1. BN层的作用
(1)BN使得网络中每层输入数据的分布相对稳定,加速模型学习速度
(2)BN使得模型对网络中的参数不那么敏感,简化调参过程,使得网络学习更加稳定
(3)BN允许网络使用饱和性激活函数(例如sigmoid,tanh等),缓解梯度消失问题
(4)BN具有一定的正则化效果
详细了解
2. 空洞卷积
空洞卷积(dilated convolution)是针对图像语义分割问题中下采样会降低图像分辨率、丢失信息而提出的一种卷积思路。利用添加空洞扩大感受野,让原本的卷积核,在相同参数量的情况下,用于
或者更大的感受野,无须下采样。
这儿存在一个问题:
- 局部信息的损失:由于atrous卷积的计算方式类似于棋盘格格式,某一层得到的卷积结果与上一层是独立的集合,不存在相互依赖,所以卷积之间不存在相关性这一层的结果。 ,即局部信息丢失。
- 远距离获取的信息没有相关性:由于空洞卷积对输入信号的采样稀疏,用于获取远距离信息。但是这些信息之间并没有相关性,同时在对大物体进行分割的时候,会有一定的效果,但是对于小物体来说,有缺点没有优点。
详细了解
3. 图像插值方法
- 最近邻法。最近邻像素是替换像素的方法
- 二次插值
已知(x1, y1, f (x1, y1)),(x1, y2, f (x1, y2)),(x2, y1, f (x2, y1)),(x2, y2, f (x2, y2))
用双线性插值估计 f(x, y):
先对 x 进行插值去求 f(x,y1) 和 f(x,y2):
然后去问:
㓚 Guo, then:
RoI Align 就行用的双线性插值对连续点利用周围的四个点进行双线性插值
详细学习链接
4. Focal loss
平衡了正负样本数量,但实际上,目标检测中大量的候选目标都是易分样本,这些样本会使损失很低,因此模型应关注那些难分样本,将高置信度的样本损失函数降低一些,就有了Focal loss
5. 深度可分离卷积
一些轻量级的网络,如mobilenet中,会有深度可分离卷积depthwise separable convolution,由depthwise(DW)和pointwise(PW)两个部分结合起来,用来提取特征feature map
与传统的卷积运算相比,参数个数和运算成本都比较低
正则卷积操作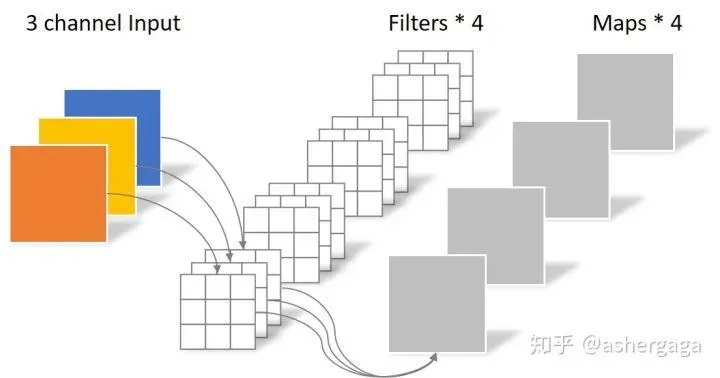
卷积层共4个Filter,每个Filter包含了3个Kernel,每个Kernel的大小为3×3。因此卷积层的参数数量可以用如下公式来计算:
N_std = 4 × 3 × 3 × 3 = 108
深度可分离卷积
- 通道卷积
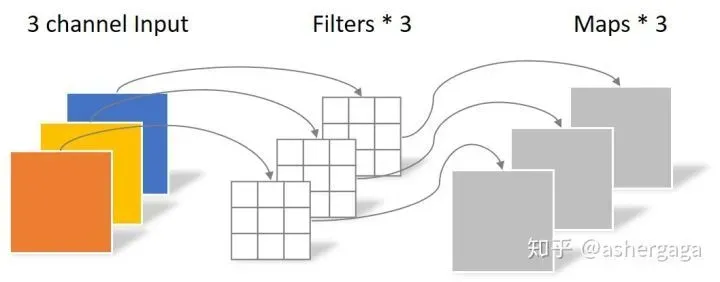
其中一个Filter只包含一个大小为3×3的Kernel,卷积部分的参数个数计算如下:
N_depthwise = 3 × 3 × 3 = 27
- 逐点卷积
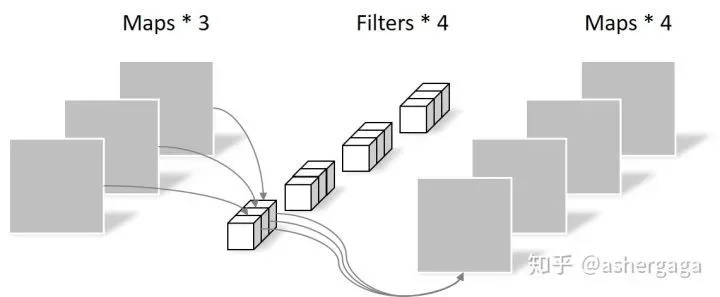
由于采用的是1×1卷积的方式,此步中卷积涉及到的参数个数可以计算为:
N_pointwise = 1 × 1 × 3 × 4 = 12
经过Pointwise Convolution之后,同样输出了4张Feature map,与常规卷积的输出维度相同
详细学习链接
6. 为什么说Dropout可以解决过拟合?
