Googlenet是2014年被提出来的一种全新的神经网络结构,我个人认为他跟Resnet一样都是具有划时代意义的神经网络,当然他的意义不仅在于获得该年 ImageNet 竞赛中 Classification Task(分类任务)第一名,而是他跟Resnet一样都代表一种网络结构的改变,Resnet提出来残差网络结构,Googlenet提出了多尺度融合的网络结构,这种结构非常有意义。在目标检测领域应用非常广泛,目标检测的特征金字塔特征融合的方法和网络结构正是借鉴了googlenet的思想。因此学好googlenet对于后续学习yolo系列等目标检测网络具有重大意义。
下图是最开始的googlenet网络结构,可以看到它将一个输入分成多个分支进行不同的处理,然后最近再将不同的处理结果进行拼接,组成最后的输出结构。
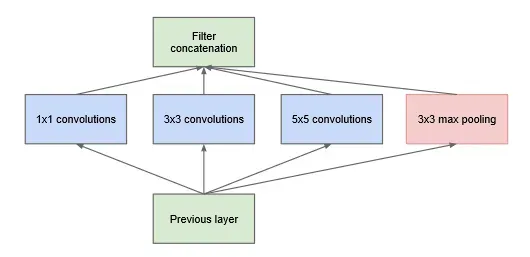
这是之后的googlenet网络结构,加入1*1的卷积结构用于降低模型的参数数量(事实上这个trick在很多经典CNN模型中都有用,属于很常见的trick)
googlenet的另一大创新点在于创造了多分类器,除了原来的主分类器之外,还增加了两个辅助分类器,这点有点类似模型融合,不过模型融合是参与模型的最终决策的,但是他的两个辅助分类器并不参与最终决策,只是在训练总损失的时候,总损失 = 主分类器的损失 + 0.3*辅助分类器1 + 0.3*辅助分类器2 识别过程中并不参与,只取主分类器的结果,而且求解验证集损失的时候也不取辅助分类器的结果,因为验证过程中模型时关闭辅助分类器的。光说有点难受,咱们来看图
论文中的数字:
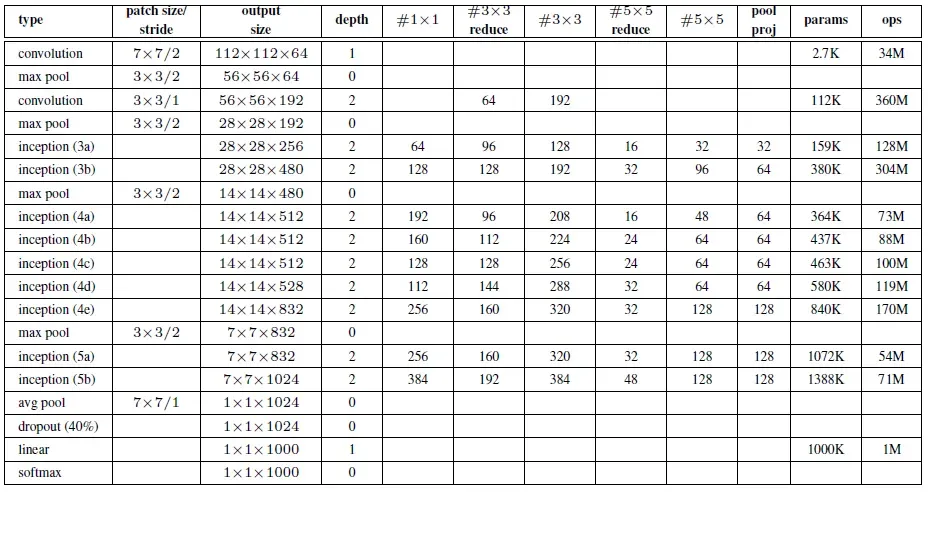
网络结构图:
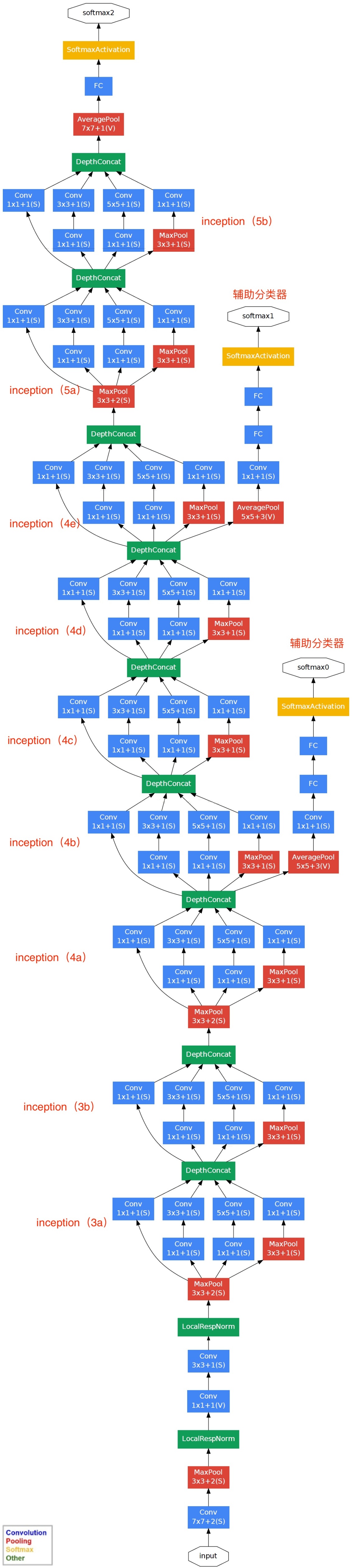
接下来我们看代码:
导入所需的库:
import torch
import torchvision
import torchvision.models
import torch.nn.functional as F
from matplotlib import pyplot as plt
from tqdm import tqdm
from torch import nn
from torch.utils.data import DataLoader
from torchvision.transforms import transforms
图像预处理: 将所有图像缩放成224*224进行处理
data_transform = {
"train": transforms.Compose([transforms.RandomResizedCrop(224), #图像预处理操作
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))]),
"val": transforms.Compose([transforms.Resize((224, 224)), # cannot 224, must (224, 224)
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])}
训练集数据和测试集数据的导入:
将数据像挤牙膏似的一点一点的抽出去,设置相应的batc_size
自己的数据放在跟代码相同的文件夹下新建一个data文件夹,data文件夹里的新建一个train文件夹用于放置训练集的图片。同理新建一个val文件夹用于放置测试集的图片。
train_data = torchvision.datasets.ImageFolder(root = "./data/train" , transform = data_transform["train"]) #训练集
traindata = DataLoader(dataset= train_data , batch_size= 32 , shuffle= True , num_workers=0 ) # 将训练数据以每次32张图片的形式抽出进行训练
test_data = torchvision.datasets.ImageFolder(root = "./data/val" , transform = data_transform["val"]) # 将训练数据以每次32张图片的形式抽出进行测试
train_size = len(train_data) # 训练集的长度
test_size = len(test_data) # 测试集的长度
print(train_size) # 输出训练集长度看一下,相当于看看有几张图片
print(test_size) # 输出测试集长度看一下,相当于看看有几张图片
testdata = DataLoader(dataset = test_data , batch_size= 32 , shuffle= True , num_workers=0 )设置GPU 和 CPU的使用:
有GPU则调用GPU,没有的话就调用CPU
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
print("using {} device.".format(device))构建Googlenet网络:
class GoogLeNet(nn.Module):
def __init__(self, num_classes=1000, aux_logits=True, init_weights=False): #这是主分类器 aux_logits是true则启动使用辅助分类器,否则不启动
super(GoogLeNet, self).__init__()
self.aux_logits = aux_logits
self.conv1 = BasicConv2d(3, 64, kernel_size=7, stride=2, padding=3)
