FLAT: Chinese NER Using Flat-Lattice Transformer 论文解析
最近在研究NLP 的一些问题,这里是针对Transformer 做命名实体识别(NER) 任务的一个优化模型,这里是本人对这篇文章的一些理解,欢迎指正。
论文链接link
作者信息:
在此处插入图像描述
首先说一下这篇文章是做什么的,这篇文章对Transformer 做了改进,使中文的NER任务效果更好。
首先我们可以看下作者给出的例子,如下图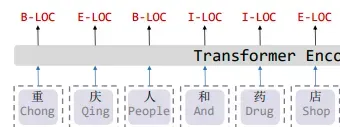
可以看到的是,在中文做NER 任务时,label 是与字粒度对应的,但是我们都知道,中文不同于英文,英文通过空格将word 切分开,使用这种方法可以 一个word 对应一个label。而中文是有分词的,如上文 如果成功分词为 重庆 人和药店,则效果不错,但是也有可能分词为 重庆人 和 药店, 造成错误。所以中文的NER 问题通常是字粒度。
动机
作者研究这种方法的动机为,栅栏结构已经被证明在中文NER方面是非常有效的,因为这种结构可以引入词信息。但是,由于这种结构是动态的且实现复杂,目前很多现有的模型都无法做到在GPU上的并行计算。
这篇文章中,作者提出了FLAT 它将晶格结构转换为由跨度组成的平面结构。 每个跨度对应于一个字符或潜在单词及其在原始格中的位置。 借助 Transformer 的强大功能和精心设计的位置编码,FLAT 可以充分利用点阵信息,并具有出色的并行化能力。
方法
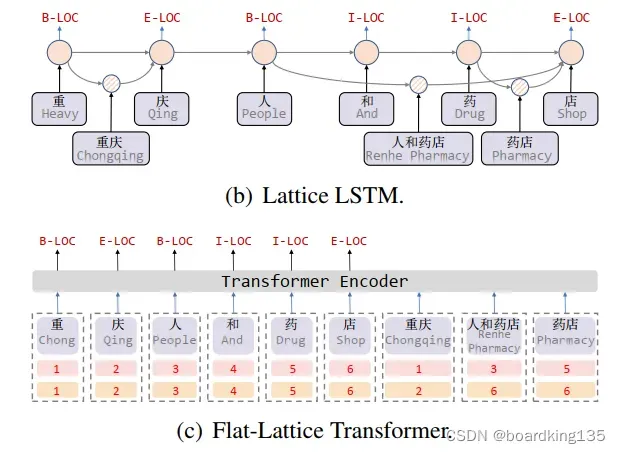
首先可以看图(b),可以看到的是,采用Lattice 的LSTM,会在字粒度之间不定点和不定量的生成一些词粒度信息,这种方法实现复杂且严重影响模型的并行计算能力。
作者的方法见©
但是 作者的图有问题,这里并不输入 词信息,而是将词信息的开始和结尾位置信息,仿照position embediding 的方式融入到词向量中。对position embediding 不清楚的同学可以看我的另一篇 attention is all you need 的解析。
如上图所示,通过对训练数据简单处理即可得到里面的词,然后得到词的首尾信息,作者在这里主要用词A 头 、尾 到 词B头、尾 的四种位置信息,然后通过transformer 的position embedding 的方式计算位置矩阵,对位置矩阵拼接后计算position encoding。
最后通过计算attention 的方式,将词的首尾信息融入。
具体公式如下:

文章出处登录后可见!