介绍
本着“凡我不能创造的,我就不能理解”的思想,本系列文章会基于纯Python以及NumPy从零创建自己的深度学习(Deep learning)框架,该框架类似PyTorch能实现自动求导。
要深入理解深度学习(Deep learning),从零开始的体验非常重要。从自我理解的角度出发,尽量不要使用外部完整的框架来实现我们想要的模型。本系列文章的目的是让大家通过这样一个过程掌握深度学习(Deep learning)的底层实现,而不是仅仅做一个调音师。
本文介绍解决过拟合(Overfitting)与欠拟合(Underfitting)的方法——正则化(Regularization),主要介绍L1和L2正则化(Regularization)。
偏差(Bias 偏置 )和方差
首先,让我们了解偏差(Bias 偏置 )和方差。
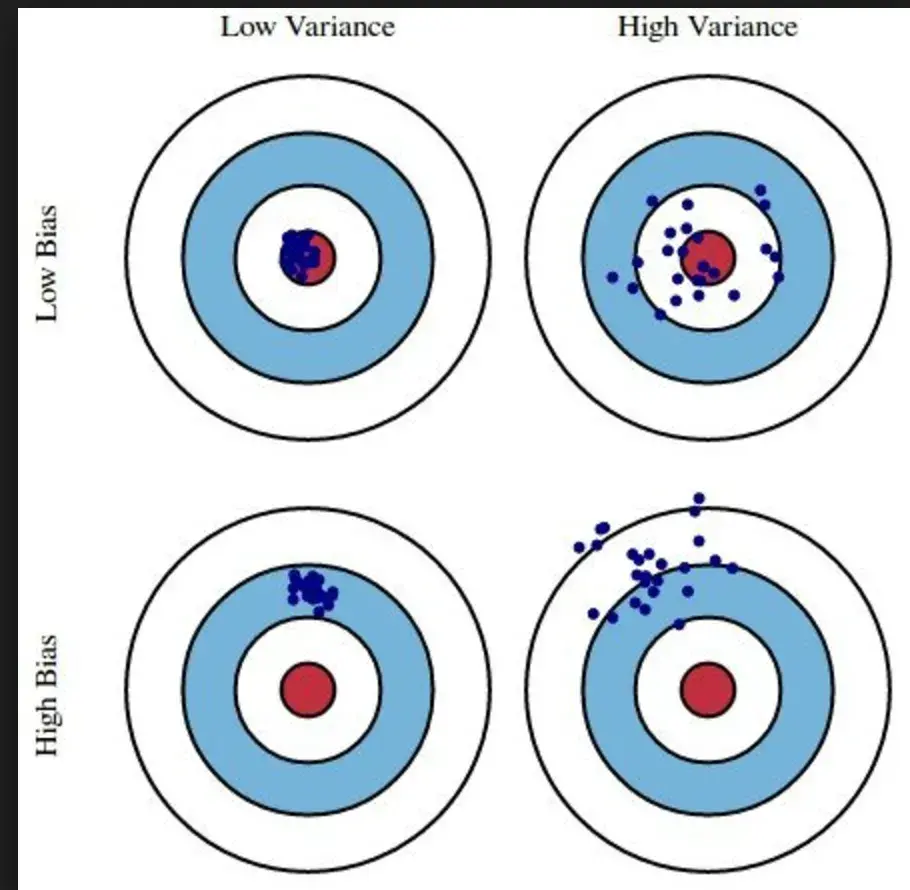
偏差(Bias 偏置 )意味着算法不能很好地拟合训练数据,而高偏差(Bias 偏置 )意味着预测将不准确。以打靶为例,就是说很多枪都打不中靶心,妥妥的身击高手。
以Andrew Ng老师举的例子来说,如果训练误差(Training error)为15%,验证误差为16%,此时属于高偏差(Bias 偏置 ),但这种情况下验证误差比较正常,只比训练高了一点。
方差是指算法对训练数据中微小波动的敏感性,即导致算法拟合训练数据中的噪声而不是目标输出。通常表现为过拟合(Overfitting)。以打靶为例,子弹并不集中在多发子弹上,可能是手在发抖,也可能是压不住枪。
如果训练误差(Training error)为1%,验证误差为11%,此时属于高方差。模型过拟合(Overfitting)了训练数据。
最糟的情况是高偏差(Bias 偏置 )且高方差,比如训练误差(Training error)为15%,验证误差为30%。
当然,我们想要的是一个低偏差(Bias 偏置 )、低方差的模型,即所有子弹都落在靶心上,不仅在目标上而且非常集中。
但是,在很多情况下,无法得到一个低偏差(Bias 偏置 )和低方差的模型,我们需要做出一些妥协。
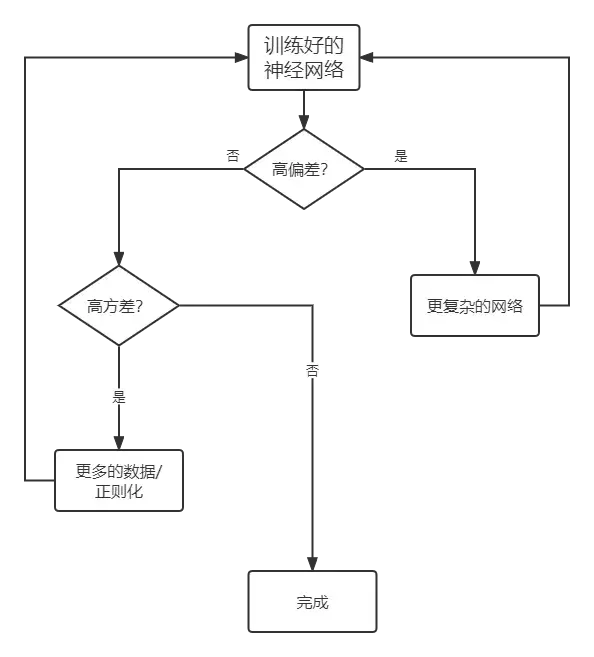
如果您有高偏差(Bias 偏置 )问题:
- 更多可用的训练数据
- 尝试更少的功能
- 增加正则化(Regularization)项的参数,使其不会过拟合(Overfitting)训练数据
如果您有高偏差(Bias 偏置 )问题:
- 尝试更多功能
- 尝试多项式特征使模型更复杂
- 减少正则化(Regularization)参数,使其能够更好地拟合数据
正则化(Regularization)以偏差(Bias 偏置 )的增加换取方差的减少,有效的正则化(Regularization)是一种有利的权衡,即显着减少方差而不会过度增加偏差(Bias 偏置 )。
这里多次提到正则化(Regularization),那么什么是正则化(Regularization)呢?
正则化(Regularization)
为了防止模型从训练数据中学习到错误或不相关的信息,最好的解决方案是获取更多的训练数据。如果没有更多数据可用,下一个最佳解决方案是调整模型允许存储的信息量,或者对模型允许存储的信息施加限制。
这种降低过拟合(Overfitting)的方法叫做正则化(Regularization)(regularization),我们介绍几种最常见的正则化(Regularization)方法,然后进行实际应用。
减小模型尺寸
单击此处获取此代码。
