使用Python在本地模拟多个客户端,然后由服务器统一管理进行联邦学习,客户端在本地用自己的数据对模型进行训练,服务器将训练结果聚合更新模型并分发给客户端,客户端继续训练。
内容
一、简介
1.什么是联邦学习
2.联邦学习中的隐私问题
2、环境准备
三、具体实施
1.编写配置文件
2.获取训练数据集
3.编写服务器端代码
4.编写客户端代码
5.编写main函数
6.编写模型文件
四、测试
五、联邦学习与集中训练的效果对比
6.总结
一、简介
1.什么是联邦学习
联邦学习是一个机器学习的概念。其概念是服务器先将统一的模型分发给客户端,然后客户端使用本地数据进行训练,然后更新模型并发回服务器。服务端收到各方新模型后,计算再更新全局模型,再划分更新后的模型继续训练,直到达到次数或收敛,最终得到多方联合训练的模型.联邦学习的核心理念是“模型不理解数据移动,数据可用且不可见”。
(ps:这里只做简单的介绍,更加详细的联邦学习介绍可以参考下面这篇文章)
https://blog.csdn.net/cao812755156/article/details/89598410?ops_request_misc=%257B%2522request%255Fid%2522%253A%2522164941377116780357226006%2522%252C%2522scm%2522%253A%252220140713.130102334..%2522%257D&request_id=164941377116780357226006&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2~blog~top_positive~default-1-89598410.nonecase&utm_term=%E8%81%94%E9%82%A6%E5%AD%A6%E4%B9%A0&spm=1018.2226.3001.4450![]() https://blog.csdn.net/cao812755156/article/details/89598410?ops_request_misc=%257B%2522request%255Fid%2522%253A%2522164941377116780357226006%2522%252C%2522scm%2522%253A%252220140713.130102334..%2522%257D&request_id=164941377116780357226006&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2~blog~top_positive~default-1-89598410.nonecase&utm_term=%E8%81%94%E9%82%A6%E5%AD%A6%E4%B9%A0&spm=1018.2226.3001.4450
https://blog.csdn.net/cao812755156/article/details/89598410?ops_request_misc=%257B%2522request%255Fid%2522%253A%2522164941377116780357226006%2522%252C%2522scm%2522%253A%252220140713.130102334..%2522%257D&request_id=164941377116780357226006&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2~blog~top_positive~default-1-89598410.nonecase&utm_term=%E8%81%94%E9%82%A6%E5%AD%A6%E4%B9%A0&spm=1018.2226.3001.4450
2.联邦学习中的隐私问题
联邦学习的本质是机器学习,但是传统的以数据为中心的学习变成了每个客户端自己的学习,只有参数的交换才能保证数据的安全和隐私,但这只是最基本的,鉴于各种针对联邦学习的攻击也应该与其他技术相结合,以确保学习过程的安全。
(ps:这里对联邦学习中的数据安全问题不进行过多的分析,感兴趣的可以参考下面的论文,写的非常好,并且容易理解)
http://www.jos.org.cn/jos/article/abstract/6446![]() http://www.jos.org.cn/jos/article/abstract/6446
http://www.jos.org.cn/jos/article/abstract/6446
2、环境准备
本实验基于python实现,使用机器学习库PyTorch。
- anaconda、python、PyTorch
- 编译器使用Pycharm
- 数据集:cifar10