self.maxpool1 = nn.MaxPool2d(3, stride=2, ceil_mode=True)
self.conv2 = BasicConv2d(64, 64, kernel_size=1)
self.conv3 = BasicConv2d(64, 192, kernel_size=3, padding=1)
self.maxpool2 = nn.MaxPool2d(3, stride=2, ceil_mode=True)
self.inception3a = Inception(192, 64, 96, 128, 16, 32, 32)
self.inception3b = Inception(256, 128, 128, 192, 32, 96, 64)
self.maxpool3 = nn.MaxPool2d(3, stride=2, ceil_mode=True)
self.inception4a = Inception(480, 192, 96, 208, 16, 48, 64)
self.inception4b = Inception(512, 160, 112, 224, 24, 64, 64)
self.inception4c = Inception(512, 128, 128, 256, 24, 64, 64)
self.inception4d = Inception(512, 112, 144, 288, 32, 64, 64)
self.inception4e = Inception(528, 256, 160, 320, 32, 128, 128)
self.maxpool4 = nn.MaxPool2d(3, stride=2, ceil_mode=True)
self.inception5a = Inception(832, 256, 160, 320, 32, 128, 128)
self.inception5b = Inception(832, 384, 192, 384, 48, 128, 128)
if self.aux_logits: #是否启用辅助分类器
self.aux1 = InceptionAux(512, num_classes)
self.aux2 = InceptionAux(528, num_classes)
self.avgpool = nn.AdaptiveAvgPool2d((1, 1))
self.dropout = nn.Dropout(0.4)
self.fc = nn.Linear(1024, num_classes)
if init_weights: #是否使用初始化权重
self._initialize_weights()
def forward(self, x):
# N x 3 x 224 x 224
x = self.conv1(x)
# N x 64 x 112 x 112
x = self.maxpool1(x)
# N x 64 x 56 x 56
x = self.conv2(x)
# N x 64 x 56 x 56
x = self.conv3(x)
# N x 192 x 56 x 56
x = self.maxpool2(x)
# N x 192 x 28 x 28
x = self.inception3a(x)
# N x 256 x 28 x 28
x = self.inception3b(x)
# N x 480 x 28 x 28
x = self.maxpool3(x)
# N x 480 x 14 x 14
x = self.inception4a(x)
# N x 512 x 14 x 14
if self.training and self.aux_logits: # eval model lose this layer 如果为训练模型则使用辅助分类器,验证模型则关闭辅助分类器
aux1 = self.aux1(x)
x = self.inception4b(x)
# N x 512 x 14 x 14
x = self.inception4c(x)
# N x 512 x 14 x 14
x = self.inception4d(x)
# N x 528 x 14 x 14
if self.training and self.aux_logits: # eval model lose this layer# eval model lose this layer 如果为训练模型则使用辅助分类器,验证模型则关闭辅助分类器
aux2 = self.aux2(x)
x = self.inception4e(x)
# N x 832 x 14 x 14
x = self.maxpool4(x)
# N x 832 x 7 x 7
x = self.inception5a(x)
# N x 832 x 7 x 7
x = self.inception5b(x)
# N x 1024 x 7 x 7
x = self.avgpool(x)
# N x 1024 x 1 x 1
x = torch.flatten(x, 1)
# N x 1024
x = self.dropout(x)
x = self.fc(x)
# N x 1000 (num_classes)
if self.training and self.aux_logits: # eval model lose this layer# eval model lose this layer 如果为训练模型则使用辅助分类器,验证模型则关闭辅助分类器
return x, aux2, aux1
return x
def _initialize_weights(self):#初始化权重的提房,有兴趣可以查查函数看看
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')
if m.bias is not None:
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.Linear):
