
论文标题:LocalViT: Bringing Locality to Vision Transformers
论文链接:https://arxiv.org/abs/2104.05707v1
论文代码:https://github.com/ofsoundof/LocalViT
发表时间: 2021年4月
Abstract
我们研究了如何将局部性机制引入 Vision Transformer中。Transformer 网络起源于机器翻译,特别擅长对长序列内的远程依赖关系进行建模。尽管可以通过 Transformer 的自我注意机制很好地模拟令牌嵌入之间的全局交互,但缺少用于本地区域内信息交换的本地机制。然而,位置对于图像至关重要,因为它涉及诸如线条,边缘,形状甚至对象之类的结构。
我们通过在前馈网络中引入深度卷积来为视觉变换器添加局部性。这个看似简单的解决方案的灵感来自前馈网络和反向残差块之间的比较。局部性机制的重要性体现在两个方面:
1)广泛的设计选择(激活函数、层放置、扩展比)可用于合并局部性机制,所有适当的选择都可以导致在基线上的性能提升
2)相同的局部性机制成功应用于4个 Vision Transformer,显示了局部性概念的泛化。特别是对于 ImageNet-2012 分类,局部增强转换器的性能优于 DeiT-T 和 PVT-T ,2.6% 和 3.1%,而参数数量和计算量的增加可以忽略不计
Method
Input interpretation
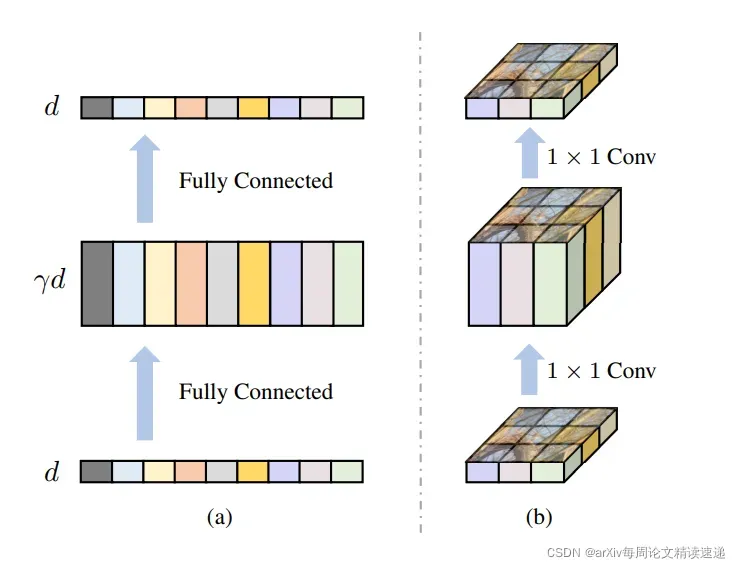
从不同角度可视化 Transformer 中的前馈网络
(a) 输入被视为一个令牌序列
(b) 一个等效的观点是仍然将标记重新排列为 2D 点阵
Locality
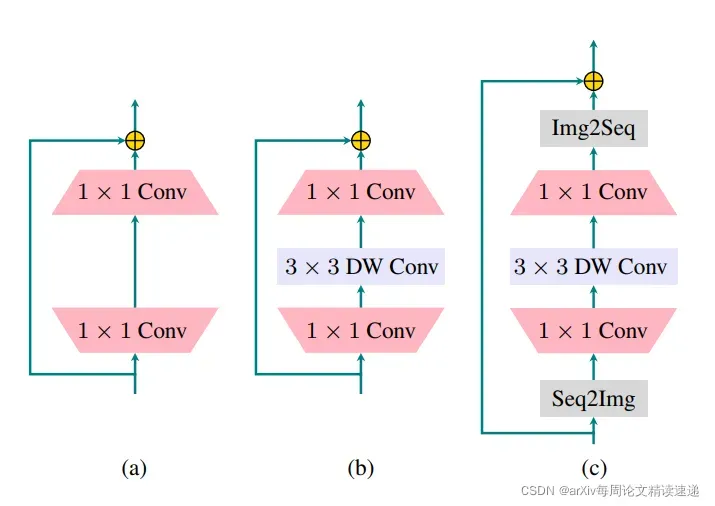 由于仅对特征图应用了 1×1 卷积,因此相邻像素之间缺乏信息交互
由于仅对特征图应用了 1×1 卷积,因此相邻像素之间缺乏信息交互
此外,transformer 的自注意力部分仅捕获所有令牌之间的全局依赖关系
因此,transformer 块没有一种机制来模拟附近像素之间的局部依赖关系
故, (c) 将局部性机制引入转换器的最终使用网络之间的比较
“DW”表示深度卷积。 为了应对卷积操作,在(c)中通过“Seq2Img”和“Img2Seq”添加了序列和图像特征图之间的转换
Experiments
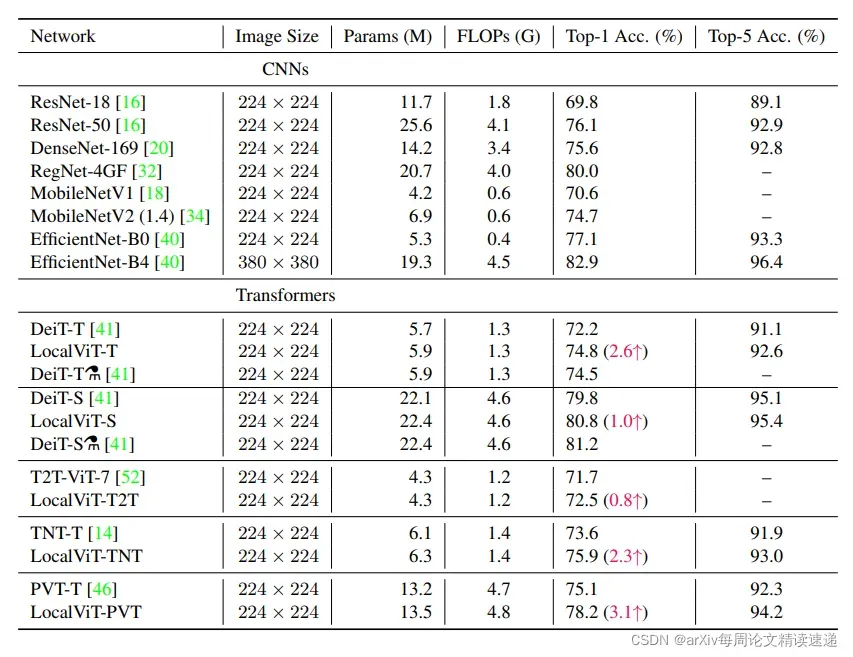
实验目标:不同 CNN 和 ViT 的图像分类结果。为四个不同的 ViT 启用了 Local 功能
实验结果:启用 Local 后的 ViT 效果均有明显提升
文章出处登录后可见!