深度学习中常用的backbone有resnet系列(resnet的各种变体)、NAS网络系列(RegNet)、Mobilenet系列、Darknet系列、HRNet系列、Transformer系列和ConvNeXt。在此博主将描述各种模型的关键结构。
1、resnet系列
1.1 原始resnet
2015年 何凯明。
resnet系列包含resnet18、resnet34、resnet50、resnet101、resnet152。
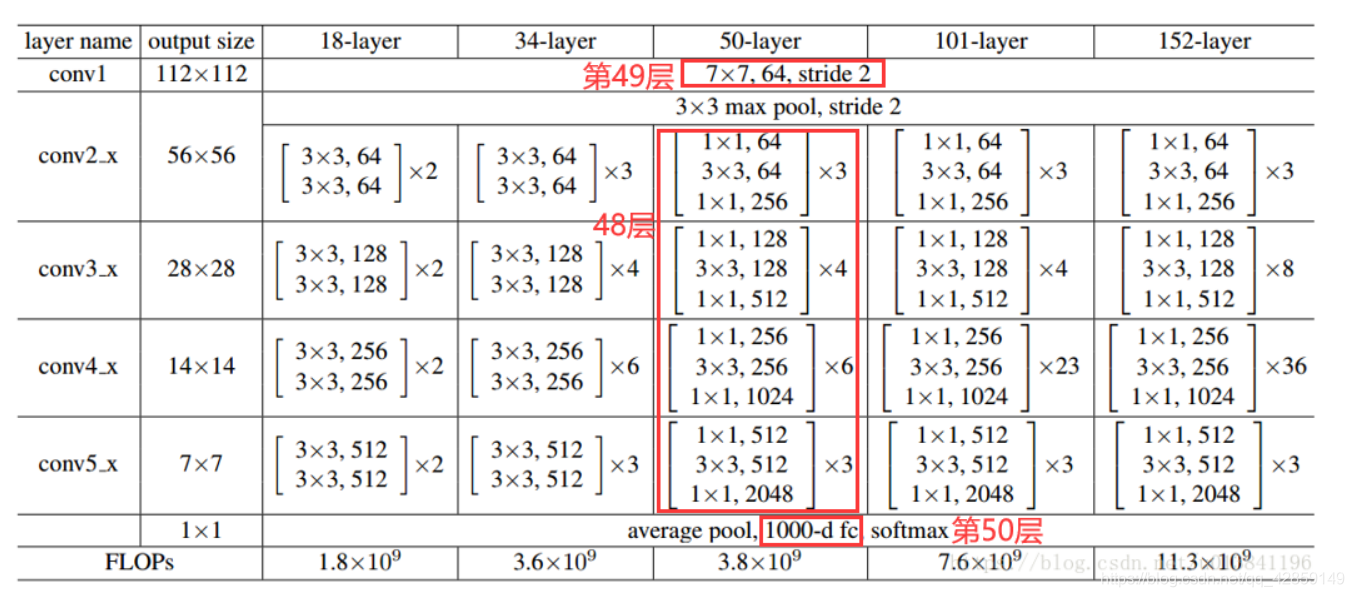
resnet18的网络结构如下所示
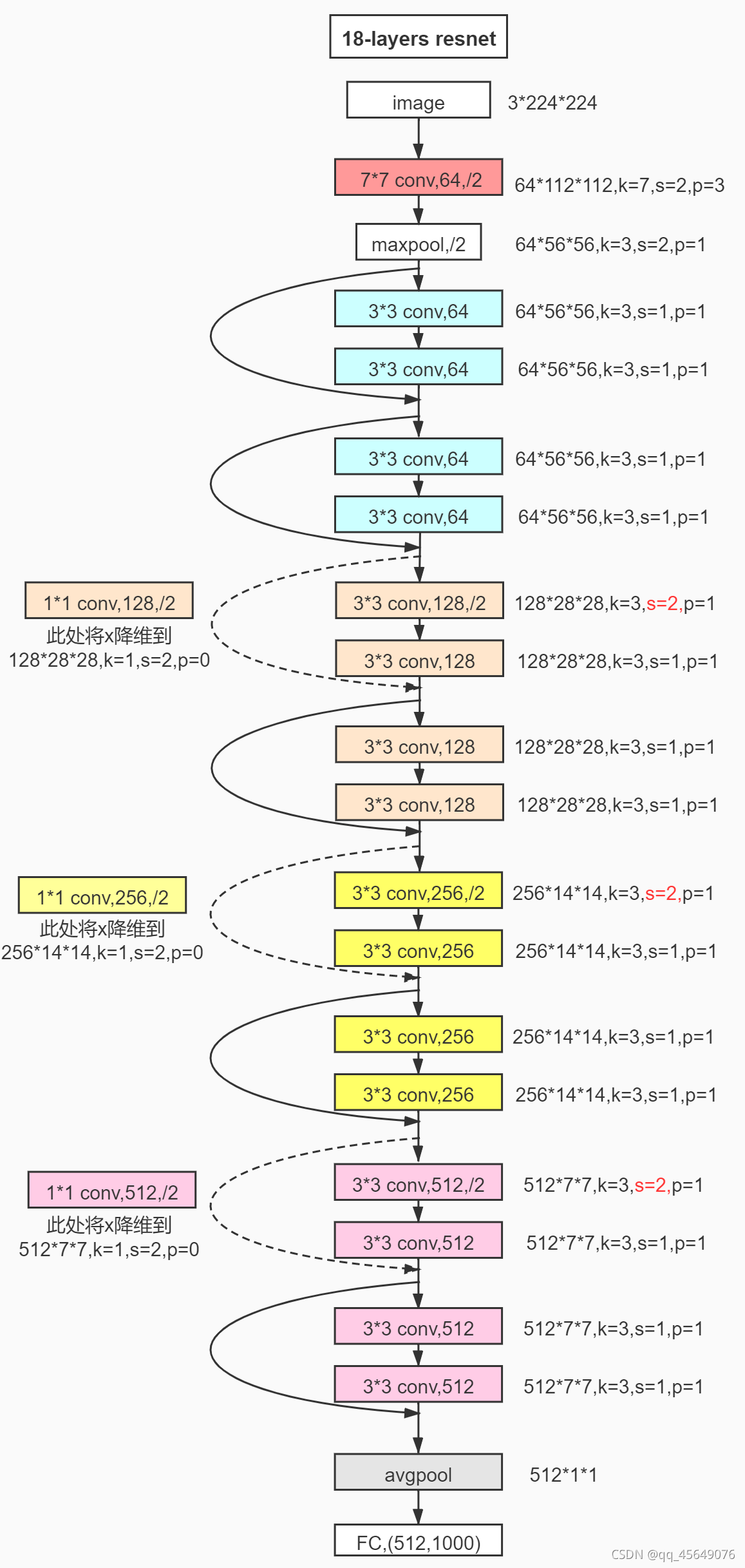
通常看到用来做backbone的主要是resnet50与resnet101
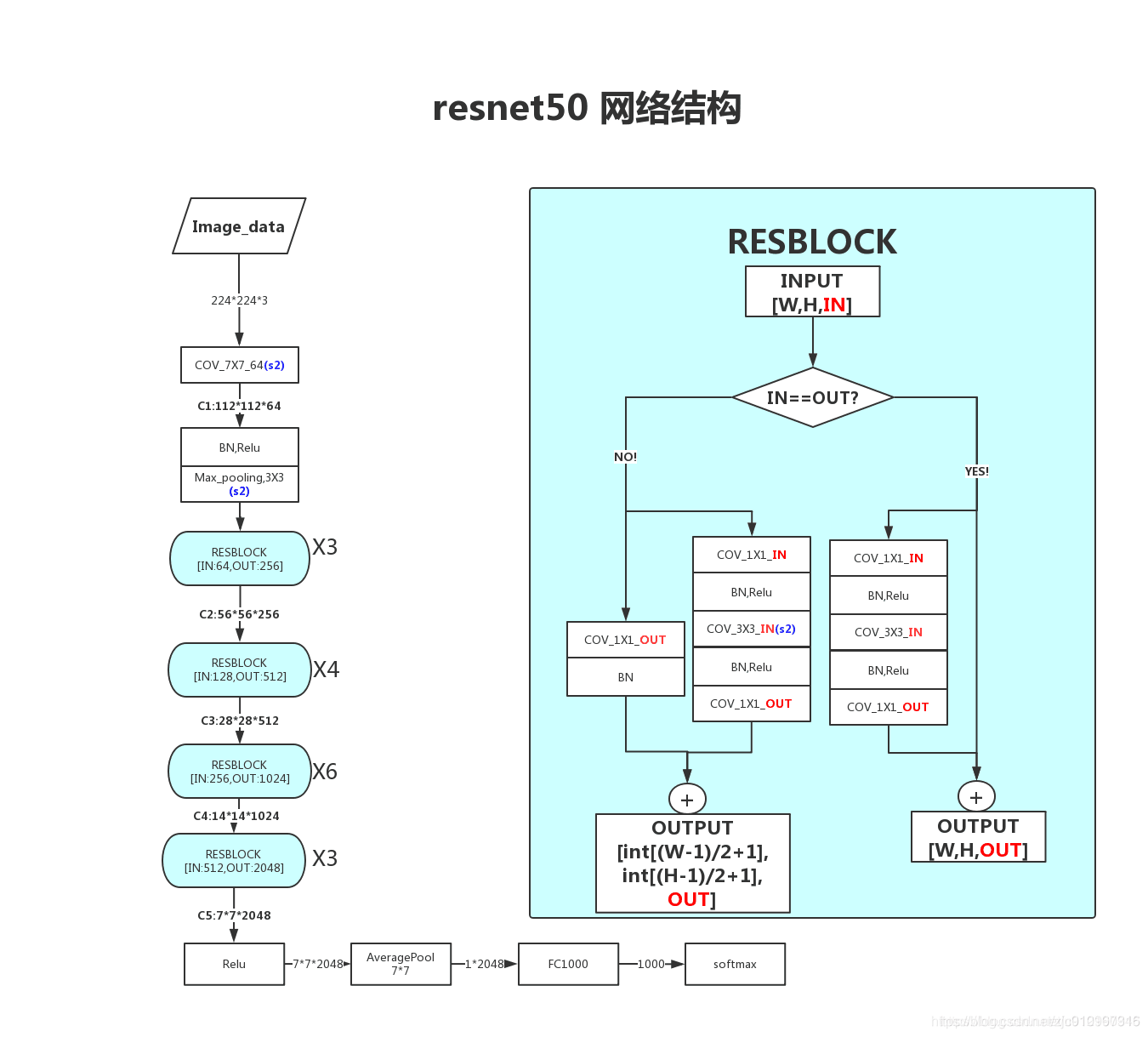
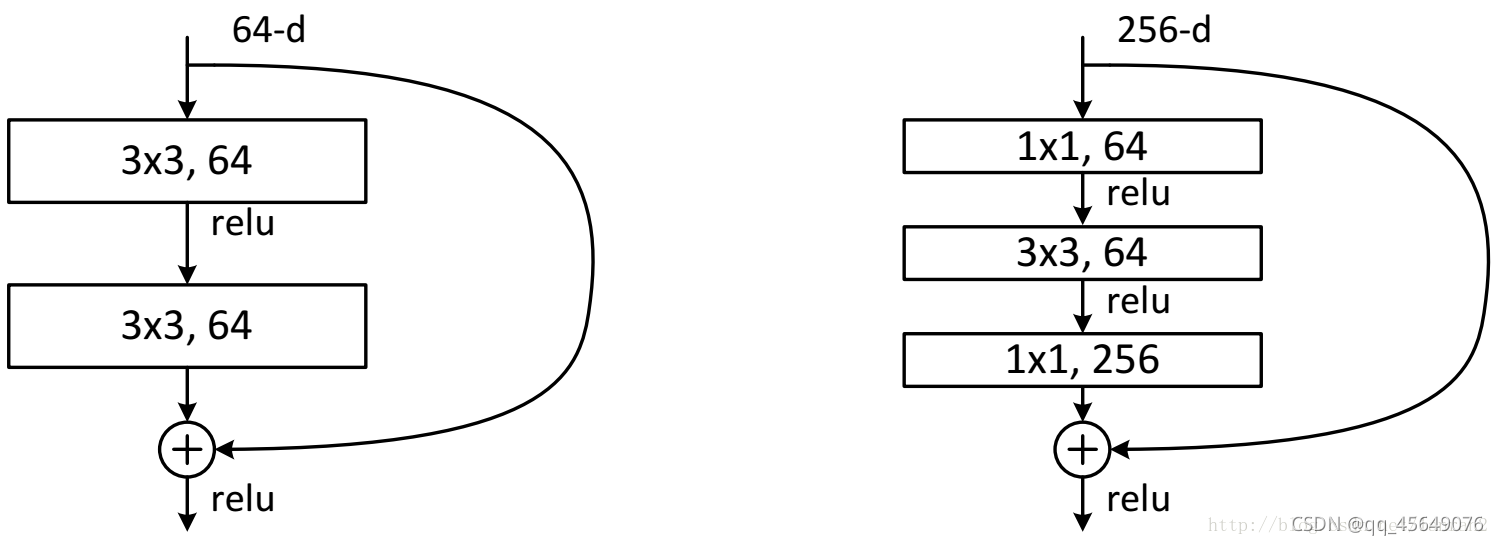
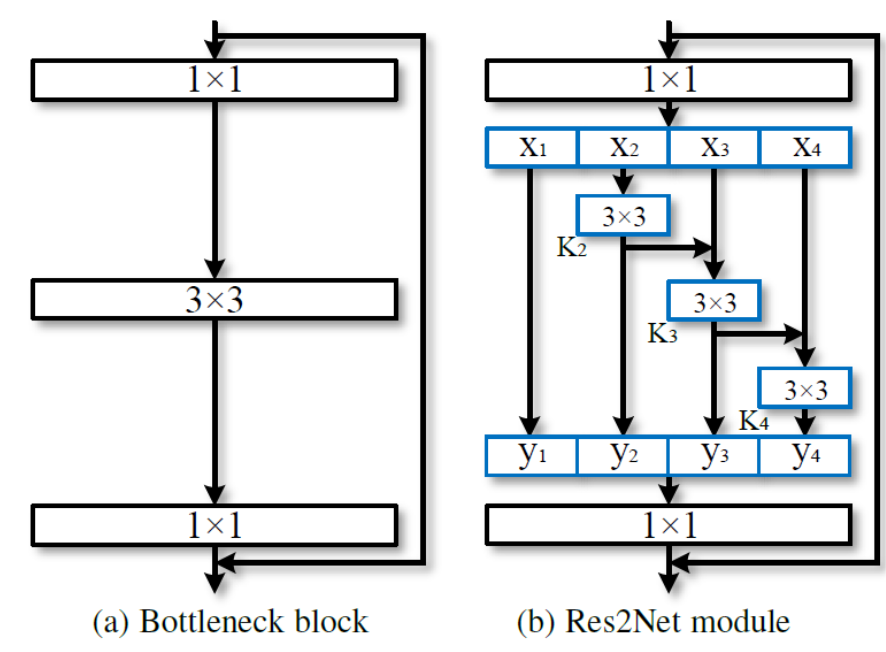
resnet中包含两种residual结构,左侧的残差结构为BasicBlock,右侧的残差结构为Bottleneck(属于一种中间小两头大的结构)
1.2 ResNeXt
2016年 Saining Xie https://arxiv.org/abs/1611.05431
该网络结构是基于ResNet的,是ResNet的增强版。该网络的提出主要吸收了ResNet和Inception结构的优点,提出了split-transform-merge的结构范式。
resnet单元与resnext单元的对比
resnext单元有分组卷积构成,虽然总的filter数比resnet多,但是运算量小一些($NN> \frac{M}{32}\frac{M}{32}*32 $,M大于N)。
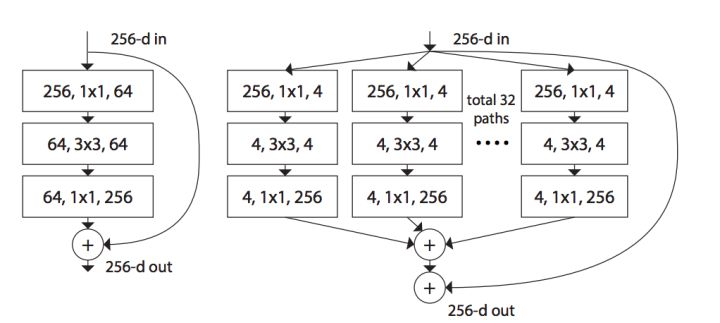
resnet50与resnext50的对比
两者整体结构相似,只是在resnext50中将resnet单元换成了resnext单元
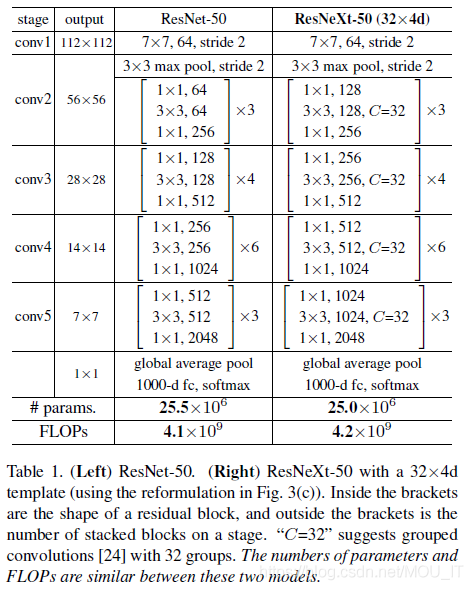
resnext单元与类似结构的对比
a是ResNeXt基本单元,如果把输出那里的1×1合并到一起,得到等价网络b拥有和Inception-ResNet相似的结构,而进一步把输入的1×1也合并到一起,得到等价网络c则和通道分组卷积的网络有相似的结构。从中可以看到Inception-ResNet和通道分组卷积网络,都只是ResNeXt这一范式的特殊形式而已。
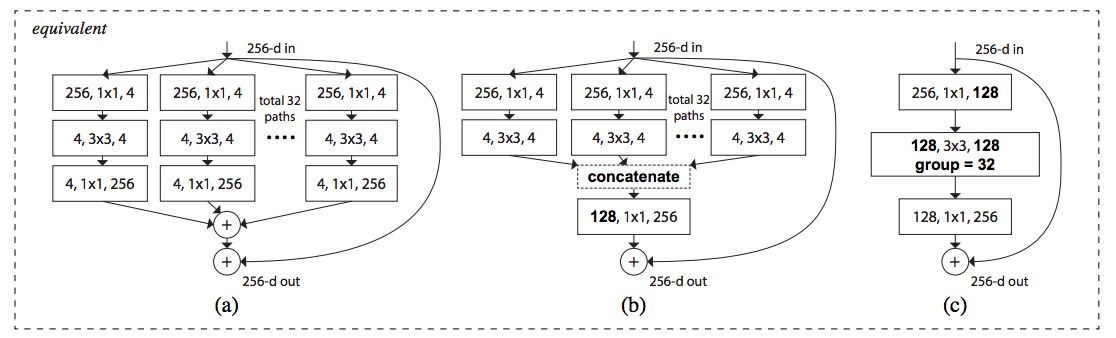
1.3 Res2Net
2019年 Shang-Hua Gao https://arxiv.org/abs/1904.01169
内容摘抄自:教训小磊@简书 https://www.jianshu.com/p/2e452a375963
Res2Net是经典深度网络ResNet的一种变体。它主要是将多尺度作为提升网络性能的出发点,并结合分组卷积和类似特征金字塔FPN的思想所设计的一种backbone。以往的多尺度都是基于不同层之间相加的方法,例如FPN,而本文是通过在同一层中结合来自不同小分块的不同感受野来得到多尺度的。本文思想比较简单明了,没有复杂的公式堆叠,相对原生的ResNet,性能有较大的提升。
resnet单元与res2net单元的对比
这里的概念是通过增加块内的感受野,而不是一层一层地捕获图像中更细粒度的不同级别的尺度,从而提高CNN检测和管理图像中物体的能力。
作者将Res2Net块内的特征组数量称为“scale dimension”。因此上面的代码块是scale为4的Res2Net代码块。