nn.init.normal_(m.weight, 0, 0.01)
nn.init.constant_(m.bias, 0)
class Inception(nn.Module): #搭建多分支架构的一部分
def __init__(self, in_channels, ch1x1, ch3x3red, ch3x3, ch5x5red, ch5x5,
pool_proj): # self.inception3a = Inception(192, 64, 96, 128, 16, 32, 32)
super(Inception, self).__init__()
self.branch1 = BasicConv2d(in_channels, ch1x1, kernel_size=1)
self.branch2 = nn.Sequential(
BasicConv2d(in_channels, ch3x3red, kernel_size=1),
BasicConv2d(ch3x3red, ch3x3, kernel_size=3, padding=1) # 保证输出大小等于输入大小
)
self.branch3 = nn.Sequential(
BasicConv2d(in_channels, ch5x5red, kernel_size=1),
BasicConv2d(ch5x5red, ch5x5, kernel_size=5, padding=2) # 保证输出大小等于输入大小
)
self.branch4 = nn.Sequential(
nn.MaxPool2d(kernel_size=3, stride=1, padding=1),
BasicConv2d(in_channels, pool_proj, kernel_size=1)
)
def forward(self, x):
branch1 = self.branch1(x)
branch2 = self.branch2(x)
branch3 = self.branch3(x)
branch4 = self.branch4(x)
outputs = [branch1, branch2, branch3, branch4]
return torch.cat(outputs, 1)
class InceptionAux(nn.Module): #辅助分类器结构
def __init__(self, in_channels, num_classes):
super(InceptionAux, self).__init__()
self.averagePool = nn.AvgPool2d(kernel_size=5, stride=3)
self.conv = BasicConv2d(in_channels, 128, kernel_size=1) # output[batch, 128, 4, 4]
self.fc1 = nn.Linear(2048, 1024)
self.fc2 = nn.Linear(1024, num_classes)
def forward(self, x):
# aux1: N x 512 x 14 x 14, aux2: N x 528 x 14 x 14
x = self.averagePool(x)
# aux1: N x 512 x 4 x 4, aux2: N x 528 x 4 x 4
x = self.conv(x)
# N x 128 x 4 x 4
x = torch.flatten(x, 1)
x = F.dropout(x, 0.5, training=self.training)
# N x 2048
x = F.relu(self.fc1(x), inplace=True)
x = F.dropout(x, 0.5, training=self.training)
# N x 1024
x = self.fc2(x)
# N x num_classes
return x
class BasicConv2d(nn.Module):
def __init__(self, in_channels, out_channels, **kwargs):
super(BasicConv2d, self).__init__()
self.conv = nn.Conv2d(in_channels, out_channels, **kwargs)
self.relu = nn.ReLU(inplace=True)
def forward(self, x):
x = self.conv(x)
x = self.relu(x)
return x启动模型并测试模型输出:
googlenet = GoogLeNet(num_classes=7, aux_logits=True, init_weights=True) #启动模型,这里的7就改成自己的数据集的种类即可,几种就改成几
print(googlenet) #打印出模型结构看看
googlenet.to(device) #将模型放到GPU上
test1 = torch.ones(64, 3, 224, 224) #输出一个测试数据看看模型的数据是几种的,是不是我们需要的种类
test1_1 , test_2 , test_3 = googlenet(test1.to(device))#会输出三个分类器的结果,我们查看主分类器的输出最后是不是我们的种类数
print(test1_1.shape)
设置训练需要的参数,epoch,学习率learning 优化器。损失函数。
epoch = 10 # 迭代次数即训练次数
learning = 0.001 # 学习率
optimizer = torch.optim.Adam(net.parameters(), lr=learning) # 使用Adam优化器-写论文的话可以具体查一下这个优化器的原理
