一、基本原理概述
基于BP神经网络的的汽车牌照识别系统的处理过程分为预处理、边缘提取、车牌定位、字符分割、字符识别五大模块。具体涉及以下几个过程:
① 车牌原图:由数码相机或其他扫描设备拍摄的车牌图像。
②车牌图像预处理:对动态采集的车牌图像进行滤波和边界增强,克服图像干扰。
③ 车牌定位:计算边缘图像的投影面积,找到峰谷点,大致确定车牌的位置,然后在连通域内计算纵横比,去掉不在连通域内的阈值范围,最后得到车牌字符区域。
④ 字符分割:使用投影检测的字符位置分割方法得到单个字符。
⑤ 字符库:为下一次字符识别建立字符模板库。
⑥ 字符识别:基于人工神经网络的OCR算法,通过训练识别出相关的字符,得到最后的汽车牌照,包括英文字母和数字。
2、设计方案及实验验证
2.1 车牌图像预处理
首先将车牌图像转为灰度,然后对车牌图像进行二值化后腐蚀,去除车牌图像的噪声。对车牌图像进行闭合操作,使车牌所在的区域形成一个连接,然后再进行形态学滤波,去除其他区域。上述过程的结果如下图所示:

2.2 车牌定位
经过预处理后得到的车牌图像,可以发现车牌位置有明显的矩形图样,如图1(f)所示,通过对矩形区域的定位即可获得具体的车牌位置。
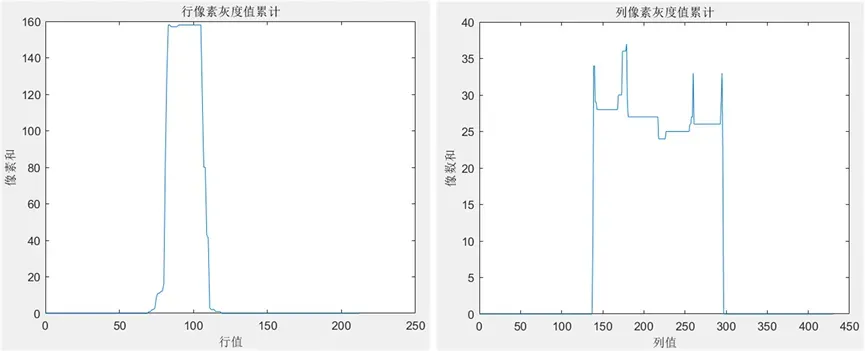
得到车牌定位后的图像如图3所示。

2.3 车牌字符分割
在车牌自动识别过程中,字符分割具有连接过去和未来的功能。当得到定位的车牌图像后,可以对其进行字符分割,并利用分割结果进行字符识别。

2.4 建立字符模板数据库
模板库的合理建造是字符识别的关键之一,所以在字符识别之前必须把模板库设置好。汽车牌照的字符一般有7个,大部分车牌第一位是汉字,通常代表车辆所属省份,或是军种、警别等有特定含义的字符简称;紧接其后的为字母与数字。车牌字符识别与一般文字识别的区别在于它的字符数有限,十个阿拉伯数字09、26个大写英文字母AZ。所建立的字符模板如图5所示。

2.5 车牌字符识别
基于人工神经网络的字符识别主要有两种方法:一种方法是先提取待识别字符的特征,然后利用得到的特征训练神经网络分类器。识别效果与字符特征的提取有关,往往比较耗时。因此,字符特征的提取成为研究的关键。另一种方法是充分利用神经网络的特性,直接将要处理的图像输入到网络中,网络自动实现特征提取直到识别。本设计采用主干人工神经网络的方法对车牌进行字符识别。
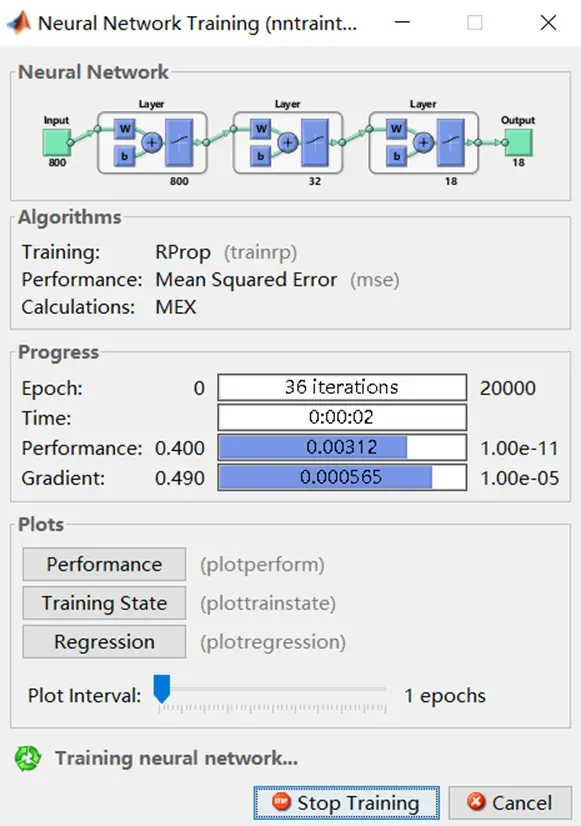
识别结果如图7所示。
相关程序代码请私信博主。
文章出处登录后可见!