Transformer + SD解析与实战——Datawhale AI视频生成学习2
文章目录
- Transformer + SD解析与实战——Datawhale AI视频生成学习2
-
- 文生图技术路径
-
- 图像生成的四个阶段
- Gan-based
- VQGAN
- Diffusion
- 主流训练步骤
- ModelScope
- 手写LLM
-
- Attention
- Self-Attention
- Llama结构图
- TransformerBlock
- 生成过程
- UViT和DiT的区别
- 参考来源
文生图技术路径
图像生成的四个阶段

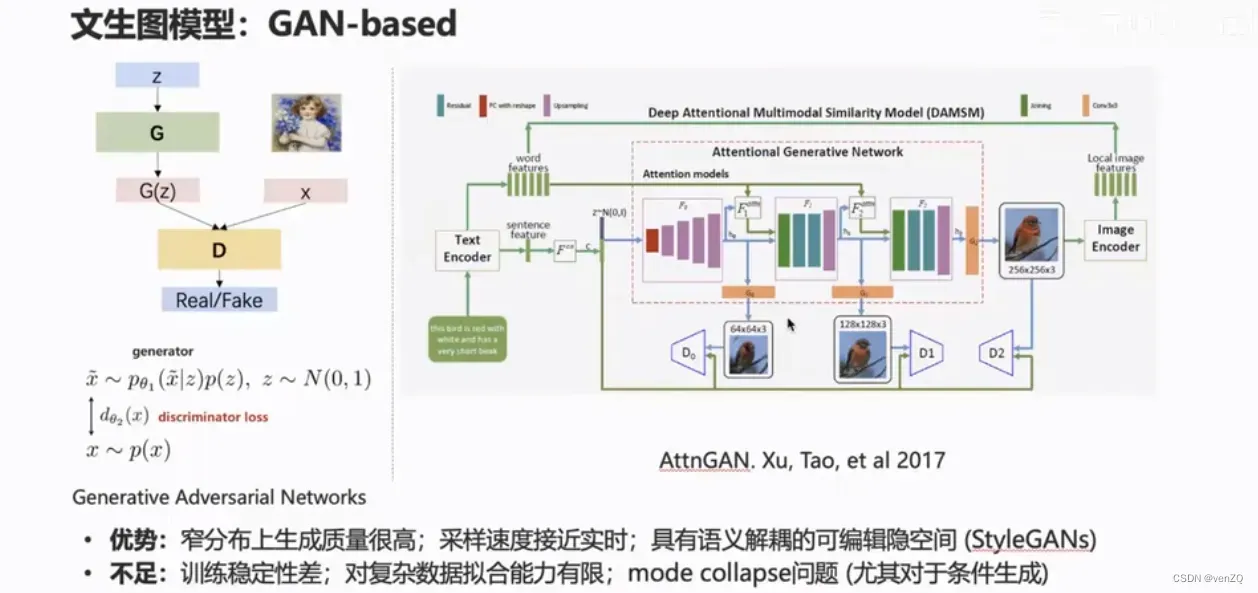
Gan-based
GAN在人脸上比较好,但是不稳定,模式坍塌,窄分布的效果很好(人脸、人体)。对于自然分布的领域很好。
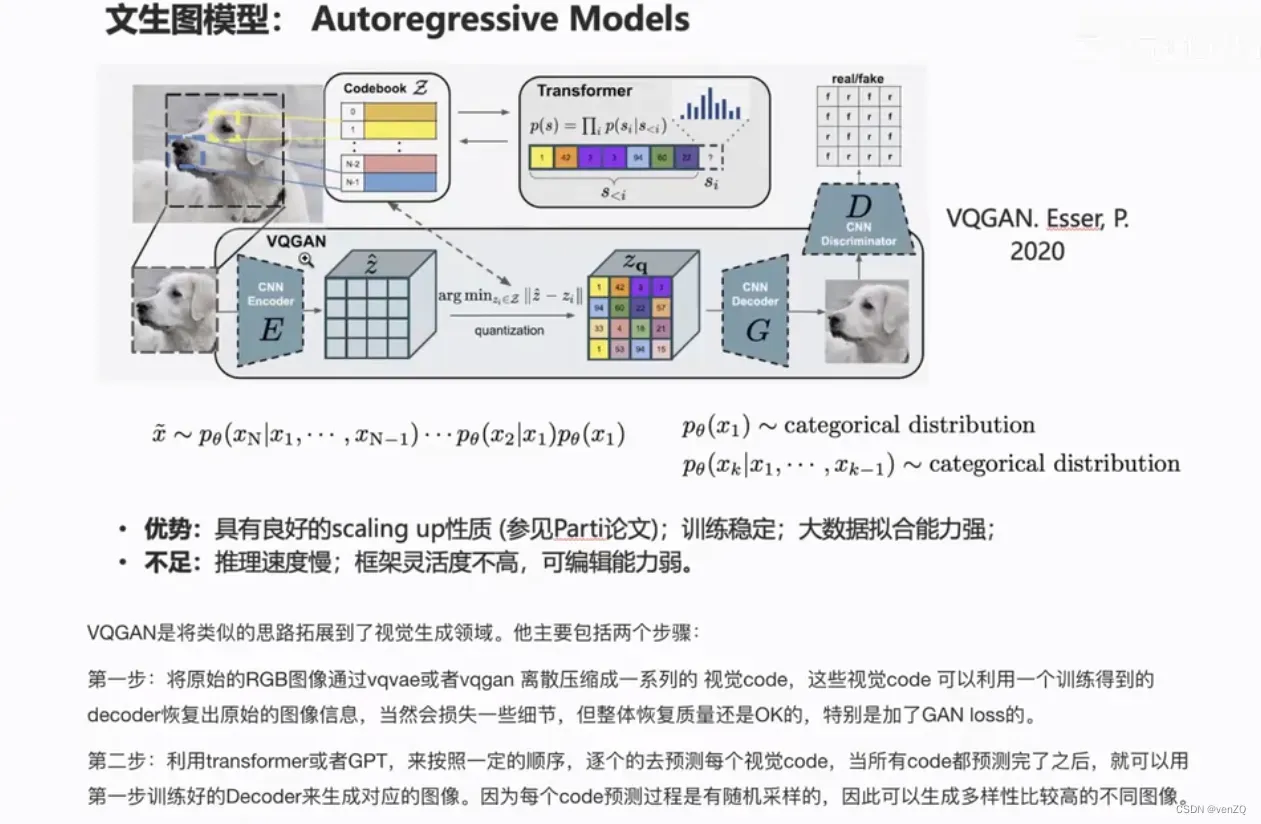
VQGAN
VQ-GAN是自回归方式,视频生成
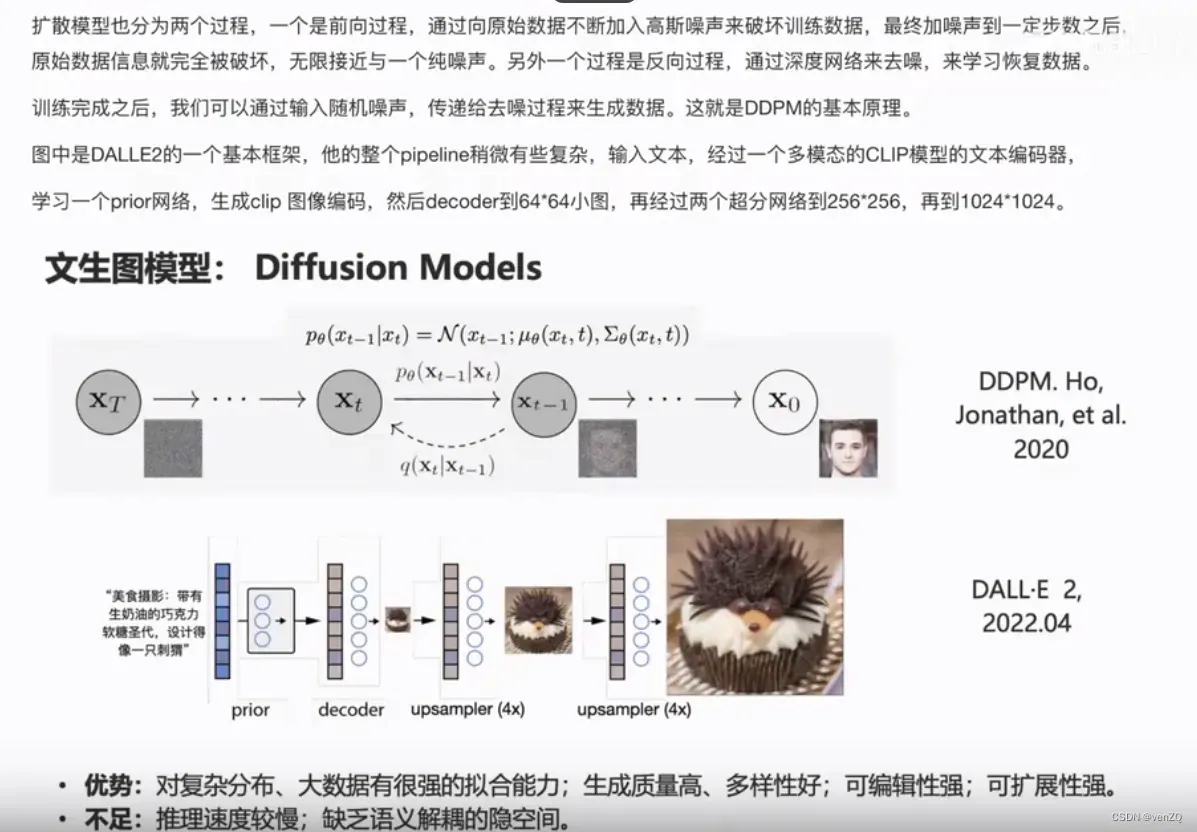
Diffusion
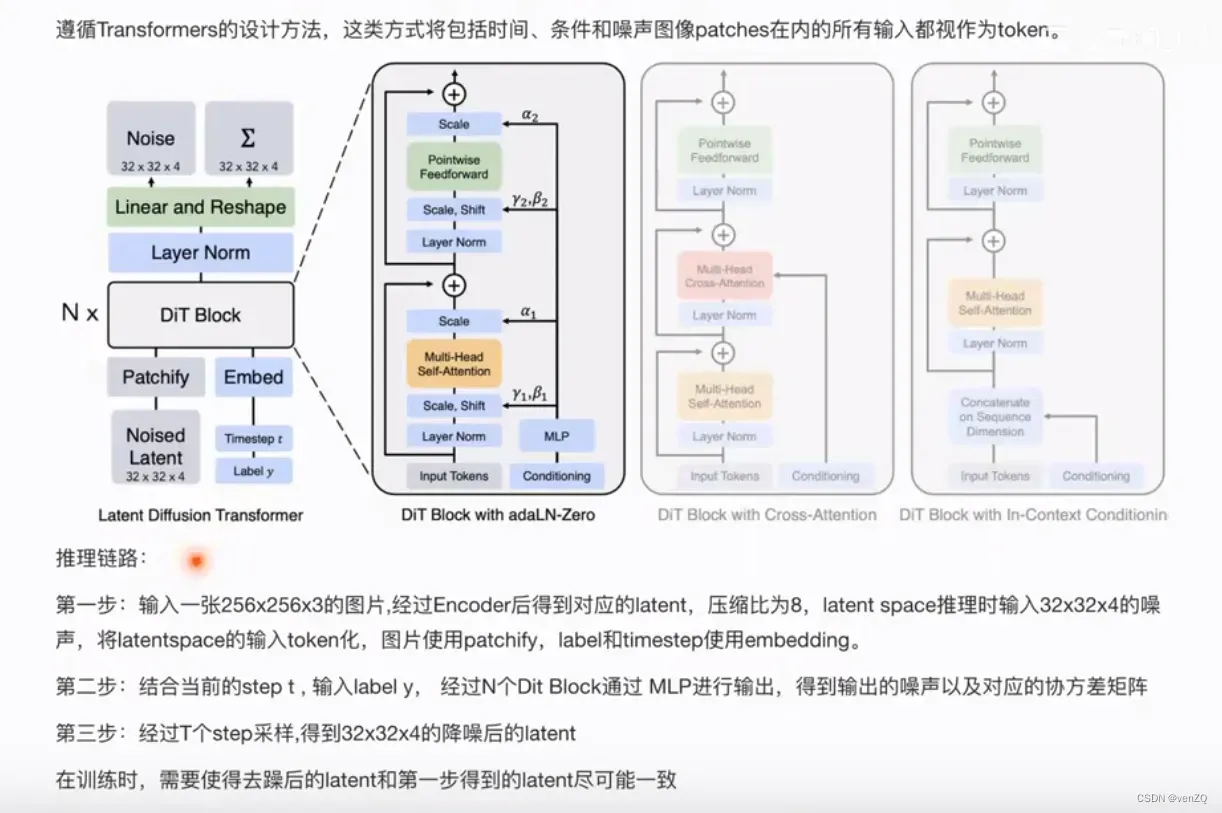
基于transformer的diffusion