loss = nn.CrossEntropyLoss() # 损失计算方式,交叉熵损失函数设置四个空数组,用来存放训练集的loss和accuracy 测试集的loss和 accuracy
train_loss_all = [] # 存放训练集损失的数组
train_accur_all = [] # 存放训练集准确率的数组
test_loss_all = [] # 存放测试集损失的数组
test_accur_all = [] # 存放测试集准确率的数组开始训练:
for i in range(epoch): #开始迭代
train_loss = 0 #训练集的损失初始设为0
train_num = 0.0
train_accuracy = 0.0 #训练集的准确率初始设为0
googlenet.train() #将模型设置成 训练模式,这里意味着启动辅助分类器
train_bar = tqdm(traindata) #用于进度条显示,没啥实际用处
for step , data in enumerate(train_bar): #开始迭代跑, enumerate这个函数不懂可以查查,将训练集分为 data是序号,data是数据
img , target = data #将data 分为 img图片,target标签
optimizer.zero_grad() # 清空历史梯度
outputs_1 = googlenet(img.to(device)) # 将图片打入网络进行训练,outputs是输出的结果
outputs , outputs1 , outputs2 = outputs_1 #因为googlenet有两个辅助分类器,所以会有三个分类结果
loss1 = loss(outputs , target.to(device)) #第一个为主分类器的损失
loss1_1 = loss(outputs1 , target.to(device)) #第二个是辅助分类器1的损失
loss1_2 = loss(outputs2 , target.to(device)) #第三个是辅助分类器2的损失
loss1_fin = loss1 + loss1_1 * 0.3 + loss1_2 * 0.3 #计算总损失
outputs = torch.argmax(outputs, 1) #计算准确率的时候 只是用主分类器的结果,辅助分类器只用来反向传播,防止梯度消失重点,牢记
loss1_fin.backward() #神经网络反向传播
optimizer.step() #梯度优化 用上面的abam优化
train_loss += abs(loss1_fin.item())*img.size(0) #将所有损失的绝对值加起来
accuracy = torch.sum(outputs == target.to(device)) #outputs == target的 即使预测正确的,统计预测正确的个数,从而计算准确率
train_accuracy = train_accuracy + accuracy #求训练集的准确率
train_num += img.size(0)
print("epoch:{} , train-Loss:{} , train-accuracy:{}".format(i+1 , train_loss/train_num , train_accuracy/train_num)) #输出训练情况
train_loss_all.append(train_loss/train_num) #将训练的损失放到一个列表里 方便后续画图
train_accur_all.append(train_accuracy.double().item()/train_num) #训练集的准确率开始测试:
test_loss = 0 #同上 测试损失
test_accuracy = 0.0 #测试准确率
test_num = 0
googlenet.eval() #测试模式启动,关闭辅助分类器
with torch.no_grad(): #清空历史梯度,进行测试 与训练最大的区别是测试过程中取消了反向传播
test_bar = tqdm(testdata)
for data in test_bar:
img , target = data
outputs_1 = googlenet(img.to(device)) #这个时候模型只有一个输出结果,因为关闭了辅助分类器
loss2 = loss(outputs_1, target.to(device))
outputs_1 = torch.argmax(outputs_1 , 1)
test_loss = test_loss + abs(loss2.item())*img.size(0)
accuracy = torch.sum(outputs_1 == target.to(device))
test_accuracy = test_accuracy + accuracy
test_num += img.size(0)
print("test-Loss:{} , test-accuracy:{}".format(test_loss / test_num, test_accuracy / test_num))
test_loss_all.append(test_loss/test_num)
test_accur_all.append(test_accuracy.double().item()/test_num)
绘制训练集loss和accuracy图 和测试集的loss和accuracy图:
plt.figure(figsize=(12,4))
plt.subplot(1 , 2 , 1)
plt.plot(range(epoch) , train_loss_all,
"ro-",label = "Train loss")
plt.plot(range(epoch), test_loss_all,
"bs-",label = "test loss")
plt.legend()
plt.xlabel("epoch")