防止过拟合(Overfitting)的最简单方法就是减少模型大小,即减少模型中科学系的参数个数,这是由神经网络模型的层数和单元个数决定的。模型可学习参数的个数通常被称为模型的容量(capacity)(capacity),参数更多的模型拥有更大的记忆容量(capacity),因此能够在训练样本和目标之间轻松地学会完美的字典式映射,但这种映射没有任何泛化(Generalization)能力。
相反,如果网络的内存资源有限,这种映射就不容易学习。因此,为了最小化损失,模型必须学习一个对目标具有高度预测性的压缩表示,这也是我们感兴趣的数据表示。注意我们使用的模型应该有足够的参数来防止欠拟合(Underfitting)。因此,需要在产能过剩和产能不足之间寻求折衷。
但是,没有确定最佳层数或每层最佳尺寸的公式。为了找到数据的最佳模型大小,我们必须评估一系列不同的网络架构(在验证集(validation set)上评估)。
一般的工作流(stream)程是从选择相对较少的层和参数开始,然后逐渐增加层的大小或数量,直到这种增加对验证损失的影响变小。
我们以手写前馈网络(feedforward network)实现电影评论分类中的任务为例,创建一个可以动态设置隐藏层(Hidden layer)数的FFN:
class DynamicFFN(nn.Module):
def __init__(self, num_layers, input_size, hidden_size, output_size):
'''
:param num_layers: 隐藏层(Hidden layer)层数
:param input_size: 输入(input)维度
:param hidden_size: 隐藏层(Hidden layer)大小
:param output_size: 分类个数
'''
layers = []
layers.append(nn.Linear(input_size, hidden_size)) # 隐藏层(Hidden layer),将输入(input)转换为隐藏向量
layers.append(nn.ReLU()) # 激活函数(Activation Function)
for i in range(num_layers - 1):
layers.append(nn.Linear(hidden_size, hidden_size // 2))
hidden_size = hidden_size // 2 # 后面的神经元数递减
layers.append(nn.ReLU())
layers.append(nn.Linear(hidden_size, output_size)) # 输出层(Output layer),将隐藏向量转换为输出
self.net = nn.Sequential(*layers)
def forward(self, x: Tensor) -> Tensor:
return self.net(x)
然后我们比较单隐藏层(Hidden layer)、4个神经元的简单网络与4个隐藏层(Hidden layer)、128个神经元的复杂网络:
X_train, X_test, y_train, y_test, X_val, y_val = load_dataset()
batch_size = 512
train_ds = TensorDataset(X_train, y_train)
train_dl = DataLoader(train_ds, batch_size=batch_size)
val_ds = TensorDataset(X_val, y_val)
val_dl = DataLoader(val_ds, batch_size=batch_size)
input_size = 10000
output_size = 1