正如图1所示,X2到X4是不断向下相加进行,越是后面的层所得到的感受就越大,而X1则充当的是恒等映射的角色,最后使用1×1卷积来融合通道信息。
在本文中,作者实验得到当scale=4,width=26时 可以得到速度和精度的均衡。
效果增益分析
内容摘抄自:Kun Li@CSDN https://blog.csdn.net/u012193416/article/details/121270765
作者实验中有个结论,在同等深度下50/101,res2net都是比resnet的效果要好. 但是101的时候增益稍小,但是也说明不了什么问题,在resnet结构中越到深层,残差激活越小,理论上res2net的结构设计收益应该越小,那么res2net强还是因为其在不是很深的时候带来的特征的深度挖掘能力,多尺度的组合,densenet也是多尺度kernel带来了比resnet更强的收益,模型如果太深,回传的梯度和输入的信息就不一定是最高效的信息。下面这个图也表明res2net其实对于loss所指向的对象的刻画更为准确,就是对干扰梯度的过滤性更好,更细,学的很好,更soft,resnet调整步长让差分更拟合,这个感觉像在步长里面在做小步长,差分里面在差分,soft上soft,解空间更平滑。

1.4 ResNest
2020年 Hang Zhang https://arxiv.org/abs/2004.08955
提出了Split-Attention模块,整合了跨通道的注意力机制,同时保持了ResNet架构的简单。ResNeSt中的S代表split。该模块可以作为backbone广泛语义于各种模型中。
ResneSt Block
先仿照Resnext将数据分为k组,然后再在组内将数据分为r个cardinal组

Split-Attention
1、先对一个cardinal组内的多个group进行按位sum操作,2、然后按照wh维度进行池化(论文中为平均池化),3、接着用ksize为1的分组conv1实现全连接+BN+relu,4、在用ksize=1的分组卷积conv2实现全连接,5、针对每一个分组都使用softmax进行激活操作,6、然后将每一组的激活值与原始值相乘,7、最后将每一组按位进行sum操作。

在其他任务中的应用
与其他cnn网络的对比
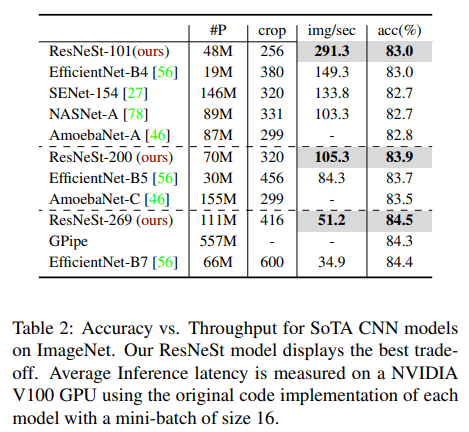
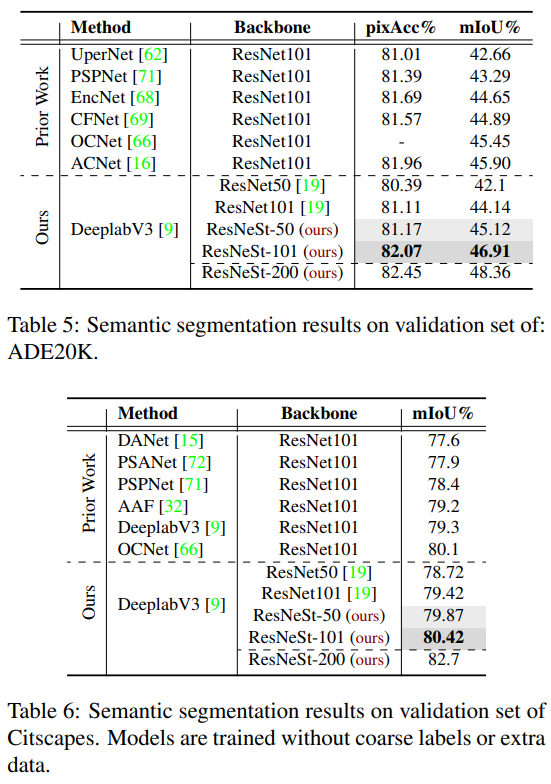
在目标检测中的应用
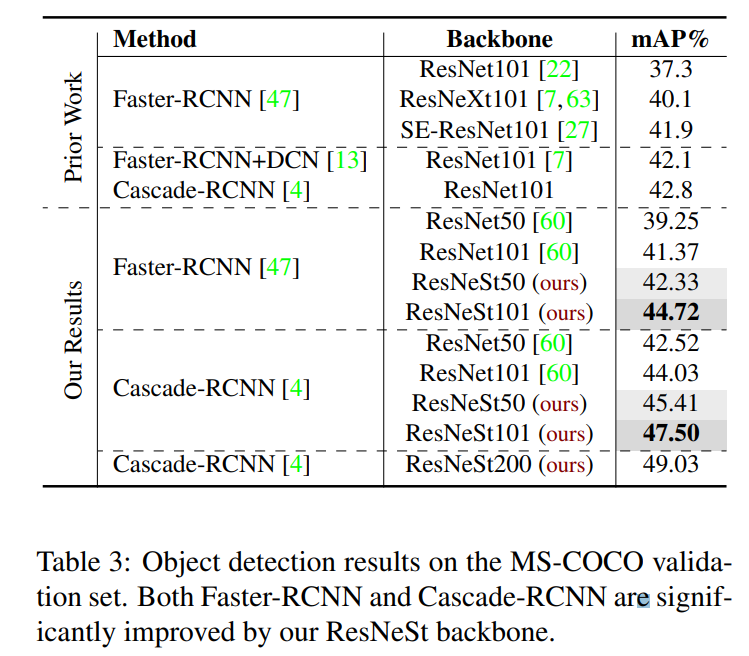
在实例分割中的应用

在语义分割中的应用
2、RegNet
2020 Ilija Radosavovic https://arxiv.org/abs/2003.13678 论文:Designing Network Design Spaces
知乎解读:https://zhuanlan.zhihu.com/p/425558548
一种使用NAS(Neural Architecture Search)技术检索出的网络结构,与一些NAS论文不同(例如MobileNetv3,EfficientNet),之前的一些有关NAS的论文都是在给定的设计空间(designed search space)中通过搜索算法去搜索出一组最佳参数组合。但在这篇论文中作者要探究的是如何去设计设计空间(design design spaces)并发现一些网络的通用设计准则(network design principles),而不是仅仅去搜索出一组参数。
基于NAS检索出的结构EfficientNet、EfficientNetV2都是可以作为backbone广泛使用的
初始设计空间AnyNetX
在深度学习中,几乎每个神经网络都可以抽象成3个模块,如图7.(a)所示:
stem:这一层又被叫做输入层,它用来处理不同类型的输入数据;