输入是一张256×256像素的图像,具有3个颜色通道(RGB)。图像通过编码器(Encoder)处理,生成一个压缩后的表示形式,称为latent表示,其空间维度被压缩为32x32x4。latent space的维度为32x32x4的向量。将latent space的每个token化,即用patchify方法,将label和timestep拼接上embedding。
主流训练步骤
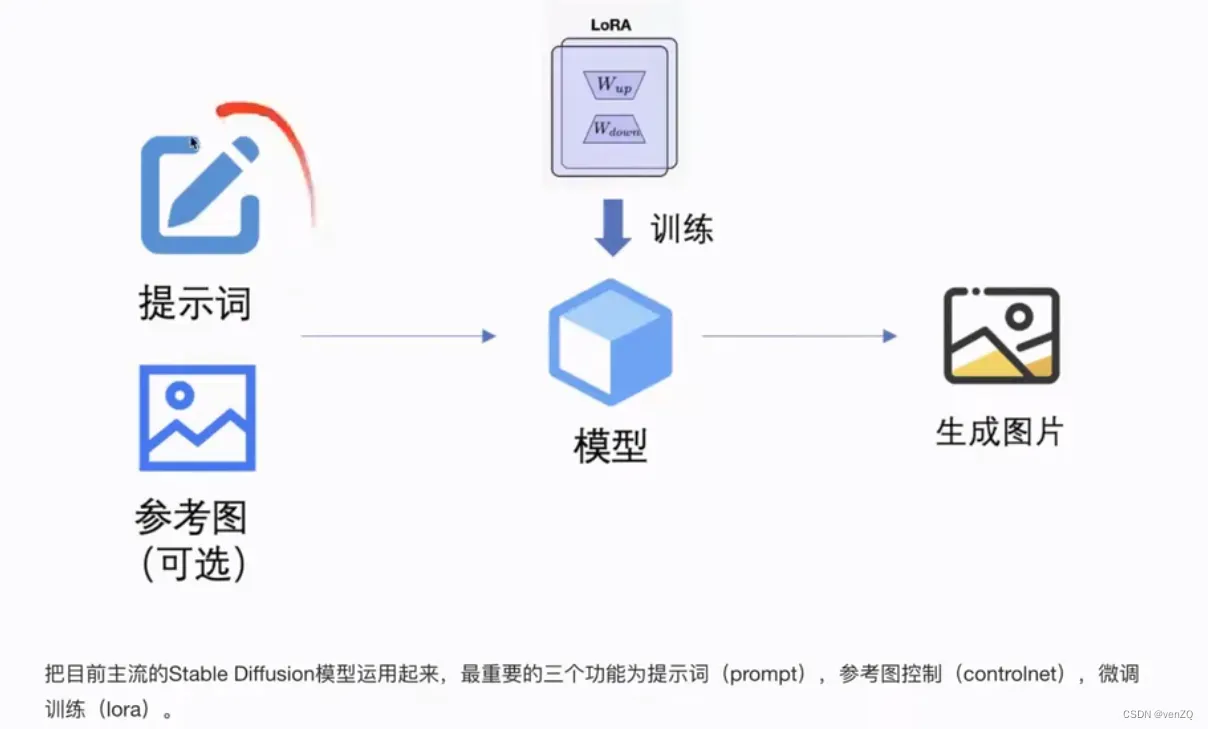
ModelScope
modelscope scepter万能图片生成工作台
可以直接用它们的低代码平台做推理
页面体验:https://modelscope.cn/studios/iic/scepter_studio/summary
也可以在“我的Notebook”里面创建笔记本,然后输入下面两行代码做一下训练端的
pip install scepter
python -m scepter.tools.webui --language zh
视频生成发展
脱离了4s的发展

手写LLM
Attention

第一行:是target,
是source
Self-Attention
对于encoder和decoder的不同attention,处理的方式可能会不一样。对于encoder来说,不需要mask,可以看到所有的token,而Decoder是自回归,需要mask。
multi-head: attention可以分成多个,不同的注意力可以注意到不同的地方。

Llama结构图
