Yolov5_v6.2训练数据集进行预测
学习笔记
记录一下第一次进行Yolov5的部署,调试,训练,预测。
新发布到了博客园:https://www.cnblogs.com/jhy-ColdMoon/p/17055124.html
1.环境部署
- 我使用的环境是:Yolov5_v6.2 + Minconda + torch_v1.13.0(CPU版本)
1.1.Minconda安装:略。
- 这里不是重点,可以查询专门的安装配置教程。
- 使用Anaconda是一样的。
- 在安装后,建议设置国内镜像源,否则后面下载会很慢。
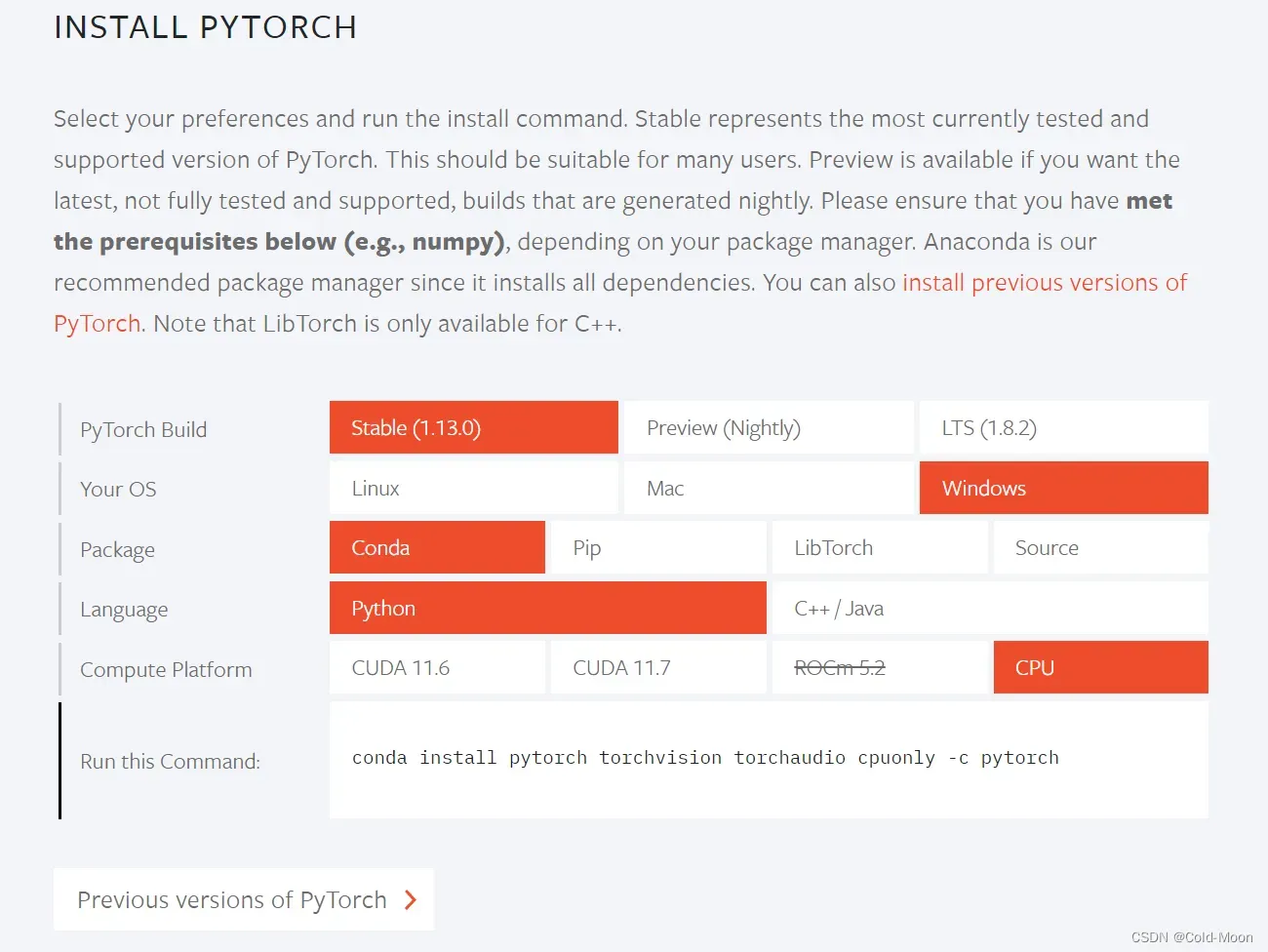
1.2.Pytorch安装:
-
在Yolov5的
requirements.txt中,有设置下载Pytorch,但Pytorch相对于其他东西比较大,所以这里选择单独安装,避免出错。 -
在Pytorch官网
https://pytorch.org选择配置(有NVIDIA独显和没独显不一样)后,复制生成的代码,在conda中安装 -
例如我这里没有NVIDIA的独立显卡,所以选择CPU版本
#我选择的CPU版本,生成的下载链接 conda install pytorch torchvision torchaudio cpuonly -c pytorch
-
安装完成后,查看torch版本
#python 查看torch版本 >>> import torch >>> print(torch.__version__) #python 判断cuda能否使用 >>> import torch >>> torch.cuda.is_available() #True 有cuda False没有cuda,我没有NVIDIA独显且安装的CPU版本,所以为False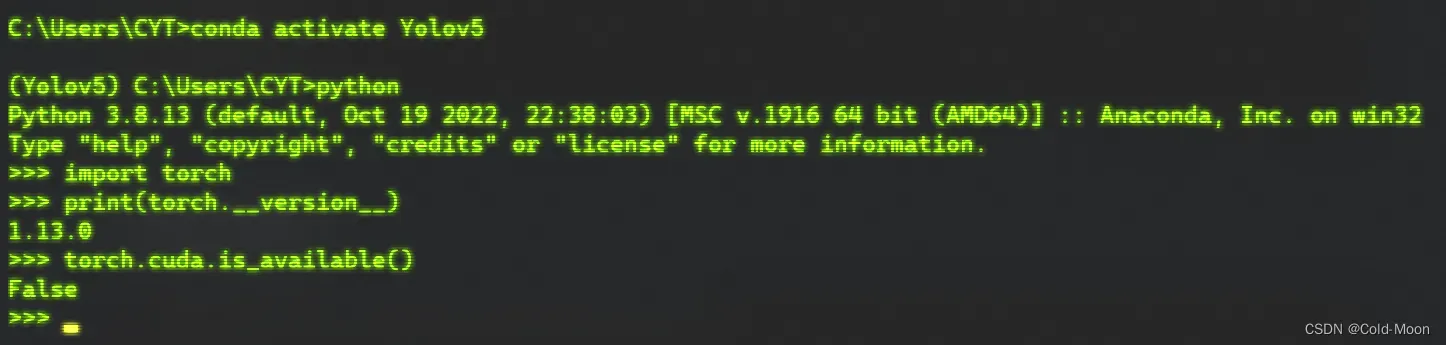
1.3. Yolov5源码下载
- Github下载地址:
https://github.com/ultralytics/yolov5 - 如果访问慢,可以访问国内的Gitee,同步更新Github上的源码:
https://gitee.com/monkeycc/yolov5 - 我下载的是yolov5_v6.2版本,下载后,打开yolov5的目录
- 在conda终端(建议单独创一个训练Yolo的虚拟环境),例如,我这里创建了一个名为Yolov5的虚拟环境,在这个环境下,安装Yolov5的
requirements.txt中的包 - 前面已安装好Pytorch,安装
requirements.txt中的包时会自动检测,只要满足Yolov5的配置需求,就不会再下载Pytorch了(当然,前面下载Pytorch时,也应该放在同一个虚拟环境)
1.4.下载Yolov5的权重文件
- 下载地址:
https://github.com/ultralytics/yolov5/releases - 训练速度:n>s>m>l>x,速度快,意味着精度低,但一般使用s就行了
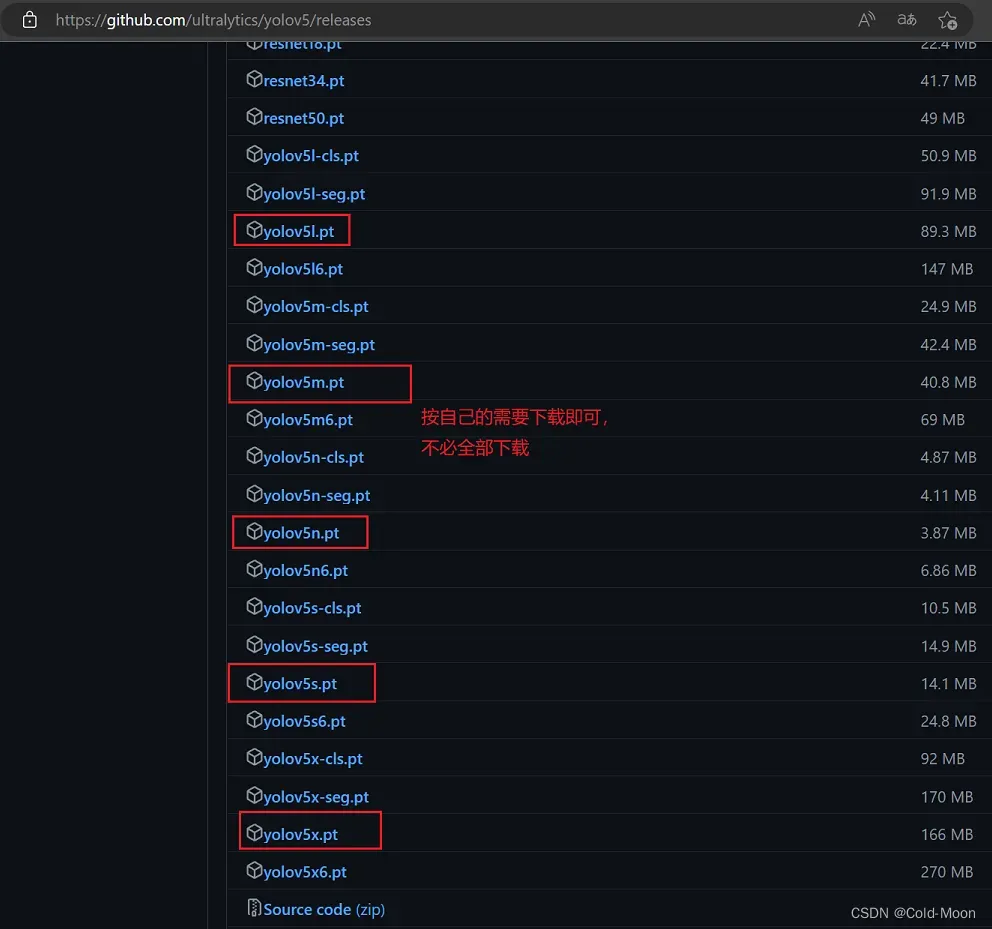
- 下载后的
.pt权重文件可以直接放在yolov5的根目录下,也可以在yolov5的根目录下新建一个weights文件夹,把权重文件放到里面
2.在Pycharm中初步调试运行yolov5
2.1.Pycharm配置conda虚拟环境
- 在Pycharm中打开yolov5文件夹,并配置好你之前创建的用于yolov5的虚拟环境
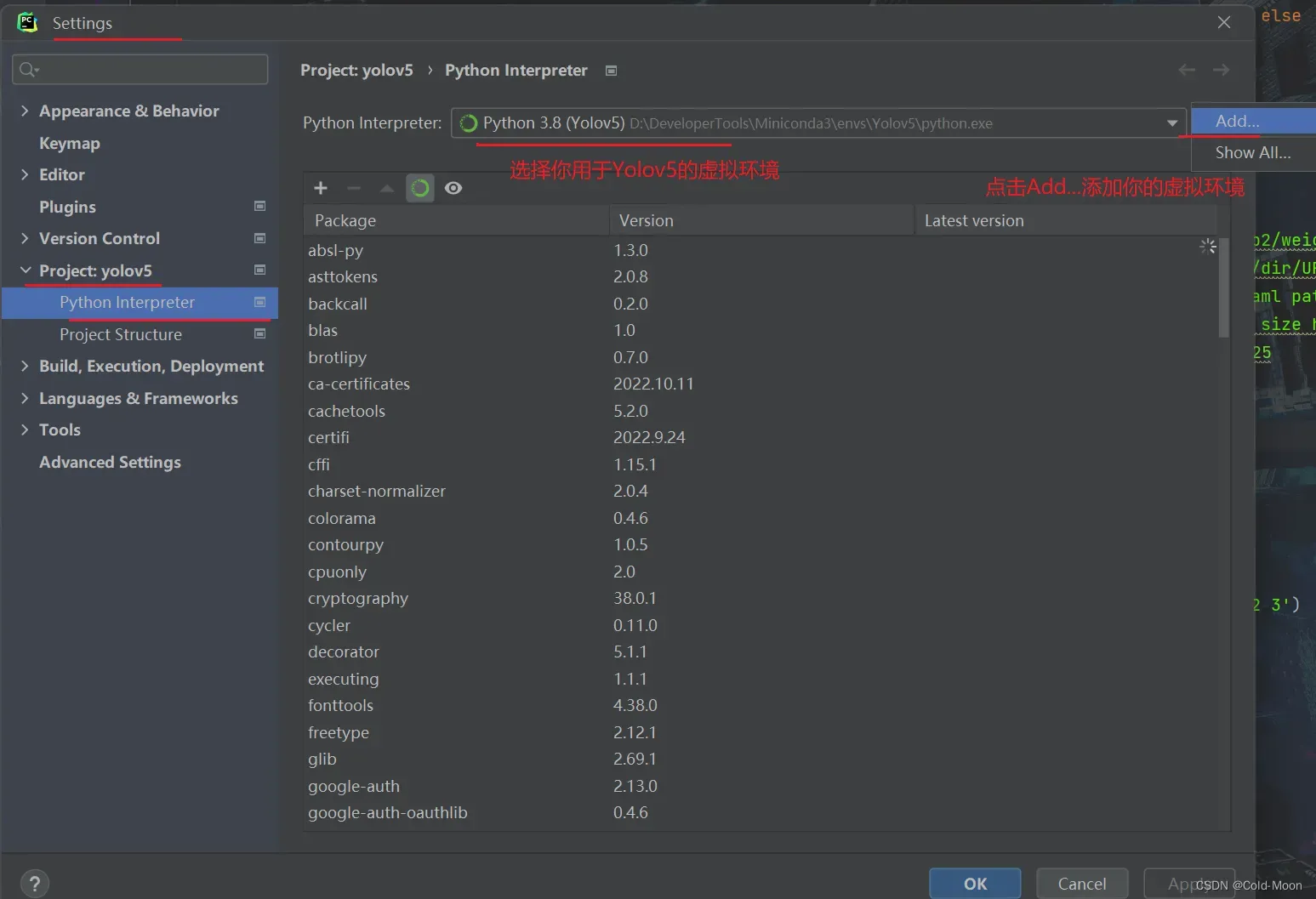
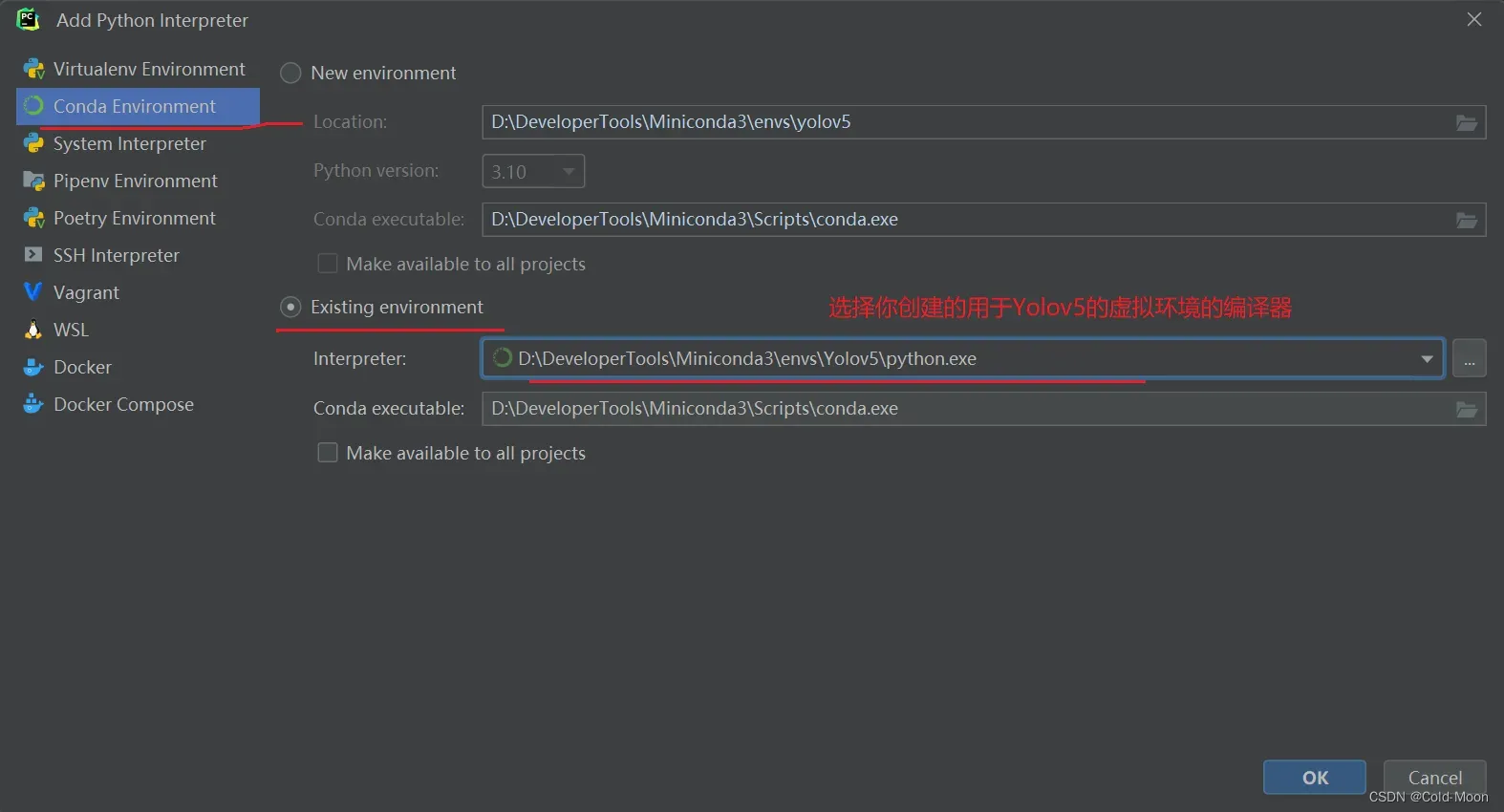
2.2. 运行yolov5根目录下的detect.py
- 运行yolov5根目录下的
detect.py,看能否正常运行(这个就是预测/目标检测,在官方下载的yolov5中,已经配置好了示例用的参数,配置好环境后,就可以直接运行)
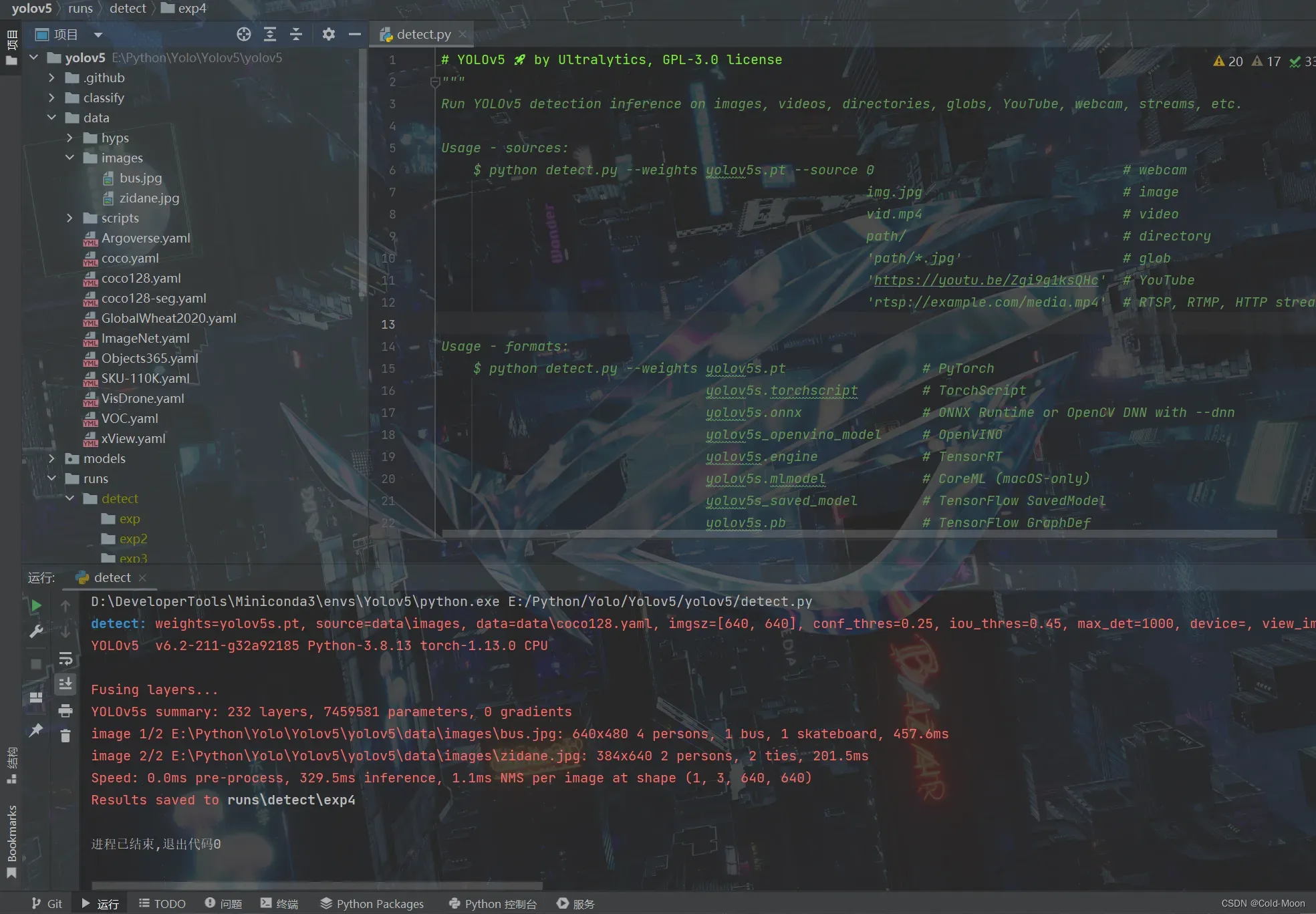
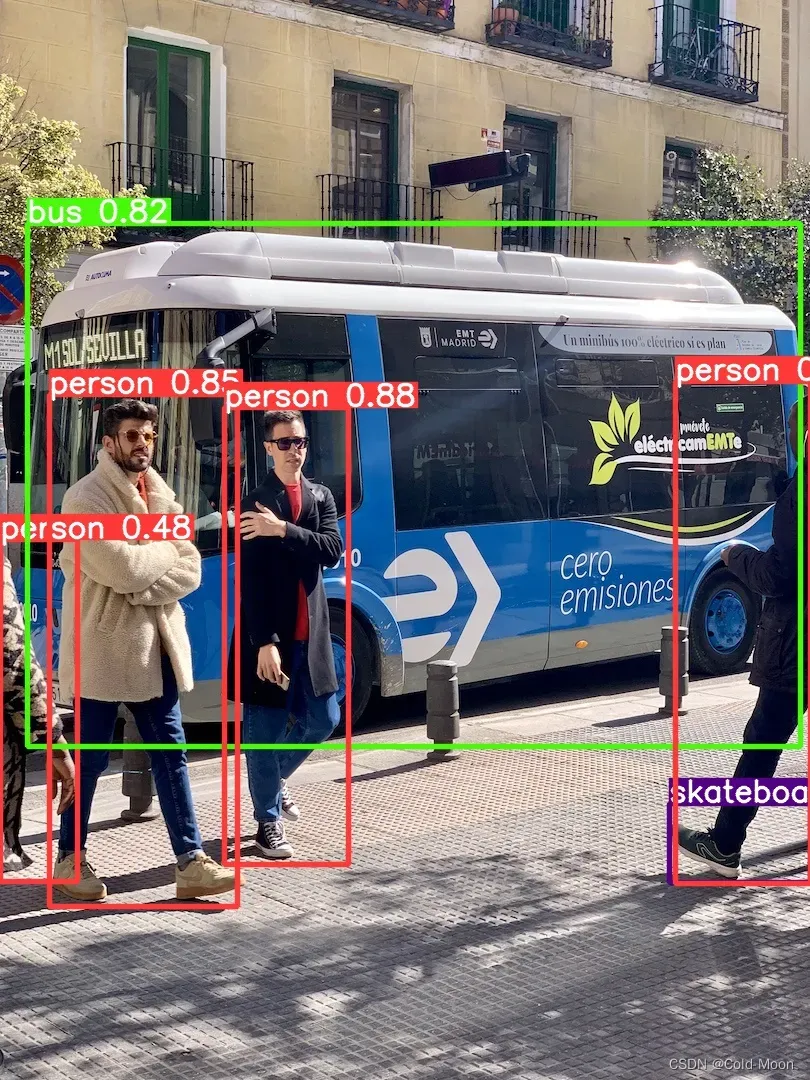
-
这样就是运行成功,结果保存在
run\detect\exp4目录中,预测结果如下:

-
也可以在终端中运行
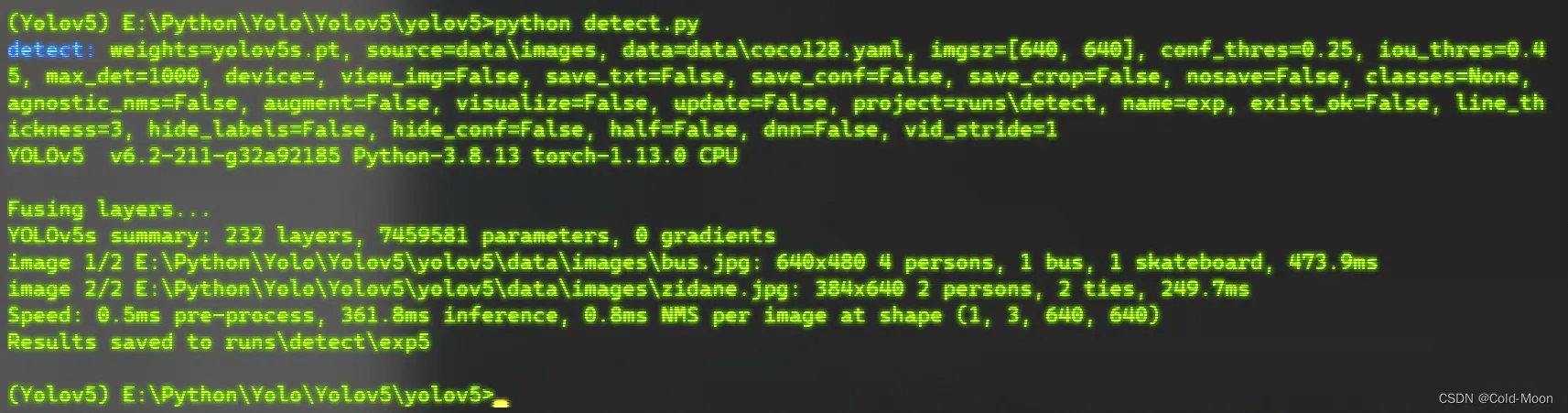
2.3.可能遇到的问题
- 抛异常:
AttributeError: 'Detect' object has no attribute 'm' - 解决:参考博客:
https://blog.csdn.net/Joseph__Lagrange/article/details/108255992 - 建议使用官网上的每个版本对应权重文件
3.训练自己的数据集
- 由于我的电脑没有独立显卡,所以我就不在本地进行训练了,后面介绍使用云服务器进行训练
- 但在训练我们自己的数据集之前,我们需要对进行训练的图片进行类别标注