simple_model = DynamicFFN(1, input_size, 4, output_size)
complex_model = DynamicFFN(4, input_size, 128, output_size)
compare_model(train_dl, val_dl, simple_model, complex_model)
最终结果如下:
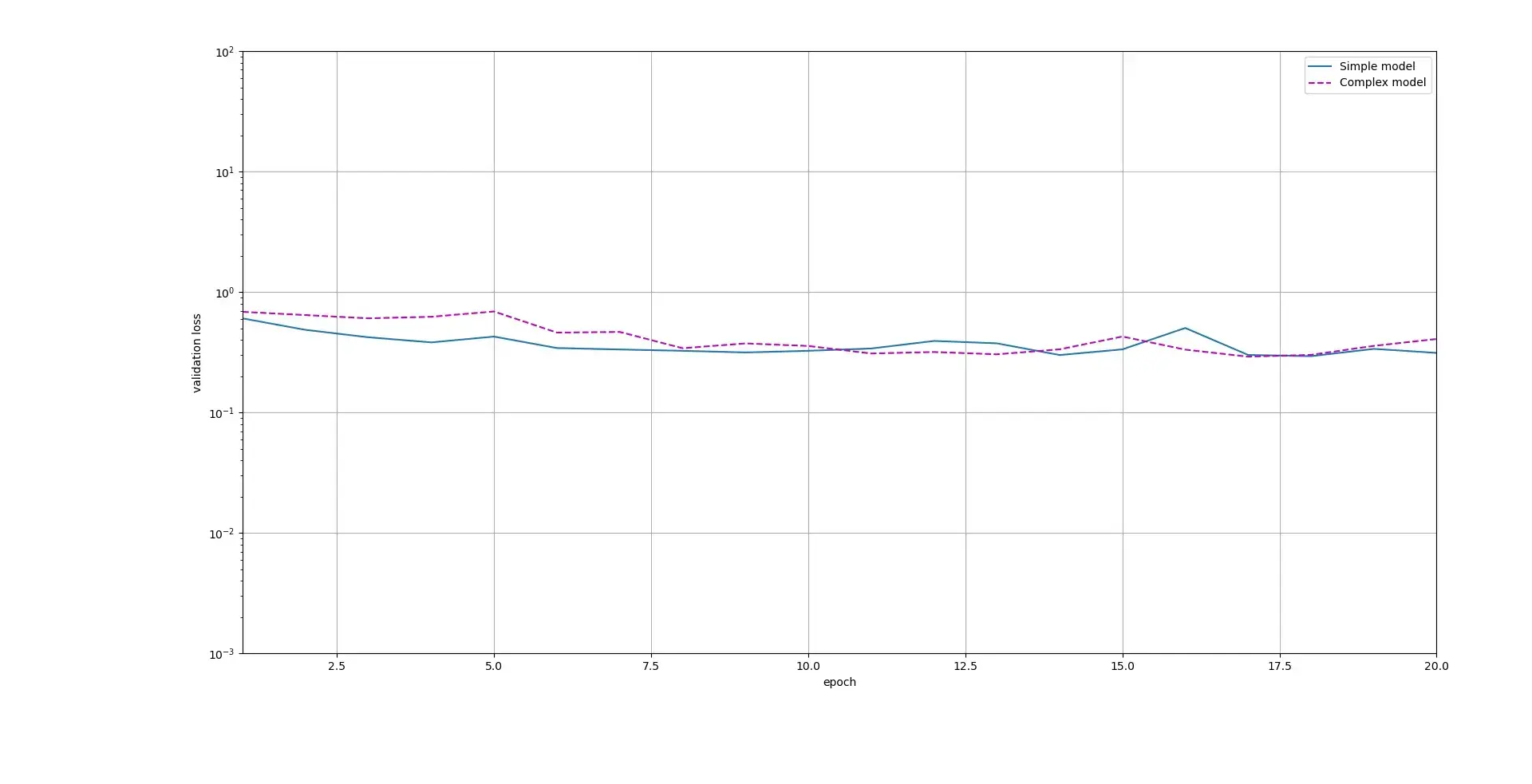
可以看出,简单模型的validation loss基本低于复杂模型,都过拟合(Overfitting)了。
权重正则化(Regularization)
奥卡姆剃刀法则:如果对一个事件有两种解释,最有可能正确的解释是最简单的一种。同样的原则也适用于深度学习(Deep learning)模型:给定一些训练数据和网络架构,许多权重集(许多模型)可以解释数据。简单模型往往不太容易过度拟合。
这里的简单模型指参数更少的模型,或参数值分布(Distribution)的熵更小的模型。一种常见的降低过拟合(Overfitting)的方法就是强制让模型权重只能取较小的值,从而限制模型的复杂度,这使得权重值的分布(Distribution)更加规则。该方法叫权重正则化(Regularization)(weight regularization)。
在神经网络中,参数包括权重和偏差(Bias 偏置 ),我们通常只惩罚权重而不惩罚偏差(Bias 偏置 )。同时我们对每一层使用相同的惩罚系数。
L2正则化(Regularization)
L2正则化(Regularization)(L2 regularization)又被称为**权重衰退(weigth decay)**的L2参数范数(Frobenius norm)惩罚。这个正则化(Regularization)策略通过向目标函数(Objective function)添加一个正则项,来惩罚过大的权重向量。
如果
,则
是
的二阶范数(Frobenius norm),
在前者的基础上加一个平方,相当于欧几里得距离。
以线性回归(Regression)(Linear Regression)中的损失函数(Loss function)为例:
其中,为第
样本的特征,
为其对应的标签;
是权重和偏置参数。为了惩罚权重向量的大小,我们通过添加一个不小于零的常数
来平衡标准损失函数(Loss function)和正则化(Regularization)项的相对贡献。将
设为
表示不进行正则化(Regularization),
越大,对应的正则化(Regularization)惩罚越大。所以我们的新损失函数(Loss function)变为:
这里的常数项是为了求导方便,正则化(Regularization)项的导数是
。
然后在更新时,通过:
变成:
其中是学习率(Learning rate)。
在实现上,参考了PyTorch,加到了优化算法中。所以我们需要重写之前的代码。首先重写Optimizer类:
class Optimizer:
def __init__(self, params, defaults) -> None:
'''
:param params: Tensor列表或字典
:param defaults: 包含优化器默认值的字典
'''
self.defaults = defaults
# 参数分组,比如分为
# 需要正则化(Regularization)的参数和不需要的
# 需要更新的参数和不需要的
self.param_groups = []
param_groups = list(params)
# 如果不是字典
if not isinstance(param_groups[0], dict):