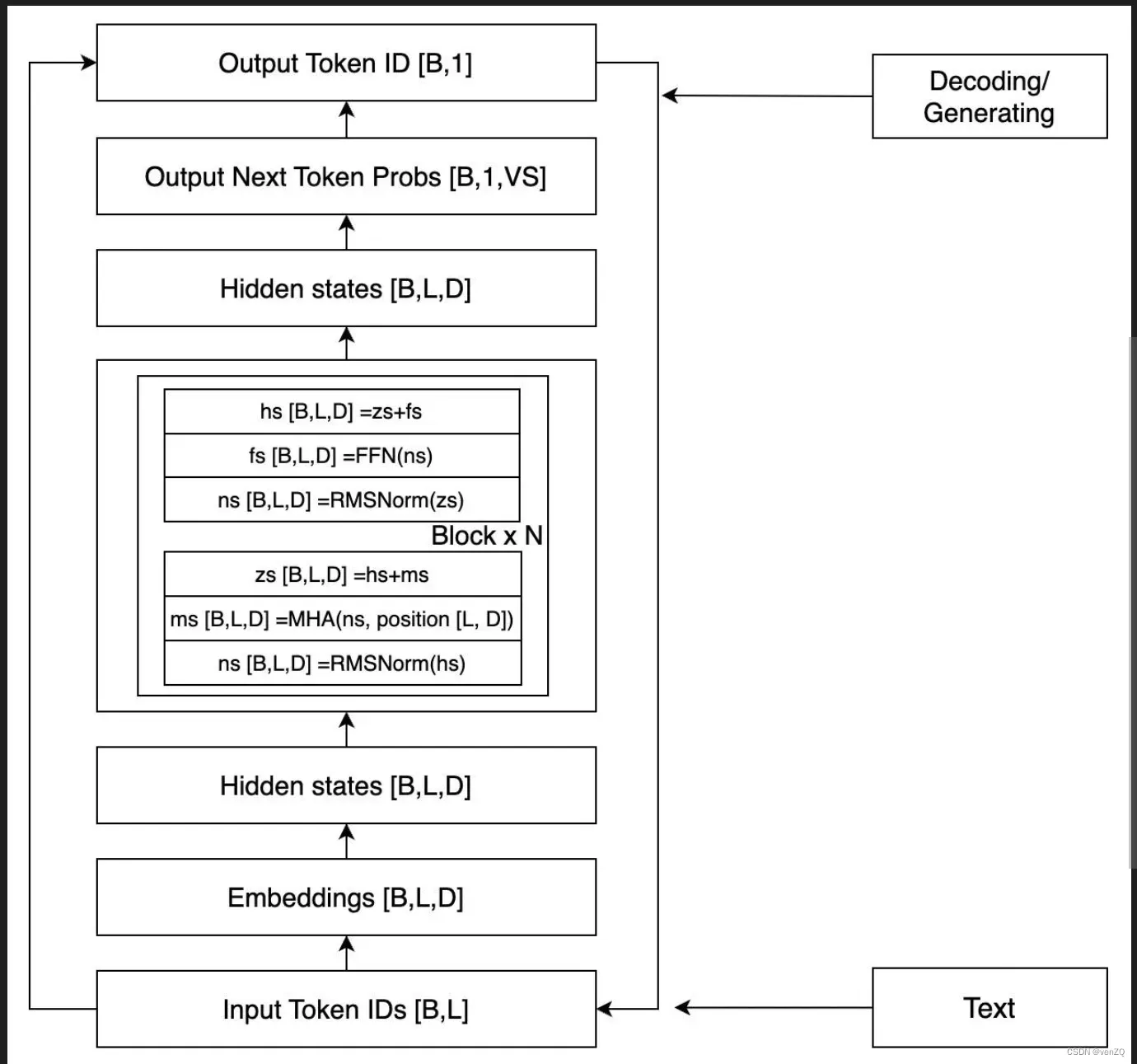
TransformerBlock
class TransformerBlock:
def __init__(self, weight: dict, layer_id: int, args: ModelArgs):
self.attention = Attention(
weight.get(f"model.layers.{layer_id}.self_attn.q_proj.weight"),
weight.get(f"model.layers.{layer_id}.self_attn.k_proj.weight"),
weight.get(f"model.layers.{layer_id}.self_attn.v_proj.weight"),
weight.get(f"model.layers.{layer_id}.self_attn.o_proj.weight"),
args
)
self.feed_forward = FeedForward(
weight.get(f"model.layers.{layer_id}.mlp.up_proj.weight"),
weight.get(f"model.layers.{layer_id}.mlp.gate_proj.weight"),
weight.get(f"model.layers.{layer_id}.mlp.down_proj.weight"),