- 如果你使用官网或其他人的已经标注好的数据集(例如:yolov5中已经配置好模型,参数的COCO128数据集),则可以直接配置参数后进行训练,不需要自己标注训练用的图片
3.1.图片类别标注
- 标注工具有很多,这里我使用
Labellmg,方便操作,且可以直接保存为适用于yolo的.txt格式,省去了格式转换的麻烦
3.1.1.Labellmg安装
- 官网下载地址:
https://github.com/heartexlabs/labelImg - 安装方式,以官网给出的
Windows + Anaconda方式为例- 下载
labellmg的code压缩包,或使用git方式克隆到本地 - 使用
Anaconda Prompt进入下载的labellmg文件夹
- 下载

#安装配置相关环境
conda install pyqt=5
conda install -c anaconda lxml
pyrcc5 -o libs/resources.py resources.qrc
#启动labellmg
python labelImg.py
#指定参数启动labellmg
python labelImg.py [IMAGE_PATH] [PRE-DEFINED CLASS FILE]
- 每次启动都需要到你的
Labellmg的目录下启动,例如我这里放在D:\DeveloperTools\labelImg目录,启动界面如下
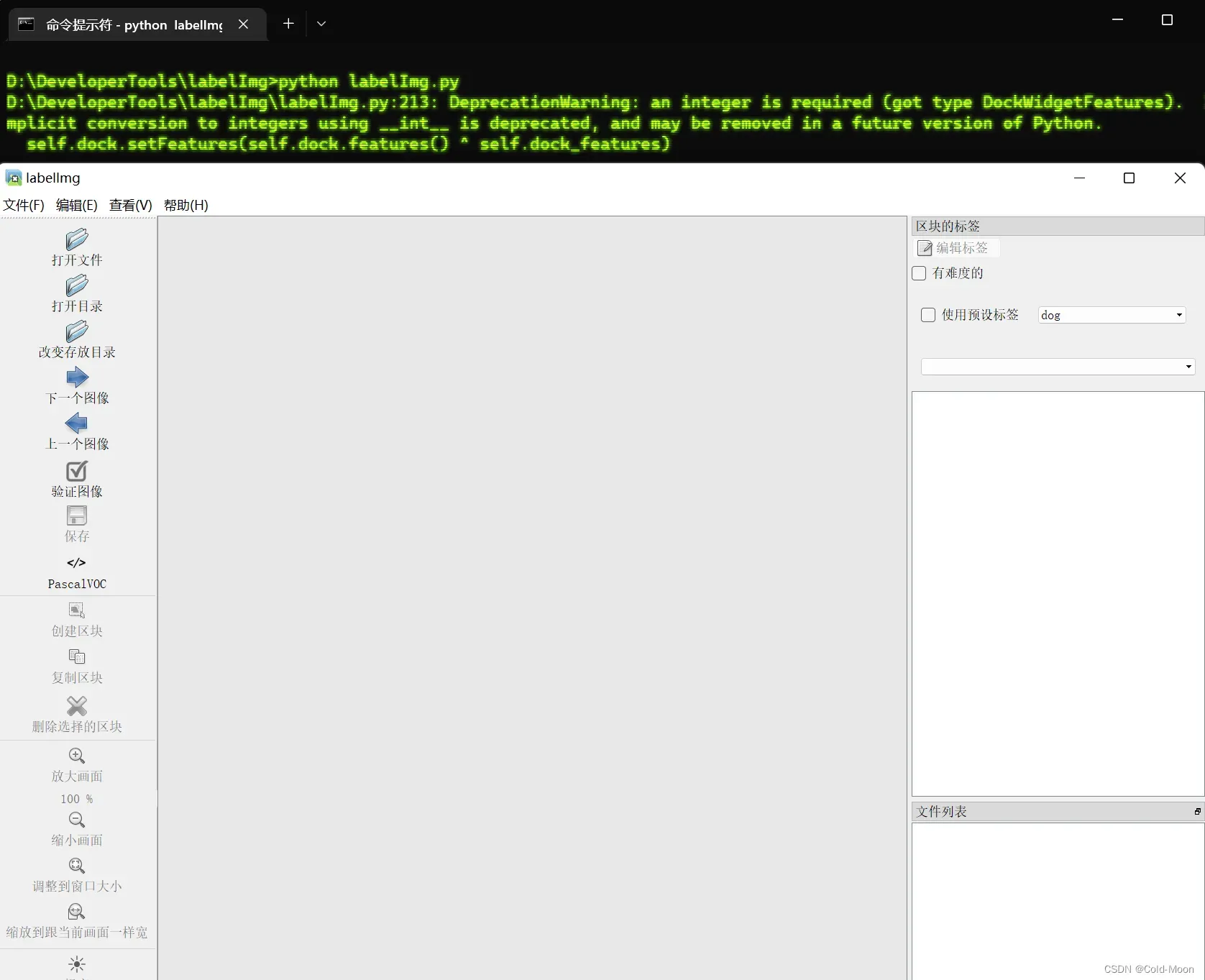
- 安装可能遇到的问题
# (1).出现:‘pyrcc5‘ 不是内部或外部命令,也不是可运行的程序 或批处理文件。
# 解决:直接使用Anaconda/Minconda的默认(base)环境安装即可,不要用自己另外创建的虚拟环境
#(2).出现:EnvironmentNotWritableError: The current user does not have write permissions to the target environm 当前用户没有对目标环境的写入权限
#解决:以管理员身份运行cmd或Anaconda Prompt即可
3.1.2.Labellmg使用
-
使用前的一个注意点
-
在
labellmg\data目录下,存在一个predefined_classes.txt文件

-
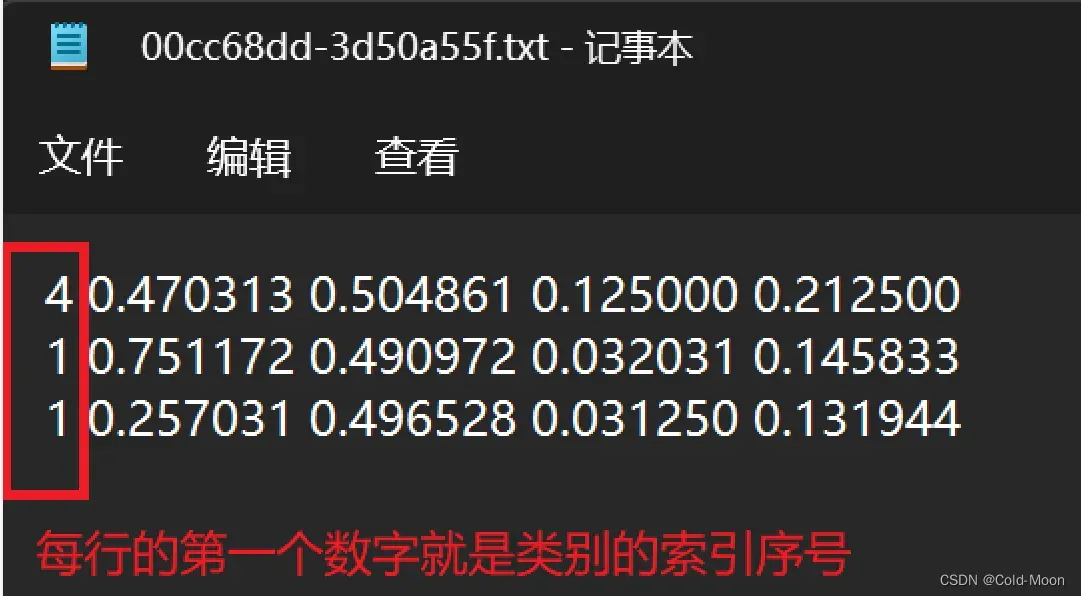
predefined_classes.txt文件内存在一些预设的标注类型,有15个,索引从0开始,[0,14]
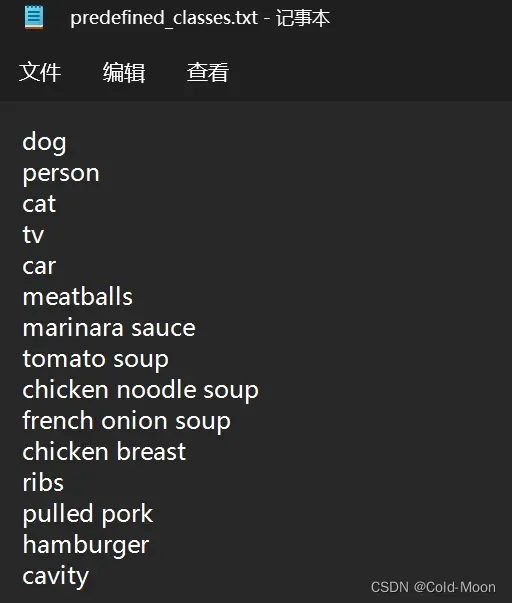
-
需要注意,如果你用不到这么多类型,则因该启动
labellmg之前就因该把这些预设删除,或替换为自己需要的标注类型名称,这些名称的顺序 必须和 你自己训练数据时的xxx.yaml文件中标注的类型一致,且顺序一致,索引从0开始,如果不一致,可能存在问题 -
例如,后面我这里才发现我只需要两个类别,但最开始是有15个类别的
-
主要的原因就是我的两个类别的顺序索引和
labellmg生成的标签顺序索引不一致,现在只能手动修改.txt中的索引了,所以建议一开始就指明自己需要哪些标签类别
-
-
Labellmg使用
- Labellmg的特点是可以自己选择标注的保存类型,而labelme是没有的。
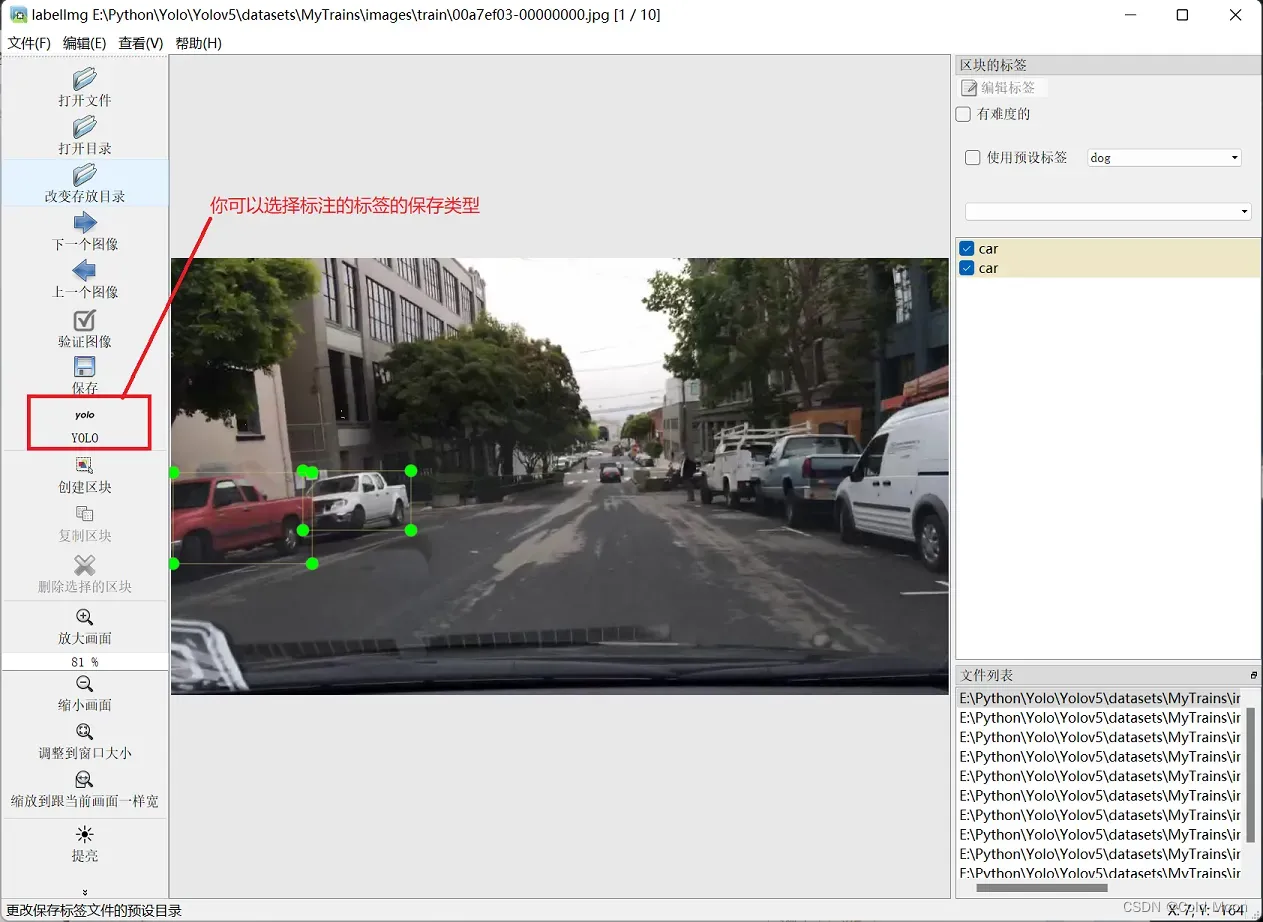
- Labellmg的特点是可以自己选择标注的保存类型,而labelme是没有的。
- 使用时的一些设置
-
设置标注的标签的保存路径(文件夹)
-
设置自动保存
-
快捷键:
A:上一张图,B:下一张图,W:创建区块(手动标注) -
标注时是鼠标选择一个起点后点击,按住鼠标左键拖动,画一个矩形框。
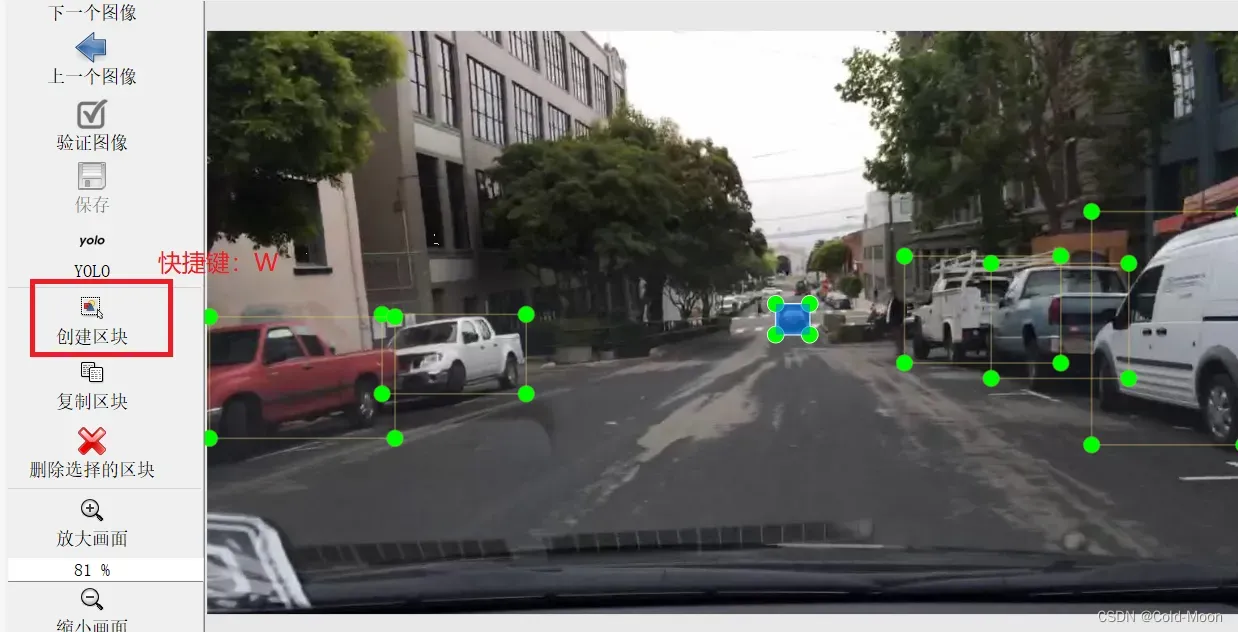
-
最终结果:一张图片对应一个txt文件
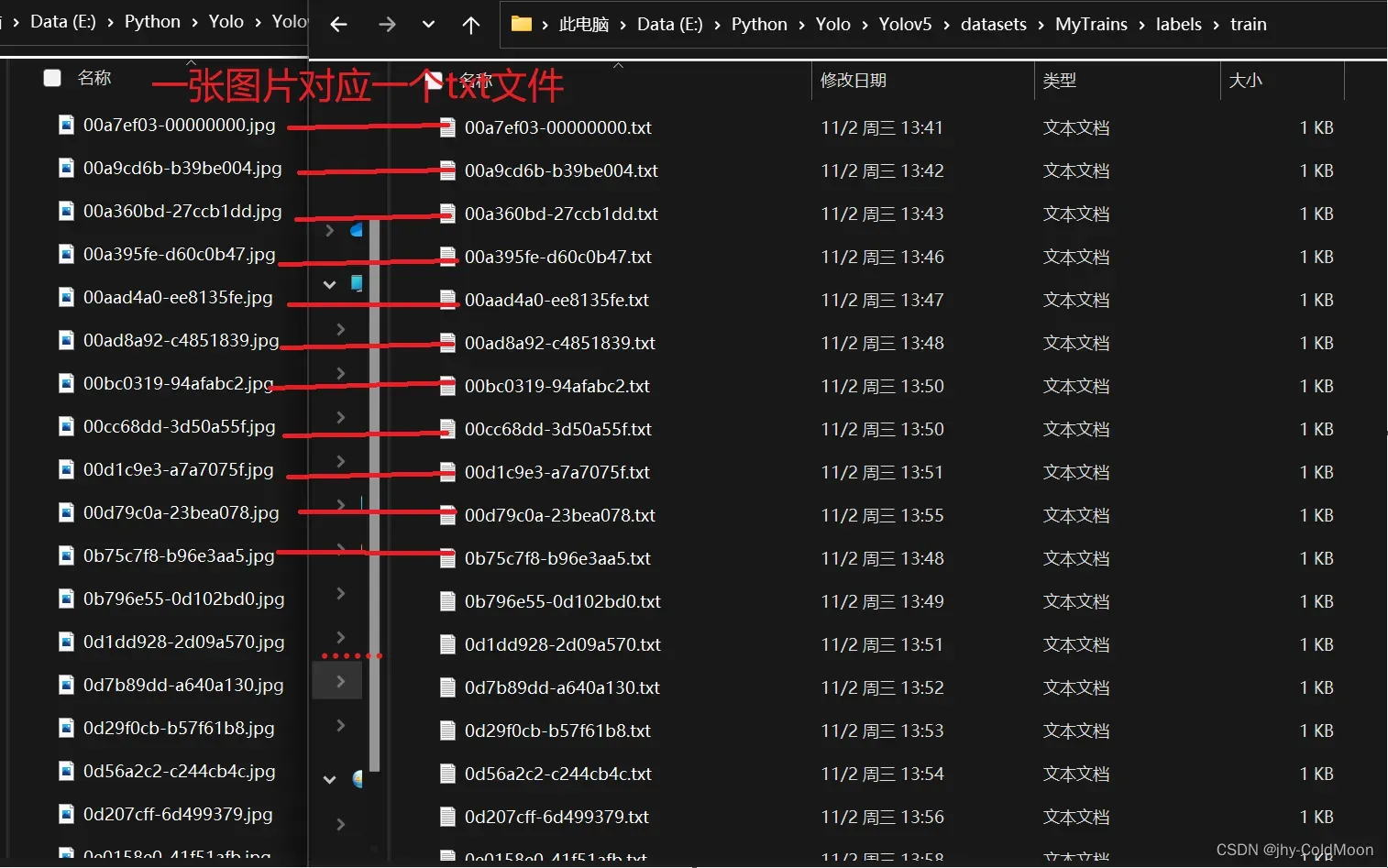
-
3.2.train.py和detect.py参数了解
- 参考视频:
https://www.bilibili.com/video/BV1tf4y1t7ru/?spm_id_from=333.999.0.0&vd_source=45352058e2e0900c3d75ba93406d8fdb - 以下是观看视频时做的笔记,可能有失偏颇,仅供参考,详细的可以去看原视频
3.2.1.detect.py文件部分参数
# default是默认,action是选择。需要的话自己配置参数
*******************************下面是有default值的参数*************************************
#有default值的参数,你不设置值,就会使用作者给你配好的默认参数值
1.'--weight' 权重