body:这一层又被叫做骨干层,它通过堆积大量的网络模块来增加模型的容量,提取多种类型的数据特征,增强模型的表征能力。骨干层又若干个block组成(论文[1]中叫做stage),每个block由降采样层组成,降采样层一般是步长为 的卷积或者池化操作。每个block由若干个Layer组成(论文[1]中叫做block),Layer一般是一个卷积操作,在这里我们可以定义卷积的一些超参,例如通道数,卷积类型,卷积核的大小等等。
head:这一层又被叫做输出层,它根据不同的任务类型(分类,回归)和内容(类别数,回归分支数)等来调整输出层的结构。
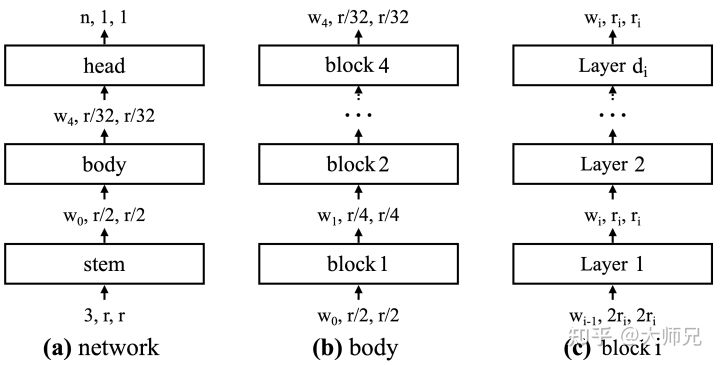
AnyNetX同样是遵循这个3个模块的架构,它的优化完全是在body部分进行的。
默认block
论文中将block设计为standard residual bottlenecks block with group convolution即带有组卷积的残差结构(和ResNext的block类似),如下图所示,左图为block的stride=1的情况,右图为block的stride=2的情况。
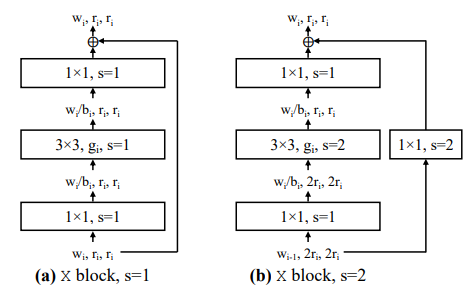
结构设计经验
参考Lighthouse@知乎 https://zhuanlan.zhihu.com/p/414531092
由于这些设计准则是在stage数量为4、每个网络训练10个epoch的实验设置下获得的。作者进一步在更多的stage数量、训练更多地epoch的实验设置下,对提炼的网络优化准则进行验证,验证了泛化性。这里不得不佩服作者实验室的土豪,算力资源配置简直了。然后得到了几个结论,对于以前业内的结论可以说是颠覆性的。
- 无论模型多大,约20个block,60层深度是最优的,网络越深越好是不对的。bottleneck ratio设置为1是最好的,width multiplier设置为2.5是最优的。其他参数,初始网络宽度w0、宽度的增长斜率wa、卷积group数量g应随着模型增大而增加。
- 推理速度与activation更有关系,而非FLOPS。这里的activation是文章中定义的,仅与输出Tensor的大小相关。所以,建立不要仅利用FLOPS表征速度了,最用根号FLOPS与线性的activation一起来建模推理速度。
- 再是几个关于非常常见的一些设计比如inverted bottleneck以及depthwise conv的结论。首先前者稍微降低了EDF(评价指标),后者就还不如group conv。缩放输入图像分辨率也没啥用,224X224是最优的。还有SE模块,这个是有用的。
3、mobilenet系列
MobileNet 是轻量级卷积神经网络系列,现在已经有v1、v2、 v3。MobileNet v2 是对Mobile v1 的改进。MobileNet v3发表于2019年,该v3版本结合了v1的深度可分离卷积、v2的Inverted Residuals和Linear Bottleneck、SE模块,利用NAS(神经结构搜索)来搜索网络的配置和参数。
以下V1与V2的介绍内容参考自man_world@CSDN https://blog.csdn.net/mzpmzk/article/details/82976871
3.1 MobileNetV1
2017年 论文地址:https://arxiv.org/pdf/1704.04861.pdf
提出使用深度可分离卷积,也就是kernel与feature map一一对应的做卷积,没有多余的通道间全连接。这会导致通道间信息不流通,因此需要引入1*1的卷积。
普通卷积和深度可分离卷积
