0. 引言
BERT全称为 Bidirectional Encoder Representation from Transformers(来自 Transformers 的双向编码器表示),是谷歌2018年发表的论文中1,提出的一个面向自然语言处理任务的无监督预训练语言模型。其意义在于:大量无标记数据集中训练得到的深度模型,可以显著提高各项自然语言处理任务的准确率。
BERT采用Transformer的编码器(Encoder)结构作为特征提取器,并使用与之配套的MLM训练方法,实现输入序列文本的双向编码;与只使用前序文本信息提取语义的单向编码器(如GPT等)相比,BERT具有更强的语义信息提取能力。
1. 预训练任务
BERT的作者认为:使用两个方向(从左至右和从右至左)的单向编码器拼接而成的双向编码器,在性能、参数规模和效率等方面都不如直接使用双向编码器强大;这是 BERT 模型使用 Transformer Encoder 结构作为特征提取器,而不拼接使用两个方向的 Transformer Decoder 结构作为特征提取器的原因。
这也令 BERT 模型不能像 GPT 模型一样,继续使用标准语言模型的训练模式,因此 BERT 模型重新定义了两种模型训练方法(即:预训练任务):MLM 和 NSP。BERT用MLM(Masked Language Model,掩码语言模型)方法训练词的语义理解能力,用NSP(Next Sentence Prediction,下句预测)方法训练句子之间的理解能力,从而更好地支持下游任务。
1.1 MLM
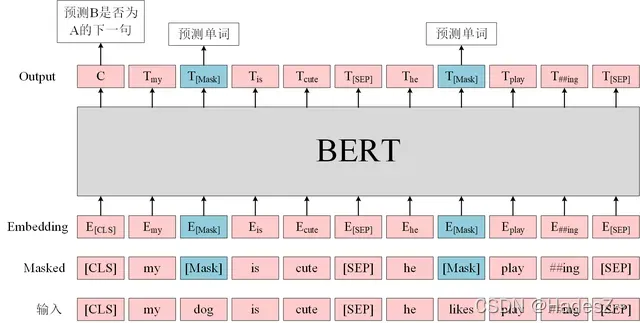
MLM是借鉴完形填空任务和Word2Vec中CBOW算法的思想,而定义的一种模型预训练任务。具体而言,就是随机抽取部分词进行掩码操作(用 ‘为目标函数来优化模型参数(仅计算被掩码单词的交叉熵之和,将其作为损失函数),如图1所示。
在模型微调训练或模型推理阶段,输入的文本序列中不再含有掩码标记,因此不可忽视的是:MLM训练方法的训练集与测试集数据之间,存在不可避免的系统性数据分布差异,这会产生训练与预测数据偏差导致的性能损失。为改善这一弊端,BERT并不总是用掩码标记替换训练样本中被选定的掩码词,而是在每样本随机抽取15%的掩码词后,对80%的样本用掩码标记 ‘
其中,对一小部分掩码词不做替换,是为了缓解训练文本与预测文本的偏差带来的性能损失。此外,对另一小部分掩码词做随机替换,是为了让BERT学会根据上下文信息自动纠错;假设不随机替换的一小部分训练样本,BERT遇到非掩码标记的词时,直接输出该词即可得到最优交叉熵,而加入随机替换样本则强制模型综合上下文信息整体推测预测词,避免模型通过“偷懒”的方式获得最优目标函数的隐患;简而言之,这增加了BERT模型的鲁棒性和对上下文信息的提取能力。
且上述这四个概率分配比例是超参数,其取值由BERT在预训练过程中尝试过各种配置比例后,通过对比测试结果得到最优参数值。
1.2 NSP
很多自然语言处理的下游任务(如问答和自然语言推断等)都基于两个句子做逻辑推理,而语言模型并不具备直接捕获句子间语义联系的能力(该能力由训练方法和目标函数的特性决定),BERT采用NSP训练方法,使用模型学会捕捉句子间的语义联系。
具体而言:模型的输入语句由两个句子组成,其中有50%的概率将语义连贯的两个连续句子作为训练样本(连续句对应取自篇章级别的语料,以确保前后语句的语义强相关),另有50%的概率将完全随机抽取的两个句子作为训练样本,模型要根据输入的两个句子,判断它们是否属于真实的连续句对,如图1所示。
其中,[SEP] 标签表示分隔符,用于区分两个句子,而 [CLS]标签对应的输出向量作为句子整体的语义表示,用于类别预测。若结果为1,则表示输入语句为真实的连续句子,其上下文有语义联系;若结果为0,则表示输入语句为随机组合的句子,上下文并没有语义联系。
2. 模型结构
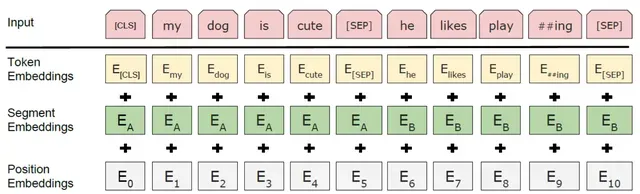
BERT模型在继承 Transformer 编码器(Encoder)结构的同时,也根据自身任务需求,对其输入层结构做了相应改进。一方面为适应NSP任务,BERT模型的输入层结构在原有静态词向量编码(Token Embeddings)和位置编码(Position Embeddings)的基础上,增加了语句分割编码(Segment Embeddings),该层的输出结果是三种 Embedding 编码之和;另一方面,BERT模型的位置编码方法,由原来 Transform 模型的三角函数编码,改变为由可学习的模型参数编码。如下图所示:
3. 微调训练
根据下游任务模型输入和输出的不同形式,微调训练支持的下游任务可分为四类:单句标注、单句分类、句对分类和文本问答。接下来按照输入和输出的形式,来介绍BERT如何通过微调训练来使用这四类任务的需求。
文章出处登录后可见!