)
self.input_layernorm = RMSNorm(
weight.get(f"model.layers.{layer_id}.input_layernorm.weight"),
eps=args.norm_eps
)
self.post_attention_layernorm = RMSNorm(
weight.get(f"model.layers.{layer_id}.post_attention_layernorm.weight"),
eps=args.norm_eps
)
- attention层(q, k, v, o)
- feed_forward
- ln_pre
- ln_post
生成过程
def generate(
self,
input_ids: Array["B,L", np.int32],
max_new_tokens: int,
do_sample: bool = True,
temperature: float = 1.0,
top_p: float = 0.0,
top_k: int = 0,
):
prev_pos = 0
_bs, prompt_len = input_ids.shape
max_new_tokens = min(self.args.max_seq_len - prompt_len, max_new_tokens)
for curr_pos in range(prompt_len, prompt_len + max_new_tokens):
logits = self(input_ids[:,prev_pos: curr_pos], prev_pos)
nxt_logits = logits[:, -1, :] # 用最后一个token产生的
if do_sample: # 采样,根据概率分布和分布值采样
nxt_ids = do_sampling(nxt_logits, temperature, top_p, top_k)
else:
probs = softmax(nxt_logits)
nxt_ids = probs.argmax(-1, keepdims=True) # 只取概率最大的 ,可能每次生成的都一样
prev_pos = curr_pos
input_ids = np.concatenate([input_ids, nxt_ids], axis=1)
yield nxt_ids
重要的采样函数
def top_k_logits(nxt_logits: Array["B,VS"], k: int): # 前k个概率大的采样
_bs, vs = nxt_logits.shape
assert k < vs
idxes = nxt_logits.argpartition(-k, axis=-1)[:,[-k]]
