pytorch自学(1)之L1Loss()损失函数源码
苦于在做多分类分割任务时不会改损失函数,只得从头学起。
L1Loss()
看源码,这是第一个loss,那就从他开始学。
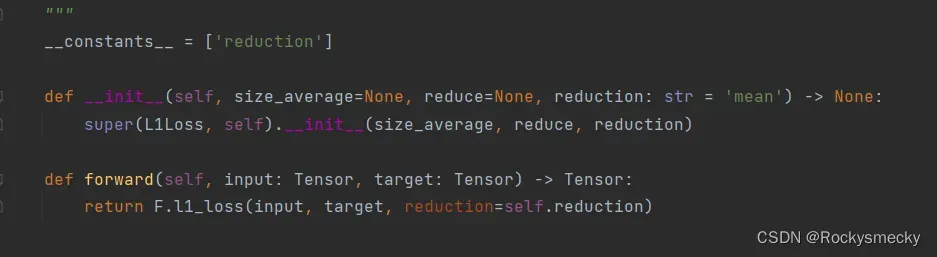
这里不考虑L1Loss是什么,只关心源代码的实现。
首先是一个双下划线变量,只记得是什么类内私有变量。不解,问老师。

似乎没有用到这个变量,也许是多态啥的,不了解,欢迎大佬指正。
然后是初始化,这个比较简单,继承自_Loss类,_Loss这个类本身也没干啥事,就是声明了几个变量。声明变量的时候应该是考虑了老版本的兼容问题。耐下性子看源码发现其实不是难点,就是被跳来跳去的文件给吓住了。
然后就是通过F.l1_loss实现forward计算,继续跟着跳。
F.l1_loss()
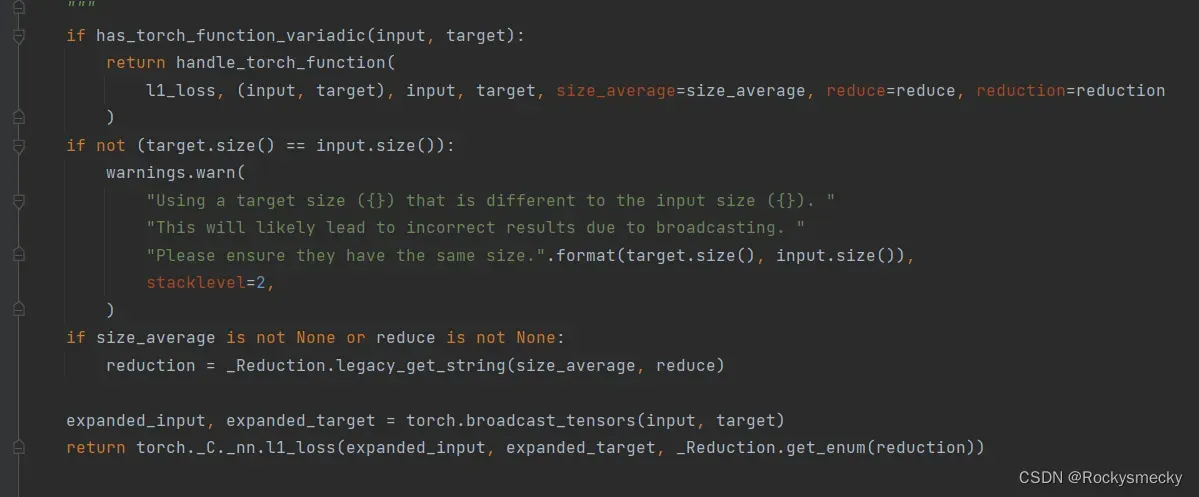
上来第一个if又把我干蒙了,继续问老师。

似乎是说,我要先检查一下是不是tensor,如果是tensor就用处理tensor的办法来计算。我估摸着可能是和数据是在cuda里还是在cpu里有关,用了cuda则会用gpu计算,否则就用cpu计算,纯粹猜想欢迎批评。
接下来的两个if都比较简单,一个是判断输入与输出的个数,另一个是类似于_Loss继续解决版本兼容问题。
然后是torch.broadcast_tensors,继续懵逼。问老师,这个叫张量广播技术,是一种对齐思想,能够简化计算。我估计又是torch对于gpu运算的专门优化,不深究了,知道有这么回事儿就行。
torch._C._nn.l1_loss
最后就是这个鬼东西,不能跳转了,老师说之后都是用c++去实现了,我这个菜鸟不用管,但可以给我一个简单的代码帮我理解。
Tensor l1_loss(const Tensor& input, const Tensor& target, int64_t reduction) {
auto input_ = input.contiguous();
auto target_ = target.contiguous();
auto loss = at::l1_loss_cpu(input_, target_, reduction);
return loss;
}
contiguous()这个操作似乎经常见到,继续问老师。