标准的卷积过程如下图所示,卷积核做卷积运算时得同时考虑对应图像区域中的所有通道(channel),而深度可分离卷积对不同的通道采用不同的卷积核进行卷积,如图2所示它将普通卷积分解成了深度卷积(Depthwise Convolution)和逐点卷积(Pointwise Convolution)两个过程,这样可以将通道(channel)相关性和空间(spatial)相关性解耦。原文中给出的深度可分离卷积后面都接了一个BN和ReLU层。

其他亮点
用 CONV/s2(步进2的卷积)代替 MaxPool+CONV:使得参数数量不变,计算量变为原来的 1/4 左右,且省去了MaxPool 的计算量;
使用Global Average Pooling大幅度的减少了全连接层的参数。
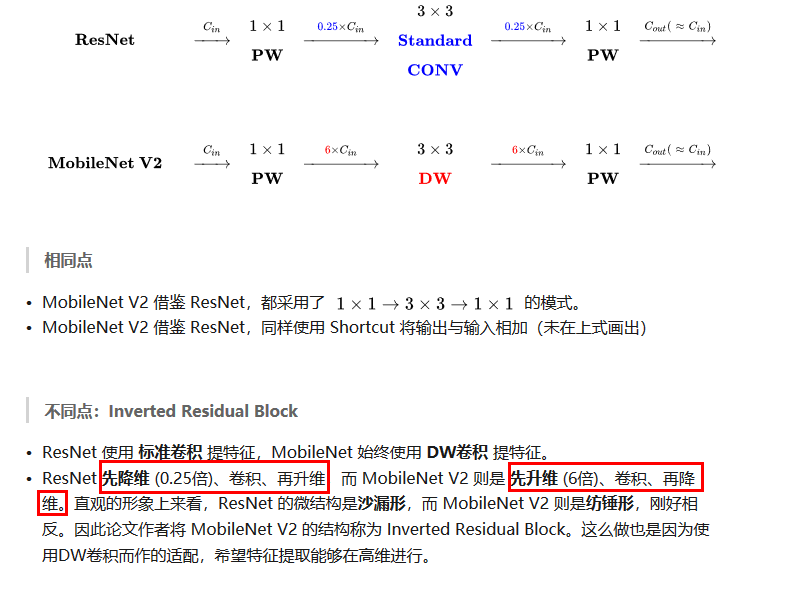
3.2 MobileNetV2
引入残差结构,先升维再降维,增强梯度的传播,显著减少推理期间所需的内存占用(Inverted Residuals)
去掉 Narrow layer(low dimension or depth) 后的 ReLU,保留特征多样性,增强网络的表达能力(Linear Bottlenecks)
网络为全卷积的,使得模型可以适应不同尺寸的图像;使用 RELU6(最高输出为 6)激活函数,使得模型在低精度计算下具有更强的鲁棒性
MobileNetV2 building block 如下所示,若需要下采样,可在 DWise 时采用步长为 2 的卷积;小网络使用小的扩张系数(expansion factor),大网络使用大一点的扩张系数(expansion factor),推荐是5~10,论文中 t = 6.
和 MobileNetV1 的区别

和 ResNet 的区别
3.3 MobileNetV3
2019年 https://arxiv.org/abs/1905.02244
v3版本结合了v1的深度可分离卷积、v2的Inverted Residuals和Linear Bottleneck、SE模块,利用NAS(神经结构搜索)来搜索网络的配置和参数。
MobileNetV3 首先使用 MnasNet 进行粗略结构的搜索,然后使用强化学习从一组离散的选择中选择最优配置。之后,MobileNetV3 再使用 NetAdapt 对体系结构进行微调,这体现了 NetAdapt 的补充功能,它能够以较小的降幅对未充分利用的激活通道进行调整。
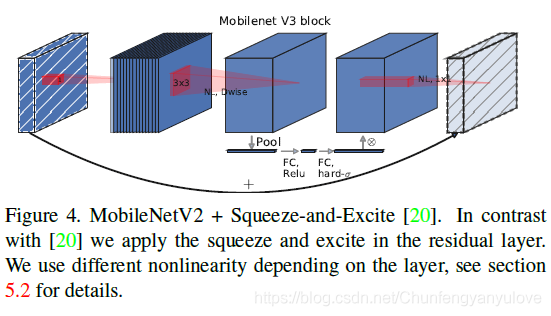
结构改进-引入se结构
SE结构会消耗一定的时间,所以作者在含有SE的结构中,将expansion layer的channel变为原来的1/4(可以看到图中的fc有一部分比较短)。这样作者发现,即提高了精度,同时还没有增加时间消耗。
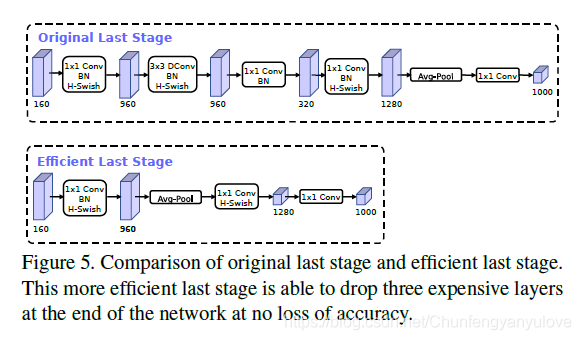
结构改进-修改avg pooling前的尾部
最后一个stage中的通道变化中存在冗余,原先的结构中输入通道为160,但是在avg pooling却被升维变成了1280。可以简化其中的升维流程。
结构改进-通道数减少
减少第一个卷积层的卷积个数(32 -> 16),在v1,v2版本第一层卷积核个数都是32的,在v3版本中我们只使用了16个。在原论文中,作者说将卷积核Filter个数从32变为16之后,它的准确率是和32是一样的,既然准确率没有影响,使用更少的卷积核计算量就变得更小了。这里节省了大概2ms的运算时间
结构改进-新的激活函数
v2版本使用的激活函数为relu6,现行主流激活函数为swish()。为了加速计算,用h-swish逼近swish。
4、darknet系列
darknet是yolo作者针对单阶段目标检测模型提出的backbone,整个yolo系列的模型都是使用darknet系列的模型做backbone的。darknet系列有darknet19、darknet53、csp_darknet等。【yoloV1的backbone为GoogLeNet with no inception modules】
