1. 写在前面
由于后面的工作会偏cv一些,所以这段时间抓住最后毕业的小尾巴抽出时间来想开一条cv的自学线路,和当时入门推荐差不多,cv这里也是简单的梳理了目前的一些方向以及各个方向常用的一些知识,然后各个方向进行学习和突破。 当然作为初学者,我依然还是从经典的模型开始,因为我发现,读论文学模型,然后做相关项目是比较快速的入门方式,但是呢, 这个过程中,我突然发现,对于cv来讲,基础的图像预处理操作也是非常重要的一大块,虽然做一些重大项目还是以大规模的深度学习(Deep learning)模型为主,但是,如何让模型能更好的学习到图像的特征,图像的相关特征工程(Feature Engineering),也是需要非常多的技术的,我觉得这是和推荐或者结构化数据不太一样的地方,图像数据有时候本身很复杂,同一张图片在不同的清晰度,颜色,亮度,轮廓等不同情况下,可能最后的模型识别效果会相差很大,所以对图像进行预处理操作,做细致的特征工程(Feature Engineering)也很重要,但图像的特征工程(Feature Engineering)方面,还需要一些针对图像的专门预处理的方式,比如图像的平滑(Smoothing),阈值(Threshold),增强,形态学,边缘目标检测,轮廓目标检测,模板匹配,滤波等,而这些技术如果能使用的好,就能很好把图像的特征给表现出来,能对后面模型的识别起到很大的作用,甚至可能模型都不用很复杂。这就是我要学习这块的原因。
OpenCV是一个专门针对图像处理的计算机视觉(Computer vision)的一个工具包,里面包含了大量的图像预处理操作,这次我从OpenCV开始学习,跟着唐宇迪老师的OpenCV入门教程学习的,这个教程是先讲图像的一些基本操作,比如变换,阈值(Threshold),平滑(Smoothing),形态学,算子,边缘目标检测,金字塔,轮廓,模板匹配以及傅里叶变换等,然后再通过几个实践项目来把前面知识融合起来,这正符合我的学习习惯。所以觉得还不错,目前到了项目实战部分,但由于前面的这些知识太多,好多都忘了,于是,就想先通过一篇文章,把之前学习到的这些东西总结一下,然后再通过后面的项目把知识融会一下。
主要内容:
- 对图像的基本操作(数据读取、通道分割、边界填充、图像融合、视频读取、阈值(Threshold)化)
- 图像平滑(Smoothing)和滤波(均值滤波器、中值滤波器、高斯(RBM Gaussian RBM)滤波器、低通滤波器和傅里叶)
- 图像的形态学运算(腐蚀、膨胀、开闭运算、黑帽礼帽等)
- 图像的算子操作(Sobel算子,Scharr算子,Laplacian算子)
- Canny边缘目标检测算法
- 图像金字塔(高斯(RBM Gaussian RBM)金字塔、拉普拉斯金字塔)
- 图像轮廓目标检测(绘图、特征提取、逼近等)
- 图片模板匹配
- 图像直方图和均衡
Ok, let’s go!
2. 图像的基本操作
2.1 图像读取
首先是图像的读取操作, opencv提供了cv2.imread函数, 帮助我们读取一张图片,主要有两种读取方式:
- cv2.IMREAD_COLOR: 默认的,读取彩色图像
- cv2.IMREAD_GRAYSCALE: 读取灰度图像
这是代码示例:
def cv_show(name, img, wait_key=0):
# 图像的展示, 也可以创建多个窗口
cv2.imshow(name, img)
# 展示时间, 毫秒级, 0表示任意键终止
cv2.waitKey(wait_key)
cv2.destroyAllWindows()
img=cv2.imread('img/cat.jpg')
# 读取灰度图
# 单通道的图一定是灰度图, 而三通道的图也可以有灰度模式,即R,G,B三个通道的亮度一致,即RGB三通道的值改成一样? 那么改成啥呢?
# 这里其实是要做灰度转换的, 涉及到灰度转换算法了
img_gray = cv2.imread("img/cat.jpg", cv2.IMREAD_GRAYSCALE)
img.shape, img.dtype等
# ndarry的形式,所以支持切片处理, 拿到部分像素值
img_part = img_gray[0:200, 0:200]
cv_show('cat', img_part)
这里读取的img其实就是numpy数组,所以np数组的一些属性这里的img都会有,并且既然是numpy数组,也能够进行基本的四则运算来改变图像的像素值大小。
2.2 颜色通道
cv2.split功能划分图片的三个通道
b, g, r = cv2.split(img)
# 三个通道也可以融合起来
img_merge = cv2.merge((b, g, r))
# 只保留某个通道
# 只保留某个通道, 这里写个函数
def get_channel_img(img, stay_channel=0):
# B, G, R 是 0, 1, 2
cur_img = img.copy()
for i in range(3):
if i != stay_channel:
cur_img[:, :, i] = 0
return cur_img
blue_channel_img = get_channel_img(img, 0)
green_channel_img = get_channel_img(img, 1)
red_channel_img = get_channel_img(img, 2)
这里补充一下点灰度、单通道、三通道的知识:
- 单通道: 维度数2, 或者第三维是1, 也称灰度图,理解成黑白图
- 图像每个像素点只能有一个值表示颜色, 值在0-255, 这样的图是单通道值,或者灰度图, 0是全黑, 255全白
- 三通道图是每个像素点3个值表示颜色, 比如GRB, 如果某个位置三个通道值相同, 图片也是黑白色,这种是彩色图的灰度模式
- 判断一张灰度图是单通道还是三通道黑白颜色的图, 看图片属性的位深度, 单通道的是8, 三通道黑白是24
如果要将单个通道转换为三个通道,可以使用以下函数:
# 单通道转成三通道
r2img = cv2.cvtColor(img_gray, cv2.COLOR_GRAY2RGB)
cv_show('img', r2img)
2.3 边界填充
这里用的cv2.copyMakeBorder函数。这里就类似于图像的padding操作, 不过是在预处理过程中,我们自定义方式进行的padding,具体使用示例如下:
# 上下左右分别填充的大小
top_pad, bottom_pad, left_pad, right_pad = 50, 50, 50, 50
# 有不同的填充方式
def img_pad(img, top_pad, bottom_pad, left_pad, right_pad, mode=cv2.BORDER_REPLICATE, value=0):
if mode == cv2.BORDER_CONSTANT:
pad_img = cv2.copyMakeBorder(img, top_pad, bottom_pad, left_pad, right_pad, borderType=mode, value=value)
else:
pad_img = cv2.copyMakeBorder(img, top_pad, bottom_pad, left_pad, right_pad, borderType=mode)
return pad_img
replicate = img_pad(img, top_pad, bottom_pad, left_pad, right_pad, cv2.BORDER_REPLICATE)
reflect = img_pad(img, top_pad, bottom_pad, left_pad, right_pad, cv2.BORDER_REFLECT)
reflect101 = img_pad(img, top_pad, bottom_pad, left_pad, right_pad, cv2.BORDER_REFLECT_101)
wrap = img_pad(img, top_pad, bottom_pad, left_pad, right_pad, cv2.BORDER_WRAP)
constant = img_pad(img, top_pad, bottom_pad, left_pad, right_pad, cv2.BORDER_CONSTANT, value=0)
这里有几个属性:
- cv2.BORDER_REPLICATE: 复制法, 复制最边缘像素
- cv2.BORDER_REFLECE: 反射法,对感兴趣的图像中的像素在两边进行复制, 比如原图abcdefg, 那么两边填充之后,fedcba|abcdefg|gfe
- cv2.BORDER_REFLECT_101: 反射法, 以最边缘像素为轴, 对称 gfedcb|abcdefg|fedcba
- cv2.BORDER_WRAP: 外包装法 cdefg|abcdefg|abcdef
- cv2.BORDER_CONSTANT: 常数值填充
2.4 图像融合
图像融合的需求是两张图片融合成一张,本质上还是像素之间的操作,但前提: shape必须一致,并且我们还可以给不同图片加权,可以用cv2.add_weight函数。
img_dog = cv2.imread('img/dog.jpg')
# 把狗和猫的成分按照比例融合在一起
# img + img_dog 这个直接相加不行 ,因为shape不一样
# 转成一样的先
img_dog = cv2.resize(img_dog, (666, 548)) # 这里注意下后面参数, 这里的是先指定宽, 再指定高
img_dog.shape
# resize 还能这么玩 cv2.resize(img, (0, 0), fx=4, fy=1) 这个是不知道具体大小,而是让x,y轴按照倍数伸长或者缩短
# 进行融合
res = cv2.addWeighted(img, 0.4, img_dog, 0.6, 0) # aplha * img + beta * img_dog + b