default 'yolo5s.pt'表示默认选择'yolo5s.pt'文件进行训练,也可以改为其他的权重文件。
例如'yolo5l.pt','yolo5m.pt','yolo5x.pt'
2.'--source' 数据源
2.1.default 'data/images'存放目标检测文件的文件夹,在/images文件夹中可以存放图片/视频(图片推荐.jpg,视频推荐.mp4格式),同时建议只放同一类的文件类型,比如只放图片,或只放视频。
2.2.手机下载ip摄像头,路径改为http://admin:admin@手机上打开之后显示的ip地址,就可以实时检测
电脑要和他在同一WiFi下,ip地址:后面的也写
3.'--data'
default 'data/coco128.yaml' 默认使用官方yaml文件
4.'--imgsz' 图片尺寸大小
default=[640] 默认检测时设置图片尺寸为640,这个和图片本身的尺寸不想关,并不是说会把目标图片的大小或输出的图片大小改为设置的大小,而是在检测图片时,会等比例缩放为指定尺寸,这样比较节约算力资源,如果按照图片原本的尺寸去检测,如果原本的图片尺寸很大,则需要更多的算力与时间去检测。但缩放图片比例去检测也意味着检测精度的损失。
5.'--conf-thres' 检测阈值
default=0.25 默认为0.25 检测阈值设置越低,则检测到的物体越多,但检测精度也越低。在检测结果中,图片上会标出检测到的物体有多少的概率是什么已知的物体。比如:阈值设置越低,则可能将"猫"检测标识为"狗"。反之,阈值设置得越高,则检测精度越高,但检测到的物体可能就很少,有时可能检测不到物体。
6.'--iou-thres' 一般默认(NMS IoU threshold(阈值))
default=0.45,数值越大,则检测结果中每个目标的标注会很多(原理就是值越大,就代表检测的块必须完全一致才算同一部份,否则就会算多个不同的部分),反之,数值越小,则检测结果中每个目标标注就会较少,因为会把相似的部分当作同一个部分来标注。
7.'--max-det'
8.'--device'设备
默认为空,会自动检测使用的设备,比如CPU,cuda等
*******************************下面是没有default值的参数*************************************
#没有default值的参数,不是需要设置什么,而是用户自己选择是否启用,默认为false,关闭状态。如果用户要启用这些功能,只需要在运行时添加对应的参数(即设置为true)即可,运行时,会自动检测,检测到对应的参数为true,就会启用对应的功能。
#比如在命令行中运行'detect.py'且实时显示结果:
> python detect.py --view-img
9.'--view-img'实时显示结果
运行过程中,会实时显示检测出的结果,如果是图片,则每张每张的显示结果(注:如果检测很多张图片,不要设置这个参数,否则会把每一张图片都挨个显示出来),如果是视频,则以视频形式实时播放检测结果(如果电脑卡,那就是一帧一帧的播放,所以也不太建议设置这个参数)
10.'--save-txt'保存检测结果中的标注的坐标
保存结果为'.txt'文件类型,结果中会多一个'./labels/'文件夹,保存了生成的'.txt'文件
11.'--save-conf' 保存置信度
12.'--save-crop' 保存裁剪的预测框
13.'--nosave' 不保存检测结果的图片/视频
14.'--classes'过滤(可用于只保留指定的类型)
在检测中的'.txt'文件中,保存了检测目标的 类别(用不同的数字表示不同的类别),还有坐标信息(x,y,w,h)
例如:--classes 0 只保留0这个类别的文件
--classes 0 2 3 只保留0,2,3这三个类别的文件
例如:".txt"文件中,人这个类别用'0'表示,如果设置参数--classes 0 ,则结果图片中只会检测人这个类别,即使图片中有车,信号,动物等,都不会检测。
15.'--agnostic-nms' 增强nms效果
16.'--augment' 增强检测(识别度可能会有提升,但也有翻车的(把狗识别为人),结果中标注框的颜色会加深一些)
17.'--visualize' 可视化特征
18.'--update' 优化
设置之后,会将运行过程中没用到的部分设置为None,只保存用到的部分
*******************************下面是有default值的参数*************************************
19.'--project' 检测结果保存的路径
default=ROOT / 'runs/detect' 即默认保存到项目下的'runs/detect/'文件夹
20.'--name' 检测结果保存到的文件夹的名称
default='exp' 所以每次运行后,保存结果的文件夹都叫'exp...'