4.1 darknet19
2017年 CVPR
yoloV2的backbone,吸收了vgg16、ini等网络的优点,其性能比vgg16优越,网络结构如下图所示。
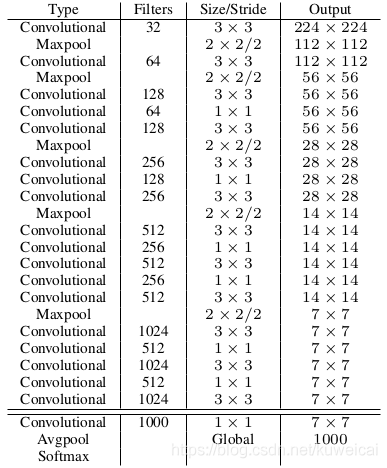
4.2 darknet53
2018年
YOLO V3的backbone。Darknet53网络的具体结构如图所示,仿照resnet50所提出,其性能比resnet50优越。
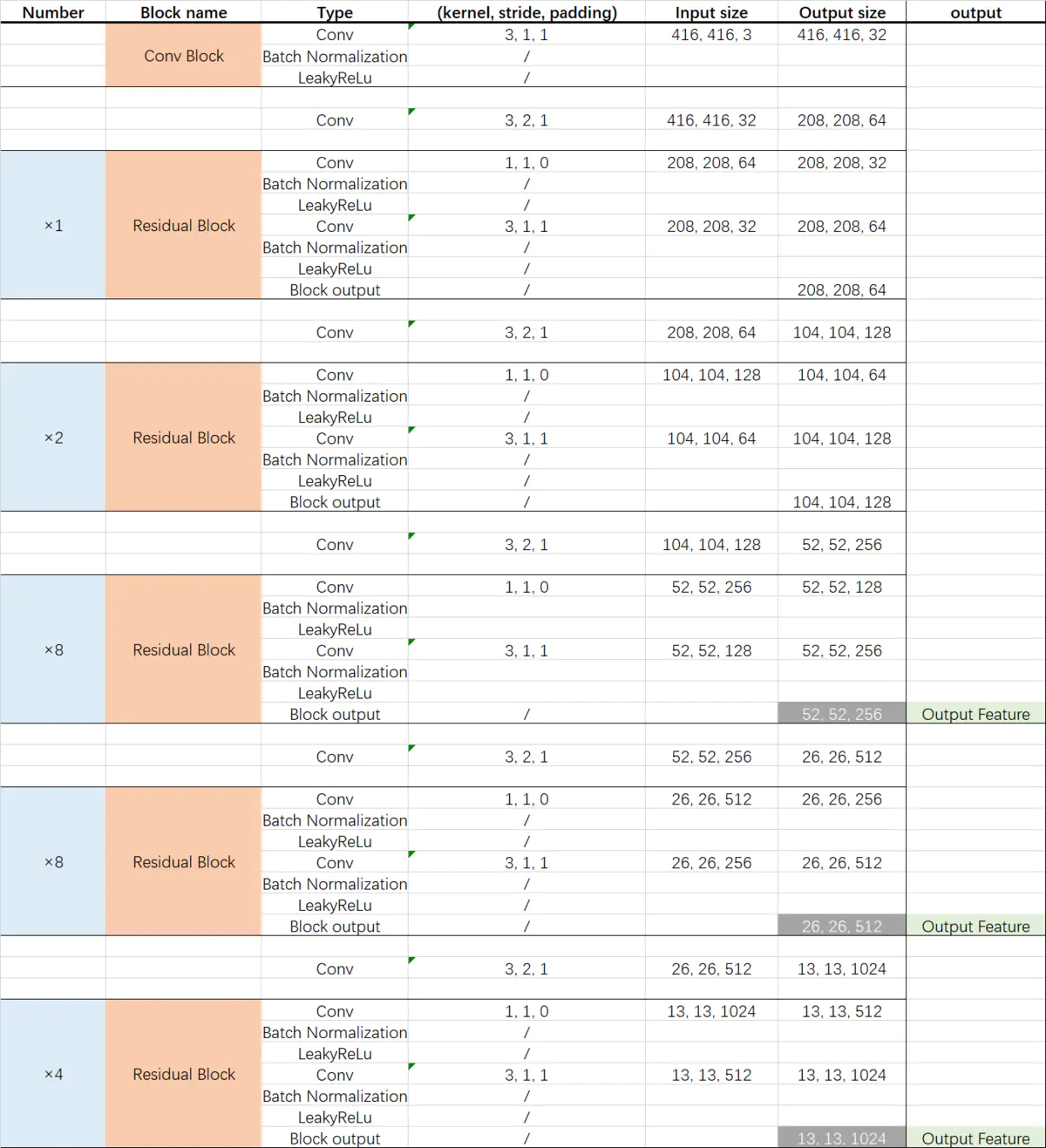
4.3 CSPDarkNet
yoloV4的backbone为CSPDarkNet53,与Darknet53相比将残差结构更改为csp dense结构
csp dense
CSPDenseNet的单级架构如图所示,CSPDenseNet的一个stage由部分dense block和部分transition layer组成。在partial Dense block中,stage中的base layer的特征图x0被分为了两部分[x00,x01],前者x00直接连接到舞台的末端,后者x01将通过dense block。在一个过渡层中所涉及的所有步骤如下:首先, [x01, x1, …, xk],将达到过渡层。其次,这个过渡层的输出xT将与x00连接,并经历另一个过渡层,然后生成输出xU
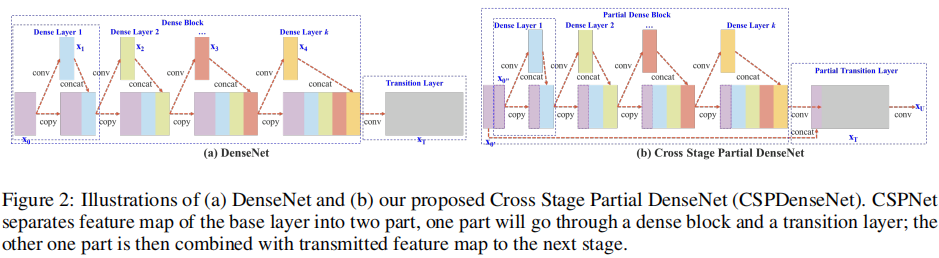
补充说明
yolox和yolov5的backbone也为CSPDarkNet,只是多了一个focus结构。
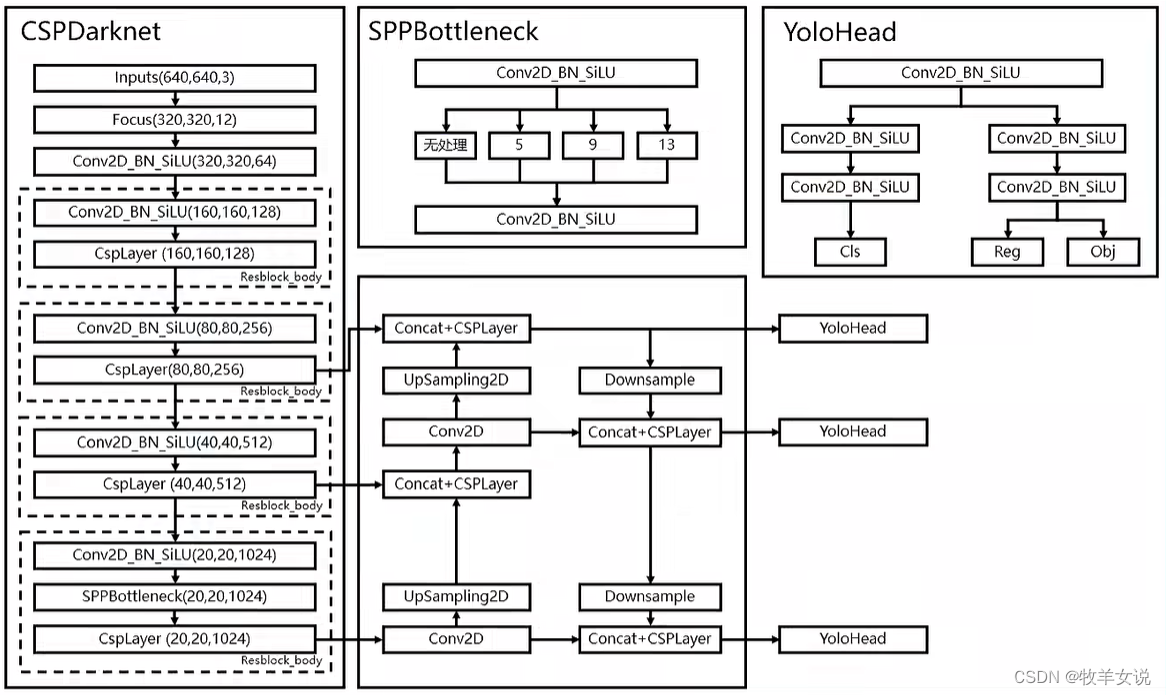
Focus网络结构
Focus结构的具体操作是,在一幅图像中行和列的方向进行隔像素抽取,组成新的特征层,每幅图像可重组为4个特征层,然后将4个特征层进行堆叠,将输入通道扩展为4倍。堆叠后的特征层相对于原先的3通道变为12通道,如下图所示
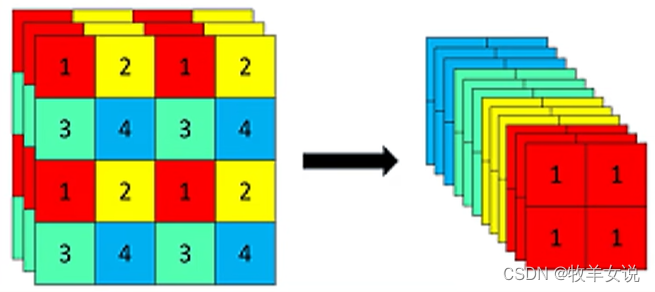
4.4 yolo其他模型的backbone
- YOLOv6的Backbone不再使用Cspdarknet,而是转为比Rep更高效的EfficientRep;它的Neck也是基于Rep和PAN搭建了Rep-PAN;而Head则和YOLOX一样,进行了解耦,并且加入了更为高效的结构。
- YOLOF的backbone为ResNet,You Only Look One-level Feature(YOLOF)
- YOLOE的backbone由CSPRepResStage(CSPNet+RMNet)构成,核心block为为RepRes-Block,通过结合Residual Connections和Dense Connections,用于YOLOE的主干和颈部。作者使用RepResBlock构建类似于ResNet的网络,称之为CSPRepResNet(图3(d),ESE制SE注意力模块)
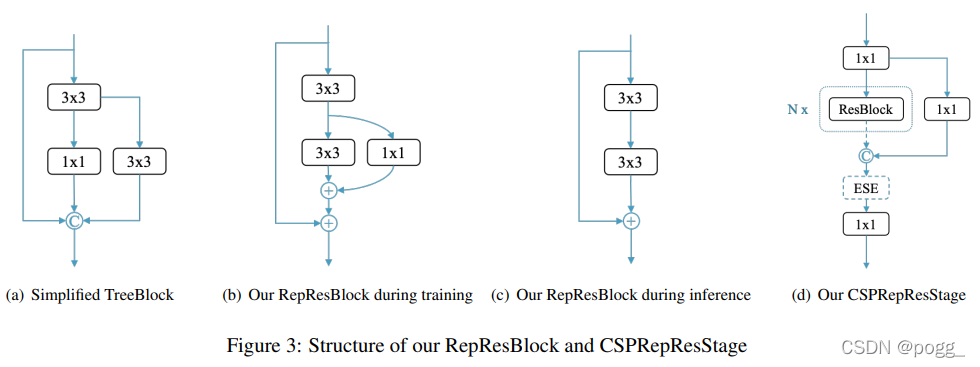
- YOLOv7的backbone为ELAN。ELAN结构通过控制最短最长的梯度路径,更深的网络可以有效地学习和收敛。基于ELAN设计的E-ELAN 用expand、shuffle、merge cardinality来实现在不破坏原有梯度路径的情况下不断增强网络学习能力的能力。

5、HRNet
高分辨率网络(HRNet)它能够在整个过程中维护高分辨率的表示。我们从高分辨率子网作为第一阶段始,逐步增加高分辨率到低分辨率的子网(gradually add high-to-low resolution subnetworks),形成更多的阶段,并将多分辨率子网并行连接。HRNet可以用作语义分割、目标检测中作为backbone。
