集成学习(Ensemble learning)
集成学习是监督式学习的一种。 在机器学习中,监督式学习(Supervised learning)算法目的是从一堆”假设”即假设空间(hypothesis space)中搜索一个具有较好且相对稳定的预测效果的模型。但很多情况下,即使”假设”空间中包含了一些很好的”假设”(hypothesis) ,我们也很难从中找到一个较好的。而集成学习的目的就是通过组合许多个弱模型(weak learners,预测效果一般的模型) 以得到一个强模型(strong learner,预测效果好的模型)。
对于大数据集(数据充足)和小数据集(数据不充足)的情况,集成学习方法都有一些比较好的策略来进行训练。
- 对于大数据集,可以按照一定策略划分成多个小数据集,对每个数据集训练一个基模型后再进行组合;
- 对于小数据集,可以利用Bootstrap(自助法,一种有放回的抽样方法)进行抽样,得到多个数据集,分别训练基模型之后再进行组合。
理论上来讲,使用集成学习的方法在评估测试时,相比于单一模型是需要更多的计算的。因此,有时集成学习也被认为是使用更多的计算来弥补弱模型的性能,此外,由于集成学习所含的参数量较大,导致模型中每个参数所包含的信息比单一模型要少很多,也就导致了太多的冗余。
集成学习的技术主要有Bagging、Boosting以及Stacking等,本文主要对Stacking技术进行讲解分析。
Stacking(堆栈)方法定义
在了解Stacking方法之前,需对Bagging方法有个简要的认知。Bagging方法是利用bootstrap方法从整体数据集中采取有放回抽样得到N个数据集,在每个数据集上学习出一个基模型。最后的预测结果利用N个模型的输出得到,具体地方式为: 分类问题采用N个模型预测投票的方式,回归问题采用N个模型预测平均的方式。Bagging背后的思想是结合多个模型的结果来获得泛化的结果,采取Bootstrap采样使得Bagging方法的训练集具有随机性,各个基分类器(基模型)也相互独立,从而可以减少过拟合的发生。
Stacking方法的基础思想与Bagging类似,都是结合多个模型的输出来完成最后的预测。但是与Bagging方法相比,有以下不同:
- Bagging是采取投票或平均的方式来处理N个基模型的输出,而Stacking方法是训练一个模型用于组合之前的基模型。具体过程是将之前训练基模型的输出构造为一个训练集,以此作为输入来训练一个模型,以获得最终的输出。
- Bagging中每个基模型的训练集是通过bootstrap抽样得到的,不尽相同。而Stacking方法中每个模型的训练集是一样的,使用全部的训练集来训练。 使用Stacking方法时,常常采用交叉验证的方法来训练基模型。
在Stacking方法中,有两个阶段的模型。 第一个阶段的模型是以原始训练集为输入的模型,叫做基模型(也叫 level-0 模型),可以选取多种基模型进行训练。第二个阶段的模型是以基模型在原始训练集上的预测作为训练集,以基模型在原始测试集上的预测作为测试集,叫做元模型(也叫 level-1 模型)。
下面是一个简单的Stacking算法模型架构。c1, …,cm是基分类器(基模型),每一个基分类器的训练集都是完整的原始训练集。对每一个基分类器都训练T个epoch,在训练完他们之后,将(c1, …,cm)对原始training set在T次epoch过程中的所有输出(p1, …,pm)合并在一起,作为新的训练集来训练第二个阶段的模型——元分类器。
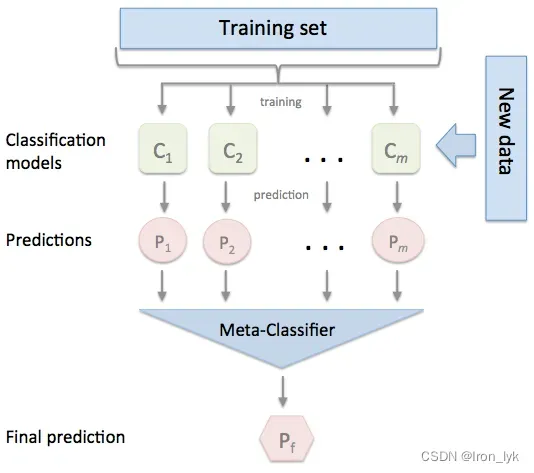
算法的伪代码[1]如下所示。

Stacking中的交叉验证