- 模型:ResNet-18
基本流程:
- 服务器按配置文件生成初始化模型,客户端按照自己的ID将数据集横向不重叠切割
- 服务器向客户端发送全局模型
- 客户端接收到全局模型(来自服务端),在本地通过多次迭代计算局部参数差返回给服务端
- 服务器聚合各个客户端的差异来更新模型,然后评估当前模型的性能
- 如果性能未达标,则重复2过程,否则结束
三、具体实施
1.编写配置文件
在项目文件夹下建立一个utils文件夹,在里面创建配置文件conf.json,其中的数据可以根据需要自行更改。(因为json文件不允许注释,所以将每个值赋值两次,第一次用作注释,第二次才是真实的值)
{
"model_name" : "模型名称",
"model_name" : "resnet18",
"no_models" : "客户端总数量",
"no_models" : 5,
"type" : "数据集信息",
"type" : "cifar",
"global_epochs" : "全局迭代次数",
"global_epochs" : 5,
"local_epochs" : "本地迭代次数",
"local_epochs" : 2,
"k" : "每一轮选用k个客户端参与训练",
"k" : 3,
"batch_size" : "本地训练每一轮的样本数",
"batch_size" : 32,
"notes" : "本地训练的超参数设置",
"lr" : 0.001,
"momentum" : 0.0001,
"lambda" : 0.1
}2.获取训练数据集
在项目文件夹下创建datasets.py文件。
from torchvision import datasets, transforms
# 获取数据集
def get_dataset(dir, name):
if name == 'mnist':
# root: 数据路径
# train参数表示是否是训练集或者测试集
# download=true表示从互联网上下载数据集并把数据集放在root路径中
# transform:图像类型的转换
train_dataset = datasets.MNIST(dir, train=True, download=True, transform=transforms.ToTensor())
eval_dataset = datasets.MNIST(dir, train=False, transform=transforms.ToTensor())
elif name == 'cifar':
# 设置两个转换格式
# transforms.Compose 是将多个transform组合起来使用(由transform构成的列表)
transform_train = transforms.Compose([
# transforms.RandomCrop: 切割中心点的位置随机选取
transforms.RandomCrop(32, padding=4),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
# transforms.Normalize: 给定均值:(R,G,B) 方差:(R,G,B),将会把Tensor正则化
transforms.Normalize((0.4914, 0.4822, 0.4465), (0.2023, 0.1994, 0.2010)),
])
transform_test = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.4914, 0.4822, 0.4465), (0.2023, 0.1994, 0.2010)),
])
train_dataset = datasets.CIFAR10(dir, train=True, download=True, transform=transform_train)
eval_dataset = datasets.CIFAR10(dir, train=False, transform=transform_test)
return train_dataset, eval_dataset3.编写服务器端代码
在项目文件夹下创建server.py文件,服务器端的主要功能就是将模型聚合,评估,分发,包括构造函数、聚合函数(使用FedAvg算法)、评估函数。
import models
import torch
# 服务器类
class Server(object):
# 定义构造函数
def __init__(self, conf, eval_dataset):
# 导入配置文件
self.conf = conf
# 根据配置文件获取模型
self.global_model = models.get_model(self.conf["model_name"])