(1)取平均的作用: 先回到标准的模型即没有dropout,我们用相同的训练数据去训练5个不同的神经网络,一般会得到5个不同的结果,此时我们可以采用 “5个结果取均值”或者“多数取胜的投票策略”去决定最终结果。例如3个网络判断结果为数字9,那么很有可能真正的结果就是数字9,其它两个网络给出了错误结果。这种“综合起来取平均”的策略通常可以有效防止过拟合问题。因为不同的网络可能产生不同的过拟合,取平均则有可能让一些“相反的”拟合互相抵消。dropout掉不同的隐藏神经元就类似在训练不同的网络,随机删掉一半隐藏神经元导致网络结构已经不同,整个dropout过程就相当于对很多个不同的神经网络取平均。而不同的网络产生不同的过拟合,一些互为“反向”的拟合相互抵消就可以达到整体上减少过拟合。
(2)减少神经元之间复杂的共适应关系: 因为dropout程序导致两个神经元不一定每次都在一个dropout网络中出现。这样权值的更新不再依赖于有固定关系的隐含节点的共同作用,阻止了某些特征仅仅在其它特定特征下才有效果的情况。迫使网络去学习更加鲁棒的特征 ,这些特征在其它的神经元的随机子集中也存在。换句话说假如我们的神经网络是在做出某种预测,它不应该对一些特定的线索片段太过敏感,即使丢失特定的线索,它也应该可以从众多其它线索中学习一些共同的特征。从这个角度看dropout就有点像L1,L2正则,减少权重使得网络对丢失特定神经元连接的鲁棒性提高。
(3)Dropout类似于性别在生物进化中的角色:物种为了生存往往会倾向于适应这种环境,环境突变则会导致物种难以做出及时反应,性别的出现可以繁衍出适应新环境的变种,有效的阻止过拟合,即避免环境改变时物种可能面临的灭绝。
详细学习链接
7. 知识蒸馏
知识蒸馏指的是将复杂模型(teacher)中的dark knowledge迁移到简单模型(student)中去,一般来说,teacher模型具有强大的能力和表现,而student模型则体量很小。通过知识蒸馏,希望student模型能尽可能逼近亦或是超过teacher模型,从而用更少的复杂度来获得类似的预测效果,实现模型的压缩和量化。
总结来说,知识蒸馏,可以将一个网络的知识转移到另一个网络。做法是先训练一个teacher网络,然后使用这个teacher网络的输出和数据的真实标签去训练student网络。知识蒸馏,可以用来将网络从大网络转化成一个小网络,并保留接近于大网络的性能;也可以将多个网络的学到的知识转移到一个网络中,使得单个网络的性能接近emsemble的结果。
详细学习链接
详细学习链接
8. 1×1卷积核作用
- 降维/升维
- 增加非线性
- 跨通道信息交互(channal 的变换)
9. add_with_concat
连接
操作时增加通道数,
是添加特征图,通道数保持不变。
- 对于
的操作,如果通道数相同,再进行卷积,
区别
- 对于
- 对于
在
综上所述
因此,如果需要融合的
和
,如果它们语义不同,我们可以使用
的形式,如
、
进行编码和解码结构,主要使用
。
而如果和
语义相同,比如
和
是不同分辨率的特征,语义相同,我们可以用
进行融合,比如
和
等网络的设计。
详细学习链接
10. CNN
CNN
- 局部连接:不是全连接,而是使用size相对input小的kernel在局部感受视野内进行连接(点积运算)
- 权重共享:在一次卷积核操作中,每次计算一个感知场,通过滑动遍历对整个输入进行卷积,而不是每次移动都改变卷积核参数