*******************************下面是没有default值的参数*************************************
21.'--exist-ok' 对于已存在的文件夹是否覆盖
默认为false,即:如果已存在'--name'参数指定的文件夹'exp',则创建新的文件夹保存结果,例如'exp2'。
同理,如果'exp2'也存在,就继续增加数字,例如'exp3',直到不存在同名的文件夹
如果用户设置了这个参数,则表示,始终把检测结果保存到'--name'参数指定的文件夹'exp'中,即使'exp'文件夹存在,里面有文件,也会保存到这里面。
*******************************下面是有default值的参数*************************************
22.'--line-thickness' 官方解释:help='bounding box thickness (pixels)' 边界框厚度(像素)
default=3
23.'--hide-labels' 官方解释:help='hide labels' 隐藏标签
default=False
24.'--hide-conf' 官方解释:help='hide confidences' 隐藏置信度
*******************************下面是没有default值的参数*************************************
25.'--half' 官方解释:help='use FP16 half-precision inference' 使用FP16半精确推理
26.'--dnn' 官方解释:help='use OpenCV DNN for ONNX inference' 使用OpenCV DNN进行ONNX推理
*******************************下面是有default值的参数*************************************
27.'--vid-stride' 官方解释:help='video frame-rate stride' 视频帧速率步幅
default=1,即默认一帧一帧的处理
- Pycharm中设置运行
detect.py时的参数 - 在命令行中加入参数,就是加在
python detect.py的后面,例如python detect.py --view-img
- 参数中设置外部图片文件夹
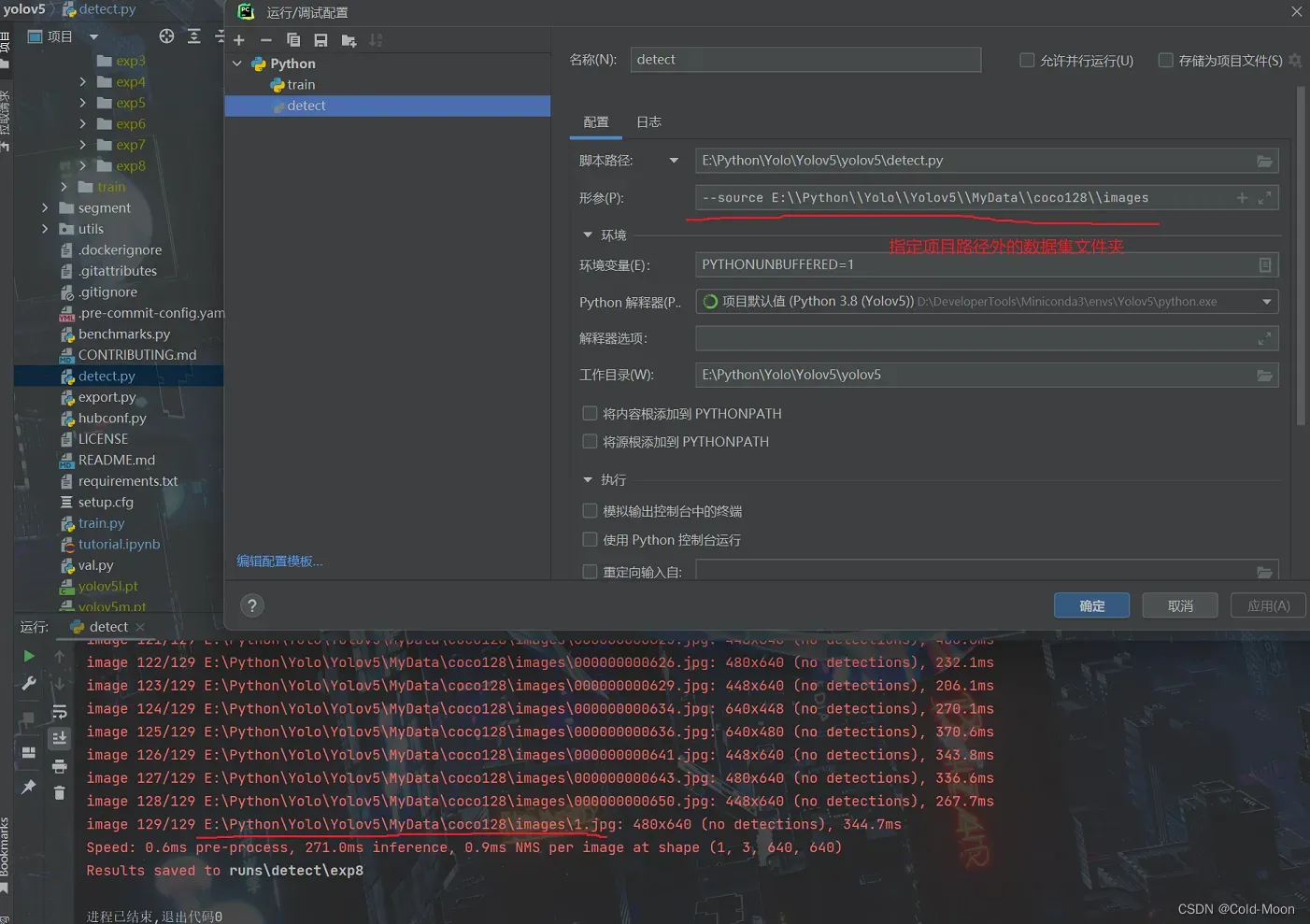
- 设置外部视频文件
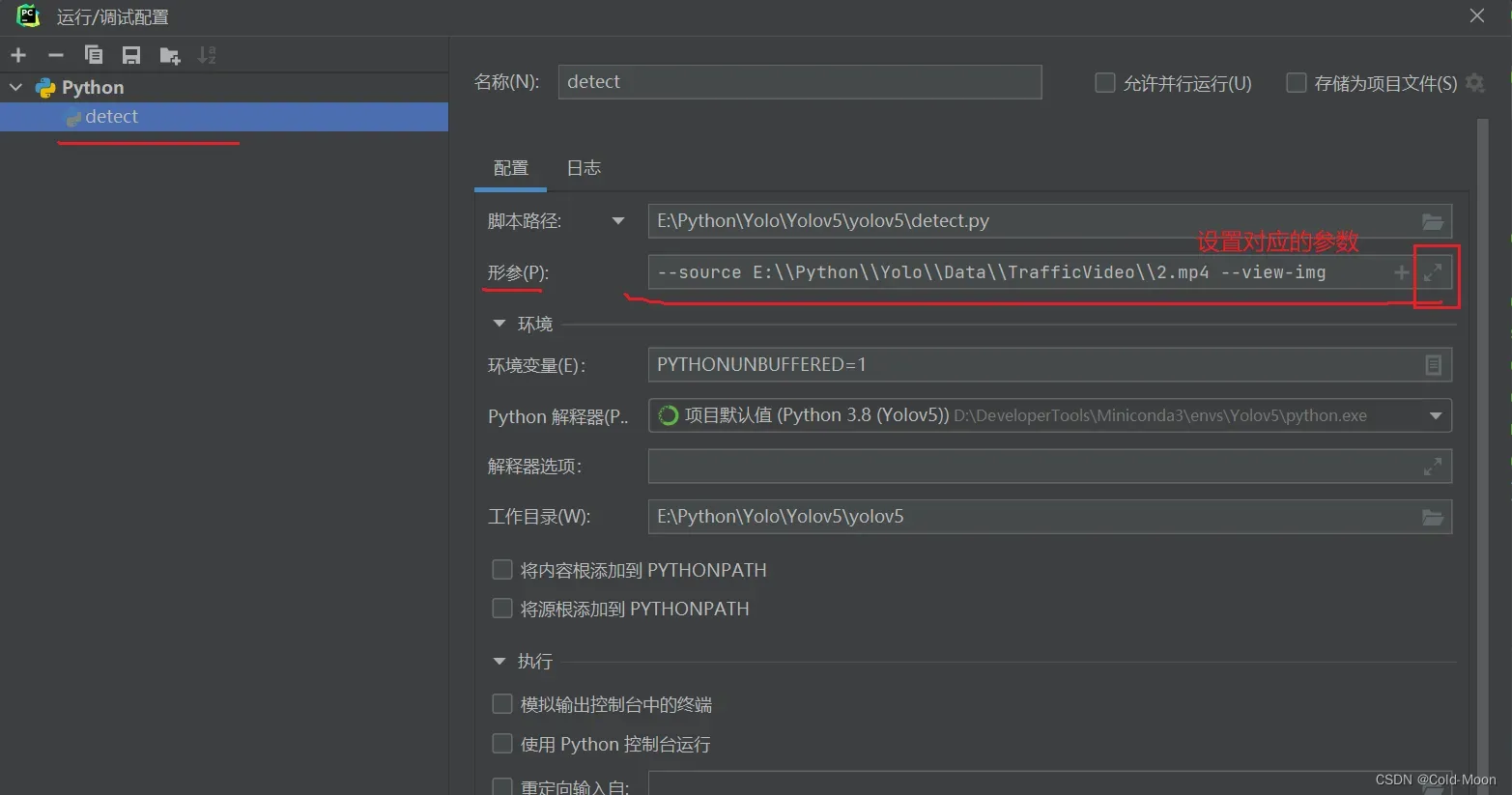
3.2.2.train.py文件部分参数

# default是默认,action是选择。需要的话自己配置参数
*******************************下面是有default值的参数*************************************
#有default值的参数,你不设置值,就会使用作者给你配好的默认参数值
1.'--weights'
default='yolov5s.pt' 默认使用'yolov5s.pt'权重文件进行训练。也可以改为其他的权重文件。
例如'yolo5l.pt','yolo5m.pt','yolo5x.pt',当然你也可以使用其他训练好的权重文件。
如果是自己训练数据集,则可以设置空参(即:default=''),让程序来生成权重文件。
2.'--cfg' 训练用的模型文件
default='' 默认为空,可以自己添加,例如使用官方的模型,在项目的'/models/'文件夹下
官方的有:'yolov5l.yaml','yolov5m.yaml','yolov5n.yaml','yolov5s.yaml','yolov5x.yaml'模型
3.'--data' 指定训练用的数据集
default='data/coco128.yaml' 默认使用官方的数据集图片(coco128即coco数据集的前128张图片,因为完整的coco数据集图片很多),打开'data/coco128.yaml'文件,可以发现其中指定的内容:
如果在本地项目中没有找到coco128数据集,则会自动下载,但由于有些电脑可能自动下载失败,可以复制给出的下载链接,手动去下载。download: https://ultralytics.com/assets/coco128.zip
'coco128.yaml'中还指定了数据集的路径:path,train(训练集),val(验证集),test(测试集)的路径。
其中 #Classes表示类别,names总共有80个,表示分了80个类别
当然,也可以使用其他的数据集,例如'coco.yaml','VOC.yaml'等官方提供的,或是别人的。
4.'--hpy' 超参数,用于对项目进行微调
default='data/hyps/hyp.scratch-low.yaml' 需要指定文件路径
需要注意:官方的'data/hyps/'文件夹下的'.yaml'文件并不适合每个数据集,例如'hyp.scratch-low.yaml'的开头几行就标明了:# Hyperparameters for low-augmentation COCO training from scratch #用于从无到有的低增强COCO训练的超参数,即这个超参数文件只适用于COCO数据集进行训练
5.'--epochs' 训练几轮
default=300,默认为训练300轮
6.'--batch-size' 批量大小(一次训练多少张图片)(一次处理的数据量多少)
default=16,跑多少的数据打包成一个batch送到网络中,低配电脑建议调小,否则可能会爆显存
建议default=4
7.'--imgsz' 设置训练时图像的大小(不是把训练的图片的尺寸改为指定的尺寸)
default=640
*******************************下面是没有default值的参数*************************************
8.'--rect' 矩阵训练
以前,对于不是正方形的图片,会自动填充图片边缘使其成为一个正方形图片,现在用矩阵训练,在满足网络模型输入要求的时候,就可以不必填充,原来是一个长方形图片,还是按长方形算,减少不必要的冗余信息,提高处理效率。
9.'--resume' 从最近的(上一个)训练模型中继续训练(断点续训)
default=False
如果要使用,除了启用设置参数,还需要指定上一个训练模型的路径(.pt文件的路径)
将default=False改为default='权重.pt文件的路径'
断点续训,这个在epoch(训练次数)太多,训练容易卡死时可设置,这样就可以接着上一次中断的地方继续训练。
例如:上一次训练到第7轮时中断了,则可以设置这个参数,这样就可以从第7轮继续训练。
但需要注意,不是指定了一个.pt文件就可以了,还需要原来训练时的所有相关联的文件。
10.'--nosave' help='only save final checkpoint'只保存最后一次训练的权重文件
训练过程中,每一轮都会生成一个.pt权重文件,但训练次数越多,权重文件的精度越好。
11.'--noval' help='only validate final epoch' 仅验证最后一轮
一般是每一轮都会验证。有些版本的这个参数叫'--notest'
12.'--noautoanchor' help='disable AutoAnchor' 禁用自动定位(禁用锚点)
以前检测图像,需要一个一个遍历,有了锚点后,就能快速定位,减少资源占用。所以默认是开启锚点的
13.'--noplots' help='save no plot files'不保存打印文件
14.'--evolve' help='evolve hyperparameters for x generations'
调整超参数的一种方式,对参数进行遗传算法
15.'--bucket' help='gsutil bucket'
16.'--cache' 缓存图像
help='--cache images in "ram" (default) or "disk"' 在RAM或DISK(磁盘)中缓存图像,以提供更快的速度
默认关闭状态
17.'--image-weights' help='use weighted image selection for training' 使用加权图像选择进行训练
理解:在上一轮的测试中,对于某些效果不太好的图片,在下一轮测试中加一些权重
18.'--device' 设备
默认为空,会自动检测使用的设备,比如CPU,cuda等
19.'--multi-scale' 对图像进行缩放比例变换
20.'--single-cls' help='train multi-class data as single-class'训练的数据集是单类别还是多类别
数据集图像中,每一种物体定义为一个类别,例如:人、车、狗、猫......
21.'--optimizer' help='optimizer' 优化器
choices=['SGD', 'Adam', 'AdamW'], default='SGD' 官方提供了3种,默认为'SGD'
22.'--sync-bn' help='use SyncBatchNorm, only available in DDP mode'
仅对于那些有很多张显卡的电脑/服务器,可以适用DDP分布式训练
23.'--workers' help='max dataloader workers (per RANK in DDP mode)' 最大数据加载器工人数
对于DDP模式的参数设置
*******************************下面是有default值的参数*************************************
24.'--project' 训练数据集后的输出路径
default='runs/train'
25.'--name' 训练结果保存到的文件夹的名称
default='exp' 所以每次运行后,保存结果的文件夹都叫'exp...'