hrnet系列模型有hrnet18、hrnet30、hrnet48、hrnet68
5.1 HRNetV1
hrnetv1的并行深度为3层

5.2 HRNetV2
hrnetv1的并行深度为4层

同时作者还提出了HRNetV2与HRNetV2P。HRNetV2只输出一个尺度(多次深度上采样成相同size),HRNetV2P输出多个尺度构成的特征金字塔(在v2的基础上构建金字塔)。
6、Vision Transformer
ViT是2020年Google团队提出的将Transformer应用在图像分类的模型(论文An image is worth 16×16 words: Transformers for image recognition at scale),虽然不是第一篇将transformer应用在视觉任务的论文,但是因为其模型“简单”且效果好,可扩展性强(scalable,模型越大效果越好),成为了transformer在CV领域应用的里程碑著作,也引爆了后续相关研究。
6.1 Pyramid Vision Transformer
2021年论文Pyramid Vision Transformer
普通的Vision Transformer在整个网络中,数据视野一直保持同样的大小,而PVT仿照CNN提出了Transformer的金字塔结构。与ViT不同的实验,PVT是将class_token进行了后置。
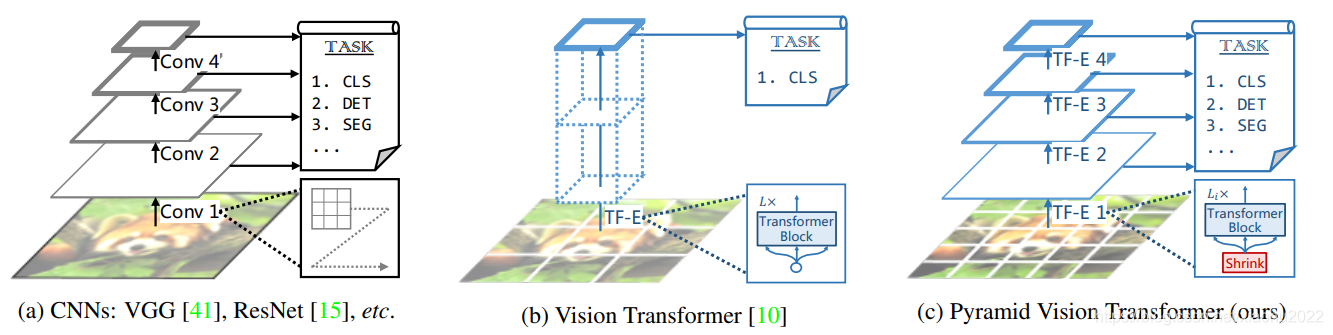
模型结构
PVT通过spatial-reduction Attention减少attention的计算量(与segformer里面的efficient attention是一样的,更多attention结构可以参考https://hpg123.blog.csdn.net/article/details/126538242)。
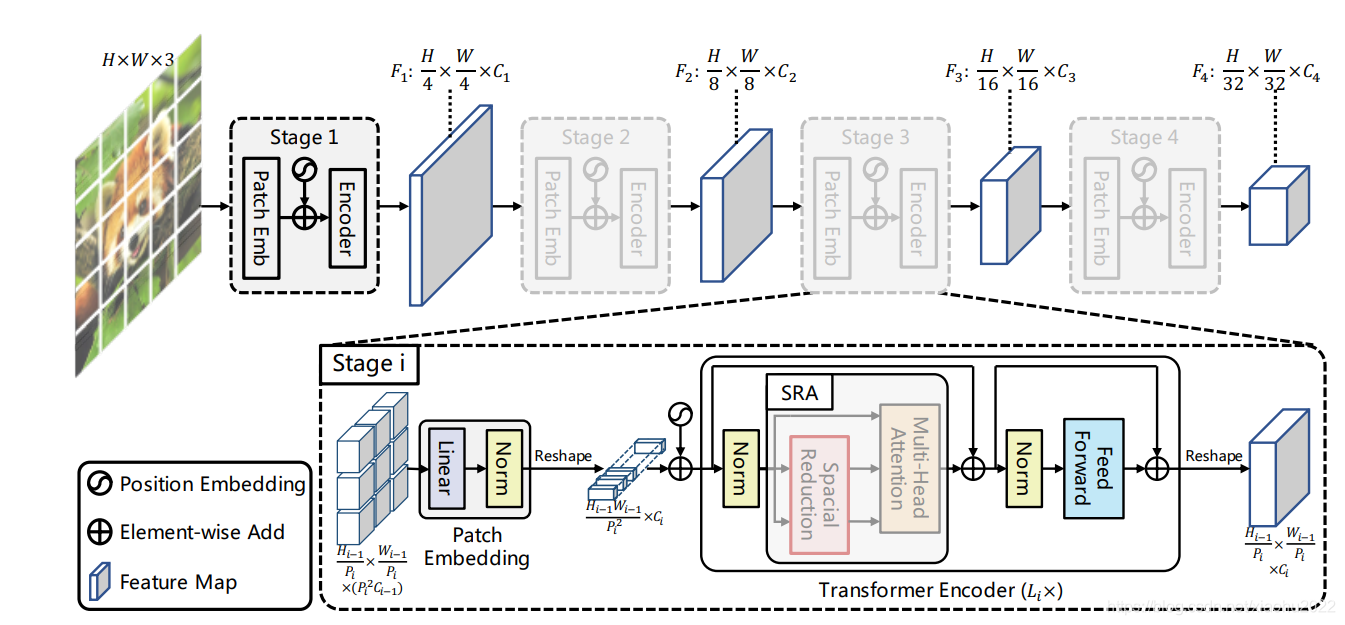
progressive shrink strategy(尺寸下降)
ViT结构在初始时将图像划分为多个相同大小的尺寸,从复杂度上考虑,这些patch的尺寸相对都比较大。而为了密集预测,这里在开始时将图像划分成较小的patch,比如4×4, 于是就获得了$ \frac{HW}{4^2} {4^2}C
{4^2}C=>4C
\frac{H}{4}\frac{W}{4}C $,这样子就实现了一次尺寸的下采样。
6.2 Swin Transformer
2021年论文 Swin Transformer: Hierarchical Vision Transformer using Shifted Windows
以下内容引用自 我不是zzk@知乎:https://zhuanlan.zhihu.com/p/367111046
目前Transformer应用到图像领域主要有两大挑战:
- 视觉实体变化大,在不同场景下视觉Transformer性能未必很好
- 图像分辨率高,像素点多,Transformer基于全局自注意力的计算导致计算量较大
针对上述两个问题,我们提出了一种包含滑窗操作,具有层级设计的Swin Transformer。
其中滑窗操作包括不重叠的local window,和重叠的cross-window。将注意力计算限制在一个窗口中,一方面能引入CNN卷积操作的局部性,另一方面能节省计算量。
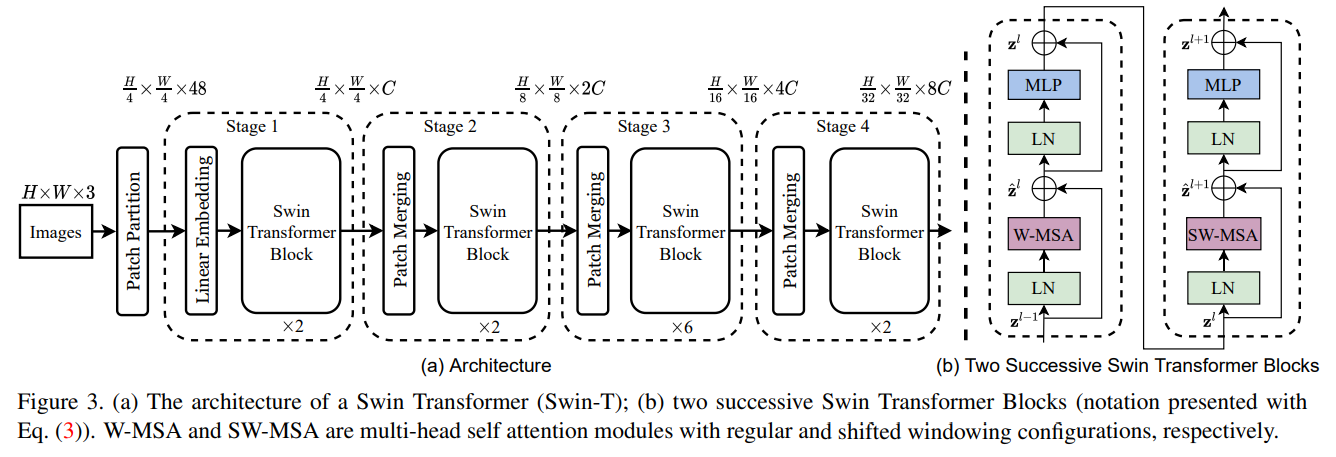
基本处理流程
整个模型采取层次化的设计,一共包含4个Stage,每个stage都会缩小输入特征图的分辨率,像CNN一样逐层扩大感受野。
- 在输入开始的时候,做了一个Patch Embedding,将图片切成一个个图块,并嵌入到Embedding。
- 在每个Stage里,由Patch Merging和多个Block组成。