plt.ylabel("Loss")
plt.subplot(1, 2, 2)
plt.plot(range(epoch) , train_accur_all,
"ro-",label = "Train accur")
plt.plot(range(epoch) , test_accur_all,
"bs-",label = "test accur")
plt.xlabel("epoch")
plt.ylabel("acc")
plt.legend()
plt.show()
torch.save(googlenet.state_dict(), "googlenet.pth") #保存模型
print("模型已保存")
全部train训练代码:
import torch
import torchvision
import torchvision.models
import torch.nn.functional as F
from matplotlib import pyplot as plt
from tqdm import tqdm
from torch import nn
from torch.utils.data import DataLoader
from torchvision.transforms import transforms
data_transform = {
"train": transforms.Compose([transforms.RandomResizedCrop(224), #图像预处理操作
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))]),
"val": transforms.Compose([transforms.Resize((224, 224)), # cannot 224, must (224, 224)
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])}
def main():
train_data = torchvision.datasets.ImageFolder(root = "./data/train" , transform = data_transform["train"]) #训练集
traindata = DataLoader(dataset= train_data , batch_size= 32 , shuffle= True , num_workers=0 ) # 将训练数据以每次32张图片的形式抽出进行训练
test_data = torchvision.datasets.ImageFolder(root = "./data/val" , transform = data_transform["val"]) # 将训练数据以每次32张图片的形式抽出进行测试
train_size = len(train_data) # 训练集的长度
test_size = len(test_data) # 测试集的长度
print(train_size) # 输出训练集长度看一下,相当于看看有几张图片
print(test_size) # 输出测试集长度看一下,相当于看看有几张图片
testdata = DataLoader(dataset = test_data , batch_size= 32 , shuffle= True , num_workers=0 )
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
print("using {} device.".format(device))
class GoogLeNet(nn.Module):
def __init__(self, num_classes=1000, aux_logits=True, init_weights=False): #这是主分类器 aux_logits是true则启动使用辅助分类器,否则不启动
super(GoogLeNet, self).__init__()
self.aux_logits = aux_logits
self.conv1 = BasicConv2d(3, 64, kernel_size=7, stride=2, padding=3)
self.maxpool1 = nn.MaxPool2d(3, stride=2, ceil_mode=True)
self.conv2 = BasicConv2d(64, 64, kernel_size=1)
self.conv3 = BasicConv2d(64, 192, kernel_size=3, padding=1)
self.maxpool2 = nn.MaxPool2d(3, stride=2, ceil_mode=True)
self.inception3a = Inception(192, 64, 96, 128, 16, 32, 32)
self.inception3b = Inception(256, 128, 128, 192, 32, 96, 64)
self.maxpool3 = nn.MaxPool2d(3, stride=2, ceil_mode=True)
self.inception4a = Inception(480, 192, 96, 208, 16, 48, 64)
self.inception4b = Inception(512, 160, 112, 224, 24, 64, 64)
self.inception4c = Inception(512, 128, 128, 256, 24, 64, 64)
self.inception4d = Inception(512, 112, 144, 288, 32, 64, 64)
self.inception4e = Inception(528, 256, 160, 320, 32, 128, 128)