# 就把它转换为字典列表
param_groups = [{'params': param_groups}]
for param_group in param_groups:
self.add_param_group(param_group)
def zero_grad(self) -> None:
for group in self.param_groups:
for p in group['params']:
p.zero_grad()
def step(self) -> None:
raise NotImplementedError
def add_param_group(self, param_group: dict):
assert isinstance(param_group, dict), "param group must be a dict"
params = param_group['params']
# 转换为列表
if isinstance(params, Parameter):
param_group['params'] = [params]
else:
param_group['params'] = list(params)
for name, default in self.defaults.items():
param_group.setdefault(name, default)
self.param_groups.append(param_group)
参考了Pytorch的源码进行实现,下面继续改造随机梯度(gradient)下降(Stochastic gradient descent)(Gradient Descent)法:
class SGD(Optimizer):
'''
随机梯度(gradient)下降(Stochastic gradient descent)(Gradient Descent)
'''
def __init__(self, params, lr: float = 1e-3, weight_decay=0) -> None:
defaults = dict(lr=lr, weight_decay=weight_decay)
super().__init__(params, defaults)
def step(self) -> None:
with no_grad():
for group in self.param_groups:
weight_decay = group['weight_decay']
lr = group['lr']
for p in group['params']:
d_p = p.grad # 我们不能直接修改p.grad
# 对于设置了weight_decay的参数
if weight_decay != 0:
d_p += weight_decay * p
p -= d_p * lr
通过增加一个权重衰退(weight_decay)率来实现L2正则,参考公式(4)。默认为零,即不进行正则惩罚,该值不能为负数,值越大代表惩罚越大。
在代码实现方面,为了简洁理解主线,一般不勾选输入(input)参数值。
通过param_groups,可以为不同的参数设置不同的学习率(Learning rate)和权重衰减(weight decay)(damping)。例如,正则化(Regularization)惩罚只能为权重设置,而不能为偏差(Bias 偏置 )
设置。
然后,测试我们的实现,看是否真的等价于公式的实现:
def test_weight_decay():
weight_decay = 0.5
X = Tensor(np.random.rand(5, 2))
