1.引言
人工神经网络容易发生灾难性遗忘。网络参数通常通过重放过去任务的真实样本来联合优化,但这种方法是内存密集型的,在实际部署中可能效果不佳。基于脑科学的研究指出,人类大脑皮层的海马体不仅仅是一个简单的记忆回放缓冲区。记忆痕迹的重新激活会产生相当灵活的结果。记忆的改变和重新激活会导致巩固记忆的缺陷,而海马体中某些记忆痕迹的共同刺激会产生从未经历过的“虚假记忆”。这些属性表明海马体和生成模型之间的并行性比回放缓冲区更好(这里解释了为什么真实样本被生成数据取代,灵感来自对海马体的研究)
所以我们提出了一种方法来顺序训练深度神经网络,而不参考过去的数据。在我们的深度生成重放框架中,该模型通过同时重放生成的伪数据(通过GAN)来保留先前获得的知识。然后将生成的数据与来自过去任务解决者的相应响应配对以表示旧任务。生成器-求解器对可以根据需要生成假数据和所需的目标对,并且当呈现新任务时,这些生成的对与新数据交错以更新生成器和求解器网络。有以下优势:
1.无需访问过去的数据(隐私保护)
2.模型可以不同(强的灵活性)
3.生成式data更能反映知识
2.相关工作
2.1比较方法
1.Dropout、L2正则化
2.EWC: 在参数空间内保护那些重要的参数
3.LWF: 通过知识蒸馏加微调平衡新旧任务性能
2.2互补学习系统理论(CLS)
1.伪排技术:将记忆网络产生的伪输入和伪目标输入任务网络
2.双网络记忆模型
3.通过训练受限玻尔兹曼机来恢复过去的输入分布的生成式回放
2.3深度生成模型
大名鼎鼎的GAN网络,GAN定义了生成器和判别器
。判别器通过比较两个数据分布来学习区分生成的样本和真实样本,而生成器则学习尽可能地模仿真实分布,优化目标定义如下:
3.生成重放
假定需要解决的包含N个任务的任务序列
Definition 1
学习任务,目标是从数据分布中优化模型
提取训练样本
我们称这个模型为scholar
Definition 2
scholar包含两个部分,分别是生成器和解决器
,
负责生成类真实样本,
负责优化模型
解决器需要执行整个任务序列,所以loss如下:
在任务训练时,模型从
抽取样本
3.1 GR方法介绍
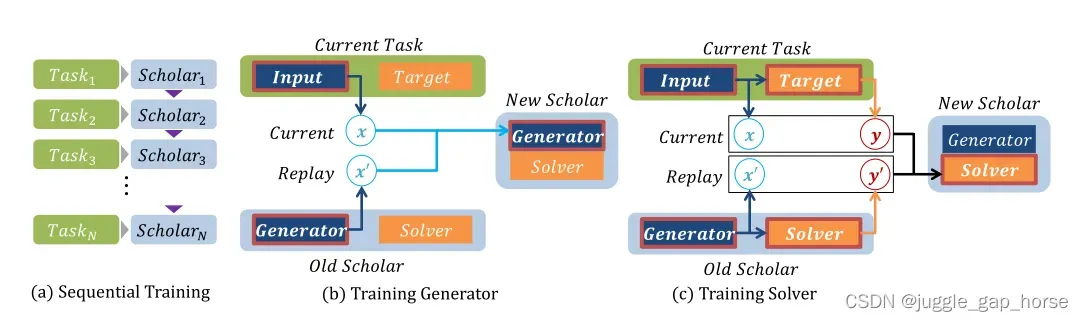
每个任务对应一个scholar,生成器首先被训练,以生成重放样本,随后重放样本与下个任务的真实样本混合供下个任务的求解器
训练。因此第
个求解器的损失函数应为:
其中是
第二学者的网络参数,
是混合真实数据的比例。由于目标是在原始任务上评估模型,因此测试损失与训练损失不同:
4.实验
对比求解器的几种重放方法:
1.ER。重放样本由真实的样本提供
2.Noise。重放样本是随机的噪声
3.None。无重放正常训练的求解器 (baseline)
4.1 在MNIST-PERMUTATION上的多任务评估
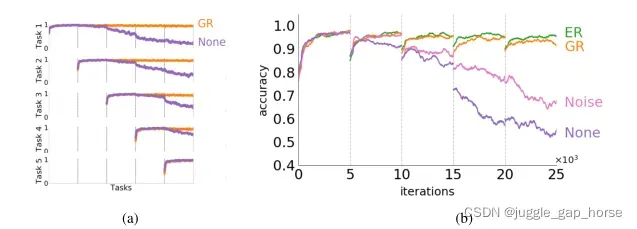
顺序训练的情况下,对所以学习过的任务性能:ER > GR > Noise > None
4.2 不同域上的评估