两者都旨在减少参数。通过对视场的局部感知,可以通过卷积运算得到高阶特征,可以达到更好的效果。
池化的意义
1.特征不变形:池化操作是模型更加关注是否存在某些特征而不是特征具体的位置。
2.特征降维:池化相当于在空间范围内做了维度约减,从而使模型可以抽取更加广范围的特征。同时减小了下一层的输入大小,进而减少计算量和参数个数。
3.在一定程度上防止过拟合,更方便优化。
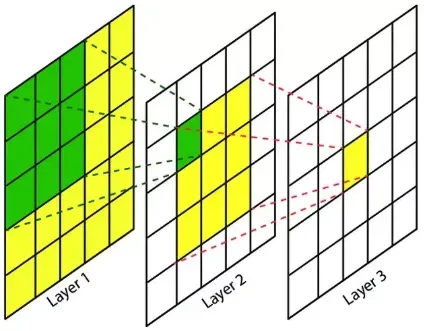
11. 感受野
感受野()的定义是卷积神经网络每一层输出的特征图(
)上的像素点映射到原始输入图像上的区域大小。更通俗的解释是,特征图上的一个点对应于原始输入图像上的一个区域,如下图所示。
12. 欠拟合和过拟合
解决欠拟合:
- 添加其他功能。组合、泛化、相关、上下文特征、平台特征等特征是特征添加的重要手段。有时特征项不足会导致欠拟合。
- 添加多项式特征。例如将线性模型添加二次项或三次项使泛化能力更强。例如,FM(Factorization Machine)模型、FFM(Field-aware Factorization Machine)模型,其实就是线性模型,增加了二阶多项式,保证了模型一定的拟合程度。
- 可以增加模型的复杂性。
- 减小正则化因子。正则化的目的是防止过拟合,但如果模型先欠拟合,则需要减小正则化参数。
解决过拟合:
- 重新清洗数据,不纯的数据会导致过拟合,这种情况需要重新清洗数据。
- 增加训练样本的数量。
- 降低模型复杂性。
- 增加正则项系数。
- 采用dropout方法,dropout方法,通俗的讲就是在训练的时候让神经元以一定的概率不工作。
- early stopping,减少迭代次数。
- 提高学习率。
- 添加噪声数据。数据增强。
- 在树结构中,树可以被修剪。
- 减少功能项目。
13. 优化器
- 非自适应优化器
GD、BGD、SGD、SGDM - 自适应优化器
Adagrad、Adadelta、RMSprop、Adam
14. 神经网络模型不收敛
原因
- 忘记标准化您的数据
- 忘记检查输出
- 无数据预处理
- 没有使用正则化方法
- 使用了一个太大的 batch size
- 使用错误的学习率
- 在最后一层使用错误的激活函数
- 网络包含不良梯度
- 网络权重未正确初始化
- 使用了太深的神经网络
- 隐藏层神经元个数设置不正确
对应的解决方案是:
- 规范化数据。常用的归一化方法有零均值归一化和线性函数归一化;
- 检测训练过程中各个阶段的数据结果。如果是图像数据,可以考虑使用可视化的方法;
- 预处理数据,包括做一些简单的转换;
- 采用正则化方法,比如 L2 正则,或者 dropout;
- 在训练的时候,找到一个可以容忍的最小的 batch 大小。可以让 GPU 并行使用最优的 batch 大小并不一定可以得到最好的准确率,因为更大的 batch 可能需要训练更多时间才能达到相同的准确率。所以大胆的从一个很小的 batch 大小开始训练,比如 16,8,甚至是 1。
- 不使用渐变剪裁。找到在训练过程中不会导致错误爆炸的最大学习率。将学习率设置为比这个低一个数量级,这可能非常接近最优学习率。
- 如果是在做回归任务,大部分情况下是不需要在最后一层使用任何激活函数;如果是分类任务,一般最后一层是用 sigmoid 激活函数;
- 如果你发现你的训练误差没有随着迭代次数的增加而变化,那么很可能就是出现了因为是 ReLU 激活函数导致的神经元死亡的情况。可以尝试使用如 leaky ReLU 或者 ELUs 等激活函数,看看是否还出现这种情况。