# 生成测试集合加载器
self.eval_loader = torch.utils.data.DataLoader(
eval_dataset,
# 根据配置文件设置单个批次大小(32)
batch_size=self.conf["batch_size"],
# 打乱数据集
shuffle=True
)
# 模型聚合函数
# weight_accumulator 存储了每个客户端上传参数的变化值
def model_aggregate(self, weight_accumulator):
# 遍历服务器的全局模型
for name, data in self.global_model.state_dict().items():
# 更新每一次乘以配置文件中的学习率
update_per_layer = weight_accumulator[name] * self.conf["lambda"]
# 累加
if data.type() != update_per_layer.type():
# 因为update_per_layer的type是floatTensor,所以将其转换为模型的LongTensor(损失精度)
data.add_(update_per_layer.to(torch.int64))
else:
data.add_(update_per_layer)
# 模型评估函数
def model_eval(self):
# 开启模型评估模式
self.global_model.eval()
total_loss = 0.0
correct = 0
dataset_size = 0
# 遍历评估数据集合
for batch_id, batch in enumerate(self.eval_loader):
data, target = batch
# 获取所有样本总量大小
dataset_size += data.size()[0]
# 如果可以的话存储到gpu
if torch.cuda.is_available():
data = data.cuda()
target = target.cuda()
# 加载到模型中训练
output = self.global_model(data)
# 聚合所有损失 cross_entropy 交叉熵函数计算损失
total_loss += torch.nn.functional.cross_entropy(
output,
target,
reduction='sum'
).item()
# 获取最大的对数概率的索引值,即在所有预测结果中选择可能性最大的作为最终结果
pred = output.data.max(1)[1]
# 统计预测结果与真实标签的匹配个数
correct += pred.eq(target.data.view_as(pred)).cpu().sum().item()
# 计算准确率
acc = 100.0 * (float(correct) / float(dataset_size))
# 计算损失值
total_l = total_loss / dataset_size
return acc, total_l4.编写客户端代码
在项目文件夹下创建client.py文件,客户端的主要功能是接受服务器传来的全局模型,并利用本地数据对模型进行训练后返回差值,包括构造函数、本地训练函数。
import models
import torch
# 客户端类
class Client(object):
#构造函数
def __init__(self, conf, model, train_dataset, id=-1):
# 读取配置文件
self.conf = conf
# 根据配置文件获取客户端本地模型(一般由服务器传输)
self.local_model = models.get_model(self.conf["model_name"])
# 客户端ID
self.client_id = id
# 客户端本地数据集
self.train_dataset = train_dataset
# 按ID对数据集集合进行拆分
all_range = list(range(len(self.train_dataset)))
data_len = int(len(self.train_dataset) / self.conf['no_models'])
train_indices = all_range[id * data_len: (id + 1) * data_len]
# 生成数据加载器
self.train_loader = torch.utils.data.DataLoader(
# 指定父集合
self.train_dataset,
# 每个batch加载多少样本
batch_size=conf["batch_size"],