self.maxpool4 = nn.MaxPool2d(3, stride=2, ceil_mode=True)
self.inception5a = Inception(832, 256, 160, 320, 32, 128, 128)
self.inception5b = Inception(832, 384, 192, 384, 48, 128, 128)
if self.aux_logits: #是否启用辅助分类器
self.aux1 = InceptionAux(512, num_classes)
self.aux2 = InceptionAux(528, num_classes)
self.avgpool = nn.AdaptiveAvgPool2d((1, 1))
self.dropout = nn.Dropout(0.4)
self.fc = nn.Linear(1024, num_classes)
if init_weights: #是否使用初始化权重
self._initialize_weights()
def forward(self, x):
# N x 3 x 224 x 224
x = self.conv1(x)
# N x 64 x 112 x 112
x = self.maxpool1(x)
# N x 64 x 56 x 56
x = self.conv2(x)
# N x 64 x 56 x 56
x = self.conv3(x)
# N x 192 x 56 x 56
x = self.maxpool2(x)
# N x 192 x 28 x 28
x = self.inception3a(x)
# N x 256 x 28 x 28
x = self.inception3b(x)
# N x 480 x 28 x 28
x = self.maxpool3(x)
# N x 480 x 14 x 14
x = self.inception4a(x)
# N x 512 x 14 x 14
if self.training and self.aux_logits: # eval model lose this layer 如果为训练模型则使用辅助分类器,验证模型则关闭辅助分类器
aux1 = self.aux1(x)
x = self.inception4b(x)
# N x 512 x 14 x 14
x = self.inception4c(x)
# N x 512 x 14 x 14
x = self.inception4d(x)
# N x 528 x 14 x 14
if self.training and self.aux_logits: # eval model lose this layer# eval model lose this layer 如果为训练模型则使用辅助分类器,验证模型则关闭辅助分类器
aux2 = self.aux2(x)
x = self.inception4e(x)
# N x 832 x 14 x 14
x = self.maxpool4(x)
# N x 832 x 7 x 7
x = self.inception5a(x)
# N x 832 x 7 x 7
x = self.inception5b(x)
# N x 1024 x 7 x 7
x = self.avgpool(x)
# N x 1024 x 1 x 1
x = torch.flatten(x, 1)
# N x 1024
x = self.dropout(x)
x = self.fc(x)
# N x 1000 (num_classes)
if self.training and self.aux_logits: # eval model lose this layer# eval model lose this layer 如果为训练模型则使用辅助分类器,验证模型则关闭辅助分类器
return x, aux2, aux1
return x
def _initialize_weights(self):#初始化权重的提房,有兴趣可以查查函数看看
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')
if m.bias is not None:
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.Linear):
nn.init.normal_(m.weight, 0, 0.01)
nn.init.constant_(m.bias, 0)
class Inception(nn.Module): #搭建多分支架构的一部分
def __init__(self, in_channels, ch1x1, ch3x3red, ch3x3, ch5x5red, ch5x5,
pool_proj): # self.inception3a = Inception(192, 64, 96, 128, 16, 32, 32)
super(Inception, self).__init__()
self.branch1 = BasicConv2d(in_channels, ch1x1, kernel_size=1)
self.branch2 = nn.Sequential(
BasicConv2d(in_channels, ch3x3red, kernel_size=1),
BasicConv2d(ch3x3red, ch3x3, kernel_size=3, padding=1) # 保证输出大小等于输入大小
)
self.branch3 = nn.Sequential(
BasicConv2d(in_channels, ch5x5red, kernel_size=1),
BasicConv2d(ch5x5red, ch5x5, kernel_size=5, padding=2) # 保证输出大小等于输入大小
)