2.5 视频读取
OpenCV可以读取视频的,使用cv2.VideoCaptuer函数, 视频是很多帧的图片组成,所以读取视频,本质上还是需要拿到每一帧图像,对图像进行处理。
vc = cv2.VideoCapture("img/test.mp4") # 从网上现下载了一个视频
# 目标检测是否打开正确
if vc.isOpened():
open, frame = vc.read()
else:
open = False
# 读取完视频后,将视频进行拆分成每一帧进行操作
while open:
ret, frame = vc.read()
# 如果当前没有帧,停掉
if frame is None:
break
if ret == True:
gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
cv2.imshow("result", gray)
if cv2.waitKey(10) & 0xFF == 27:
break
vc.release()
cv2.destroyAllWindows()
2.6 图像的阈值(Threshold)操作
阈值(Threshold)操作,就是对某张图片,根据给定的阈值(Threshold)进行像素改变,比如大于某个阈值(Threshold)或者小于某个阈值(Threshold)的像素点,我们给他改成多少。 这里使用的cv2.threshold函数, 里面4个参数:
ret, dst = cv2.threshold(src, thresh, maxval, type)
- src: 输入(input)图像,只能是单通道图像,通常来说是灰度图
- dst: 输出图
- thresh: 阈值(Threshold), 大于多少的或者小于多少的进行处理, 一般是127
- maxval: 当像素值超过了阈值(Threshold)(或者小于阈值(Threshold)的,根据type来决定)所赋予的值, 一般255
- type: 二值化操作类型,包括下面五种类型:
- cv2.THRESH_BINARY: 超过阈值(Threshold)部分取maxval,否则取0
- cv2.THRESH_BINAEY_INV: 上面的相反
- cv2.THRESH_TRUNC: 大于阈值(Threshold)部分设置为阈值(Threshold),否则不变(invariant)
- cv2.THRESH_TOZERO: 大于阈值(Threshold)部分的不改变,否则设为0
- cv2.THRESH_TOZERO_INV: 上面这个反转
这里可以看一个应用示例,感受一下效果:
# 数据读取 opencv读取的格式是BGR, 不是RGB,所以图片展示的时候,最好是使用opencv自带的工具函数
import cv2
import matplotlib.pyplot as plt
img_gray = cv2.imread("img/cat.jpg", cv2.IMREAD_GRAYSCALE)
ret, thresh1 = cv2.threshold(img_gray, 127, 255, cv2.THRESH_BINARY) # 像素大于127的替换成255, 小于127的换成0 255是最亮,白
ret, thresh2 = cv2.threshold(img_gray, 127, 255, cv2.THRESH_BINARY_INV) # 像素大于127的换成0, 大于127的换成255
ret, thresh3 = cv2.threshold(img_gray, 127, 255, cv2.THRESH_TRUNC) # 大于127的换成255, 其余不变(invariant), 这个相当于截断
ret, thresh4 = cv2.threshold(img_gray, 127, 255, cv2.THRESH_TOZERO) # 大于127的不改变,小于127的变成0
ret, thresh5 = cv2.threshold(img_gray, 127, 255, cv2.THRESH_TOZERO_INV) # 大于127的变成0, 小于127的不改变
titles = ['original image', 'binary', 'binary_inv', 'trunc', 'tozero', 'tozero_inv']
images = [img, thresh1, thresh2, thresh3, thresh4, thresh5]
for i in range(6):
plt.subplot(2, 3, i+1), plt.imshow(images[i], 'gray')
plt.title(titles[i])
plt.xticks([]), plt.yticks([])
plt.show()
结果如下:
3. 图像的平滑(Smoothing)处理
图像过滤一般有两个目的:
- 提取对象的特征作为图像识别的特征模式
- 适应图像处理要求,消除图像数字化中混入的噪声
过滤处理也有两个要求:
- 图像的轮廓和边缘等重要信息不会被损坏
- 使图像清晰,视觉效果好
平滑(Smoothing)滤波是一种低频增强空间滤波技术,主要目的是模糊或消除图像噪声。
空间域的平滑(Smoothing)滤波一般采用简单平均法,即得到相邻像素点的平均亮度值。邻域的大小与平滑(Smoothing)效果直接相关。邻域越大,平滑(Smoothing)效果越好。但是,如果邻域过大,平滑(Smoothing)会造成较大的边缘信息丢失,使输出图像变得模糊。因此,需要合理的选择。邻里的大小。
以过滤在我们生活中的应用为例:美容的微晶换肤功能。如果将我们脸上的凹凸与噪音进行比较,那么过滤算法可以消除噪音并使我们的自拍皮肤看起来更光滑。
常用的滤波方法:均值滤波、中值滤波和高斯(RBM Gaussian RBM)滤波。
3.1 均值滤波
均值滤波就是将中心点的值替换为周围相似点的平均值,边缘部分保持不变(invariant),比如下面的例子:
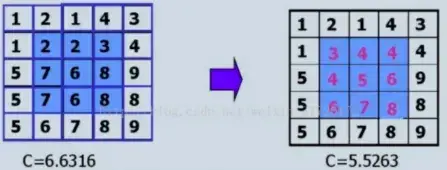
cv2.blur函数可以实现均值滤波,代码示例:
# 均值滤波
# 简单的平均卷积(convolution)操作
blur = cv2.blur(img, (3, 3)) # 3*3是卷积(convolution)核的大小
cv_imshow('blur', blur) # 真实实现的时候,其实这个卷积(convolution)核的参数是[[1,1,1], [1,1,1], [1,1,1]] * 1/9 用这样的卷积(convolution)核卷上面图片
缺陷:均值滤波器本身存在先天缺陷,即不能很好地保护图像细节,在对图像进行去噪(denoising)的同时也破坏了图像的细节,使图像变得模糊,不能很好地去除噪声点。尤其是椒盐噪声。
3.2 中值滤波
中值滤波就是将中心点和周围像素从小到大排序,用中值代替中心点的值。最终的值必须是周围的圆和自身的某个值,这样比较连贯。均值滤波器是所有值的平均值。一旦这些点的距离相差很大,一旦平均,原始图像就会被破坏。这就是为什么在均值滤波后图像变得模糊的原因。但是均值滤波在处理高斯(RBM Gaussian RBM)噪声时很有用。
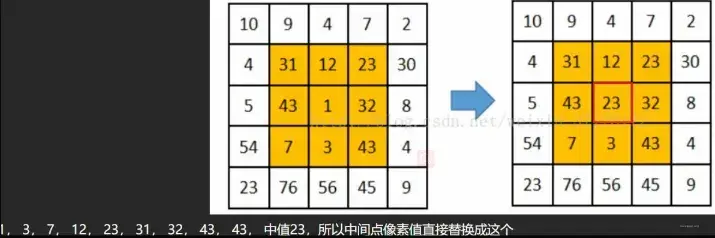
cv2.medianBlur函数实现中值滤波:
# 中值滤波
img_median = cv2.medianBlur(img, 5)
均值滤波 VS 中值滤波:
- 两者都可以起到平滑(Smoothing)图像和过滤噪声的作用
- 均值滤波器使用线性方法对整个窗口范围内的像素值进行平均。均值滤波器本身就有先天的缺陷,即不能很好地保护图像的细节,而且在对图像进行去噪(denoising)的同时也破坏了图像的细节,使得图像变得模糊,并不能很好地去除噪声点。均值滤波器在高斯(RBM Gaussian RBM)噪声上表现更好,但在椒盐噪声上表现更差
- 中值滤波器采用非线性方法,对平滑(Smoothing)脉冲噪声非常有效。同时可以保护图像的锐利边缘,选择合适的点来代替污染点的值,所以处理效果好,椒盐噪声的表现更好。对高斯(RBM Gaussian RBM)噪声的性能较差。
3.3 高斯(RBM Gaussian RBM)滤波
高斯(RBM Gaussian RBM)滤波是指卷积(convolution)核的参数符合高斯(RBM Gaussian RBM)分布(Gaussian distribution)(Distribution)。与均值滤波类比更容易理解。对于均值滤波,它是周围点和中心点的平均值。所谓均值是指所有像素的权重相同。这样就相当于周围点对中心点的贡献度相同,不是很合理。因为从像素点来看,周围像素点的值越接近中心点,权重越大。所以高斯(RBM Gaussian RBM)分布(Gaussian distribution)(Distribution)就是这样,根据像素点距离中心点的权重分配不同的权重参数。
# 高斯(RBM Gaussian RBM)滤波
# 高斯(RBM Gaussian RBM)滤波的卷积(convolution)核里面的参数满足高斯(RBM Gaussian RBM)分布(Gaussian distribution)(Distribution),相当于给周围的像素值根据距离中心点的远近加一个权重
aussian = cv2.GaussianBlur(img, (3, 3), 1)
cv_imshow('aussian', aussian)
看看下面三个滤镜对椒盐噪声图像的处理效果:
以下是一些想法:
- 上面的过滤器实际上是一个卷积(convolution)核。内核上的参数不同,代表不同的算法。
- 均值滤波器周围点的贡献率相同,高斯(RBM Gaussian RBM)滤波器核的参数与到中心像素的距离有关。距离越近,权重越大,相当于对周围像素进行加权。
