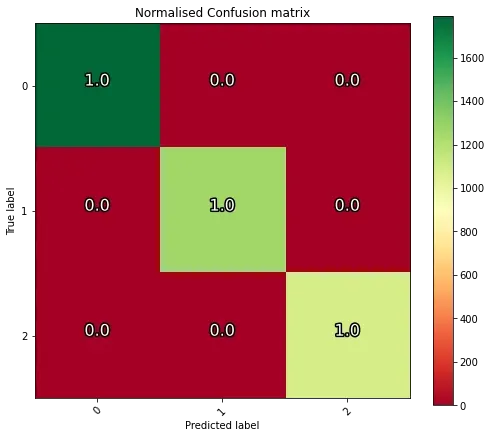
训练验证和准确率非常高,但测试准确率很低
deep-learning 625
原文标题 :Training validation and accuracy are very high, but testing accuracy is low
我的模型的训练准确率和验证准确率非常高。
...
Epoch 4/5
457/457 [==============================] - 4s 8ms/step - loss: 0.0237 - accuracy: 0.9925 - val_loss: 0.0036 - val_accuracy: 0.9993
Epoch 5/5
457/457 [==============================] - 4s 8ms/step - loss: 0.0166 - accuracy: 0.9941 - val_loss: 0.0028 - val_accuracy: 0.9994
但是,经过测试,准确性非常糟糕:
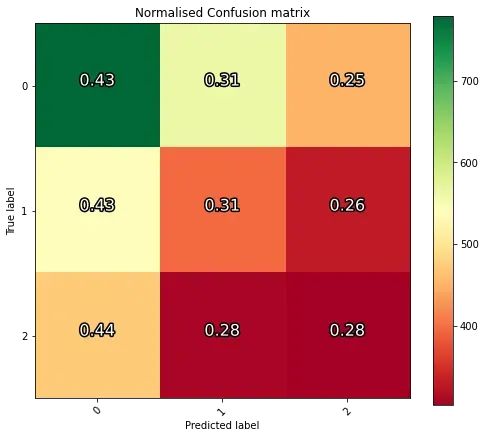
(为了获得高精度,从左上角到右下角会有一条绿色对角线)
我不确定为什么会这样,考虑到训练集和验证集的高精度和低损失。如果模型过度拟合,那么验证损失或准确性应该偏离训练损失或准确性,但事实并非如此.这是我的数据生成器:
train_datagen = DataGenerator(
partition["train"],
labels,
batch_size=BATCH_SIZE,
**params
)
val_datagen = DataGenerator(
partition["val"],
labels,
batch_size=BATCH_SIZE,
**params
)
test_datagen = DataGenerator(
partition["test"],
labels,
batch_size=1,
**params
)
请注意,由于我的数据采用 .npy 文件上的 npy 数组的形式,因此我按照这篇文章创建了一个自定义数据生成器类。
这是我的训练过程:
history = model.fit(
train_datagen,
epochs = 5,
steps_per_epoch = len(train_datagen),
validation_data = val_datagen,
validation_steps = len(val_datagen),
shuffle = False,
callbacks = callback,
use_multiprocessing = True,
workers = 4
)
在这里你可以看到我是如何对数据进行分区的:
print(len(partition["train"]))
print(len(partition["val"]))
print(len(partition["test"]))
print(len(partition["train"]) + len(partition["val"]) + len(partition["test"]))
print(good, ok, bad)
# good: 0, ok: 1, bad: 2
29249
8342
4144
41735
18152 12665 10918
我还确认任何集合之间没有重叠:
print(bool(set(partition["train"]) & set(partition["val"])))
print(bool(set(partition["test"]) & set(partition["val"])))
print(bool(set(partition["train"]) & set(partition["test"])))
False
False
False
有人可以帮我弄清楚我哪里出错了吗?我不确定如何获得如此高的测试和验证准确性,但测试率却很糟糕。我在 Github 上托管了我的完整代码和文件。