*******************************下面是没有default值的参数*************************************
26.'--exist-ok' 对于已存在的文件夹是否覆盖
默认为false,即:如果已存在'--name'参数指定的文件夹'exp',则创建新的文件夹保存结果,例如'exp2'。
同理,如果'exp2'也存在,就继续增加数字,例如'exp3',直到不存在同名的文件夹
如果用户设置了这个参数,则表示,始终把检测结果保存到'--name'参数指定的文件夹'exp'中,即使'exp'文件夹存在,里面有文件,也会保存到这里面。
27.'--quad' help='quad dataloader' 四数据加载器
实验性功能,可能效果会更好,但也不确定,有时也更差
28.'--cos-lr' help='cosine LR scheduler' 余弦调度
如果开启,适用余弦方式进行处理(余弦退火算法),如果没有开启则使用线性处理
*******************************下面是有default值的参数*************************************
29.'--lable-smoothing' elp='Label smoothing epsilon' 标签平滑
避免在一些分类算法中,一些过拟合的情况产生
default=0.0
30.'--patience' help='EarlyStopping patience (epochs without improvement)'
提前停止训练(每一轮没有变化)
default=100
31.'--freeze' help='Freeze layers: backbone=10, first3=0 1 2' 冻结层:主干=10,第一层=0 1 2
default=[0]
32.'--save-preiod' help='Save checkpoint every x epochs (disabled if < 1)'
每x轮保存日志,不过好像要装WandB这个插件(这个插件好像没什么用),装了之后才能设置
default=-1,即禁用,装了插件后启用,则将参数值改为>1的
33.'--seed' help='Global training seed' 全局训练传递
default=0
34.'--local_rank' help='Automatic DDP Multi-GPU argument, do not modify' 自动DDP多GPU参数,请勿修改
default=-1
-------------# Logger arguments 记录器参数------------------
35.'--entity' help='Entity'实体
default=None(好像这个功能还没实现,具体实现代码作者还没写)