- 均值滤波不适用于消除椒盐噪声,我是这样理解的, 椒盐噪声的话就是那些白点, 像素值255, 而均值滤波的话,是取周围像素的均值,虽然能平滑(Smoothing)这些白色点了,但是像普通的那些点,或者不是噪声的尖锐边缘,用这种方式也一下子平滑(Smoothing)掉了, 所以会使得图像变得模糊, 而中值滤波的话, 白色点那里取的是中值, 而其他点也是取中值, 而取中值的意思是必定取它周围那一圈里面的,这样在视觉效果上看更加平滑(Smoothing)些,所以从效果上比较清晰
由于上面已经整理了简单的滤波操作,为了知识的连贯性,我这里再整理一点知识,带来后面学到的低高通滤波。
3.4 低高通滤波与傅里叶变换
我们知道傅里叶变换是将图像从时域转换到频域的非常有力的武器。时域中的图像数据是我们看到的由像素组成的图片,而在频域中,我们可以得到灰度分量的频率。也许图像看起来不是很容易理解,用一种语言来描述它最合适:假设(Hypothesis)我们录制了一种语言,其中混合(Mixing)了各种声音。从时域的角度来看,这是一段按时间序列组成的音频,那么我们有办法去除这段音频的噪声,只保留重要的音频信息吗?其实这在时域是很难做到的,但是当你转到频域的时候,你会发现这些声音是由不同频率的声线组成的,很容易过滤掉一些声音我们要通过频率。 .所以通过傅里叶变换操作,我们可以很方便的取出图像或声音中一些我们需要的灰度分量。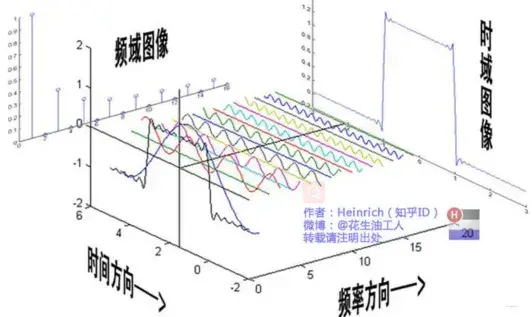
那么回到图像中,也会有高频或低频的灰度分量:
- 高频:灰度变化剧烈的分量,比如图片中的边界信息,相当于从一个物体变为另一个物体,像素值变化很大
- 低频:灰度变化缓慢的成分,如大海,像素值变化很小
基于频率的滤波主要有两种类型:
- 低通滤波器:只保留低频,这会使图像模糊,高频没有了,这样边界就没有了
- 高通滤波器:只保留高频,会增强图像细节,也就是边缘锐化的感觉
在opencv中的函数:
- opencv中主要是 cv2.dft() 和 cv2.idft() , 输入(input)图像需要先转成np.float32格式, cv2.dft 就是把时域转成了频域,但是为了显示,还需要进行逆变换,即 cv2.idft()
- 得到的结果中频率为0的部分会在左上角, 通常要转换到中心位置, 可以通过shift变换来实现。
- cv2.dft()返回的结果是双通道的(实部,虚部), 通常还需要转换成图像格式才能展示(0,255)
下面总结了低通滤波和高通滤波的过程:
- 原始图像 -> cv2.ift -> 得到频域图像dft -> 低频信息移到中间( np.fft.fftshift ) -> 这个结果是双通道(实部+虚部) -> 转成图像格式 cv2.magnitude
- 找中心点 -> 制作mask掩码(mask)矩阵(matrix) -> 频域图像 dft* mask -> 得到过滤之后的频域图像 fshift
- 过滤掉高频信息的频域图像fshift -> 低频信息移动到原来位置( np.fft.ifftshift ) -> 傅里叶逆变换 cv2.idft -> 转成图像格式 cv2.magnitude
这就是整个的处理逻辑, 高通滤波和低通滤波只是保留的频率不一样,所以区别在于制作的mask矩阵(matrix)上,但整体逻辑是一样的, 下面我把高通滤波和低通滤波操作封装成了一个函数:
# 下面是代码总结
def dft_idft(img, threshold=30, mode='low'):
img_float = np.float32(img) # 转成float
# 时域 -> 频域
dft = cv2.dft(img_float, flags=cv2.DFT_COMPLEX_OUTPUT)
# 把低频值转到中间位置
dft_shift = np.fft.fftshift(dft) # 低频值转到中心位置
# 掩码(mask)矩阵(matrix)
row, col = img.shape
c_row, c_col = int(row/2), int(col/2)
if mode == 'low':
mask = np.zeros((row, col, 2), np.uint8)
mask[c_row-threshold:c_row+threshold, c_col-threshold:c_row+threshold] = 1
elif mode == 'high':
mask = np.ones((row, col, 2), np.uint8)
mask[c_row-threshold:c_row+threshold, c_col-threshold:c_row+threshold] = 0
else:
print("参数错误")
return
# 下面就是用这个滤波器对频域的那个图像做操作
fshift = dft_shift * mask
f_ishift = np.fft.ifftshift(fshift) # 之前是低频信息shift到了中间位置,而这个操作是从中间位置变到原来位置
img_back = cv2.idft(f_ishift) # 逆变换
img_back = cv2.magnitude(img_back[:, :, 0], img_back[:, :, 1])
return img_back
# 低通滤波和高通滤波
img_low = dft_idft(img, mode='low')
img_high = dft_idft(img, mode='high')
让我们可视化效果:
高频滤波和低频滤波的作用是在频域过滤原始图像的相关频率信息。在频域中,图像实际上是有层次的,因此通过将时域图像转换为频域,我们可以很容易地得到图像的层次信息,这对于过滤高频或低频信息非常重要。
4. 图像的形态学操作
所谓形态学操作,我理解,就是对图像本身进行一些预处理,比如让图像中的线条变粗或者变细,突出图像的某些部分,去除图像中的毛刺,处理一些缺陷等等。
图像形态学中两种常用的操作是腐蚀和膨胀。侵蚀一般用于处理毛刺问题,可以使线条或图形变细。膨胀一般是为了填补一些缺陷,可以使线条变粗。
4.1 腐蚀操作
腐蚀操作一般处理图像的毛刺,原理如下:
我们事先定义了一个kernel,是一个的全1的卷积(convolution)核, 指定这样的kernel之后, 就开始对输入(input)的图像进行卷积(convolution)操作, 对于当前的
区域, 卷积(convolution)核会这样目标检测:
- 如果
的当前图像区域是全白的,那么当前
区域的中心点的像素值保持不变(invariant)
- 如果当前
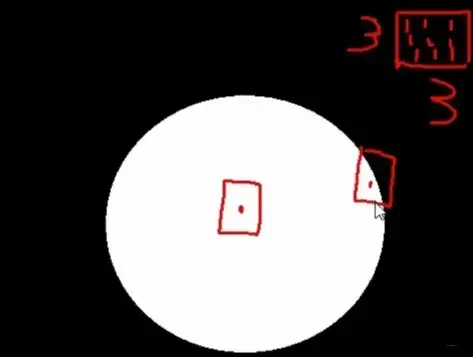
看上面这两个中心点,右边的中心点会被腐蚀掉, 并且这个中心点之外的点也都会被腐蚀掉, 因为的区域肯定白色和黑色都有。 这样,迭代一次,就能把一些中心点变成黑色, 再迭代一次, 又会有一些点被腐蚀掉。 所以上面腐蚀操作虽然会去掉毛刺,但笔也变细了,而iteration就是控制迭代次数的, 迭代次数越多, 白色被腐蚀的越厉害。 当然,这个腐蚀程度也和卷积(convolution)核大小有关,
的估计迭代1次就很细了, 这个也非常好理解,毕竟中心点周围的区域大了, 而只有这里面黑白兼有,这个点就要被腐蚀掉。 所以大的卷积(convolution)核使得中心点被腐蚀性的概率会更大。
应用示例:
img = cv2.imread('img/dige.png')
cv_imshow('img', img)
kernel = np.ones((3, 3), np.uint8)
erosion_img = cv2.erode(img, kernel, iterations = 1)
cv_imshow('erosion_img', erosion_img)
效果如下:
卷积(convolution)核越大,或者迭代次数越多,右边的线越细。
4.2 膨胀操作
经过上面的腐蚀操作,虽然可以去除图像中的一些毛刺,但是腐蚀越多,线条也会变细,那我们能不能把它加粗一点呢?让画面的线条更丰满?这就是通货膨胀的作用。
这个原理也很容易理解:
- 同样是那个3*3的卷积(convolution)核卷,只不过对当前中心点处理不一样了:
- 如果当前中心点周围区域有黑白,则将当前值变为白色
- 如果当前中心点全黑,则无变化
迭代次数和卷积(convolution)核越大越有利于展开操作,越胖
# 下面尝试把上面腐蚀的图片弄成胖一点的
kernel = np.ones((3, 3), np.uint8)
dige_dilate = cv2.dilate(erosion_img, kernel, iterations=1)
cv_imshow('dilate_img', dige_dilate)
# 对线条起了加粗的效果
看看效果:
研究发现:
- 腐蚀算法: 用
的卷积(convolution)核扫描每个元素, 用卷积(convolution)核与其覆盖的二值图像做”与”操作,如果都是1, 那么结果中心元素像素值是1, 否则是0
- 膨胀算法: 猜一下,
但,全0的卷积(convolution)核发现并不会改变图像。
4.3 开闭运算
类似于将腐蚀和膨胀操作连接在一起的数据流(stream)程:
- 开运算 cv2.MORPH_OPEN : 先腐蚀,后膨胀
- 闭运算 cv2.MORPH_CLOSE : 先膨胀,后腐蚀
代码显示如下:
img = cv2.imread('img/dige.png')
cv_imshow('img', img)
# 开运算: 先腐蚀,再膨胀
kernel = np.ones((5, 5), np.uint8)
opening = cv2.morphologyEx(img, cv2.MORPH_OPEN, kernel)
cv_imshow('opening', opening)
这样也可以达到去毛刺的效果,也就是先腐蚀后膨胀,效果和之前的线粗度差不多。
# 闭运算: 先膨胀后腐蚀
closing = cv2.morphologyEx(img, cv2.MORPH_CLOSE, kernel)
cv_imshow('closing', closing)
这不会去除毛刺。仔细想想就可以理解为先膨胀,相当于毛刺变粗,然后腐蚀。怎么会被腐蚀?