又是优化速度,人麻了,跳过。
at::l1_loss_cpu()
终于在这个c++的源码里找到损失是如何计算的了,太离谱了,为什么python要这么设计。以下全是老师的话。
Tensor l1_loss_cpu(const Tensor& self, const Tensor& target, int64_t reduction) {
auto dims = at::broadcast_tensors(self, target).size();
auto expanded_input = self.expand(dims);
auto expanded_target = target.expand(dims);
auto input_ = expanded_input.contiguous();
auto target_ = expanded_target.contiguous();
Tensor result;
AT_DISPATCH_FLOATING_TYPES_AND_HALF(input_.scalar_type(), "l1_loss_cpu", [&] {
result = at::empty({0}, self.options());
cpu_kernel_reduce(
input_,
target_,
result,
reduction == Reduction::None ? at::Reduction::None : at::Reduction::Mean,
[] (scalar_t a, scalar_t b) -> scalar_t {
return std::abs(a - b);
}
);
});
return result;
}
at::l1_loss_cpu() 函数的输入参数为 self 和 target 两个张量,以及一个整数 reduction,用于指定如何降维计算损失。
该函数首先调用 at::broadcast_tensors() 函数对 self 和 target 两个张量进行广播,以使它们具有相同的形状,以便进行逐元素的 L1 Loss 计算。dims 变量存储广播后的形状。
接下来,使用 expand() 方法将 self 和 target 张量扩展为广播后的形状,得到 expanded_input 和 expanded_target 张量。然后,使用 contiguous() 方法将这两个张量转换为连续的内存块,存储在 input_ 和 target_ 变量中,以便后续计算使用。
在此之后,根据输入张量的数据类型,使用 AT_DISPATCH_FLOATING_TYPES_AND_HALF() 宏将计算 L1 Loss 的代码分派到相应的 CPU 内核函数中执行。在计算过程中,根据 reduction 参数的值,将计算结果缩减为标量(如果 reduction 为 Reduction::Mean 或 Reduction::Sum),或者保留为张量(如果 reduction 为 Reduction::None)。
最后,将计算结果存储在 result 变量中,并返回该变量。
到我了
非常有意思哦,虽然看不懂这些内核下的代码,但它似乎只计算了a-b,也就是类似于elment-wise。input_.scalar_type()返回的是枚举类型,而关于
[] (scalar_t a, scalar_t b) -> scalar_t {
return std::abs(a - b);
}
这段代码是一个lambda表达式,它定义了一个匿名函数,函数的输入是两个类型为
scalar_t的参数a和b,返回值也是类型为scalar_t的结果。该lambda表达式的主体是
return std::abs(a - b),它计算了输入参数a和b之间的绝对差,并将其作为结果返回。
在此处,该lambda表达式被用作thrust::transform_reduce函数的参数,这个函数会
对输入序列进行一系列的操作,并返回一个汇总结果。该lambda表达式将被用于对输入序
列中的每对元素执行绝对差的计算,以便求得它们的L1范数。
结合老师的指导,猜测也许是对的,然后顺便看了一下该损失函数的gpu版本。
Tensor& l1_loss_gpu_out(Tensor& output, const Tensor& self, const Tensor& target, int64_t reduction) {
// 根据需要在 CPU 或 GPU 上分配内存
auto& ctx = self.is_cuda() ? self.get_device() : kCPU;
Tensor input_contig = self.contiguous();
Tensor target_contig = target.contiguous();
output.resize_({});
output = at::empty({0}, self.options().dtype(kFloat).device(ctx));
// 在 GPU 上执行 L1 Loss
AT_DISPATCH_FLOATING_TYPES_AND_HALF(input_contig.scalar_type(), "l1_loss_gpu", [&] {
auto input = input_contig.data_ptr<scalar_t>();
auto target = target_contig.data_ptr<scalar_t>();
auto output_data = output.data_ptr<scalar_t>();
int64_t numel = input_contig.numel();
l1_loss_kernel<scalar_t><<<GET_BLOCKS(numel), CUDA_NUM_THREADS>>>(
numel, input, target, output_data, reduction);
});
return output;
}
感觉没什么意思也学不到啥,过于底层有点看不懂了,好像用使用cuda对L1Loss的计算又单独进行了优化,那就不关我的事了。
今天就学到这里了,搓老头环去。
文章出处登录后可见!