k_vals = np.take_along_axis(nxt_logits, idxes, axis=1)
scores = np.where(nxt_logits < k_vals, -np.inf, nxt_logits)
return scores
def top_p_logits(nxt_logits: Array["B,VS"], top_p: float): # 概率值为p的进行采样
assert 0.0 < top_p < 1.0
bs, _vs = nxt_logits.shape
sorted_indices = np.argsort(nxt_logits, axis=-1)
sorted_logits = np.take_along_axis(nxt_logits, sorted_indices, axis=-1)
cum_probs = softmax(sorted_logits).cumsum(axis=-1)
sorted_idxes_to_remove = cum_probs <= (1 - top_p)
# Use broadcasting to scatter the boolean values to the original shape
indices_to_remove = np.zeros_like(sorted_logits, dtype=bool)
indices_to_remove[np.arange(bs)[:, None], sorted_indices] = sorted_idxes_to_remove
# Mask the logits
scores = np.where(indices_to_remove, -np.inf, nxt_logits)
return scores
def sampling(probs: Array["B,VS"]):
bs, vocab_size = probs.shape
rng = np.random.default_rng() # 函数对每个批次的概率分布执行采样操作,使用 numpy 的 choice 函数根据概率分布随机选择下一个词的索引
res = []
for b in range(bs):
bp = rng.choice(vocab_size, size=1, p=probs[b])
res.append(bp)
samples = np.stack(res)
return samples
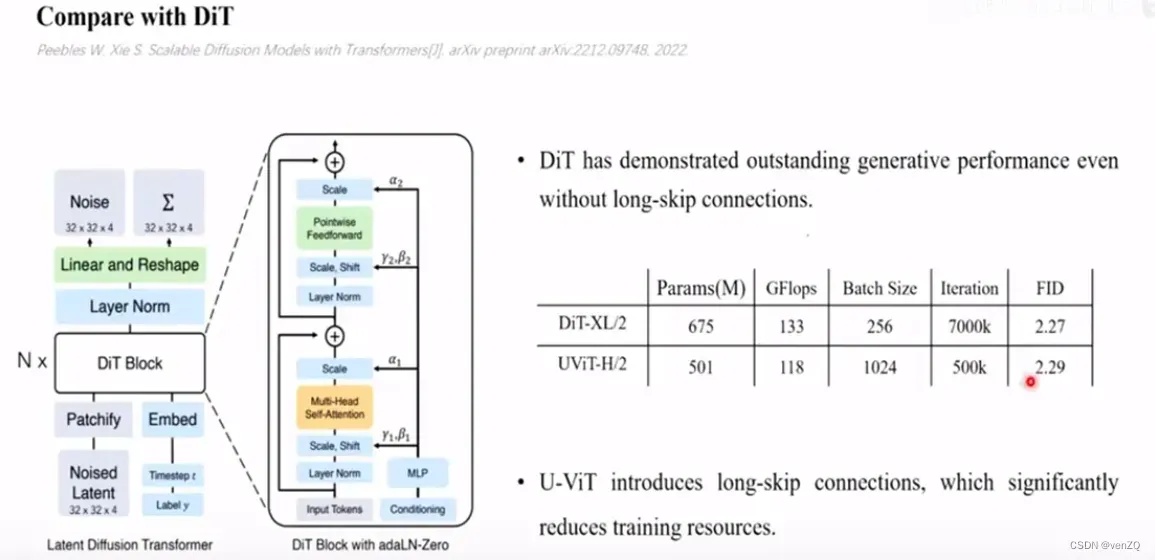
UViT和DiT的区别
参考来源
[1] sora-tutorial
版权声明:本文为博主作者:venZQ原创文章,版权归属原作者,如果侵权,请联系我们删除!
原文链接:https://blog.csdn.net/weixin_46112284/article/details/136593819