但是开闭操作的使用不仅如此,我认为开闭操作在很多项目中都非常有用,通过这个操作可以达到突出画面某些部分的效果。
4.4 梯度(gradient)运算
cv2.MORPH_GRADIENT 这是膨胀腐蚀,很容易提取边缘信息。
# 梯度(gradient) = 膨胀 - 腐蚀
pie = cv2.imread('img/pie.png')
kernel = np.ones((5, 5), np.uint8)
dilate = cv2.dilate(pie, kernel, iterations=5)
erosion = cv2.erode(pie, kernel, iterations=5)
res = np.hstack((dilate, erosion))
cv_imshow('res', res)
cv_imshow('subtract', dilate-erosion)
gradient = cv2.morphologyEx(pie, cv2.MORPH_GRADIENT, kernel, iterations=5)
cv_imshow('gradient', gradient)
这个梯度(gradient)运算和直接膨胀-腐蚀效果是一样的结果, 背后实现,我猜其实就是膨胀先执行iterations次,然后腐蚀执行iterations次,然后前面结果减去后面的结果。
4.5 礼帽和黑帽
- 礼帽操作cv2.MORPH_TOPHAT: 原始输入(input) – 开运算结果,即原始输入(input)-(先腐蚀,后膨胀)
- 黑帽操作cv2.MORPH_BLACKHAT: 闭运算结果-原始输入(input),即(先膨胀,后腐蚀)-原始输入(input)
代码显示如下:
# 礼帽
img = cv2.imread('img/dige.png')
tophat = cv2.morphologyEx(img, cv2.MORPH_TOPHAT, kernel)
cv_imshow('tophat', tophat)
# 黑帽
img = cv2.imread('img/dige.png')
blackhat = cv2.morphologyEx(img, cv2.MORPH_BLACKHAT, kernel)
cv_imshow('blackhat', blackhat)
一开始没看懂是干什么用的。参考这篇文章,有些了解。
礼帽操作:取出亮点
- 开放式操作可以消除黑暗背景上的明亮区域
- 如果从原始图像中减去开运算结果,则可以得到灰度图像中的区域
黑帽操作:取出亮度低的地方
- 闭运算可以删除亮区背景下的暗区,闭运算可以减去原始图像得到原始图像中较暗的灰色区域。
一般使用是将原始图像转换为灰度图像,然后进行二值化,然后通过开闭运算、顶帽和黑帽运算,就可以得到图像中想要的区域。所以后面的组合操作很重要,也很实用。比如车牌号识别、信用卡号识别等,都会用到这些技术,后面会整理出来。
5. 图像的算子操作
图像的算子操作其实可以帮助我们去找图像的轮廓信息,主要有Sobel算子,Scharr算子以及Laplacian算子,区别在于卷积(convolution)核参数不一样。
5.1 Sobel算子
Sobel算子, 这感觉依然是两个卷积(convolution)核进行操作, 原理如下:
这个东西其实找的是图像的轮廓信息,或者边缘信息,依赖(dependency)于上面的两个卷积(convolution)核, 一个是水平方向的,一个是垂直方向的, 实际计算的时候是这样,的卷积(convolution)核覆盖到一个图像区域, 中间点的取值,就是水平的这个卷积(convolution)核与当前图像卷积(convolution)结果或者垂直方向的卷积(convolution)核与当前图像卷积(convolution)结果。这个就看是从水平上算还是垂直方向上算了。 当然, 这个算子也是保证最终结果是0-255,如果超了,就会进行截断操作。
靠中心越近权重越大,所以这里用了2或者-2表示
- 只要中心点两边的颜色不一样,这个点这里就有梯度(gradient), 就不为0, 中心点两边的亮度相差越大, 使得这个边界就会越明显。
- 如果中心点两边的颜色一样, 这个点就没有梯度(gradient),上面运行就是0, 变成黑色
- 找边的时候尽量先横后竖或者先竖后横,不要找一块,因为一块可能会偏移,造成效果不清楚。 — 这是一个小经历
具体功能如下:
dst = cv2.Sobel(src, ddepth, dx, dy, ksize)
ddepth: 图像的深度
dx和dx分别表示水平和垂直方向, 是算x方向还是y方向
ksize是Sobel算子的大小, 一般是3*3
这里直接说常规使用方法, 对于一张图片, 先通过imread的灰度方式读入进来,然后先求水平上的梯度(gradient),再求垂直方向上的梯度(gradient), 最后加权融合就能找出图片的梯度(gradient)来。
lena = cv2.imread('img/lena.jpg', cv2.IMREAD_GRAYSCALE)
# 水平做sobel算子
lena_sobelx = cv2.Sobel(lena, cv2.CV_64F, 1, 0, ksize=3)
lena_sobelx = cv2.convertScaleAbs(lena_sobelx) # 这里是为了如果出现负数不让他截断成0,而是变成它的绝对值
# cv_imshow('lena_x', lena_sobelx)
# 垂直做sobel计算
lena_sobely = cv2.Sobel(lena, cv2.CV_64F, 0, 1, ksize=3)
lena_sobely = cv2.convertScaleAbs(lena_sobely)
# cv_imshow('lena_y', lena_sobely)
# 把这俩合并
lena_margin = cv2.addWeighted(lena_sobelx, 1, lena_sobely, 1, 0)
cv_imshow('lena_margin', lena_margin)
这里的一个小经验是,分别计算两个方向比同时计算要好。原因是如果同时计算的话,亮度上会有一些偏移。
# 如果是同时找
lena_test = cv2.Sobel(lena, cv2.CV_64F, 1, 1, ksize=5)
lena_test = cv2.convertScaleAbs(lena_test)
cv_imshow('lena', lena_test)
这个效果不好。比较结果如下:
左边是原图,中间是先找水平边缘,再找垂直边缘再合并的结果,右边是同时找两个方向边缘的结果。
这里有两个尝试:
- 改变ksize参数, 发现了一个问题,就是这个ksize越大, 最终得到的边界会越粗, 这个考虑了下,是因为,如果ksize越大,说明覆盖的区域会越大,这时候中心点两边的值区别就越可能相差的大,所以中心点像素不为0的概率就会变大,所以会越来越粗
- 尝试改变加和的时候, dx和dy的权重, 这个得到的结论就是这俩权重越大,最终的合并边界就会越发亮和明显,其实是显然的。
- 最后一个很重要的经验就是, 同时在dx和dy方向计算,不如先计算某一边再计算另一边最终效果来的好。这是因为会发生方向上的效果抵消。
5.2 Scharr算子
该算子的卷积(convolution)核如下: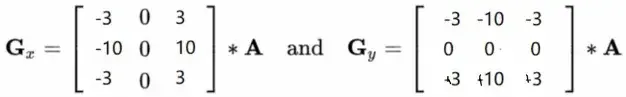
Scharr算子能够找出更加细致的边界,使得图像的纹理信息更加丰富。使用的方法和上面Sobel是一样的,无非就是函数换了下:
# 这里用scharr算子试一下
img = cv2.imread('img/lena.jpg', cv2.IMREAD_GRAYSCALE)
lena_scharr_x = cv2.Scharr(img, cv2.CV_64F, 1, 0)
lena_scharr_x = cv2.convertScaleAbs(lena_scharr_x)
lena_scharr_y = cv2.Scharr(img, cv2.CV_64F, 0, 1)
lena_scharr_y = cv2.convertScaleAbs(lena_scharr_y)
lena_scharr_xy = cv2.addWeighted(lena_scharr_x, 0.5, lena_scharr_y, 0.5, 0)
cv_imshow('lena_scharr_xy', lena_scharr_xy)
# 可以找出更细致的边界, 我猜的没错 对, 纹理细节这个词用的好
结果如下:
5.3 Laplacian算子
卷积(convolution)核如下: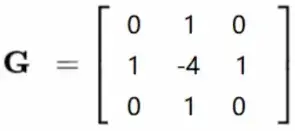
一般来说,这不是单独使用的。经常和其他算子结合使用,对噪声会比较敏感,但是噪声点可能不是边界,所以这个效果不适合单独使用。
这个具体用的时候,会发现是中心点和紧挨着的上下左右四个邻居进行比较, 这里就没有x和y的概念了
laplacian = cv2.Laplacian(img, cv2.CV_64F)