- 目前比较常用而且在任何情况下效果都不错的初始化方式包括了“he”,“xaiver”和“lecun”。所以可以任意选择其中一种,但是可以先进行实验来找到最适合你的任务的权值初始化方式。
- 从256到1024个隐藏神经元数量开始。然后,看看其他研究人员在相似应用上使用的数字
15. 权重初始化方法
- 初始化为常量
- 平均初始化
- 普通函数初始化
- Aavier初始化:尽可能的让输入和输出服从相同的分布,这样就能够避免后面层的激活函数的输出值趋向于
- He Kaiming initialization
16. 网络模型训练技巧
17. 时序建模模块
18. 激活函数
19. AUC和ROC
20. L1和L2
正则化项是模型参数的绝对值之和。
正则化项是模型各参数平方和的平方根值。
生成一个稀疏的权重矩阵,即可以生成一个稀疏的模型,可以用于特征选择;在一定程度上,
);
21. 标签平滑-

标签平滑采用如下思想:在训练时,假设标签可能存在错误,从而避免“过度”信任训练样本的标签。当目标函数是交叉熵时,这个想法有一个非常简单的实现,叫做标签平滑()。
没有标签平滑计算的损失只考虑了正确标签位置的损失,没有考虑其他标签位置的损失,这会导致没有考虑其他错误标签位置的损失的问题,这会使模型过于集中很多关于正确增加预测。标签的概率,而不是专注于降低预测错误标签的概率,最终的结果是模型在自己的训练集上拟合得很好,但是在其他测试集上表现不佳,也就是过拟合,也就是据说模型的泛化能力很差。
平滑后的样本交叉熵损失不仅考虑了训练样本中正确标签位置(–
标注
)的损失,还略微考虑了其他错误标签位置(
–
标签位置为
)。损失,导致最终损失的增加,导致模型学习能力的提高,即要减少原来的损失,它必须学习得更好,即迫使模型增加正确的概率分类并减少错误分类的概率。前进。
详细学习链接
详细学习链接
22. BN,LN,IN,GN, SN
batchNorm是在batch上,对NHW做归一化,对小batchsize效果不好;
layerNorm在通道方向上,对CHW归一化,主要对RNN作用明显;
instanceNorm在图像像素上,对HW做归一化,用在风格化迁移;
GroupNorm将channel分组,然后再做归一化;
SwitchableNorm是将BN、LN、IN结合,赋予权重,让网络自己去学习归一化层应该使用什么方法。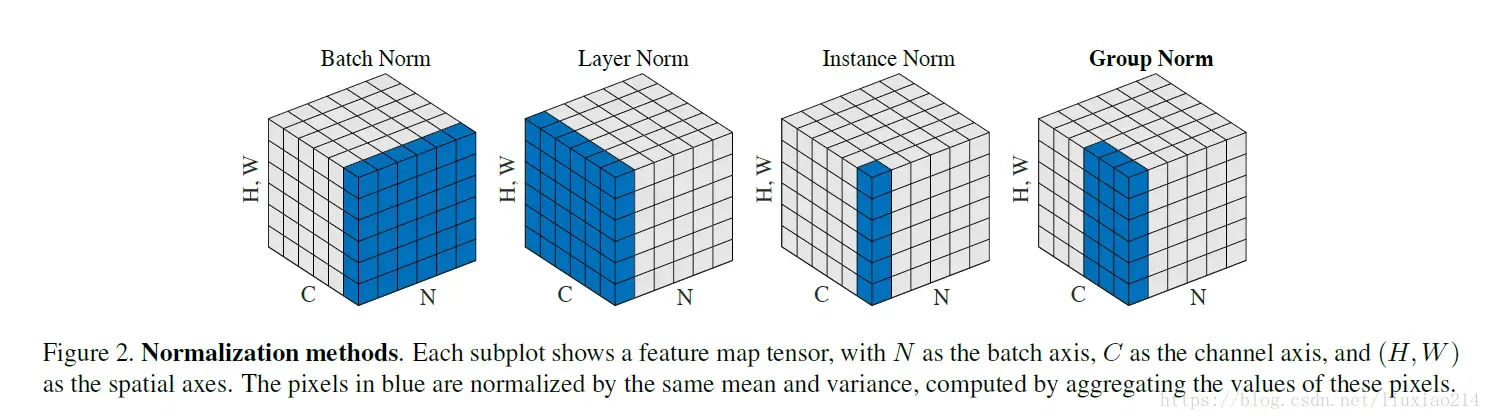
详细学习链接
23. FPN为何能够提升小目标的精度
低层的特征语义信息比较少,但是目标位置准确;高层的特征语义信息比较丰富,但是目标位置比较粗略。原来多数的object detection算法都是只采用顶层特征做预测。FPN同时利用低层特征高分辨率和高层特征的高语义信息,通过融合这些不同层的特征达到预测的效果。并且预测是在每个融合后的特征层上单独进行的。所以可以提升小目标的准确率。
24. Softmax与sigmoid计算公式
详细学习链接
详细学习链接
25. 为什么分类问题的损失函数采用交叉熵而不是均方误差MSE?
版权声明:本文为博主Fighting_1997原创文章,版权归属原作者,如果侵权,请联系我们删除!
原文链接:https://blog.csdn.net/frighting_ing/article/details/123378776