- 其中Patch Merging模块主要在每个Stage一开始降低图片分辨率。
- 而Block具体结构如上述右图所示,主要是LayerNorm,MLP,Window Attention 和 Shifted Window Attention组成
与ViT的差异
其中有几个地方处理方法与ViT不同:
ViT在输入会给embedding进行位置编码。而Swin-T这里则是作为一个可选项(self.ape),Swin-T是在计算Attention的时候做了一个相对位置编码
ViT会单独加上一个可学习参数,作为分类的token。而Swin-T则是直接做平均,输出分类,有点类似CNN最后的全局平均池化层
Patch Merging
在行方向和列方向上,间隔2选取元素,然后拼接在一起作为一整个张量,最后展开。此时通道维度会变成原先的4倍(因为H,W各缩小2倍),此时再通过一个全连接层再调整通道维度为原来的两倍。

Window Attention
传统的Transformer都是基于全局来计算注意力的,而Swin Transformer则将注意力的计算限制在每个窗口内,进而减少了计算量。主要区别是在原始计算Attention的公式中的Q,K时加入了相对位置编码。
Shifted Window Attention
前面的Window Attention是在每个窗口下计算注意力的,为了更好的和其他window进行信息交互,Swin Transformer还引入了shifted window操作。
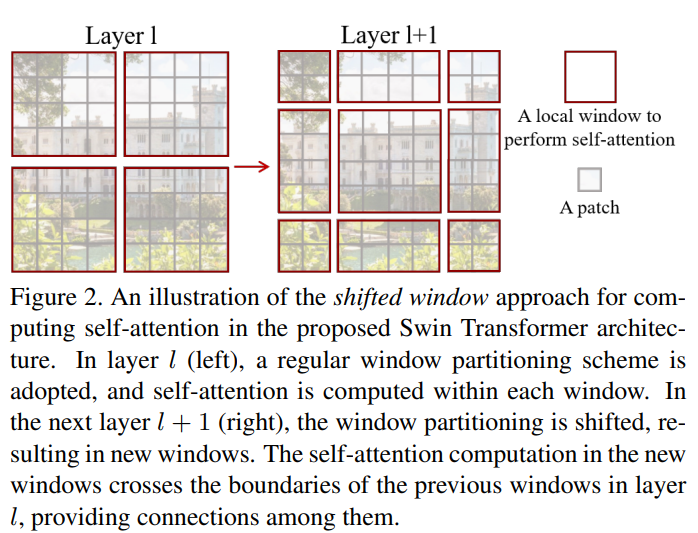
在实际代码里,我们是通过对特征图移位(代码里对特征图移位是通过torch.roll来实现),并给Attention设置mask来间接实现的。能在保持原有的window个数下,最后的计算结果等价。
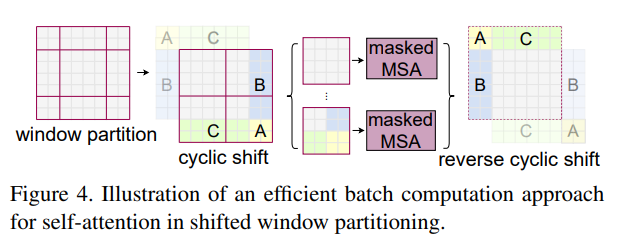
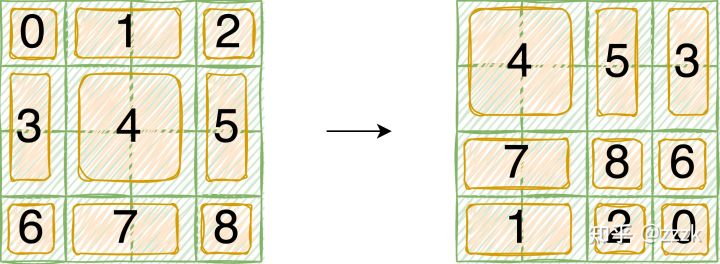
通过Attention Mask确定各个patch的注意力计算范围,如下图所示,5、3、7、1、8、6、2、0等区块因为连接的远处的信息,是在用mask使其attention仅在块内完成。
7 ConvNext
论文地址:https://arxiv.org/pdf/2201.03545.pdf
代码地址:https://github.com/facebookresearch/ConvNeXt
内容参考:https://m.thepaper.cn/baijiahao_16254490
2020s的卷积网络
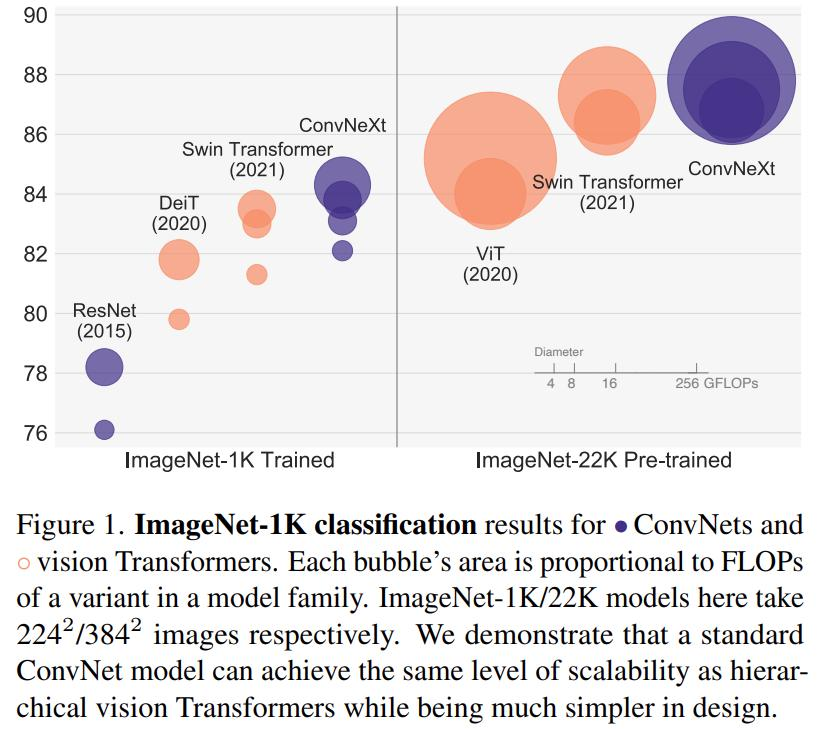
来自 FAIR 、UC 伯克利的研究者重新检查了设计空间并测试了纯 卷积网络 所能达到的极限。研究者逐渐将标准 ResNet「升级(modernize」为视觉 Transformer 的设计,并在此过程中发现了导致性能差异的几个关键组件。研究者将这一系列纯 ConvNet 模型,命名为 ConvNeXt。ConvNeXt 完全由标准 ConvNet 模块构建,在准确性和可扩展性方面 ConvNeXt 取得了与 Transformer 具有竞争力的结果,达到 87.8% ImageNet top-1 准确率,在 COCO 检测和 ADE20K 分割方面优于 Swin Transformer,同时保持标准 ConvNet 的简单性和有效性。
宏观研发路径
1、使用了 AdamW 优化器、Mixup、Cutmix、RandAugment、随机擦除(Random Erasing)等数据增强技术,以及随机深度和标签平滑(Label Smoothing)等正则化方案。这种改进的训练方案将 ResNet-50 模型的性能从 76.1% 提高到了 78.8%(+2.7%),这意味着传统 ConvNet 和视觉 Transformer 之间很大一部分性能差异可能是训练技巧导致的。