laplacian = cv2.convertScaleAbs(laplacian)
cv_imshow('laplacian', laplacian)
最后,比较各种算子找边的效果: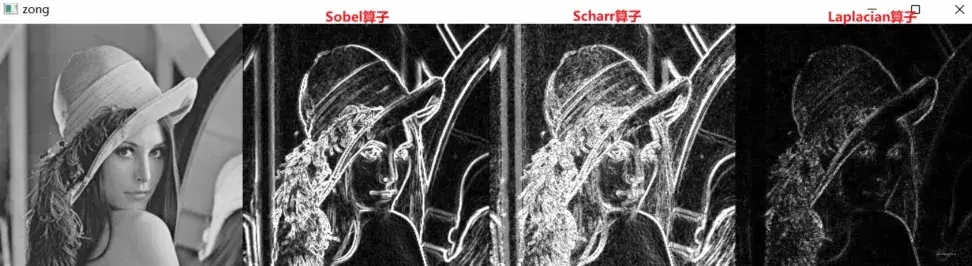
6. Canny边缘目标检测算法
Canny边缘目标检测算法,用于目标检测图像的边缘信息。主要包括下面的流(stream)程:
- 使用高斯(RBM Gaussian RBM)滤波器对图像进行平滑(Smoothing),滤除噪声—-filter denoising
- 计算图(computational graph)像中每个像素点的梯度(gradient)强度和方向—-梯度(gradient)的强度和方向
- 应用非极大值(maxima)抑制(Non-Maximum Suppression), 以消除边缘目标检测带来的杂散响应 —- 梯度(gradient)小的像素点抑制掉
- 应用双阈值(Threshold)(Double-Threshold)目标检测来确定真实和潜在(latent)的边缘 —- 双阈再目标检测
- 边缘目标检测最终通过抑制孤立的弱边缘来完成
6.1 高斯(RBM Gaussian RBM)滤波
这一步是对原始图像处理,去掉一些噪声,让其本身更加平滑(Smoothing), 在Canny算法中用的是高斯(RBM Gaussian RBM)滤波器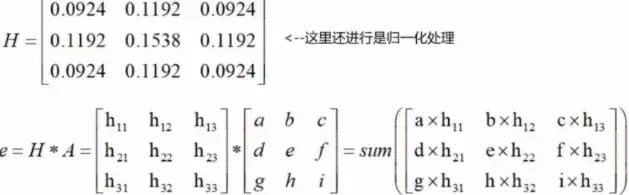
其他滤波器,如均值滤波器、中值滤波器等比较常用,这是滤波器的相关知识。
6.2 梯度(gradient)和方向
这里就是求各个中心点的梯度(gradient), Canny算法中用的是sobel算子
6.3 非极大值(maxima)抑制
这是为了去除一些梯度(gradient)值较小的边缘信息,以消除边缘信息带来的杂散效应。这里描述了两种方法:
6.3.1 Method1

这里描述下这种方法是怎么做的, 这个属实有些复杂, 这里是判断像素C这个点要不要被抑制点,即判断C这个点是不是极大值(maxima),可以这么做:
- 首先,根据上面的求梯度(gradient)的方法,计算C点的梯度(gradient), 有了梯度(gradient),就有了方向(和边界垂直), 这样就能画出C点处像素的梯度(gradient)来
- C点的梯度(gradient)就那条蓝色的线, 延伸一下,会和上下的边界有交点, 上面交到了dtmp1, 下面交到了dtmp2
- 下面算出dtmp1和dtmp2点的梯度(gradient)来,用M表示梯度(gradient)的话,然后比较 M(dtmp1), M(dtmp2), M(C) 的大小, 如果 M(C) 比那两个都大,那么说明C这个点的像素值是极大值(maxima)像素点, 保留下这个点,否则, 把它干掉。 那么接下来的问题,就是 M(dtmp1), M(dtmp2) 如何计算呢?
- 这俩点的梯度(gradient)其实是伪梯度(gradient),直接算没法算,只能通过与它相邻的两个点去估计, 比如算 M(dtmp1)
- 首先, 我们能得到dtmp1两端点的像素值 M(g1), M(g2)
- 然后, 我们通过这两点的像素值线性插出dtmp1的梯度(gradient)值来, 怎么插呢? 线性插值公式如上面, 这里的w表示的距离权重,很好理解应该
- 对于dtmp2,同样按照上面的方式计算即可
6.3.2 Method2
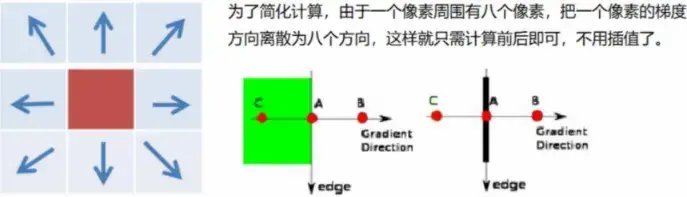
这个方法比上面那个简单了, 这里会借助它周围的8个点:
- 首先, 把一个像素的梯度(gradient)方向离散成周围8个方向, 然后看看它离这个方向进,就用那个方向代替
- 在这个方向,看哪两个点靠近,有这两个点的梯度(gradient),比较中心点的梯度(gradient)
- 如果中心点的梯度(gradient)大于两点的梯度(gradient),则保持,否则,抑制
6.4 双阈值(Threshold)目标检测
这是另一个自定义过滤器
其实这里就是指定一个最大值和一个最小值,然后看中心点的梯度(gradient)值,需要按照右边的规则进行预留。即使有边界,这里的意思是看它是否在边界旁边。如果它旁边的点是边界,那么这个点也将被保留,否则将被移除。
上面就是Canny算法各个流(stream)程的细节部分,在opencv中用起来其实很简单,只需要一个cv2.Canny函数即可。
lena = cv2.imread('img/lena.jpg', cv2.IMREAD_GRAYSCALE)
v1 = cv2.Canny(lena, 80, 150)
v2 = cv2.Canny(lena, 50, 100)
res_lena = np.hstack((lena, v1, v2))
cv_imshow('res', res_lena)
看看结果:

这里的minval指定的如果比较小,会找到更加细致的边界, 纹理信息更多, 但可能会拿到很多误选择的边界
maxval指定的如果比较大, 会找到更加严格的边界,但可能会漏掉一些边界
- minval和maxval都越小,那么目标检测到的信息就越丰富
- maxval和maxval都越大, 目标检测到的信息就越稀疏, 很多边界可能目标检测不出来
7. 图像金字塔
图像金字塔,将图像组合成类似金字塔的形状。图像金字塔的作用,比如我们想从一张图像中提取特征,我们可以把图像做成金字塔,对金字塔中的每一张图像进行特征提取。每张图像提取的特征可能不同,这样可以增加图像特征的丰富度。
图像金字塔是图像的一种多尺度表示,主要用于图像分割。它是一种有效但概念上简单的结构,可以解释多种分辨率的图像。最底部是要处理的图像的高分辨率表示,层越高,分辨率越低。
两种常见的金字塔类型:
- 高斯(RBM Gaussian RBM)金字塔: 用来向下/降采样(Downsampling)(Sampling), 主要的图像金字塔
- 拉普拉斯金字塔:用于从金字塔底部的图像重建上层未采样(Sampling)的图像,可以最大程度地还原图像,可与高斯(RBM Gaussian RBM)金字塔配合使用
两者的简单区别:高斯(RBM Gaussian RBM)金字塔用于对图像进行下采样(Sampling)(Downsampling)。注意下采样(Sampling)(Downsampling)其实是从金字塔底部向上,分辨率降低,这和我们理解的金字塔的概念相反(注);而拉普拉斯金字塔用于通过从金字塔底部图像进行上采样(Upsampling)(Sampling)来重建图像。
7.1 高斯(RBM Gaussian RBM)金字塔
7.1.1 向下采样(Sampling)(Downsampling)方法(缩小)
将level0级别的图像转换为 level1,level2,level3,level4,图像分辨率不断降低的过程称为向下取样。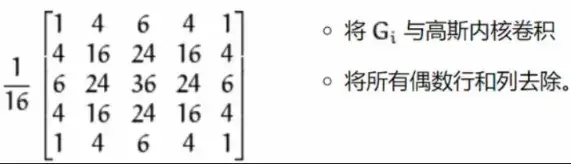
从金字塔的底部到顶部,是一个下采样(Sampling)(Downsampling),采样(Sampling)越小,主要过程有两个步骤:
- 普通的卷积(convolution)操作使用上面的卷积(convolution)核。我发现这里的卷积(convolution)和卷积(convolution)神经网络(CNN网络)中的卷积(convolution)操作不太一样。使用上面的卷积(convolution)核再次滚动。滚动的过程就是将覆盖区域的元素相乘,最后相加得到中心点的元素,这样最终的结果就和原图一样大小。
- 但是金字塔越来越小,所以这里的第二步就是去掉所有偶数行和列,这样得到的图像只有原图的四分之一。这就是下采样(Sampling)(Downsampling)的过程。
7.1.2 向上采样(Upsampling)(Sampling)方法(放大)
将level4级别的图像转换为 level3,level2,level1,leve0,图像分辨率不断增大的过程称为向上取样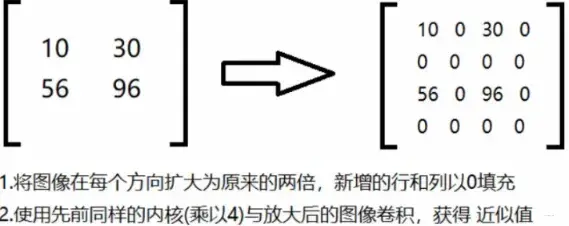
金字塔上下,是上采样(Upsampling)(Sampling),采样(Sampling)越多,越大
它将图像在每个方向上扩大为原图像的2倍,新增的行和列均使用0来填充,并使用于“向下取样”相同的卷积(convolution)核乘以4,再与放大后的图像进行卷积(convolution)运算,以获得“新增像素”的新值
注意:先对图像进行上采样(Upsampling)(Sampling),然后再下采样(Sampling)(Downsampling),或者先下采样(Sampling)(Downsampling)再上采样(Upsampling)(Sampling),都会丢失信息。虽然和原图大小一样,但是会比原图模糊,所以上采样(Upsampling)(Sampling)和下采样(Sampling)(Downsampling)都是非线性的。处理,不可逆,会丢失信息!