self.branch4 = nn.Sequential(
nn.MaxPool2d(kernel_size=3, stride=1, padding=1),
BasicConv2d(in_channels, pool_proj, kernel_size=1)
)
def forward(self, x):
branch1 = self.branch1(x)
branch2 = self.branch2(x)
branch3 = self.branch3(x)
branch4 = self.branch4(x)
outputs = [branch1, branch2, branch3, branch4]
return torch.cat(outputs, 1)
class InceptionAux(nn.Module): #辅助分类器结构
def __init__(self, in_channels, num_classes):
super(InceptionAux, self).__init__()
self.averagePool = nn.AvgPool2d(kernel_size=5, stride=3)
self.conv = BasicConv2d(in_channels, 128, kernel_size=1) # output[batch, 128, 4, 4]
self.fc1 = nn.Linear(2048, 1024)
self.fc2 = nn.Linear(1024, num_classes)
def forward(self, x):
# aux1: N x 512 x 14 x 14, aux2: N x 528 x 14 x 14
x = self.averagePool(x)
# aux1: N x 512 x 4 x 4, aux2: N x 528 x 4 x 4
x = self.conv(x)
# N x 128 x 4 x 4
x = torch.flatten(x, 1)
x = F.dropout(x, 0.5, training=self.training)
# N x 2048
x = F.relu(self.fc1(x), inplace=True)
x = F.dropout(x, 0.5, training=self.training)
# N x 1024
x = self.fc2(x)
# N x num_classes
return x
class BasicConv2d(nn.Module):
def __init__(self, in_channels, out_channels, **kwargs):
super(BasicConv2d, self).__init__()
self.conv = nn.Conv2d(in_channels, out_channels, **kwargs)
self.relu = nn.ReLU(inplace=True)
def forward(self, x):
x = self.conv(x)
x = self.relu(x)
return x
googlenet = GoogLeNet(num_classes=7, aux_logits=True, init_weights=True) #启动模型,这里的7就改成自己的数据集的种类即可,几种就改成几
print(googlenet) #打印出模型结构看看
googlenet.to(device) #将模型放到GPU上
test1 = torch.ones(64, 3, 224, 224) #输出一个测试数据看看模型的数据是几种的,是不是我们需要的种类
test1_1 , test_2 , test_3 = googlenet(test1.to(device))#会输出三个分类器的结果,我们查看主分类器的输出最后是不是我们的种类数
print(test1_1.shape)
epoch = 5 #训练额轮数
learning = 0.001 #学习率
optimizer = torch.optim.Adam(googlenet.parameters(), lr = learning) #优化梯度下降器
loss = nn.CrossEntropyLoss() #设置损失函数,这里为交叉熵
train_loss_all = [] # 存放训练集损失的数组
train_accur_all = [] # 存放训练集准确率的数组
test_loss_all = [] # 存放测试集损失的数组
test_accur_all = [] # 存放测试集准确率的数组
for i in range(epoch): #开始迭代
train_loss = 0 #训练集的损失初始设为0
train_num = 0.0
train_accuracy = 0.0 #训练集的准确率初始设为0
googlenet.train() #将模型设置成 训练模式,这里意味着启动辅助分类器
train_bar = tqdm(traindata) #用于进度条显示,没啥实际用处
for step , data in enumerate(train_bar): #开始迭代跑, enumerate这个函数不懂可以查查,将训练集分为 data是序号,data是数据
img , target = data #将data 分为 img图片,target标签
optimizer.zero_grad() # 清空历史梯度
outputs_1 = googlenet(img.to(device)) # 将图片打入网络进行训练,outputs是输出的结果
outputs , outputs1 , outputs2 = outputs_1 #因为googlenet有两个辅助分类器,所以会有三个分类结果
loss1 = loss(outputs , target.to(device)) #第一个为主分类器的损失
loss1_1 = loss(outputs1 , target.to(device)) #第二个是辅助分类器1的损失