36.'--upload_dataset' 上传数据集 help='Upload data, "val" option' 上传数据,“val”选项
default=False(好像这个功能还没实现,具体实现代码作者还没写)
37.'--bbox_interval' help='Set bounding-box image logging interval' 设置边界框图像记录间隔
default=-1(好像这个功能还没实现,具体实现代码作者还没写)
38.'--artifact_alias' help='Version of dataset artifact to use' 要使用的数据集工件版本
default='latest'(好像这个功能还没实现,具体实现代码作者还没写)
3.3.本地训练
- 由于我的电脑没有独立显卡,所以我就不在本地进行训练了,下面介绍使用云服务器进行训练
3.4.云端训练
-
这里我使用的是恒源云,也可使用阿里云、腾讯云等,随意。
-
恒源云官网:
https://www.gpushare.com -
访问官网,打开文档中心,可以自行学习如何操作
-
下面是我自己的操作,仅供参考
3.4.1.数据上传
-
第一步就可以先把自己的需要训练的数据上传,官方提供的OSS存储(云盘),好像是按时间收费的(不用的时候可以清空下空间)
-
上传个人数据时,数据量越大,上传时间越久(也取决于个人的网速),如果不需要的文件,可以不用上传
-
在用户文档的数据上传板块,官方提供了三种上传文件的方式
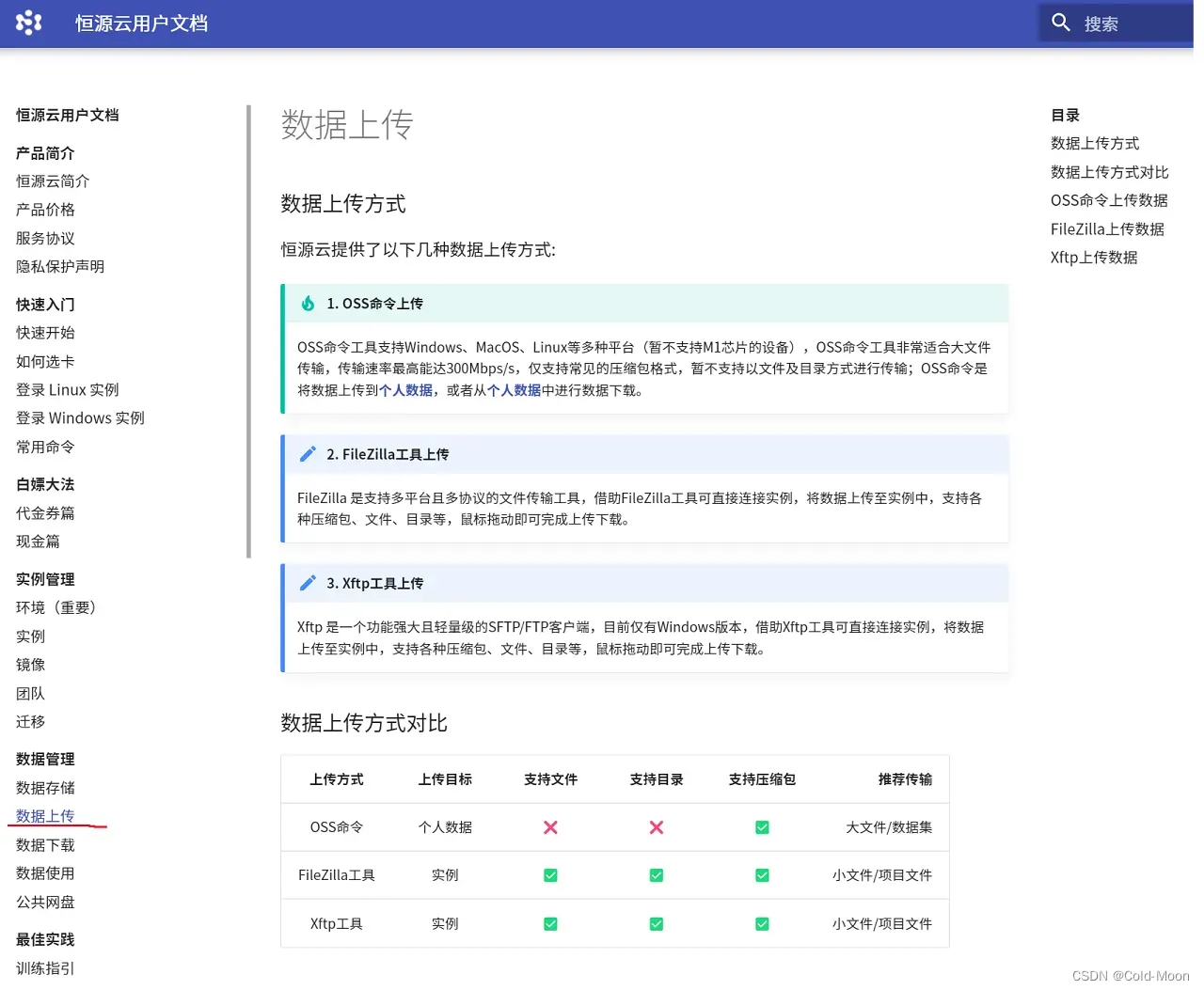
-
这里我选择使用官方提供的OSS工具,上传个人数据,OSS工具的下载安装,可在官网的用户文档中找到
-
下载后就是一个
oss.exe文件,不用安装,直接使用,建议直接复制到需要上传数据的文件夹 -
注意:OSS工具只能上传压缩包形式的文件!,所以先把要上传的数据压缩为
.zip文件格式
-
双击运行
oss.exe,启动界面如下
-
输入
login,登录,接着输入Username和Password,就是你注册/登录时的账号和密码
-
输入
mkdir oss://MyData,就会在官网上的属于你的OSS存储中创建一个MyData文件夹(可选)

-
上传你的训练数据到上面自己创建的文件夹中
-
这里以
test.zip为例,输入cp test.zip oss://MyData/即可上传文件到云端目录,上传的快慢和文件大小与自己的网速有关 -
注意:在本地上传数据期间,需要把网页端打开,可能是保持连接吧,否则可能会上传失败,但还好有断点续传
-
输入
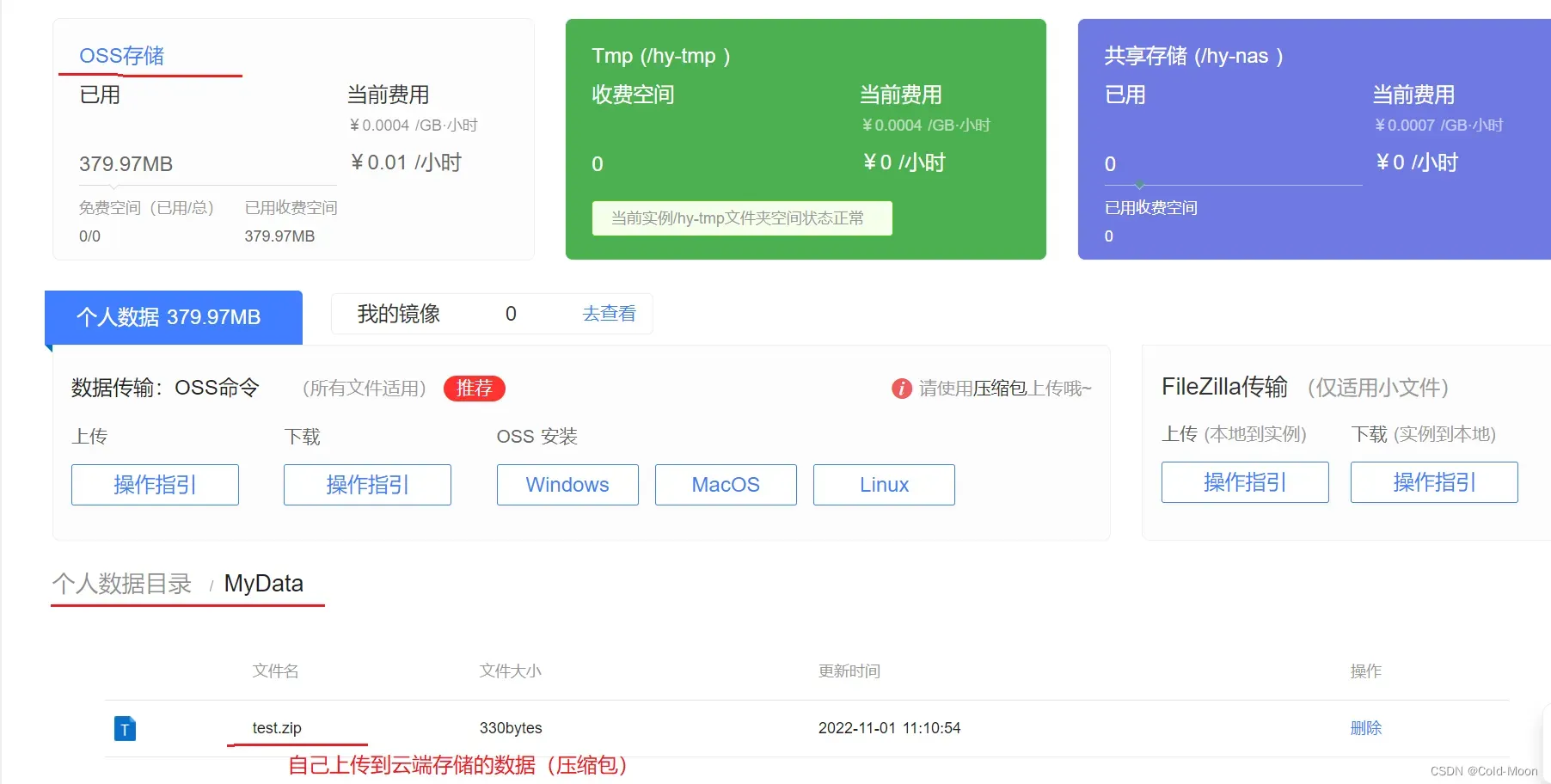
ls -s -d oss://MyData/查看自己上传的个人数据(压缩包)
-
也可以在云端的控制台查看到自己上传的文件
3.4.2.创建实例
-
在控制台,我的实例中,点击创建实例
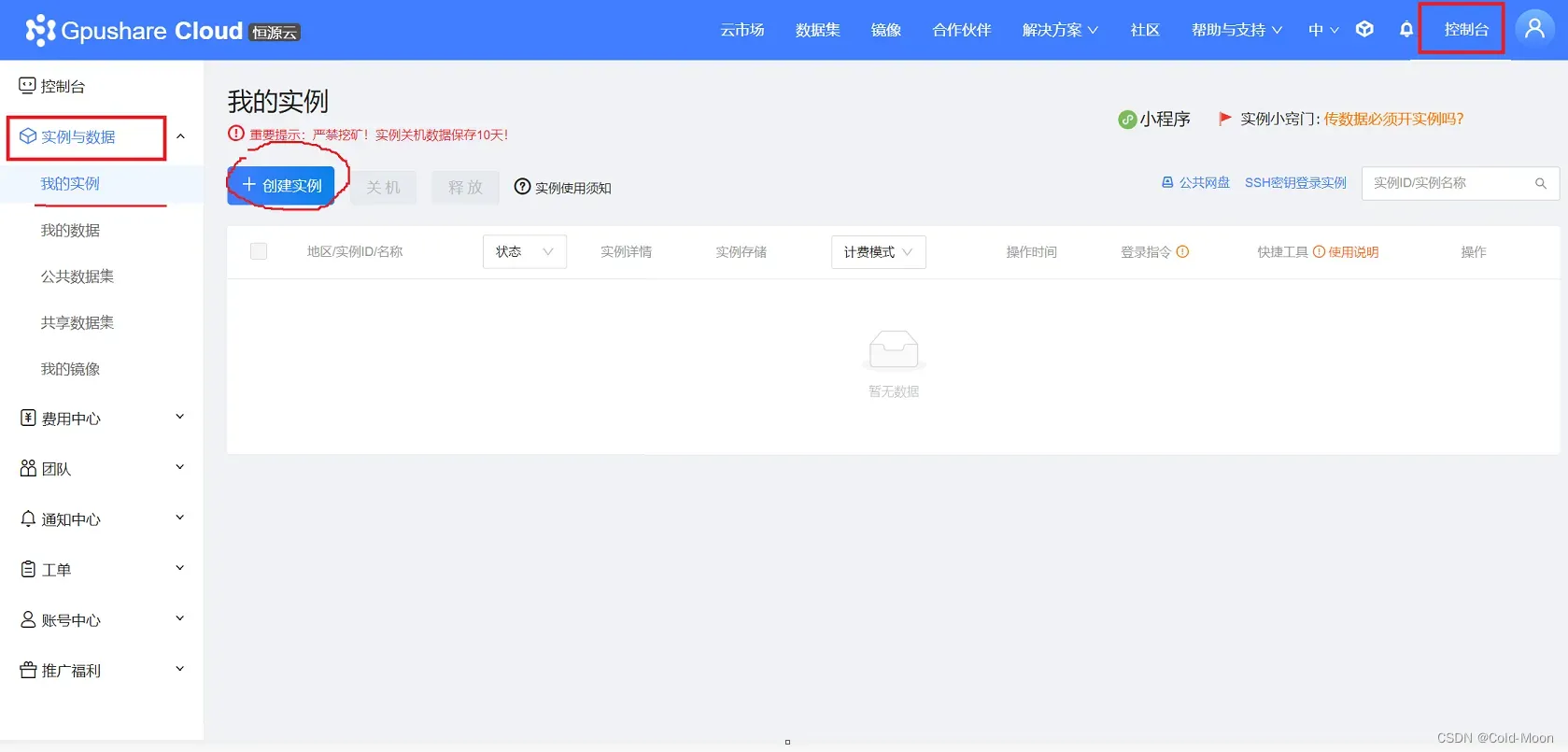