下面是具体实现:
img = cv2.imread('img/AM.png') # (442, 340, 3)
# 先向上采样(Upsampling)(Sampling)看看
up_sample = cv2.pyrUp(img)
cv_imshow('up', up_sample)
print(up_sample.shape) # (884, 680, 3)
# 向下采样(Sampling)(Downsampling)
up_down = cv2.pyrDown(img)
cv_imshow('down', up_down)
print(up_down.shape) # (221, 170, 3)
# 先经历上采样(Upsampling)(Sampling)再还原
cv_imshow('up_down', np.hstack((img, cv2.pyrDown(up_sample))))
可以看最后的结果,会有一些失真,因为下采样(Sampling)(Downsampling)和上采样(Upsampling)(Sampling)都会造成一定的信息丢失
7.2 拉普拉斯金字塔
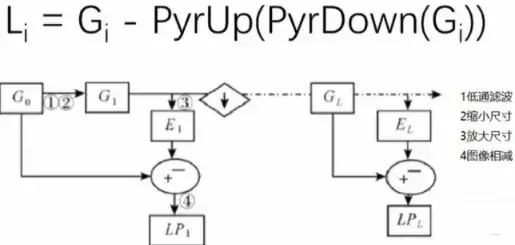
这个东西的公式计算就是上面的,代表
层的图像,下面解释一下过程:
- 对原图逐层下采样(Sampling)(Downsampling)做图像金字塔,这样每一层都有下采样(Sampling)(Downsampling)的图像,这个是
- 每一层图片的下一步操作就是上面的公式,比如第一层(first layer),用
得到
层的当前图片
也就是说,拉普拉斯金字塔是通过从首先缩小然后放大的源图像中减去一系列图像来构建的。剩下的就是残余!为图像恢复做准备,实现非常简单。
down = cv2.pyrDown(img)
down_up = cv2.pyrUp(down)
l_1 = img - down_up
cv_imshow('l1', l_1)
接下来将高斯(RBM Gaussian RBM)上采样(Upsampling)(Sampling)、下采样(Sampling)(Downsampling)、拉普拉斯金字塔的过程写成一个函数的形式,可以一键干掉整个金字塔。
# 高斯(RBM Gaussian RBM)降采样(Downsampling)(Sampling)金字塔
def Gaussian_Down(img, sample_times):
Gaussian_Down_pyramid = []
for i in range(sample_times):
if i == 0:
down = cv2.pyrDown(img)
else:
down = cv2.pyrDown(down)
Gaussian_Down_pyramid.append(down)
return Gaussian_Down_pyramid
def Gaussian_up(img, sample_times):
Gaussian_up_pyramid = []
for i in range(sample_times):
if i == 0:
up = cv2.pyrUp(img)
else:
up = cv2.pyrUp(up)
Gaussian_up_pyramid.append(up)
return up
def Laplace(img, sample_times):
laplace_pyramid = []
for i in range(sample_times):
if i == 0:
down = cv2.pyrDown(img)
laplace_pyramid.append(img-cv2.pyrUp(cv2.pyrDown(img)))
else:
up_down = cv2.pyrUp(cv2.pyrDown(down))
# 注意这里由于取整的关系,导致这俩还不一样大
if down.shape != up_down.shape:
laplace_pyramid.append(down - up_down[:down.shape[0], :down.shape[1], :])
else:
laplace_pyramid.append(down - up_down)
down = cv2.pyrDown(down)
return laplace_pyramid
8. 图像轮廓目标检测
根据我目前的理解,轮廓目标检测和边缘目标检测是不同的概念。轮廓目标检测只目标检测物体最外层的轮廓,类似于用框围住物体,相当于锁定了物体的位置,而边缘目标检测则是目标检测物体内部的各种边界信息。所以不一样。
轮廓目标检测的作用是帮助我们做一些额外的数值特征,比如图像轮廓的面积和周长,从而可以体现出尺寸的大小。
8.1 轮廓绘制
核心是以下功能:
cv2.findContours(img, mode, method) → contours, hierarchy(返回的轮廓列表及层级信息)
- mode: 轮廓检索模式
- RETR_EXTERNAL: 只检索最外面的轮廓
- RETR_LIST: 检索所有的轮廓,并将其保存到一条链表当中
- RETR_CCOMP: 检索所有的轮廓, 并将他们组织成两层, 顶层是各部分的外部边界, 第二层是空洞的边界
- RETR_TREE: 检索所有的轮廓, 并重构嵌套轮廓的整个层次(最常用), 多层字典?
- method: 轮廓逼近方法:
- CHAI(人工智能(Artificial Intelligence))N_APPROX_NONE: 以Freeman链码的方式输出轮廓, 所有其他方法输出多边形(顶点的序列)
- CHAI(人工智能(Artificial Intelligence))N_APPROX_SIMPLE: 压缩水平的,垂直的和斜的部分, 也就是,函数只保留他们的终点部分
以下是如何使用它:
img = cv2.imread('img/car.png')
# 转成灰度, 这里为啥不直接读取的时候转? 因为有些人后序会用到彩色图,仅此而已
gray = cv2.cvtColor(img, cv2.COLOR_RGB2GRAY)
# 下一步, 对上面的灰度图像进行二值处理
ret, thresh = cv2.threshold(gray, 127, 255, cv2.THRESH_BINARY) # 像素小于127的弄成0, 大于127的弄成255,这样变成二值图像
# 下面绘制轮廓
# 最新版opencv只返回两个值了 3.2之后, 不会返回原来的二值图像了,直接返回轮廓信息和层级信息
contours, hierarchy = cv2.findContours(thresh, cv2.RETR_TREE, cv2.CHAI(人工智能(Artificial Intelligence))N_APPROX_NONE)
这是原始图像中可视化的轮廓:
# 下面把轮廓进行可视化
draw_img = img.copy() # 这里要copy一下, 否则会改变原始图像, 下面那哥们貌似是原子操作
# drawContours(image, contours, contourIdx, color[, thickness[, lineType[, hierarchy[, maxLevel[, offset]]]]]) -> image
# 这里的contourIdx要绘制的轮廓线,负数表示所有, 正是只画对应位置的那个点
# color是轮廓线的颜色, (0,0,255)表示红色,因为opencv里面通道排列是bgr吧应该--> 对的
# 最后面那个2是线条的宽度,值越大, 线条越宽
res = cv2.drawContours(draw_img, contours, -1, (0, 255, 0), 2)
cv_imshow('res', res)
看看效果:
8.2 轮廓特征
寻找轮廓的目的就是将这些信息转化为数值特征,方便后续计算。在这里,您可以找到轮廓面积和轮廓周长。
但它必须是特定的轮廓,而不是上面的轮廓列表
def contours_feature(contour):
