小容量,决定了其相对较弱的模型记忆和语言能力,随着自己训练数据数量和轮次增加,会逐步丧失原来的对话能力.
2,较弱的多轮对话能力:ChatGLM-6B 的上下文理解能力还不够充分,在面对长答案生成,以及多轮对话的场景时,可能会出现上下文丢失和理解错误的情况。
1,安装
目前开源的ChatGLM-6B基于P-Tuning v2微调,
链接: link
下载ChatGLM-6B
git clone https://github.com/THUDM/ChatGLM-6B
cd ChatGLM-6B
pip install -r requirements.txt
cd ptuning/
pip install rouge_chinese nltk jieba datasets
1.1 使用自己数据集
修改 train.sh 和 evaluate.sh 中的 train_file、validation_file和test_file为你自己的 JSON 格式数据集路径,并将 prompt_column 和 response_column 改为 JSON 文件中输入文本和输出文本对应的 KEY。
将自己的数据集换成以下格式
{
“content”: “类型#上衣版型#宽松版型#显瘦图案#线条衣样式#衬衫衣袖型#泡泡袖衣款式#抽绳”,
“summary”: “这件衬衫的款式非常的宽松,利落的线条可以很好的隐藏身材上的小缺点,穿在身上有着很好的显瘦效果。领口装饰了一个可爱的抽绳,漂亮的绳结展现出了十足的个性,配合时尚的泡泡袖型,尽显女性甜美可爱的气息。”
}
2,开始训练
bash train.sh
train.sh 中的 PRE_SEQ_LEN 和 LR 分别是 soft prompt 长度和训练的学习率,可以进行调节以取得最佳的效果。P-Tuning-v2 方法会冻结全部的模型参数,可通过调整 quantization_bit 来被原始模型的量化等级,不加此选项则为 FP16 精度加载。
在默认配置 quantization_bit=4、per_device_train_batch_size=1、gradient_accumulation_steps=16 下,INT4 的模型参数被冻结,一次训练迭代会以 1 的批处理大小进行 16 次累加的前后向传播,等效为 16 的总批处理大小,此时最低只需 6.7G 显存。若想在同等批处理大小下提升训练效率,可在二者乘积不变的情况下,加大 per_device_train_batch_size 的值,但也会带来更多的显存消耗,请根据实际情况酌情调整。
PRE_SEQ_LEN=128
LR=2e-2
CUDA_VISIBLE_DEVICES=0 python3 main.py \
--do_train \
--train_file di/train.json \
--validation_file di/fval.json \