-
购买实例,选择自己需要的计费模式,机型,显卡
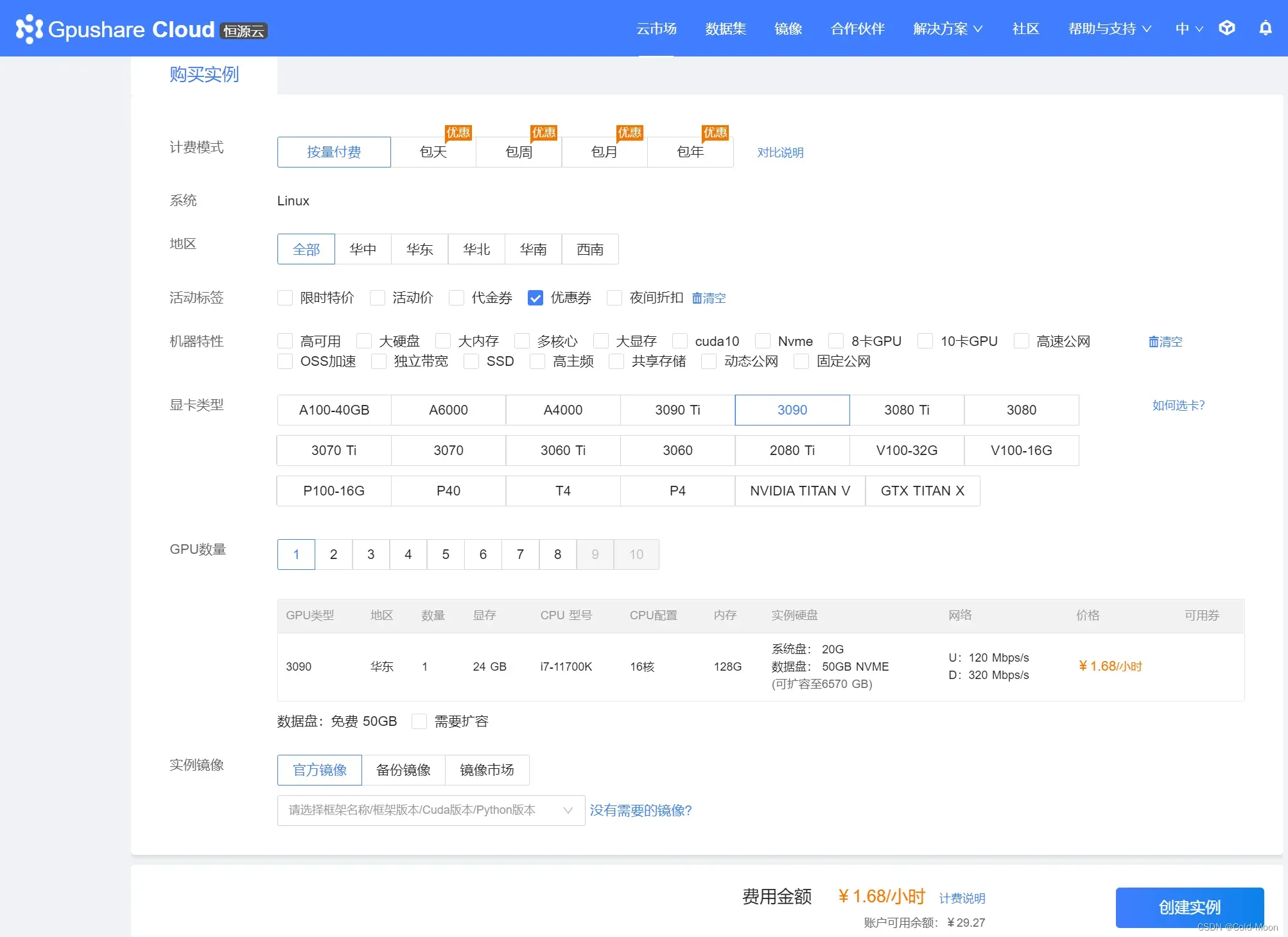
-
关于镜像选择
-
可以选择官方的镜像
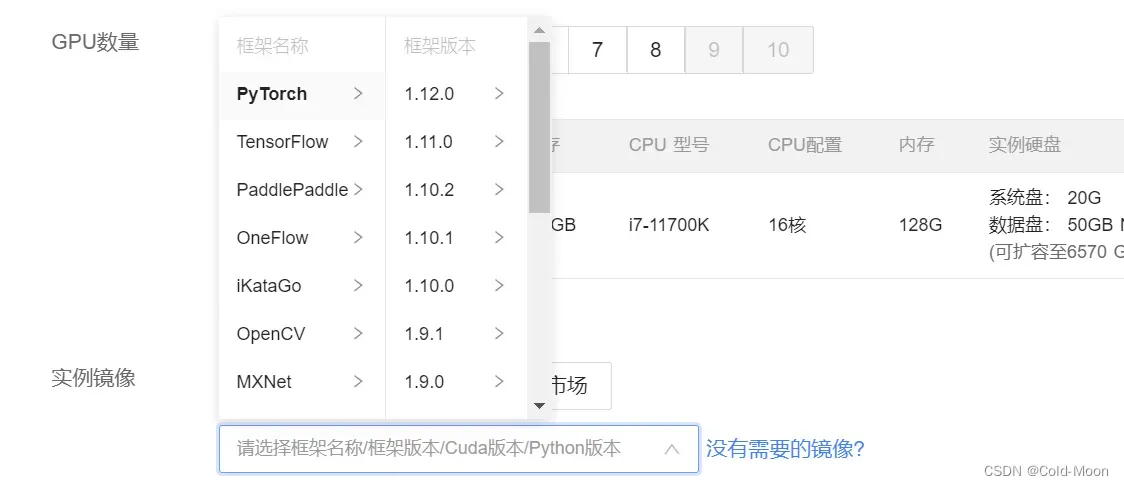
-
如果想图个方便,直接去镜像市场看看,有别人已经配置好的镜像,可以直接用(推荐)
-
关于镜像费用,购买镜像是不花钱,但购买了镜像,就相当于你把别人的镜像复制到了你的云空间,使用云空间是收费的,就是占用你的OSS存储空间,超过免费的5GB容量是另外收费的,不过也很便宜的。
-
也可以先在镜像中找一下,是否有自己需要的镜像
-
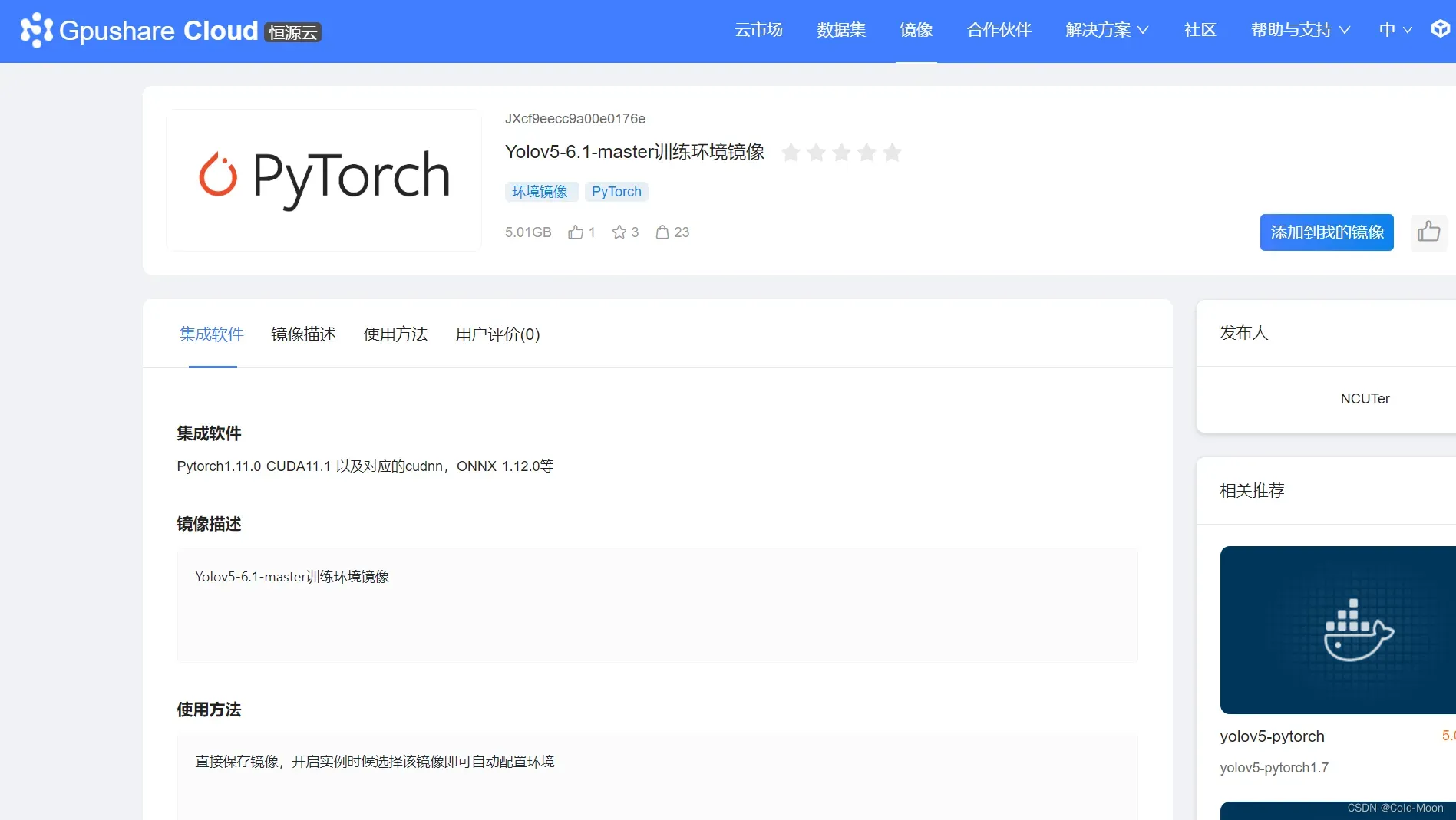
例如用于训练
Yolov5的镜像,点击添加到我的镜像,即添加进自己账户的OSS存储空间(按小时收费,也很便宜)
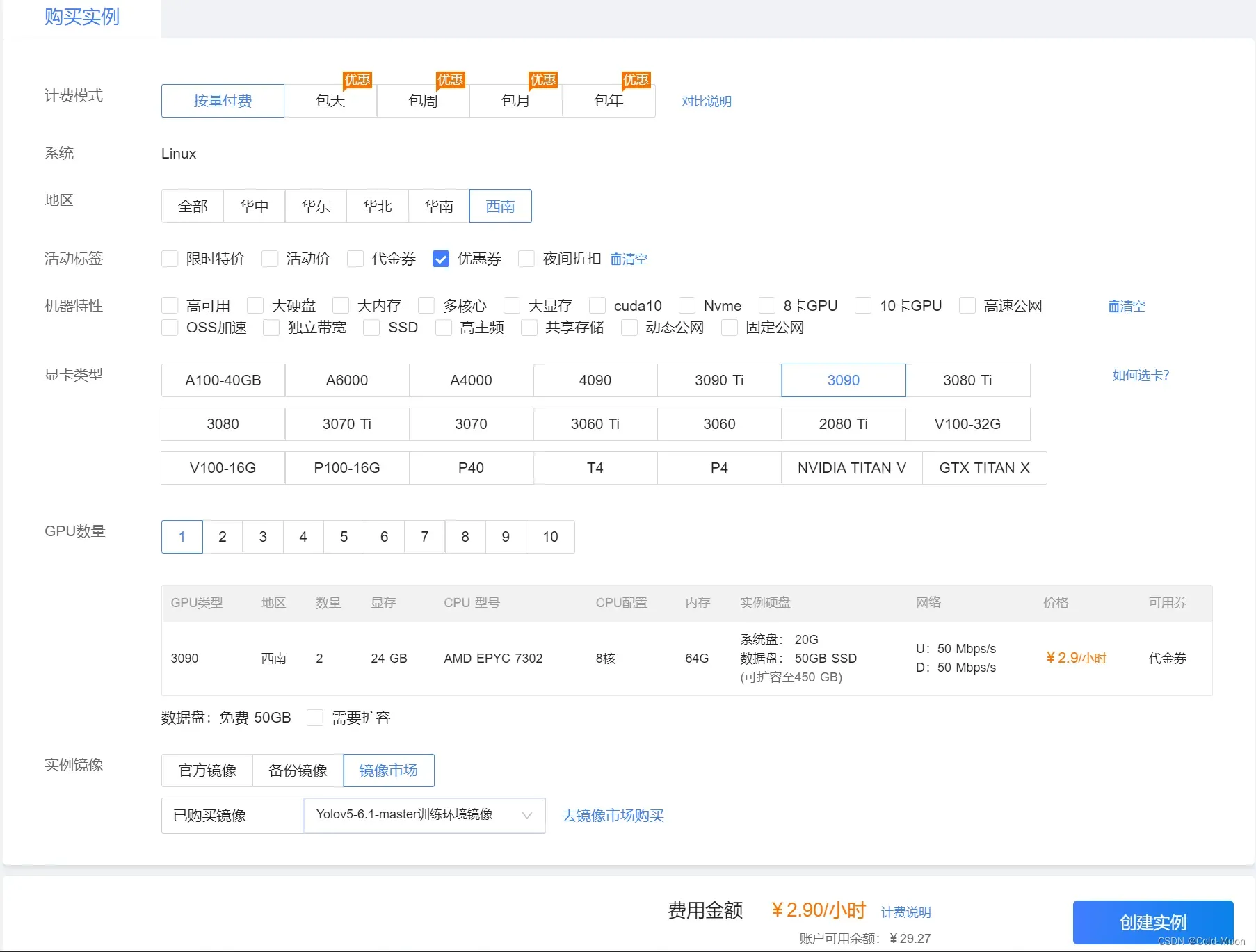
-
使用官方送的代金卷购买实例
-
创建实例后的界面,打开
JupyterLab
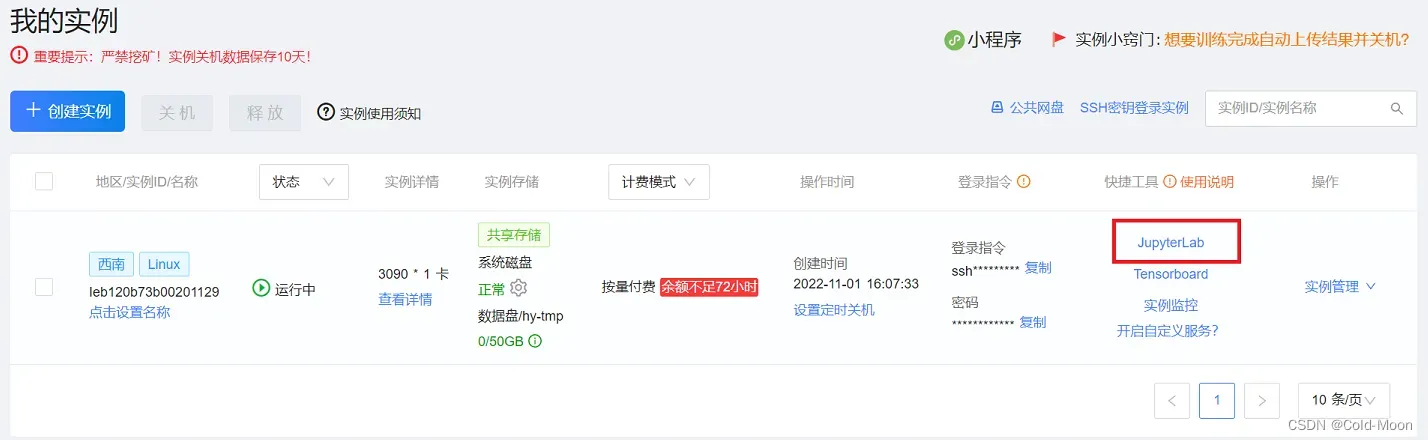
3.4.3.打开云端控制台,数据下载
- 选择终端
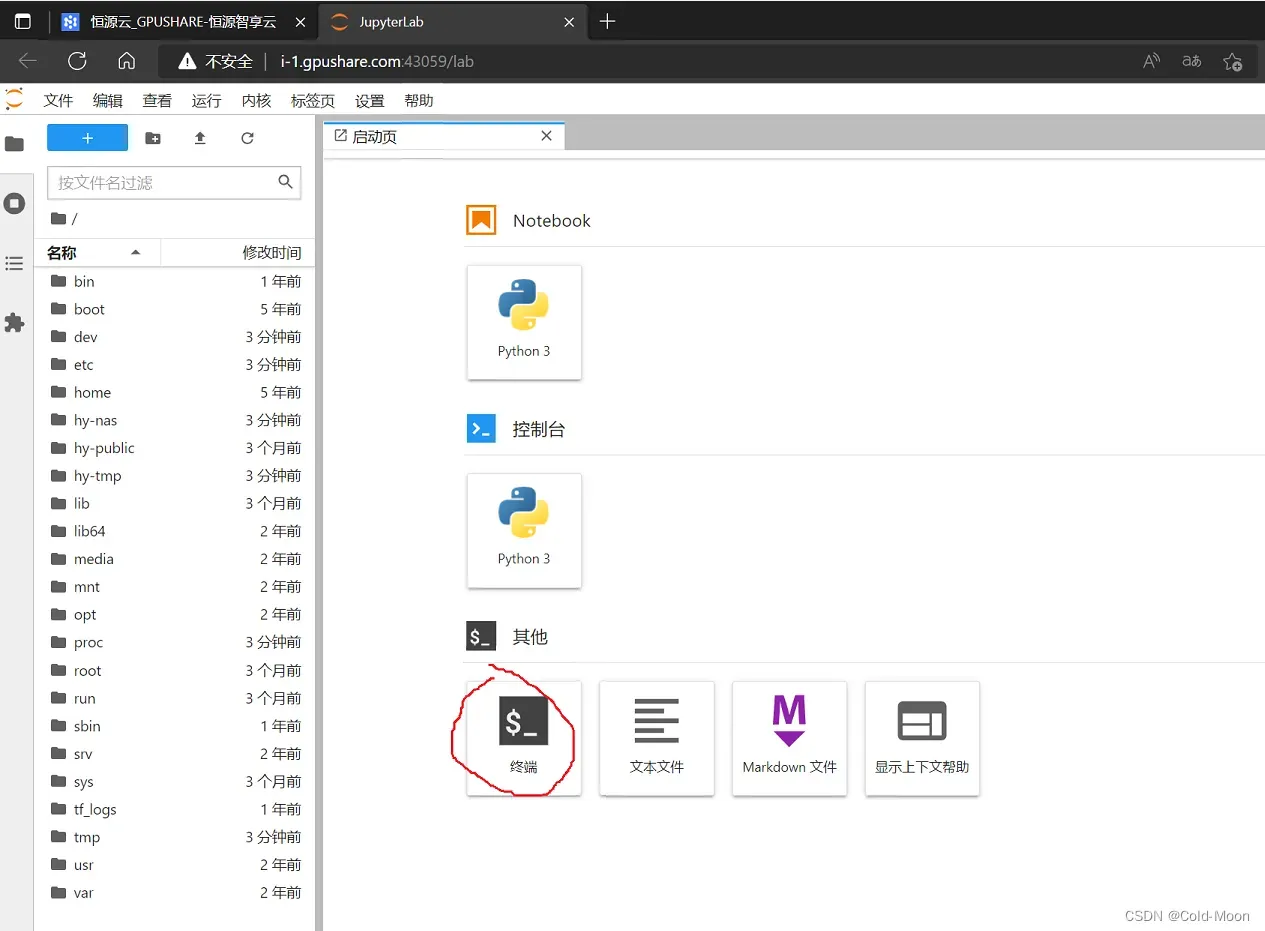
- 使用前,先登录,输入
oss login进行登录
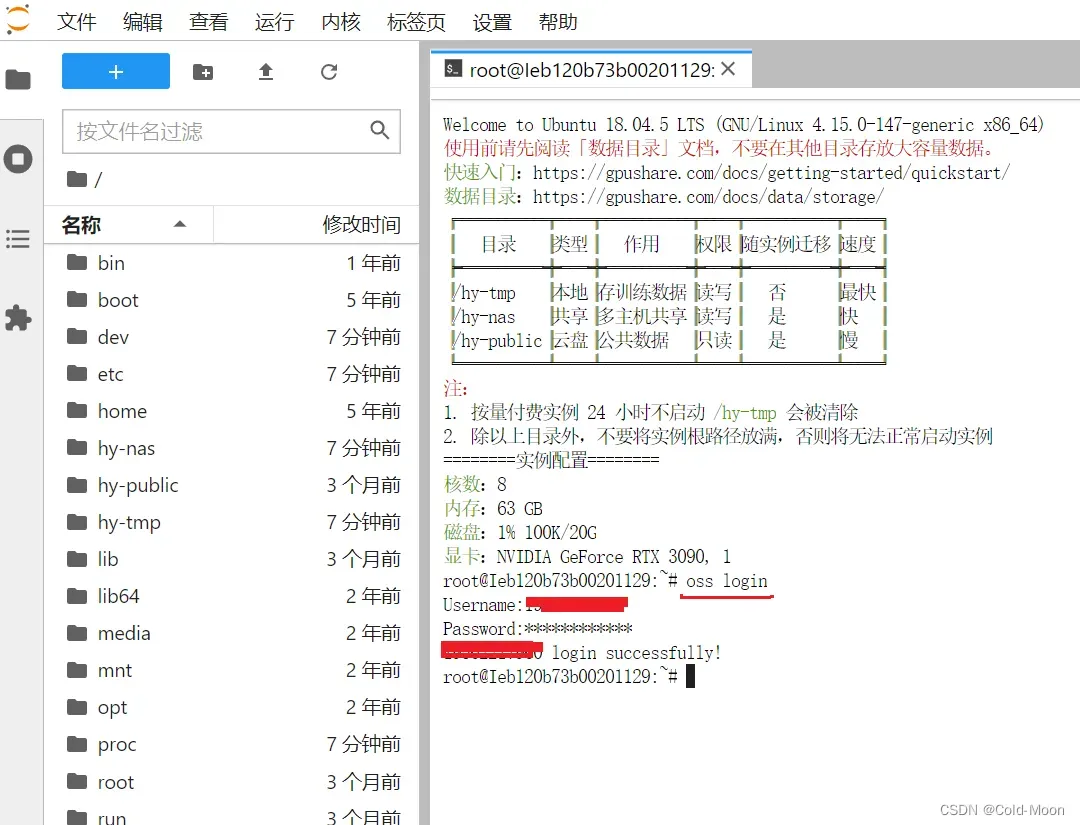
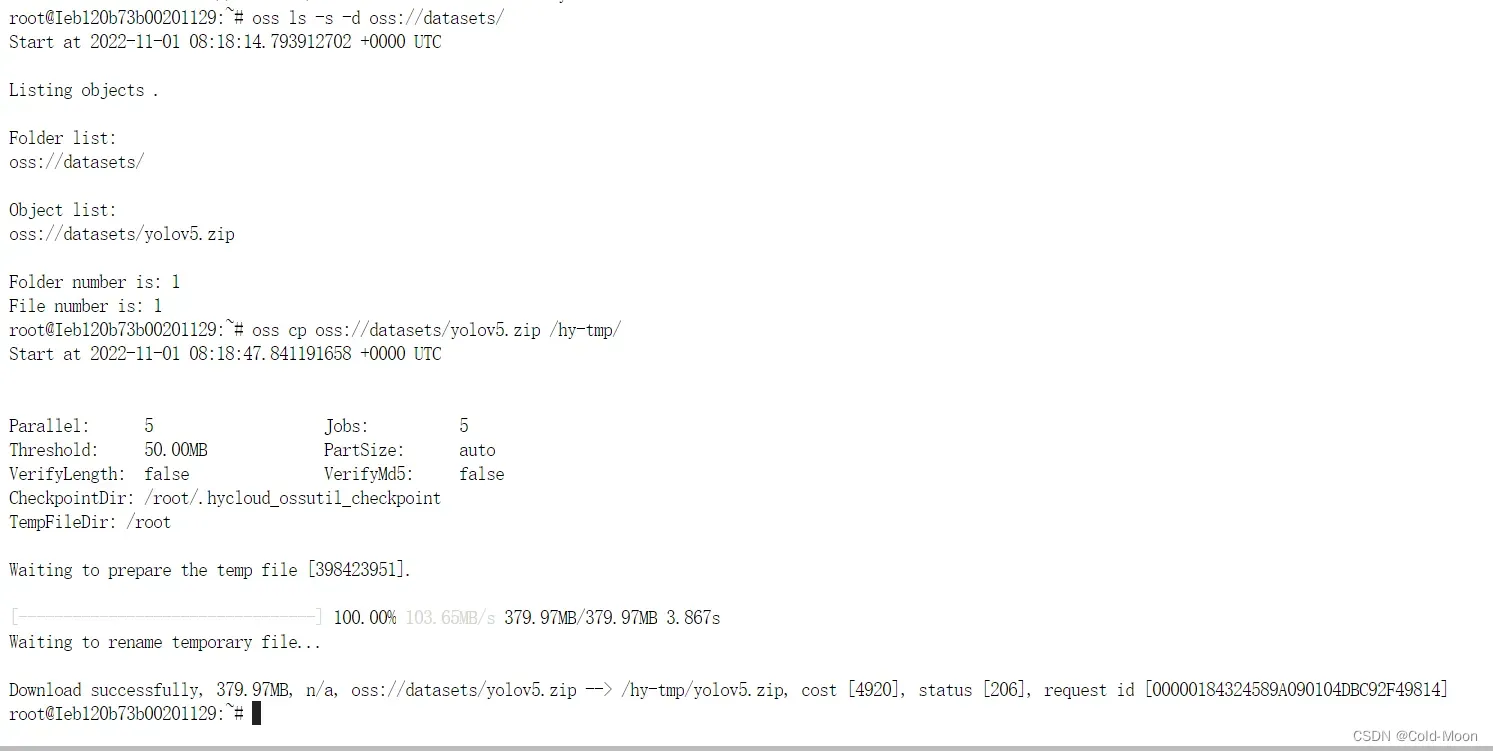
oss ls -s -d oss://datasets/查看之前上传到云端datasets文件夹的.zip文件oss cp oss://datasets/yolov5.zip /hy-tmp/下载压缩文件到/hy-tmp目录下
- 进入到
/hy-tmp目录,并查看当前目录下存在的文件为yolov5.zip - 使用
unzip yolov5.zip命令,解压文件
- 解压后再次查看存在的文件

- 当然也可以在左边的树形目录中查看
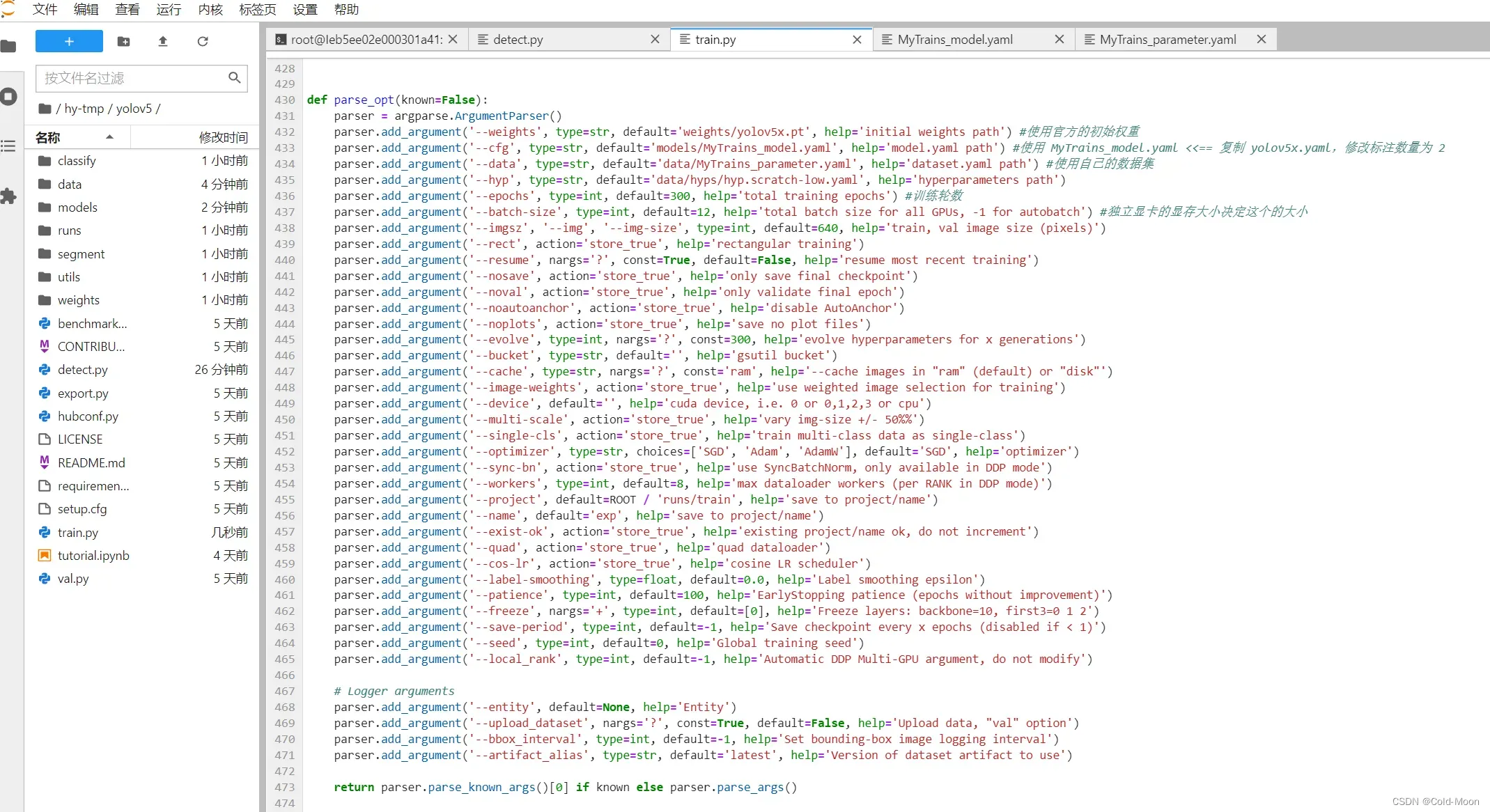
3.4.4.调整参数开始训练
-
由于之前创建实例用的是已经配置好的Yolov5的环境镜像,所以可以直接用
-
这里以训练我自己标注的20张图片为例,初始权重使用
yolov5x.pt,训练300轮 -
train.py参数设置,也可以自己设置其他的参数
-
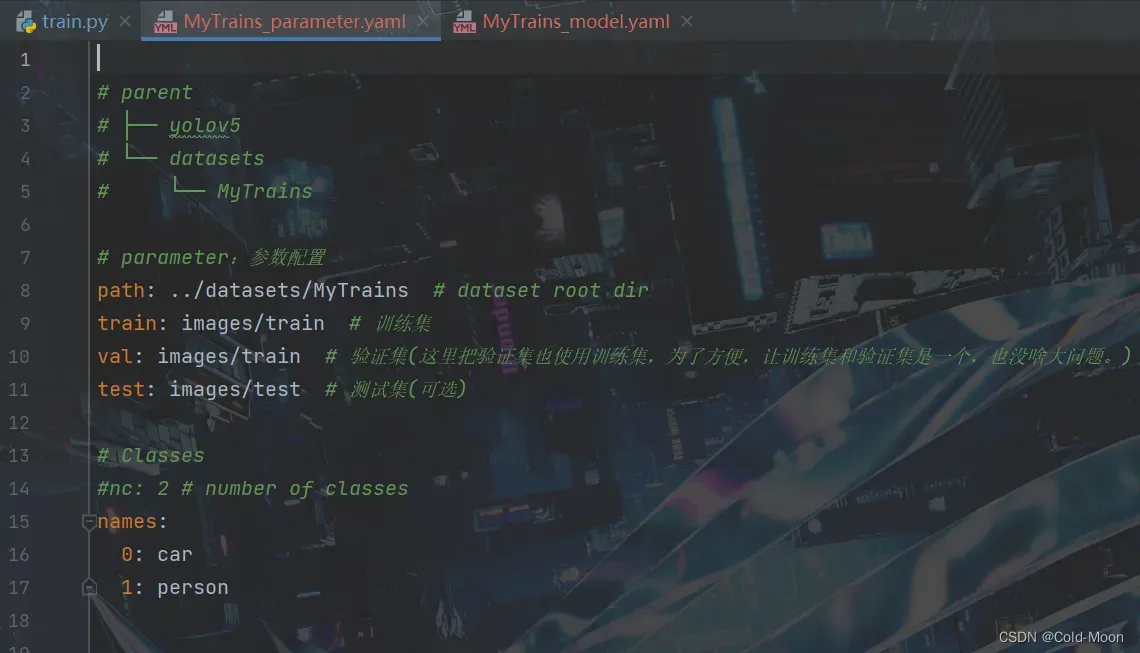
其中