2、将每个阶段的块数从 ResNet-50 中的 (3, 4, 6, 3) 调整为 (3, 3, 9, s3),使得 FLOPs 与 Swin-T 对齐。这将模型准确率从 78.8% 提高到了 79.4%。
3、将 ResNet stem流程中的下采样替换为使用 4×4、步长为 4 的卷积层实现的 patchify 层,准确率从 79.4% 提升为 79.5%。这表明 ResNet 的主干架构可以用更简单的 patchify 层替代。
4、采用 ResNeXt [82] 的思路,ResNeXt 比普通的 ResNet 具有更好的 FLOPs / 准确率权衡。核心组件是分组卷积,其中卷积滤波器被分成不同的组。ResNeXt 的指导原则是「使用更多的组,扩大宽度」。按照 ResNeXt 中提出的策略,该研究将网络宽度增加到与 Swin-T 的通道数相同(从 64 增加到 96)。随着 FLOPs (5.3G) 的增加,网络性能达到了 80.5%。
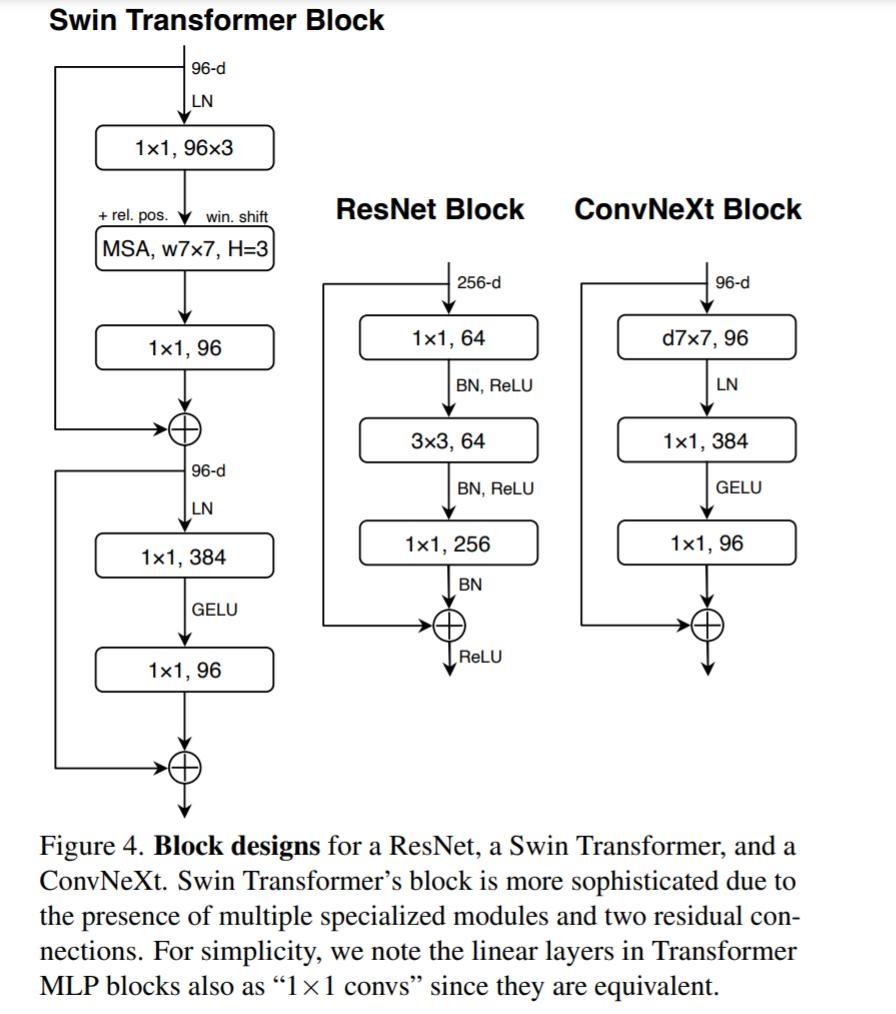
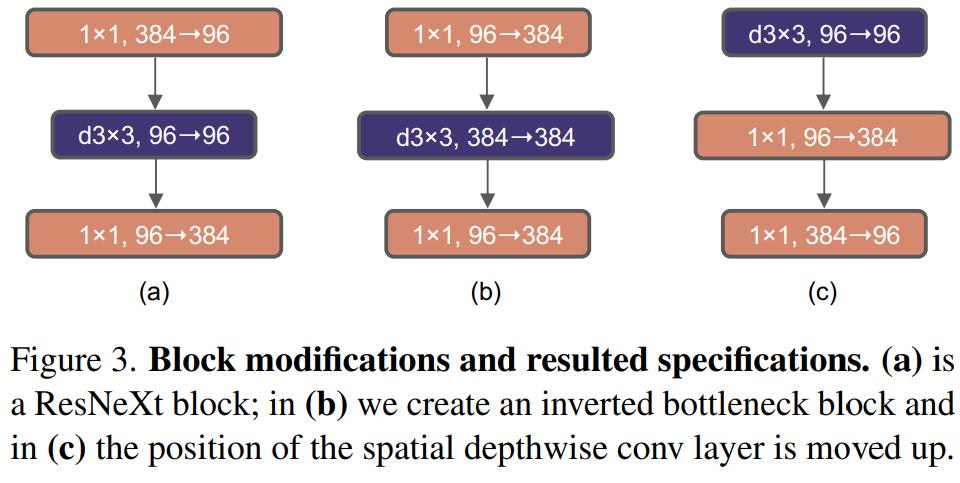
5、探索了反转瓶颈的设计。如下图 3 所示,尽管深度卷积层的 FLOPs 增加了,但由于下采样残差块的 shortcut 1×1 卷积层的 FLOPs 显著减少,整个网络的 FLOPs 减少到 4.6G。有趣的是,这会让性能从 80.5% 稍稍提高至 80.6%。在 ResNet-200 / Swin-B 方案中,这一步带来了更多的性能提升——从 81.9% 提升到 82.6%,同时也减少了 FLOPs。
6、探索了大型卷积核的作用。 Swin Transformer中窗口大小至少为 7×7,明显大于 3×3 的 ResNe(X)t 卷积核大小。因此这个中间步骤将 FLOPs 减少到 4.1G,导致性能暂时下降到 79.9%。经过上述准备工作,采用更大的卷积核是具有显著优势的。该研究尝试了几种卷积核大小:3、5、7、9、11。网络的性能从 79.9% (3×3) 提高为 80.6% (7×7),而网络的 FLOPs 大致保持不变。
微调路径
1、GELU 替代 ReLU 准确率保持不变(80.6%)
2、更少的归一化层。该研究删除了两个 BatchNorm (BN) 层,在 conv 1 × 1 层之前只留下一个 BN 层。这进一步将性能提升至 81.4%,已经超过了 Swin-T 的结果
3、用 LN 代替 BN。在原始 ResNet 中直接用 LN 代替 BN 性能欠佳。随着网络架构和训练技术的改进,该研究重新审视使用 LN 代替 BN 的影响,得出 ConvNet 模型在使用 LN 训练时没有任何困难;实际上,性能会改进一些,获得了 81.5% 的准确率。
4、分离式(Separate)下采样层。在 ResNet 中,空间下采样是通过每个 stage 开始时的残差块来实现的,使用 stride =2 的 3×3 卷积。在 Swin Transformer 中,在各个 stage 之间添加了一个分离式下采样层。该研究探索了一种类似的策略,在该策略中,研究者使用 stride =2 的 2×2 卷积层进行空间下采样。令人惊讶的是,这种改变会导致不同的训练结果。进一步调查表明,在空间分辨率发生变化的地方添加归一化层有助于稳定训练。该研究可以将准确率提高到 82.0%,大大超过 Swin-T 的 81.3%。
结构对比
ResNet-50、Swin-T 和 ConvNeXt-T 的详细架构规范的比较如表 9 所示。

coco数据集对比

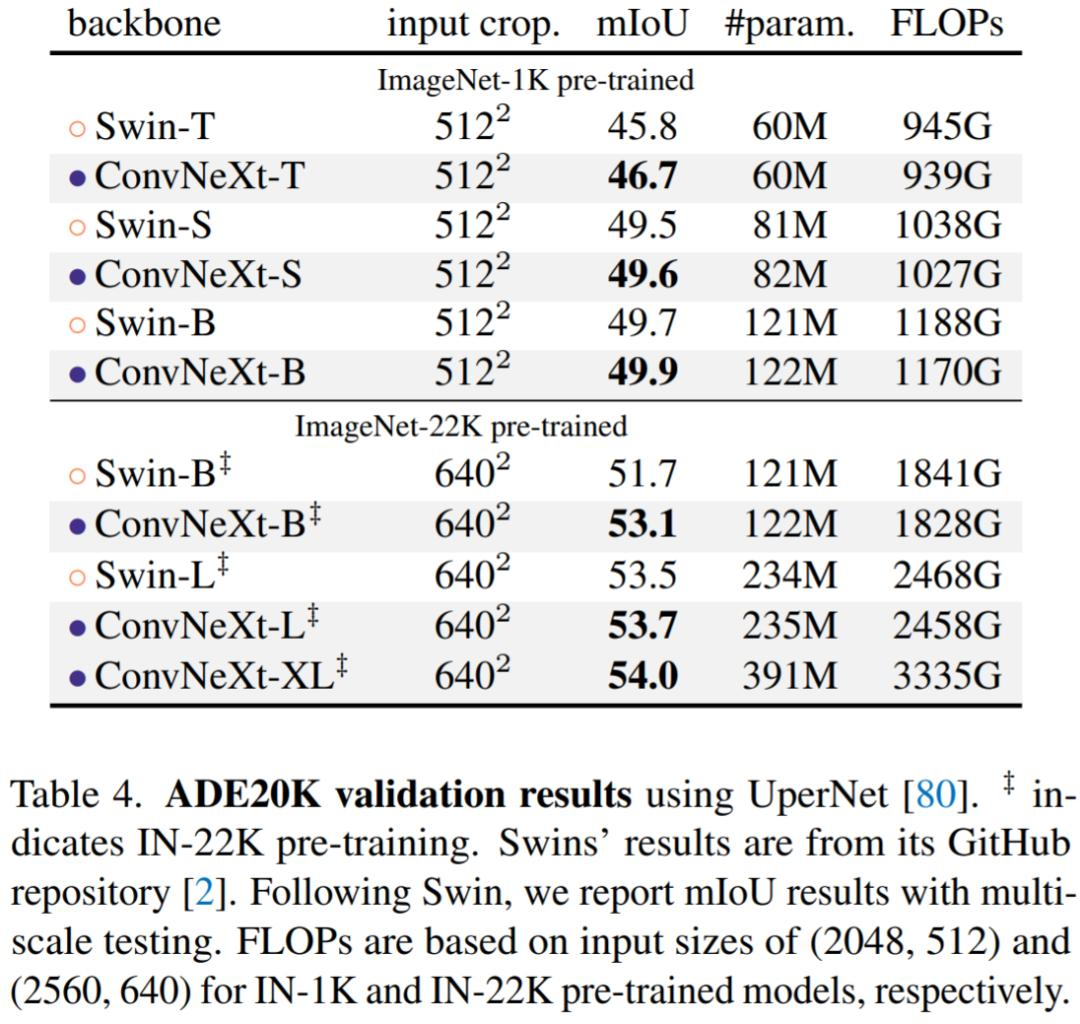
ADE20K 数据集对比
文章出处登录后可见!