features = []
features.append(cv2.contourArea(contour)) # 轮廓面积
features.append(cv2.arcLength(contours, True)) # 轮廓周长,后面那个是closed,表示这个曲线是否闭合
return features
controus_feature(countours[0])
这里可以得到一个函数,找到特定轮廓的一系列特征,然后返回,这些特征可以反映特定物体的大小。
8.3 轮廓近似

如果左边的轮廓太细,会出现一些轮廓的毛刺。这时候,我们可能会去除这种毛刺的轮廓,我们需要右边的近似结果。右边两个是两个不同的近似结果,多少避免了过拟合(Overfitting)的味道。
下面简单看一下轮廓逼近的原理: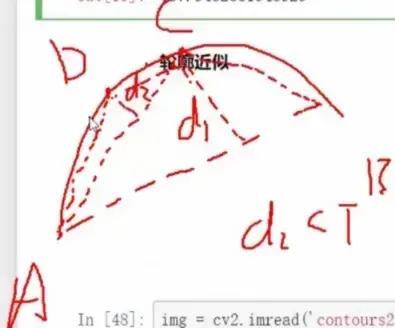 比如,我AB这是一条曲线,我想找一条或者几条直线近似它, 可以这么做:
比如,我AB这是一条曲线,我想找一条或者几条直线近似它, 可以这么做:
- 首先, A, B两点先连起来,成了一个拱形
- 然后,从AB的曲线上找点C, 向AB直线上做垂线, 与AB直线的交点假设(Hypothesis)与C点的距离d1<设定的阈值(Threshold), 那么AB这条直线就是成立的,AB曲线直接用这条直线来近似
- 如果上面的d1>设定的阈值(Threshold), 那么说明AB曲线用A到B的一条直线无法近似,看看两条行不
- 把AC, BC连起来
- AC之间的曲线看看能不能用AC之间的直线代替,方法还是和上面一样, AC上找D点,然后向AC做垂线,看距离d2是否小于设定阈值(Threshold),如果小于则可以, 如果不小于,则不行,继续二分
- BC之间曲线也同理,这样二分下去
使用简单:
# 读取图片 -> 转成灰度图 -> 二值化 -> 找轮廓
img = cv2.imread('img/contours2.png')
# 用上面的函数画一些轮廓
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
ret, thresh = cv2.threshold(gray, 127, 255, cv2.THRESH_BINARY)
contours, hierarchy = cv2.findContours(thresh, cv2.RETR_TREE, cv2.CHAI(人工智能(Artificial Intelligence))N_APPROX_NONE)
cnt = contours[0]
draw_img = img.copy()
res = cv2.drawContours(draw_img, [cnt], -1, (0, 0, 255), 2)
cv_imshow('res', res)
# 下面进行轮廓近似
epsilon = 0.1 * cv2.arcLength(cnt, True) # 这里是指定的阈值(Threshold),一般按照周长的百分比设置
# 这个阈值(Threshold)越大,那么画出来的轮廓就越粗糙,因为很容易直接一条直线代替曲线, 如果阈值(Threshold)越小,那么近似出来的轮廓细腻,因为d很容易大于阈值(Threshold),用多条直线近似
approx = cv2.approxPolyDP(cnt, epsilon, True)
draw_img2 = img.copy()
res2 = cv2.drawContours(draw_img2, [approx], -1, (0, 0, 255), 2)
cv_imshow('res2', res2)
看看以下两个对比: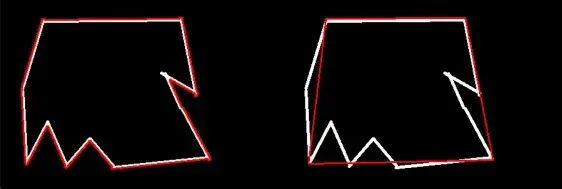
8.3 轮廓小作用
基于图像的轮廓,还可以计算出一些外接矩形、外接圆等,然后根据这些外接矩形和外接圆构造一些数值特征,比如添加一些额外的组合特征,比如轮廓本身到边界矩形的区域。 、周长比等。
# 基于这个轮廓画外接矩形
x, y, w, h = cv2.boundingRect(cnt) # 这里返回的是(x, y)是左上角的顶点坐标, w是宽, h是长
draw_img3 = res2.copy()
img_rec = cv2.rectangle(draw_img3, (x, y), (x+w, y+h), (0, 255, 0), 2)
cv_imshow('rec', img_rec)
使用外部矩形,您可以执行一些附加功能:
# 有了这样的一个矩形,我们就可以额外做一些特征
area = cv2.contourArea(cnt)
x, y, w, h = cv2.boundingRect(cnt)
rect_area = w * h
extent = float(area) / rect_area
print('轮廓面积与边界矩形比: ', extent)
你也可以做一个外接圆:
# 还可以做外接圆
(x, y), radius = cv2.minEnclosingCircle(cnt) # 圆心位置和半径
center = (int(x), int(y))
radius = int(radius)
draw_img4 = draw_img3.copy()
res_circle = cv2.circle(draw_img4, center, radius, (255, 0, 0), 2)
cv_imshow('circle', res_circle)
结果如下:
通过轮廓目标检测算法,可以找到上图中每张图片的具体轮廓,从而对每一张具体的图片进行具体的操作,如果加上后面学习的模板匹配,计算机就可以很容易的知道这些具体的物体。它是什么。比如车牌号码目标检测、信用卡号码识别等,其实就是用这个原理,先锁定卡上的号码区域,然后进行模板匹配。
所以这些东西非常重要。
9. 图像模板匹配
模板匹配和卷积(convolution)原理很像, 模板在原图像上从原点开始滑动,计算模板与(图像被模板覆盖的地方)的差别程度,这个差别程度的计算方法在opencv里面有6种, 然后将每次计算的结果放入一个矩阵(matrix)里,作为结果输出。
如果原始图像大小为,模板大小为
,则输出结果的矩阵(matrix)为
,与卷积(convolution)神经网络(CNN网络)中的卷积(convolution)运算非常相似。主要步骤如下:
- 读入原始图像,通常是灰度图像
- 读入模板图,也是一张灰度图
- 模板匹配,这里直接使用模板匹配函数 cv2.matchTemplate(img, template, mode) , mode表示计算方式
- TM_SQDIFF: 计算平方不同, 计算出来的值越小越相关
- TM_CCORR: 计算相关性, 计算出来的值越大,越相关
- TM_CCOEFF: 计算相关系数(Correlation coefficient),计算出来的值越大,越相关
- TM_SQDIFF_NORMED: 计算归一化(Normalization)平方不同,计算出来的值越接近0, 越相关
- TM_CCORR_NORMED: 计算归一化(Normalization)相关性,计算出来的值越接近1, 越相关
- TM_CCOEFF_NORMED: 计算归一化(Normalization)相关系数(Correlation coefficient), 计算出来的值越接近1, 越相关
具体的计算公式可以在文档中找到。尝试使用下面的归一化(Normalization)结果 - 获取到匹配好的原始图像的起始位置 cv2.minMaxLoc , 这里可以获取到最大值位置,也可以获取到最小值位置,但是由于上面计算方式的不同, 得先弄明白是最大的时候两个越相关,还是越小的时候, 两个越相关
这是一个例子:
# 1. 读入原始图像,灰度图模式读入 0表示灰度图,还有就是cv2.IMREAD_SCALE
img = cv2.imread('img/cat.jpg', 0) # <==> cv2.imread('img/cat.jpg', cv2.IMREAD_GRAYSCALE)