/data/MyTrains_parameter.yaml的内容如下# parent # ├── yolov5 # └── datasets # └── MyTrains # parameter:参数配置 path: ../datasets/MyTrains # dataset root dir 数据集路径 train: images/train # 训练集 val: images/train # 验证集(这里把验证集也使用训练集,为了方便,让训练集和验证集是一个,也没啥大问题。) #test: images/test # 测试集(可选) # Classes nc: 2 # number of classes 你标注的类别的数量 names: 0: car 1: person -
其中
/models/MyTrains_model.yaml的内容,就是复制的源码中的/models/yolov5x.yaml,然后将其中的nc类别数量改为 2(你自己标注有几个类别就改为几个类别) -
开始训练
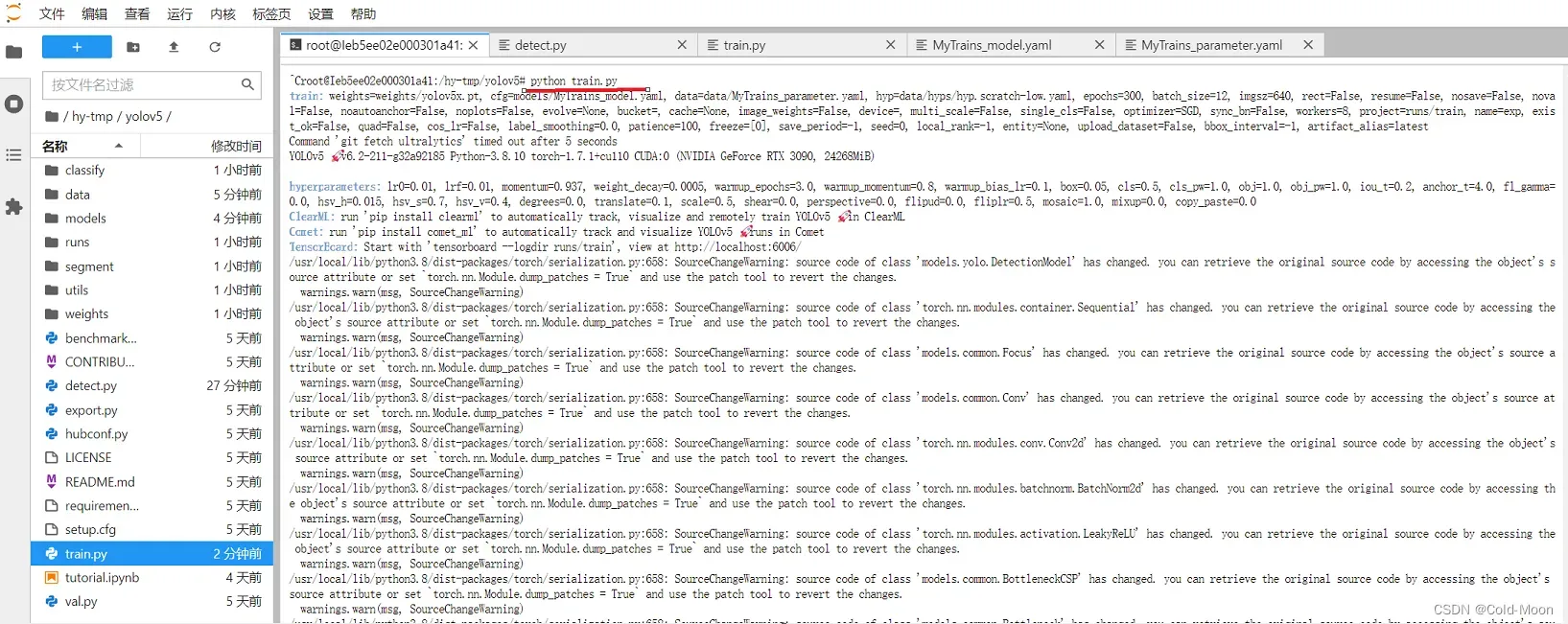
-
训练完成
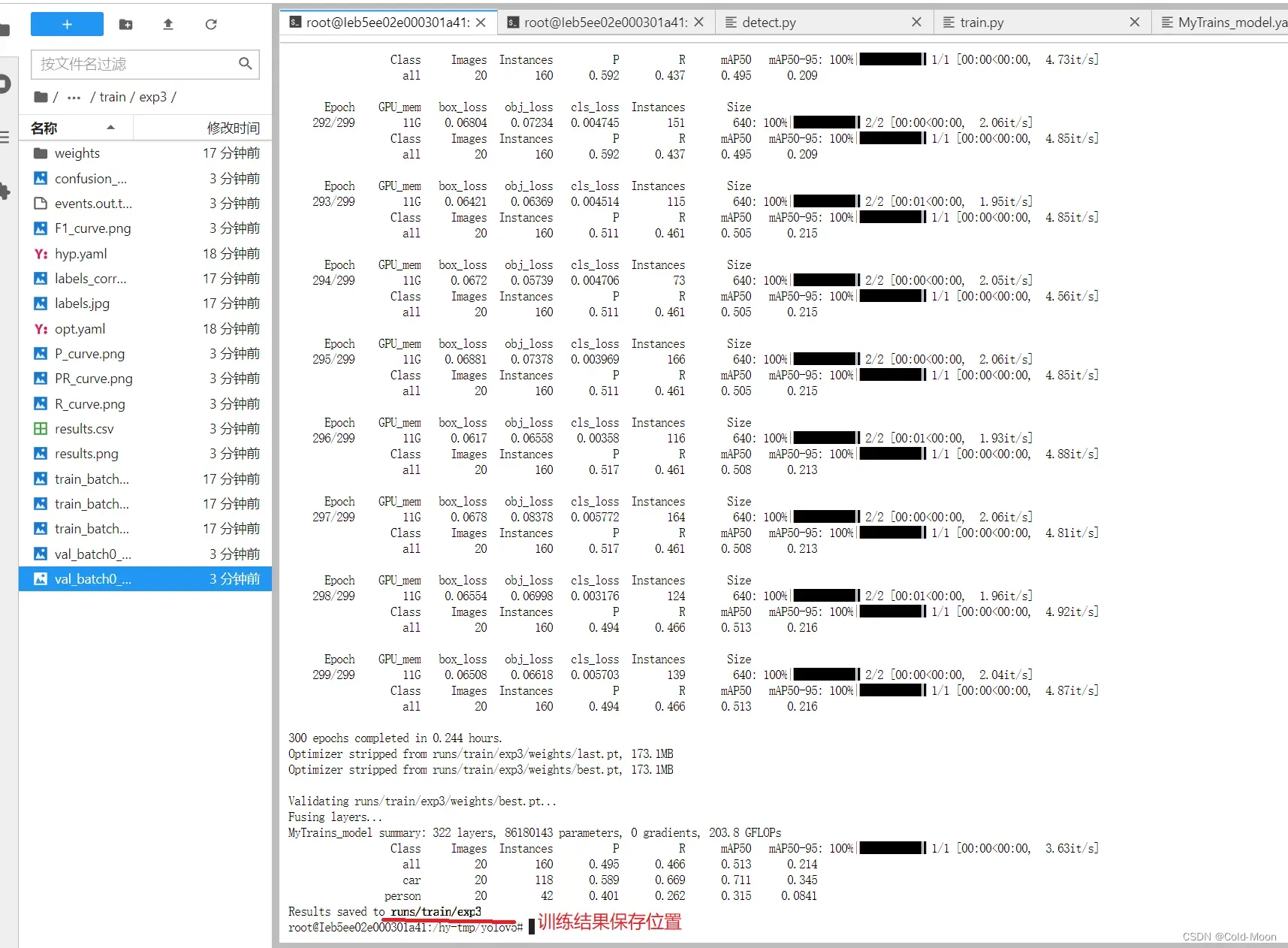
3.4.5.预测
- 在
detect.py的--weights参数设置自己训练后生成的best.pt权重文件 --source参数设置你用于预测的图片--data参数设置为训练时的data/MyTrains_parameter.yaml- 其他参数可以自行设置
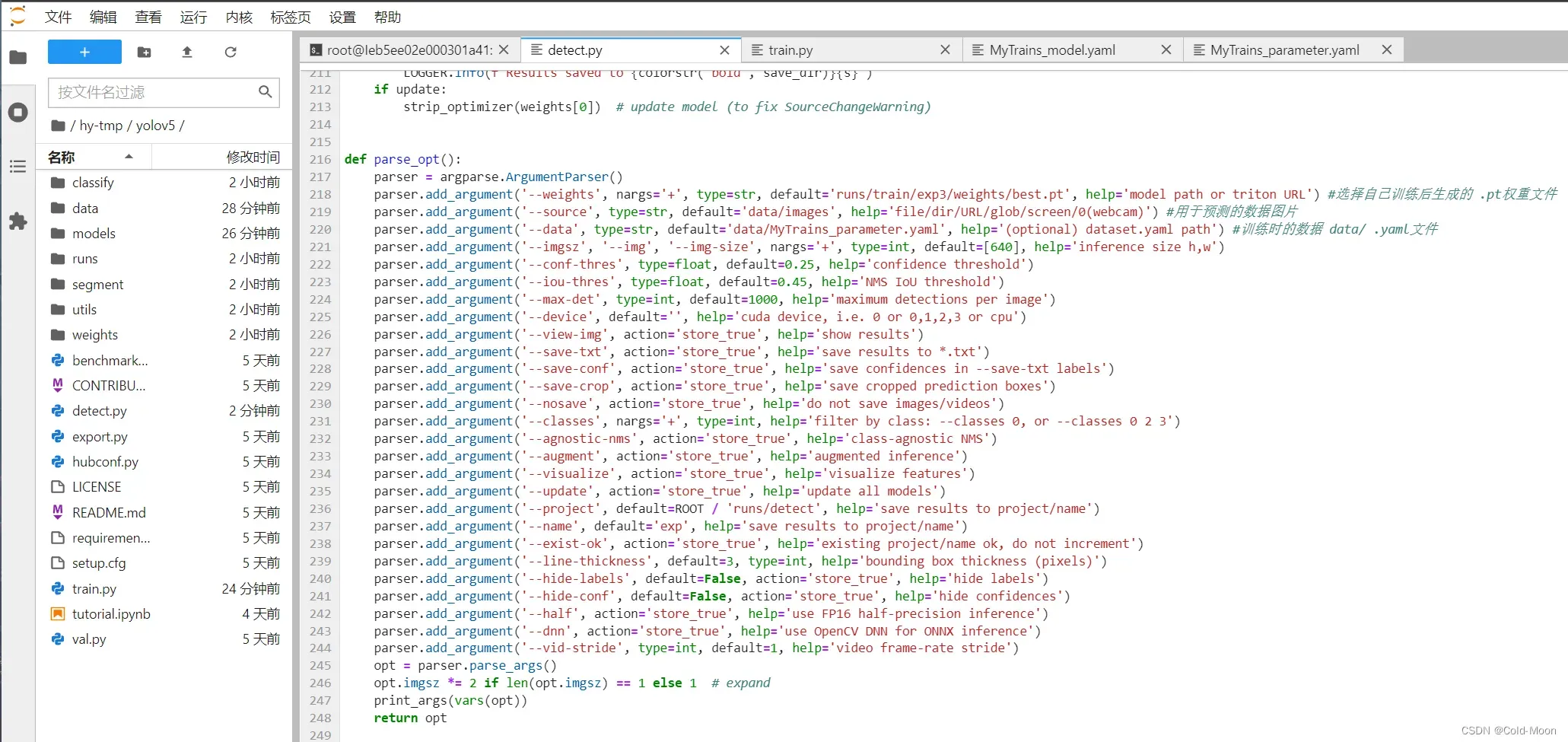
- 开始预测
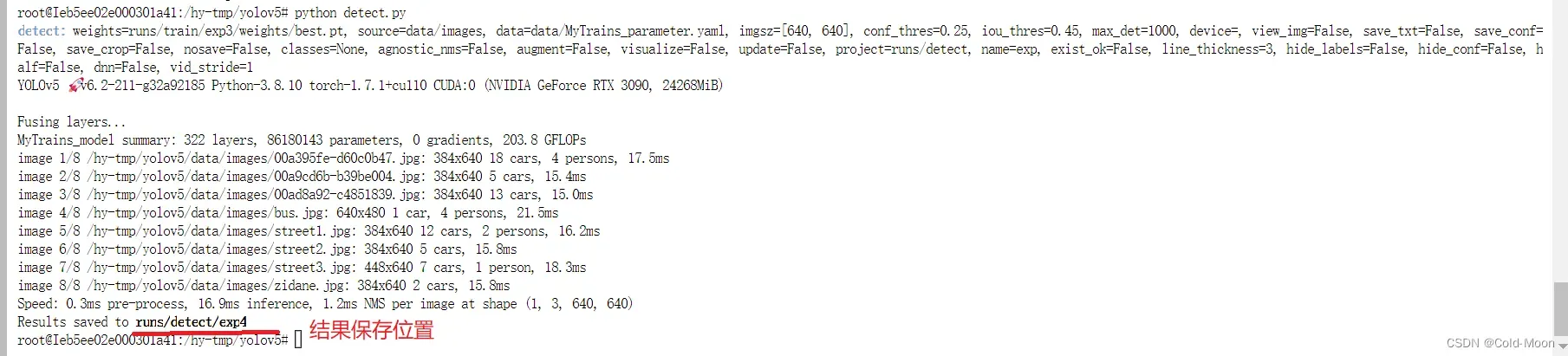
- 部分预测结果

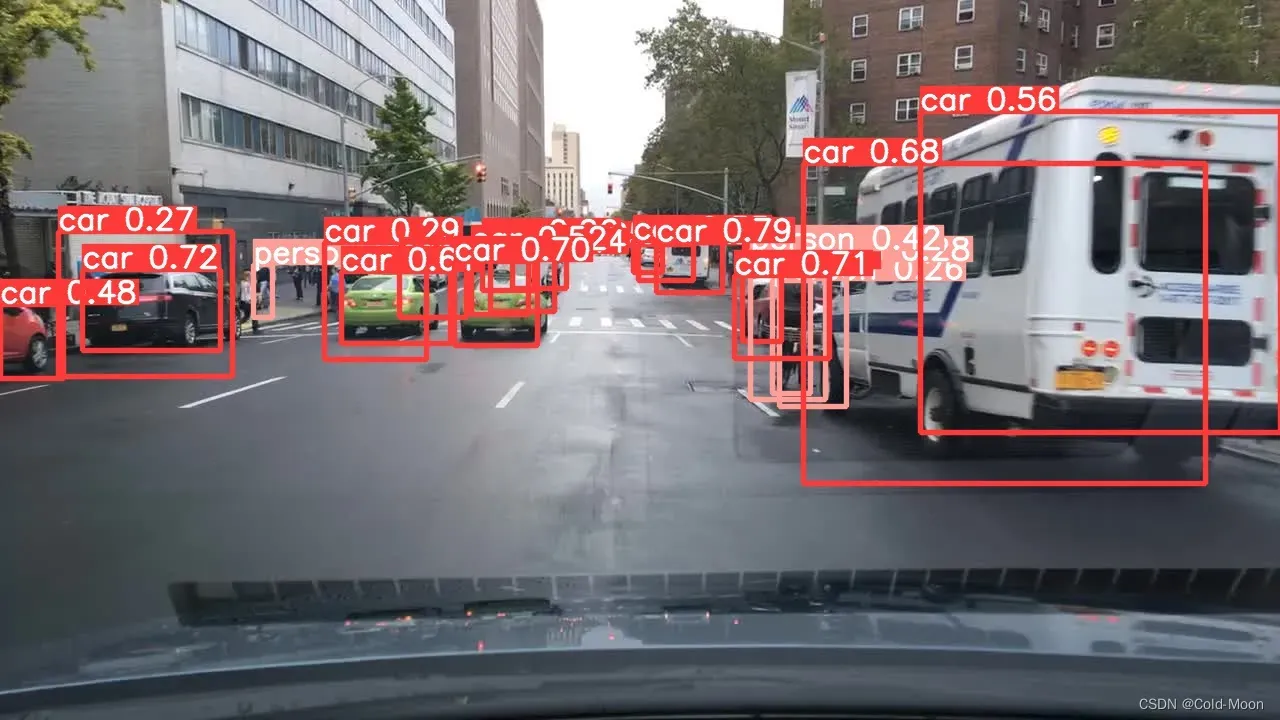
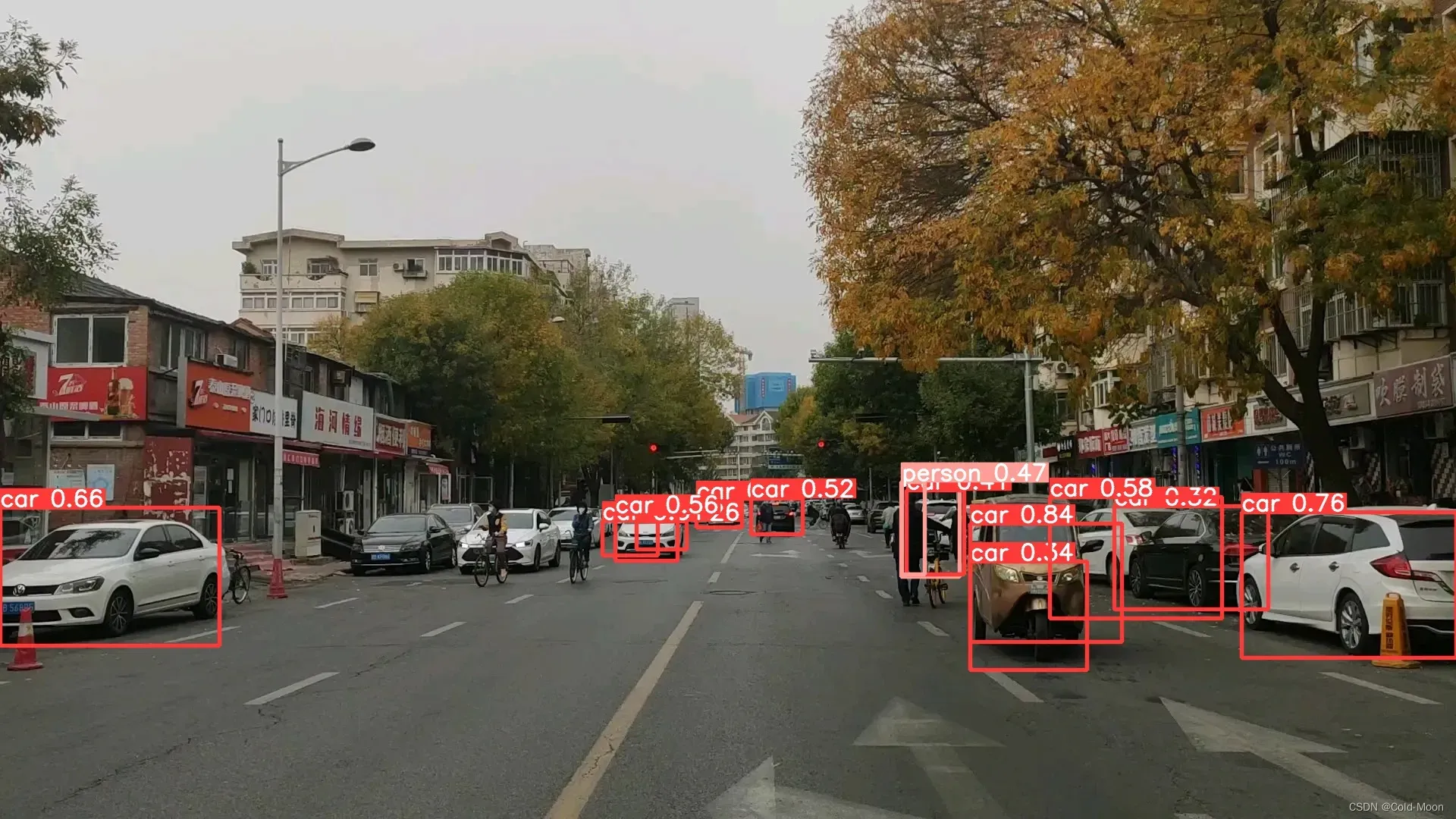
- 只有20张图,预测结果还是不太准确
3.4.6.训练后的数据下载到本地
- 这里我只把训练结果
runs/文件夹下载,因为其他都是本地上传的,所以就全部下载了 - 在yolov5目录下,压缩
runs/文件夹zip -r -q xxx.zip runs/ 将目录 run/ 下的所有文件,打包成一个压缩文件,并查看了打包后文件的大小和类型。 -r 参数表示递归打包包含子目录的全部内容, -q 参数表示为安静模式,即不向屏幕输出信息

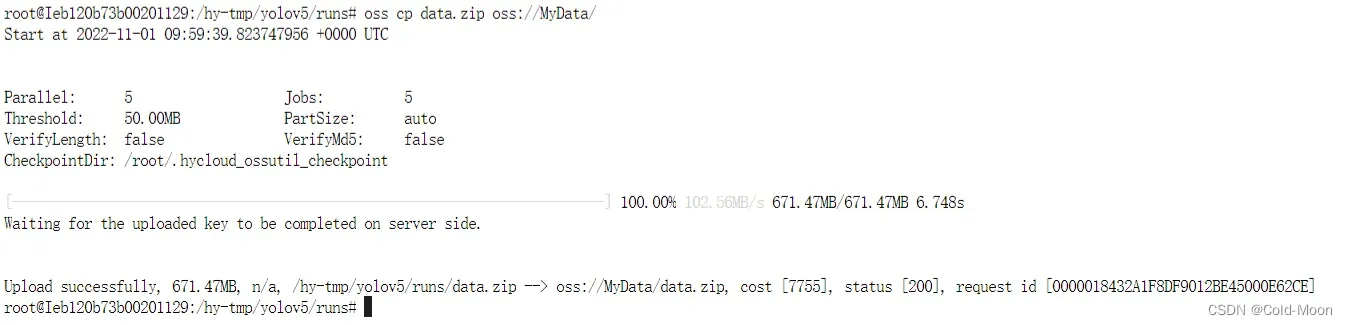
- 将压缩后的文件,上传到OSS云存储空间,输入
oss cp xxx.zip oss://MyData/ - 这一步是后面加的,所以压缩后的名字不同
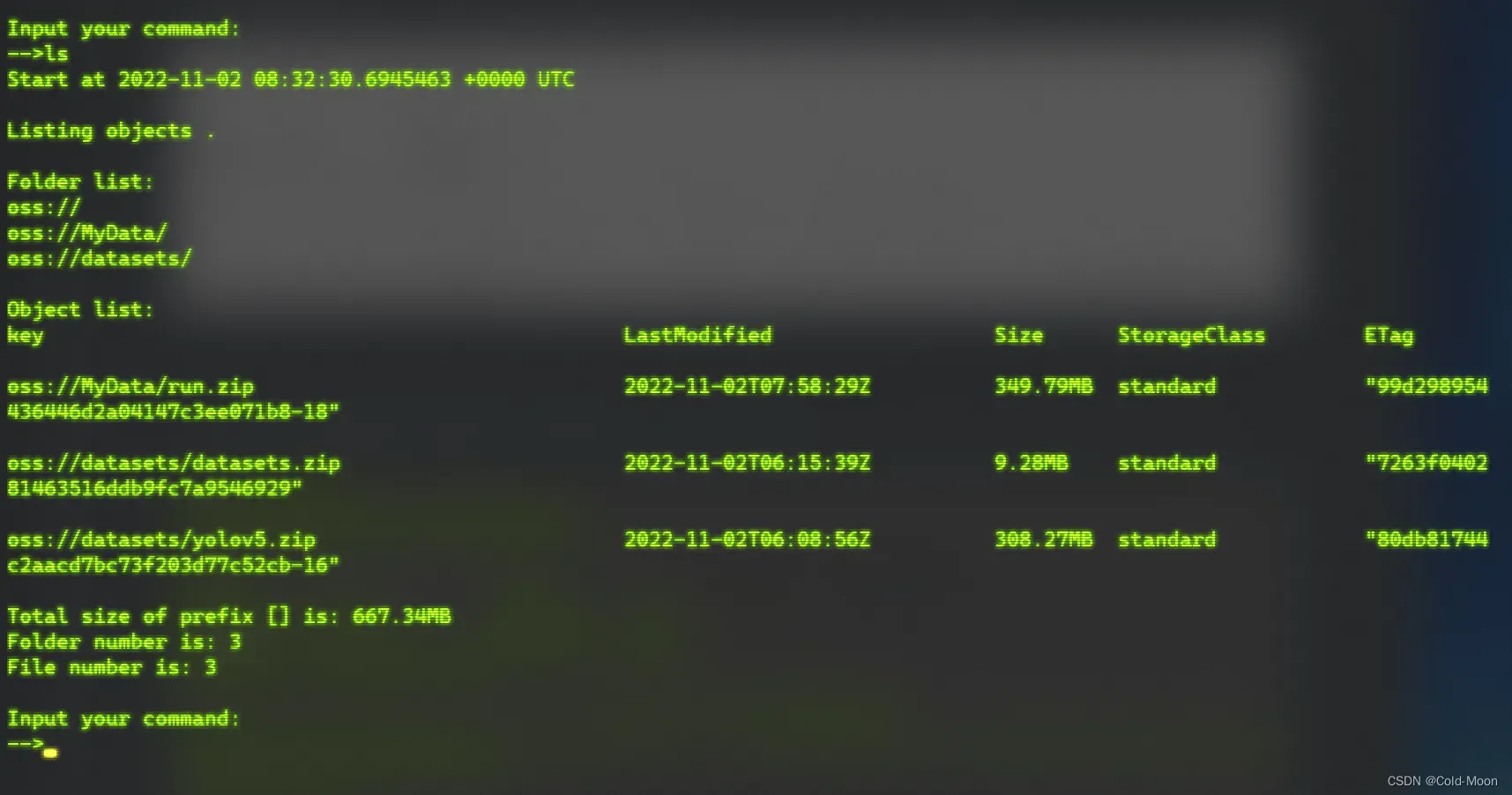
ls在本地OSS中查看OSS云储存空间中的文件有哪些
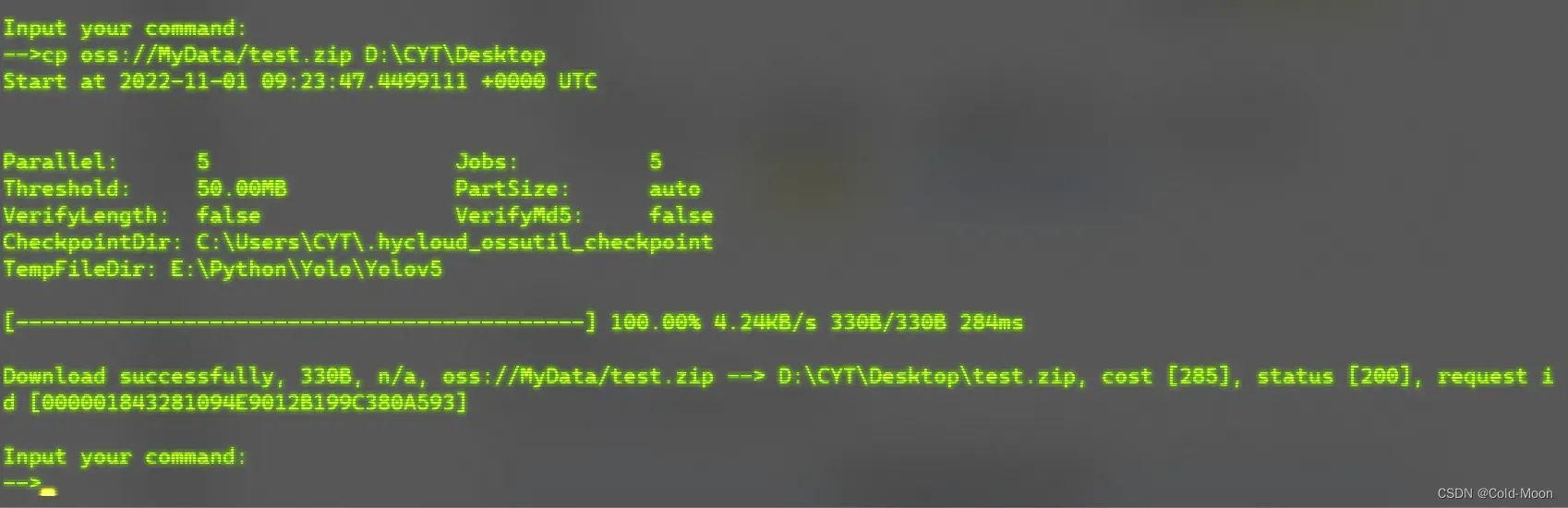
- 将OSS云存储空间中的压缩文件下载到本地
- 例如:我这里下载到桌面,输入
cp oss://MyData/test.zip D:\CYT\Desktop
以上就是我第一次训练Yolov5的一些笔记记录。
文章出处登录后可见!