# 指定子集合
# sampler定义从数据集中提取样本的策略
sampler=torch.utils.data.sampler.SubsetRandomSampler(train_indices)
)
# 模型本地训练函数
def local_train(self, model):
# 客户端获取服务器的模型,然后通过部分本地数据集进行训练
for name, param in model.state_dict().items():
# 用服务器下发的全局模型覆盖本地模型
self.local_model.state_dict()[name].copy_(param.clone())
# 定义最优化函数器用户本地模型训练
optimizer = torch.optim.SGD(
self.local_model.parameters(),
lr=self.conf['lr'],
momentum=self.conf['momentum']
)
# 本地训练模型
# 设置开启模型训练
self.local_model.train()
# 开始训练模型
for e in range(self.conf["local_epochs"]):
for batch_id, batch in enumerate(self.train_loader):
data, target = batch
# 如果可以的话加载到gpu
if torch.cuda.is_available():
data = data.cuda()
target = target.cuda()
# 梯度初始化为0
optimizer.zero_grad()
# 训练预测
output = self.local_model(data)
# 计算损失函数cross_entropy交叉熵误差
loss = torch.nn.functional.cross_entropy(output, target)
# 反向传播
loss.backward()
# 更新参数
optimizer.step()
print("Epoch %d done." % e)
# 创建差值字典(结构与模型参数同规格),用于记录差值
diff = dict()
for name, data in self.local_model.state_dict().items():
# 计算训练后与训练前的差值
diff[name] = (data - model.state_dict()[name])
print("Client %d local train done" % self.client_id)
# 客户端返回差值
return diff
5.编写main函数
在项目文件夹下创建main.py文件,用来将代码整合起来。
import argparse
import json
import random
import datasets
from client import *
from server import *
if __name__ == '__main__':
# 设置命令行程序
parser = argparse.ArgumentParser(description='Federated Learning')
parser.add_argument('-c', '--conf', dest='conf')
# 获取所有参数
args = parser.parse_args()
# 读取配置文件,指定编码格式为utf-8
with open(args.conf, 'r', encoding='utf-8') as f:
conf = json.load(f)
# 获取数据集,加载描述信息
train_datasets, eval_datasets = datasets.get_dataset("./data/", conf["type"])
# 启动服务器
server = Server(conf, eval_datasets)
# 定义客户端列表
clients = []
# 创建10个客户端到列表中
for c in range(conf["no_models"]):
clients.append(Client(conf, server.global_model, train_datasets, c))
print("\n\n")
# 全局模型训练
for e in range(conf["global_epochs"]):
print("Global Epoch %d" % e)
# 每次训练从clients列表中随机抽取k个进行训练
candidates = random.sample(clients, conf["k"])
print("select clients is: ")
for c in candidates:
print(c.client_id)
# 累计权重
weight_accumulator = {}
# 初始化空模型参数weight_accumulator
for name, params in server.global_model.state_dict().items():
# 生成一个和参数矩阵大小相同的0矩阵
weight_accumulator[name] = torch.zeros_like(params)
# 遍历选中的客户端,每个客户端本地进行训练
for c in candidates:
diff = c.local_train(server.global_model)
# 根据客户端返回的参数差值字典更新总体权重
for name, params in server.global_model.state_dict().items():
weight_accumulator[name].add_(diff[name])
# 模型参数聚合
server.model_aggregate(weight_accumulator)
# 模型评估
acc, loss = server.model_eval()
print("Epoch %d, acc: %f, loss: %f\n" % (e, acc, loss))6.编写模型文件
在项目文件夹下创建models.py文件,用来定义各种机器学习模型供使用。
import torch
from torchvision import models
# 各种机器学习模型
def get_model(name="vgg16", pretrained=True):
if name == "resnet18":
model = models.resnet18(pretrained=pretrained)
elif name == "resnet50":
model = models.resnet50(pretrained=pretrained)
elif name == "densenet121":
model = models.densenet121(pretrained=pretrained)
elif name == "alexnet":
model = models.alexnet(pretrained=pretrained)
elif name == "vgg16":
model = models.vgg16(pretrained=pretrained)
elif name == "vgg19":
model = models.vgg19(pretrained=pretrained)
elif name == "inception_v3":
model = models.inception_v3(pretrained=pretrained)
elif name == "googlenet":
model = models.googlenet(pretrained=pretrained)
if torch.cuda.is_available():
return model.cuda()
else:
return model四、测试
整个项目结构:
转到项目目录并使用命令行运行以下命令:
python main.py -c ./utils/conf.json首先会进行数据集的下载,在项目目录下会出现data文件夹,里面会有要用到的数据集,然后就会随机挑选客户端进行训练,进行完指定轮数的训练后就会停止。
五、联邦学习与集中训练的效果对比
联邦训练:一共10台客户端设备,每轮挑选5台参与训练,每次本地训练迭代3次,全局迭代次数20次。
集中式训练:将客户端设备数改为1,每轮挑选1台进行训练,通过修改配置就可以完成集中式训练的效果。
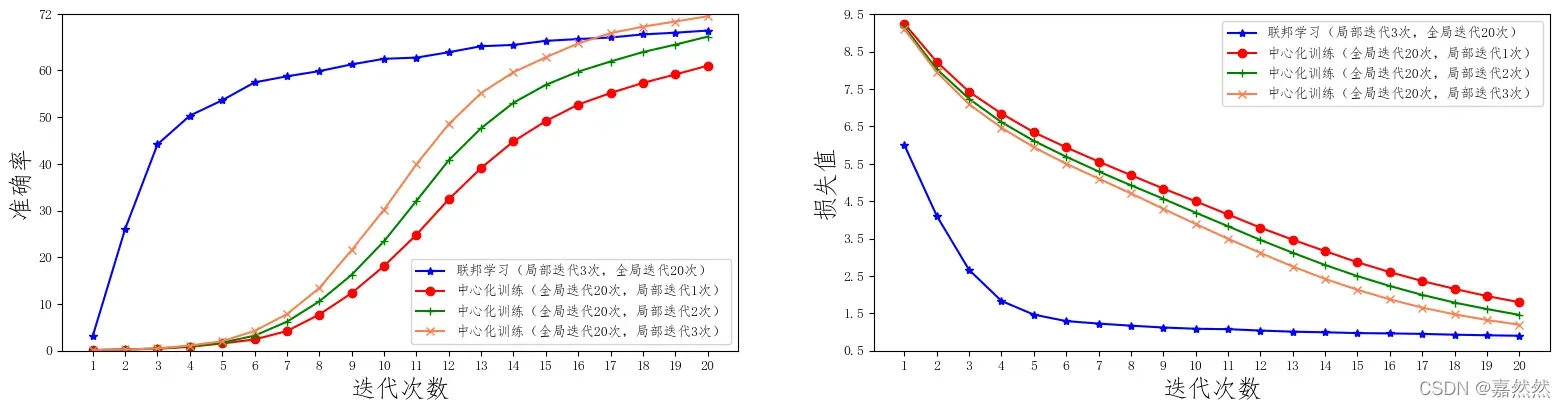
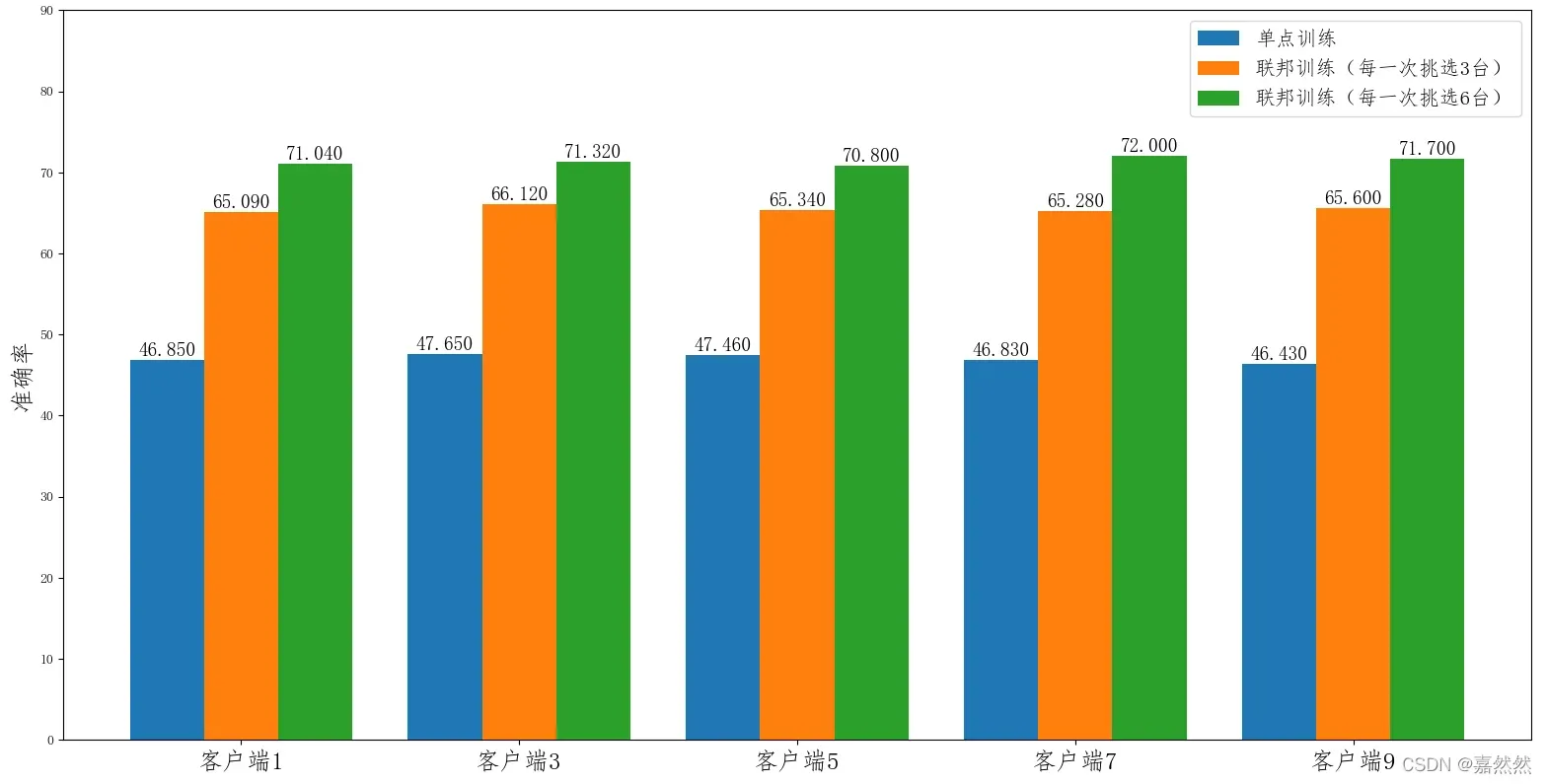
图中的单点训练只是在某个客户端下使用本地数据进行模型训练的结果。
- 我们看到单点训练的模型效果(蓝条)明显低于联邦训练的效果(绿条和红条),这也说明仅仅通过单个客户端的数据,数据不能很好学到了。由于全局分布的特点,模型的泛化能力较差。
- 此外,对于每一轮 参与联邦训练的客户端数目(k 值)不同,其性能也会有一定的差别,k 值越大,每一轮参与训练的客户端数目越多,其性能也会越好,但每一轮的完成时间也会相对较长。
6.总结
目前联邦学习的应用已经非常广泛了,各个大企业也都开发了自己的联邦学习框架,例如微众银行的FATE、谷歌的TensorFlow、OpenMind的PySyft、百度的PaddleFL、字节的FedLearner等,都是很好的框架,本文只在本地模拟了客户端和服务器进行训练,要在多台机器上进行训练还需进行学习。
文章出处登录后可见!