在在不同的多个域上的性能更能体现持续学习的意义。与仅在单个域中工作的模型相比,在多个域中运行的模型具有几个优点。首先,如果领域不是完全独立的,一个领域的知识可以帮助更好更快地理解其他领域。其次,对多个领域的概括可能会导致更普遍的知识适用于看不见的领域。下面是数字分类场景mnist到街道门牌场景SVHN性能对比: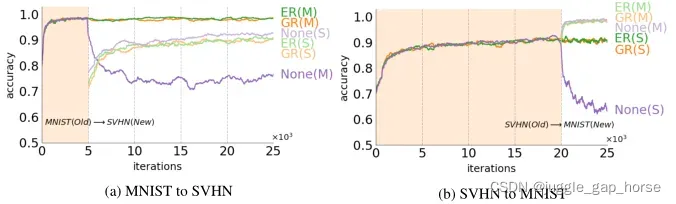
显然,无论是MNIST to SVHN,还是SVHN to MNIST,无生成器的单单顺序学习下的求解器都会导致明显的性能下降。而GR相比ER,性能非常接近,一定程度上反映了模型中的知识能代表真实样本。而GR也能兼容于其他持续学习算法如LWF。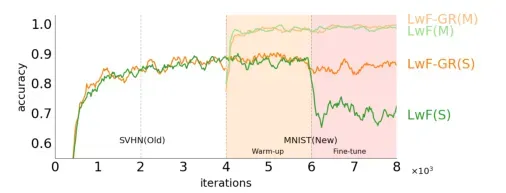
LWF不使用旧任务的数据,而是通过旧任务模型对新任务数据的‘’respond‘’来匹配旧任务的输出,从而平衡新旧任务的性能。直观的,如果加上生成式的样本作为补充,在在微调参数时,性能不会出现大的损失。
4.3 学习新类
为了说明即使输入和目标在任务之间高度倾斜,生成回放也可以回忆过去的知识,提出了一个新的实验,其中网络在不相交的数据上进行顺序训练。在持续学习的场景中,学习新的未知类显然比跨域迁移更难。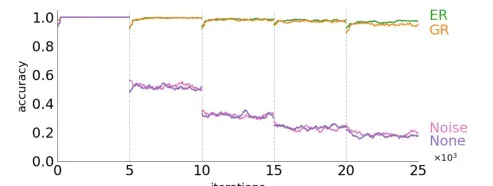
实验在MNIST上进行,具体将其切分为5个子集,每个子集两类。可以观察到经过简单训练的分类器完全忘记了以前的类,只学习了新的数据子集(紫色)。仅恢复过去的输出分布而没有有意义的输入分布无助于保留知识,带有噪声发生器(粉红色)的模型就证明了这一点。当输入 7和输出分布都被重建时,生成重放会唤起先前学习的类,并且该模型能够区分所有遇到的类(橙色)。
5.总结
此文引入了深度生成重放框架(GR),它允许通过生成和排练模仿以前训练示例的假数据来对多个任务进行顺序学习。学者模型包含生成器和求解器。学者模型可以只是同一网络的过去副本,它可以学习多个任务,而无需明确划分训练过程。
比较方法中,EWC 等正则化方法和 LwF 中对共享参数的训练表明,可以通过保护网络的先前知识来减轻灾难性遗忘。然而,正则化方法使用额外的损失项来约束网络以保护权重,因此它们可能会受到新任务和旧任务性能之间的权衡的影响。为了保证这两项任务的良好性能,通常在一个比以往需要的大得多的巨大网络上进行训练(计算代价GR)。此外,当约束特定于 EWC 中的每个参数时,网络必须在所有任务中保持相同的结构(不灵活);LwF 框架的缺点也有两个:性能高度依赖于任务的相关性,并且一个任务的训练时间随着前一个任务的数量线性增加。
GR受益于它仅使用从保存的网络产生的输入-目标对来维护以前的知识,因此它可以轻松平衡以前和新的任务性能和灵活的知识转移。最重要的是,网络针对任务目标进行了联合优化,因此当生成器恢复之前的输入空间时,可以保证实现全部性能。生成重放框架的一个缺陷是算法的有效性在很大程度上取决于生成器的质量。而作者提出与EWC、LWF的有机结合应该是很有潜力的。
文章出处登录后可见!