--prompt_column content \
--response_column summary \
--overwrite_cache \
--model_name_or_path THUDM/chatglm-6b \
--output_dir output/adgen-chatglm-6b-pt-$PRE_SEQ_LEN-$LR \
--overwrite_output_dir \
--max_source_length 64 \
--max_target_length 64 \
--per_device_train_batch_size 4 \
--per_device_eval_batch_size 4 \
--gradient_accumulation_steps 8 \
--predict_with_generate \
--max_steps 2000 \
--logging_steps 10 \
--save_steps 500 \
--learning_rate $LR \
--pre_seq_len $PRE_SEQ_LEN \
--quantization_bit 4
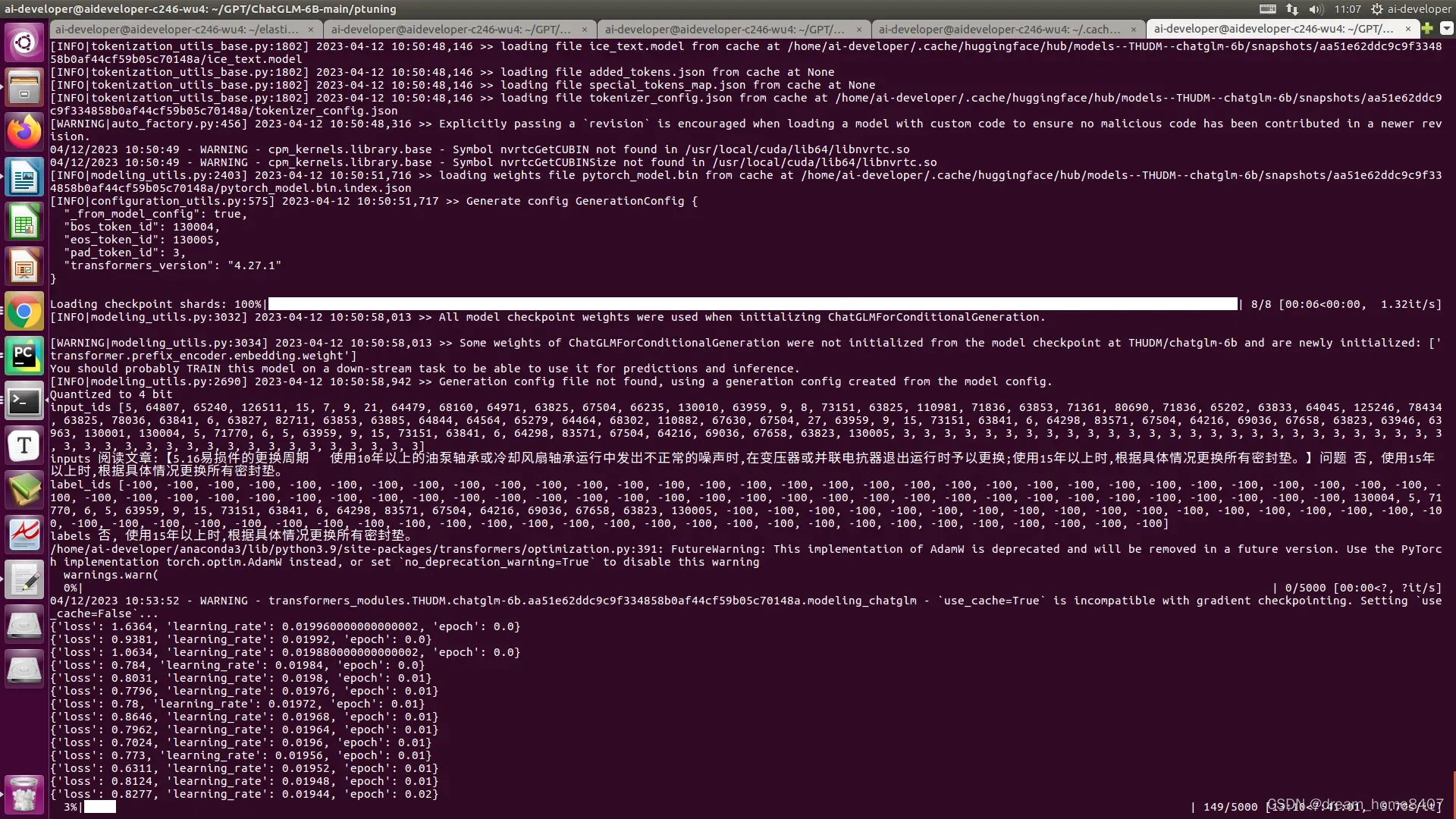
3,验证模型
将 evaluate.sh 中的 CHECKPOINT 更改为训练时保存的 checkpoint 名称,运行以下指令进行模型推理和评测:
bash evaluate.sh
4,模型部署
3.1 自己验证 ,更换模型路径
将对应的demo或代码中的THUDM/chatglm-6b换成经过 P-Tuning 微调之后 checkpoint 的地址(在示例中为 ./output/adgen-chatglm-6b-pt-8-1e-2/checkpoint-3000)。注意,目前的微调还不支持多轮数据,所以只有对话第一轮的回复是经过微调的。
tokenizer = AutoTokenizer.from_pretrained("THUDM/chatglm-6b", trust_remote_code=True)
model = AutoModel.from_pretrained("THUDM/chatglm-6b", trust_remote_code=True).half().cuda()
5,备注:预训练模型地址一般存放位置在本机
.cache/huggingface/hub/models–THUDM–chatglm-6b/snapshots/aa51e62ddc9c9f334858b0af44cf59b05c70148a/
查看包含这些目录
config.json configuration_chatglm.py modeling_chatglm.py pytorch_model.bin quantization.py
替换掉 demo.py 文件中THUDM/chatglm-6b为自己路径
文章出处登录后可见!