在实际使用Stacking方法时,为了避免过拟合的风险,常常伴随着交叉验证操作,以下面这张经典的图来解释[2]。这张图表示训练模型时使用5折交叉验证,Model1、Model2(还可以有Model3、Model4等)是不同的机器学习模型,比如随机森林、KNN、朴素贝叶斯、决策树等。假如整个数据集有12500行数据,训练集(Training set)包含10000行数据,测试集包含2500行数据。因为是5折交叉验证,训练集会被划分为5份。以Model1的训练为例,需对Model1进行5次训练,每次挑选一份作为验证集,即每次的训练集为8000行(10000*4/5),验证集为2000行(10000 *1/5)。Model1经过第一次训练后,在验证集上的输出记作a1(2000行),在测试集上的输出记作b1(2500行),经过第二次训练后,在验证集上的输出记作a2(2000行),在测试集上的输出记作b2(2500行)。以此类推,Model1经过五折交叉验证后,会得到a1,a2,a3,a4,a5,和b1,b2,b3,b4,b5。a1,a2,a3,a4,a5即Model1每次经过训练后在验证集上的输出结果,将他们拼接在一起得到A1,即Model1训练后在完整原始训练集上预测的结果。b1,b2,b3,b4,b5即Model1每次经过训练后在测试集上的输出结果,将他们相加之后求平均得到B1,即Model1训练后在完整原始测试集上预测的结果。
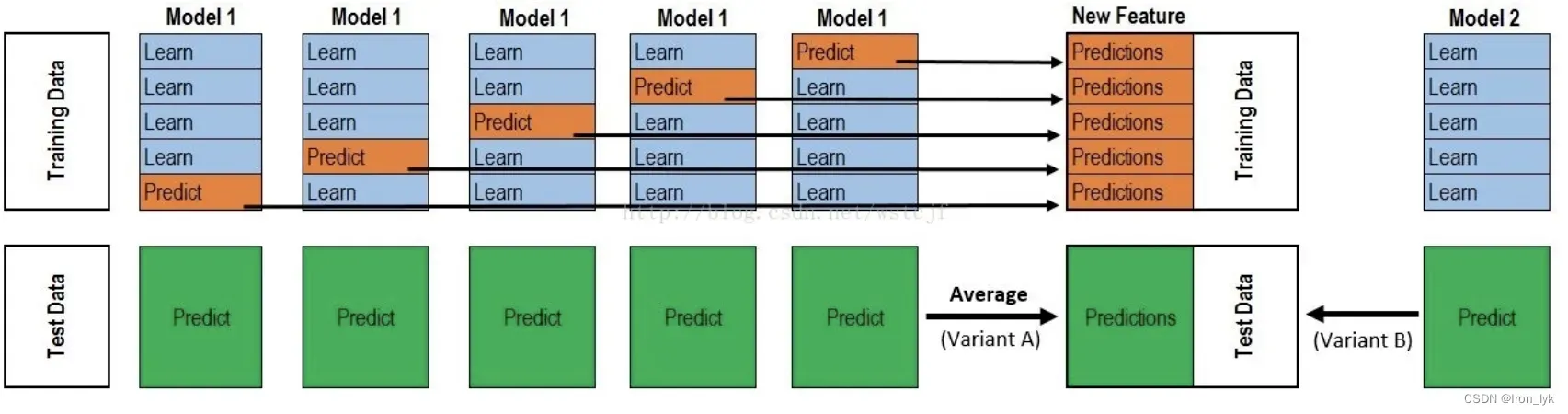
以上是Model1的五折交叉验证,经过训练之后得到了A1,B1。对其他的基模型进行同样的操作,假设我们的level-0模型中共包含五个基模型,那么经过上面的操作后,我们就会得到A1、A2、A3、A4、A5,和B1、B2、B3、B4、B5。此时我们再将A1、A2、A3、A4、A5合并在一起作为训练集,将B1、B2、B3、B4、B5作为测试集,来训练和测试我们的level-1模型(元模型)。这样就以五折交叉验证的方式实现了Stacking方法。
Stacking中的过拟合问题
从本质上来讲,Stacking方法其实是一种表示学习[3]。 表示学习指的是模型从原始数据中自动抽取有效特征的过程,比如深度学习就是一种表示学习的方法。在机器学习的问题中,原始数据往往是杂乱无规律的,在stacking方法中,通过第一层的多个学习器后,有效的特征被学习了出来,然后再输入至第二层的元模型中进行学习,这样效果就会很好。从这个角度来看,stacking的第一层就是特征抽取的过程。这一点与神经网络非常的相似,具体可参考「Stacking」与「神经网络」。
在神经网络中,如影随形的就是过拟合问题,在Stacking方法中也不例外。周志华教授也声明在Stacking在使用中常常会出现过拟合问题,因为第二层的特征来自于对于第一层数据的学习,那么第二层数据中的特征中不该包括原始特征,以降低过拟合的风险。所以第二层的数据特征应该仅包含学习到的特征,而不应该包含原始特征。 也正是因为Stacking方法中常常出现过拟合问题,所以在使用Stacking方法才会经常伴随着交叉验证操作来避免过拟合。
其他
在Stacking和Bagging方法中,每个基模型可以选取任意一种机器学习模型,比如KNN、朴素贝叶斯、决策树、SVM、逻辑回归等。经验上来说,如果待组合的各个基模型之间差异性(diversity )比较显著,那么Ensemble之后通常会有一个较好的结果,因此也有很多Ensemble的方法致力于提高待组合模型间的差异性。尽管不直观,但是越随机的算法(比如随机决策树)比有意设计的算法(比如熵减少决策树)更容易产生强分类器。然而,在实际使用中,发现使用多个强学习算法比那些为了促进多样性而做的模型更加有效。
从组合策略的角度来看,理论上,Stacking方法可以表示为Bagging、Boosting这两种方法,只需要采样合适的模型组合策略即可,但是在实际使用中,我们一般采用的是Logistic回归作为组合策略。
总的来说,Stacking 方法比任何单一模型的效果都要好,而且不仅成功应用在了监督式学习中,也成功应用在了非监督式(概率密度估计)学习中。甚至应用于估计bagging模型的错误率。目前在各种机器学习的比赛中,排名较高的模型一般也都会使用Stacking的技巧。
[1]. Tang, J., S. Alelyani, and H. Liu. “Data Classification: Algorithms and Applications.” Data Mining and Knowledge Discovery Series, CRC Press (2015): pp. 498-500.
[2] 【机器学习】集成学习之stacking
[3] 「Stacking」与「神经网络」
文章出处登录后可见!