y = np.array([0, 1, 2, 2, 0]).astype(np.int32)
y = Tensor(np.eye(3)[y])
model = Linear(2, 3, False)
model.weight.assign(np.ones_like(model.weight.data))
# 带有weigth_decay
optimizer = SGD(params=model.parameters(), weight_decay=weight_decay)
pred = model(X)
loss = F.cross_entropy(pred, y)
loss.backward()
optimizer.step()
weight_0 = model.weight.data.copy()
# 重新设置权重
model.weight.assign(np.ones_like(model.weight.data))
# 没有weigth_decay
optimizer = SGD(params=model.parameters())
model.zero_grad()
pred = model(X)
# 在原来的loss上加上L2正则
loss = F.cross_entropy(pred, y) + weight_decay / 2 * (model.weight ** 2).sum()
loss.backward()
optimizer.step()
weight_1 = model.weight.data.copy()
assert np.allclose(weight_0.data, weight_1.data)
最后用一个简单的例子来验证正则化(Regularization)的效果。
complex_model = DynamicFFN(1, input_size, 256, output_size)
complex_opt = SGD(complex_model.parameters(), lr=0.1)
complex_l2_model = DynamicFFN(1, input_size, 256, output_size)
# 只为权重设置L2惩罚
complex_l2_opt = SGD([
{"params": complex_l2_model.weights(), 'weight_decay': 0.01},
{"params": complex_l2_model.bias()}], lr=0.1
)
compare_model(train_dl, val_dl, complex_model, complex_l2_model, complex_opt, complex_l2_opt, "Complex model",
"Complex Model(L2)")
上面只为权重设置L2惩罚,同时将权重和偏置的学习率(Learning rate)都设为0.1。
L1正则化(Regularization)
除了L2正则,还有一种方法叫L1正则,即计算L1范数(Frobenius norm)。
如果说L2范数(Frobenius norm)计算的是欧几里得距离,那么L1范数(Frobenius norm)计算的是曼哈顿距离。
L1正则化(Regularization)项定义为:
是每个参数的绝对值之和。
相比L2正则化(Regularization),L1正则化(Regularization)会产生稀疏的值。稀疏指的是有某些参数值为0,这种特性可以用于特征选择(Feature selection)。
References
- Python深度学习(Deep learning)
- DIVE INTO DEEP LEARNING
文章出处登录后可见!