# 2. 读入模板
template = cv2.imread('img/template.jpg', 0)
# 3. 模板匹配
res = cv2.matchTemplate(img, template, cv2.TM_SQDIFF) # 值越小越相似
res.shape # (548-122+1)(666-181+1)
# 4. 获取匹配好图像的起始位置
min_val, max_val, min_loc, max_loc = cv2.minMaxLoc(res)
# 下面尝试把矩形框画出来
top_left = min_loc
bottom_right = (top_left[0]+template.shape[0], top_left[1]+template.shape[1])
# 画矩形
img2 = img.copy()
rect = cv2.rectangle(img2, top_left, bottom_right, 255, 2)
效果如下:
假设(Hypothesis)图像中有多个对象要匹配?有没有办法匹配所有的模板图像,那么你需要自己的最大或最小位置,这实际上很简单:
img_rgb = cv2.imread('img/mario.jpg')
# 转成灰度图
img_gray = cv2.cvtColor(img_rgb, cv2.COLOR_BGR2GRAY)
template = cv2.imread('img/mario_coin.jpg', 0)
h, w = template.shape[:2]
res = cv2.matchTemplate(img_gray, template, cv2.TM_CCOEFF_NORMED)
threshold = 0.8 # 这里设置一个门限
# 取匹配程度大于百分之八十的坐标
loc = np.where(res >= threshold)
# 这个loc是横坐标一个数组,纵坐标一个数组的形式,所以下面得用可选参数的方式进行组合
for pt in zip(*loc[::-1]):
bottom_right = (pt[0]+w, pt[1]+h)
cv2.rectangle(img_rgb, pt, bottom_right, (0, 255, 0), 2)
cv_imshow('img_rgb', img_rgb)
效果如下:
10. 图像直方图与均衡化
10.1 直方图
所谓直方图就是通过直方图统计一张图片中像素值的个数。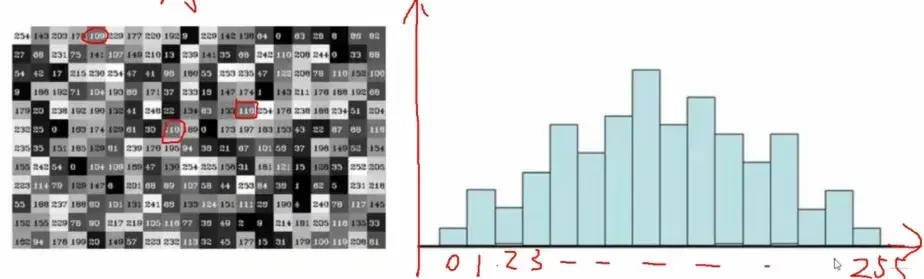
功能介绍如下:
cv2.calcHist(images, channels, mask, histSize, ranges):
- images: 原图像格式为uint8或者float32, 当传入时用[]括起来, 一般时灰度图像居多。
- channels: 同样时中括号括起来, 指定彩色图片的哪个通道,如果时灰度图,它的值就是[0], 如果时彩色图, [0], [1], [2]表示BGR三个通道。
- mask: 掩膜图像, 统计整个图的时候,就时None,如果想统计图像的某一部分,那么可以制作一个掩膜矩阵(matrix)
- histSize: bin的数目, 可以统计0-255,每个像素点,也可以按照范围, 比如0-10, 10-20, 等等的个数,这里指定
- ranges: 像素值范围,一般默认[0,256)
使用起来也非常简单:
img_bgr = cv2.imread('img/cat.jpg')
color = ('b', 'g', 'r')
for i, col in enumerate(color):
histr = cv2.calcHist([img_bgr], [i], None, [256], [0, 256])
plt.plot(histr, color=col)
plt.xlim([0, 256])
其实这个东西,用plt.plot也能画出直方图来,毕竟图片数据是numpy数组, 通过可视化的方式,就能大致上知道图片的像素分布(Distribution)取值了。
mask掩码(mask)操作的使用, mask掩码(mask)矩阵(matrix)传入之后,只会统计我们需要部分的直方图:
# 先创建mask
mask = np.zeros(img.shape[:2], np.uint8)
mask[100:300, 100:400] = 255
cv_imshow('mask', mask) # 这样就创造除了一个掩码(mask)矩阵(matrix), 只有0和255组成, 白色的地方是要显示的,黑色的地方是被遮挡
masked_img = cv2.bitwise_and(img, img, mask=mask) # 与操作 等价img & mask
# 下面对比一下
hist_full = cv2.calcHist([img], [0], None, [256], [0, 256])
hist_mask = cv2.calcHist([img], [0], mask, [256], [0, 256])
效果如下: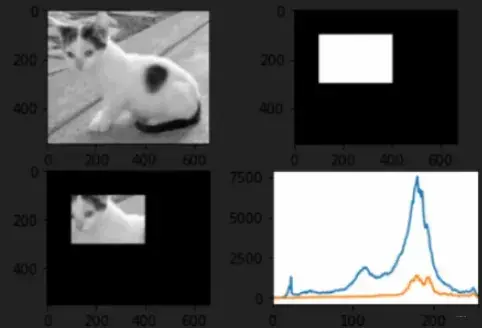
10.2 均衡化
直方图的作用是对一些图像进行均衡处理,使图像的对比度增加,图像更清晰。请看下面这张图片: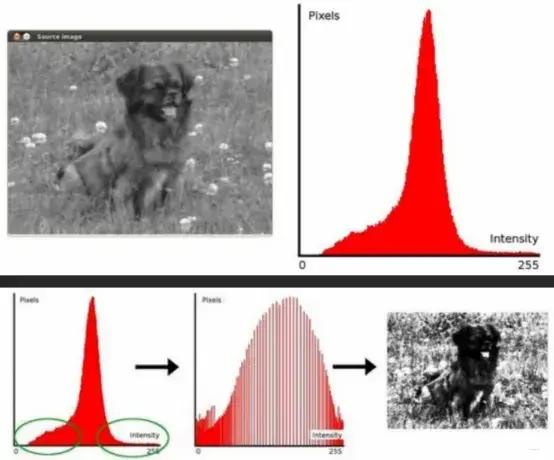
先简单介绍一下原理:
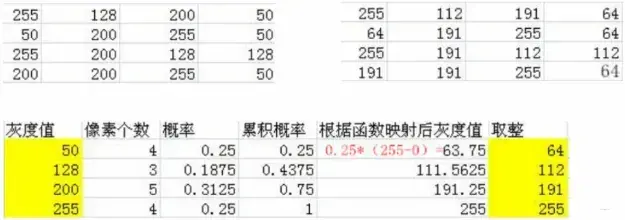
上图左图假设(Hypothesis)为原图,右图为均衡后的结果。所谓均衡化,无非是一种算法,将原始图像中的像素值映射到其他值而不是其他值。让它更统一,那么如何映射呢?
- 首先统计原始图像中每个像素点出现的次数,然后进行归一化(Normalization)计算概率
- 从小到大排序,然后即使累积概率很简单,从上到下,概率的累积值
- 用到的映射函数: 累计概率值*像素的取值范围(255-0)
- 将上面计算的数字四舍五入
具体用途:
img = cv2.imread('img/clahe.jpg', 0)
plt.hist(img.ravel(), 256)
# 均衡化
equ = cv2.equalizeHist(img)
plt.hist(equ.ravel(), 256)
plt.show()
res = np.hstack((img, equ))
cv_imshow('res', res) # 会发现均衡话之后,变得更加清晰了
效果如下:
均衡话可能存在的问题,虽然有时候会增强图片的对比度,但是可能有些细节丢失掉,因为均衡化类似于全局求了个平均,有细节的地方会受到其他位置的干扰。 所以,改进就是分块进行均衡话, 比如把一张图片分成多个小块,然后在每个小块里面执行均衡化的操作。当然,这样可能带来的问题就是每个小块的边界可能很明显了, opencv提供了一些插值处理来解决这个问题。
# cv2提供了分块均衡化的函数
clahe = cv2.createCLAHE(clipLimit=2.0, tileGridSize=(8,8)) # 自适应均衡化
res_clahe = clahe.apply(img)
res = np.hstack((img, equ, res_clahe))
cv_imshow('res', res)
最终效果如下:

11. 小总
这就是目前学习到的通过OpenCV库进行图像预处理操作的所有知识了,内容有些多,不适合顺序阅读,而是想着把这些东西整理到一块,后面用到的时候会很方便。 当然,目前对每一块的了解还处在皮毛状态,如果后面学习到更深入的知识,也会及时的在相应版块进行补充。 下面一张导图把知识拎起来: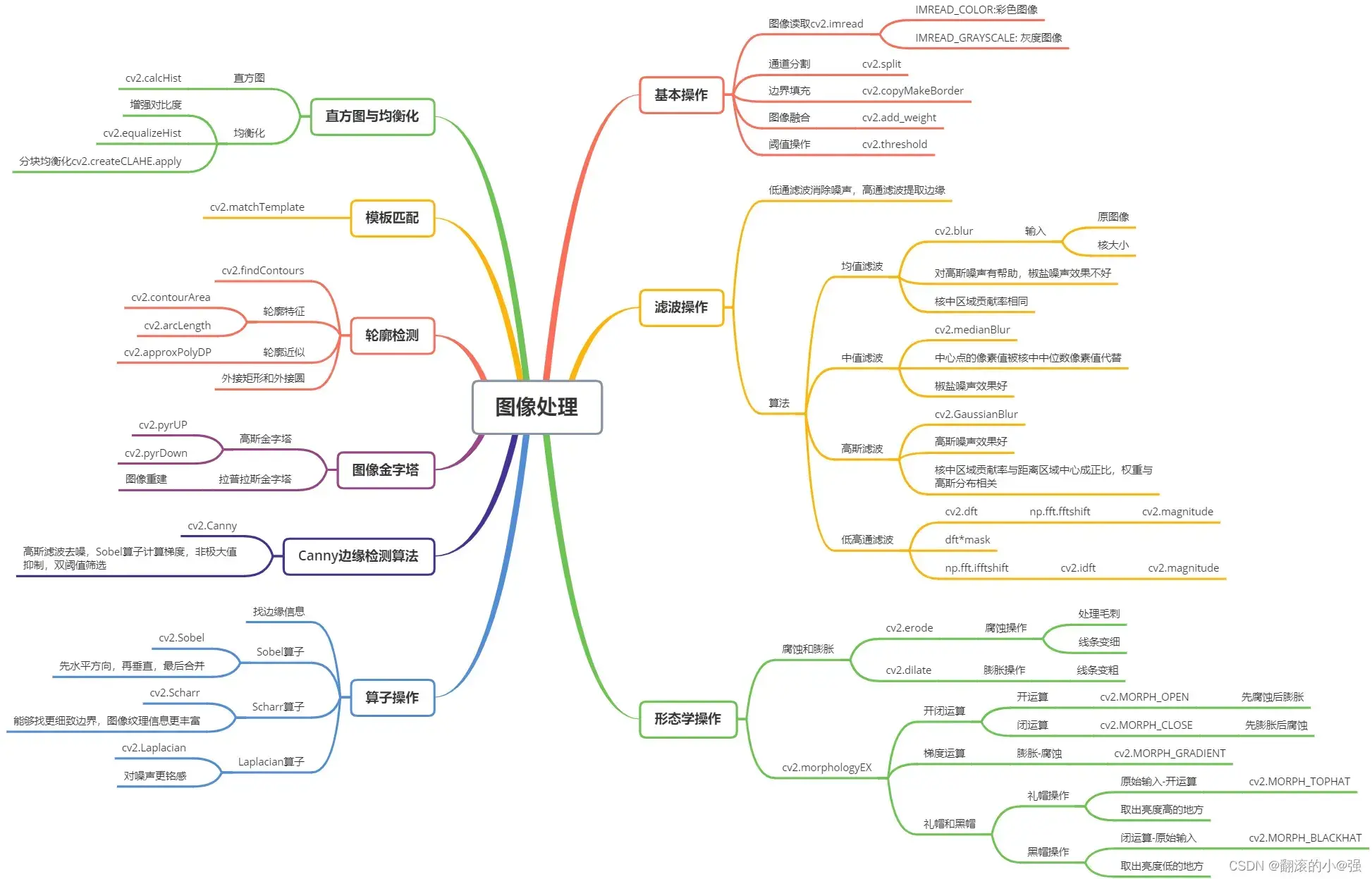
基础知识应该就到这里了,后面就是通过几个项目把上面所有内容带起来, Rush 😉
参考:
- opencv入门教程
文章出处登录后可见!