loss1_2 = loss(outputs2 , target.to(device)) #第三个是辅助分类器2的损失
loss1_fin = loss1 + loss1_1 * 0.3 + loss1_2 * 0.3 #计算总损失
outputs = torch.argmax(outputs, 1) #计算准确率的时候 只是用主分类器的结果,辅助分类器只用来反向传播,防止梯度消失重点,牢记
loss1_fin.backward() #神经网络反向传播
optimizer.step() #梯度优化 用上面的abam优化
train_loss += abs(loss1_fin.item())*img.size(0) #将所有损失的绝对值加起来
accuracy = torch.sum(outputs == target.to(device)) #outputs == target的 即使预测正确的,统计预测正确的个数,从而计算准确率
train_accuracy = train_accuracy + accuracy #求训练集的准确率
train_num += img.size(0)
print("epoch:{} , train-Loss:{} , train-accuracy:{}".format(i+1 , train_loss/train_num , train_accuracy/train_num)) #输出训练情况
train_loss_all.append(train_loss/train_num) #将训练的损失放到一个列表里 方便后续画图
train_accur_all.append(train_accuracy.double().item()/train_num) #训练集的准确率
test_loss = 0 #同上 测试损失
test_accuracy = 0.0 #测试准确率
test_num = 0
googlenet.eval() #测试模式启动,关闭辅助分类器
with torch.no_grad(): #清空历史梯度,进行测试 与训练最大的区别是测试过程中取消了反向传播
test_bar = tqdm(testdata)
for data in test_bar:
img , target = data
outputs_1 = googlenet(img.to(device)) #这个时候模型只有一个输出结果,因为关闭了辅助分类器
loss2 = loss(outputs_1, target.to(device))
outputs_1 = torch.argmax(outputs_1 , 1)
test_loss = test_loss + abs(loss2.item())*img.size(0)
accuracy = torch.sum(outputs_1 == target.to(device))
test_accuracy = test_accuracy + accuracy
test_num += img.size(0)
print("test-Loss:{} , test-accuracy:{}".format(test_loss / test_num, test_accuracy / test_num))
test_loss_all.append(test_loss/test_num)
test_accur_all.append(test_accuracy.double().item()/test_num)
plt.figure(figsize=(12,4))
plt.subplot(1 , 2 , 1)
plt.plot(range(epoch) , train_loss_all,
"ro-",label = "Train loss")
plt.plot(range(epoch), test_loss_all,
"bs-",label = "test loss")
plt.legend()
plt.xlabel("epoch")
plt.ylabel("Loss")
plt.subplot(1, 2, 2)
plt.plot(range(epoch) , train_accur_all,
"ro-",label = "Train accur")
plt.plot(range(epoch) , test_accur_all,
"bs-",label = "test accur")
plt.xlabel("epoch")
plt.ylabel("acc")
plt.legend()
plt.show()
torch.save(googlenet.state_dict(), "googlenet.pth")
print("模型已保存")
if __name__ == '__main__':
main()
全部predict代码:
import torch
from PIL import Image
from torch import nn
from torchvision.transforms import transforms
import torch.nn.functional as F
image_path = "1.JPG"#需要测试的图片放入当前文件夹下,这里改成自己的图片名即可
trans = transforms.Compose([transforms.Resize((224 , 224)),
transforms.ToTensor()])
image = Image.open(image_path) # 打开图片
image = image.convert("RGB") # 将图片转换为RGB格式
image = trans(image) # 上述的缩放和转张量操作在这里实现
image = torch.unsqueeze(image, dim=0) # 将图片维度扩展一维
classes = ["1" , "2" , "3" , "4" , "5" , "6" , "7"] # # 预测种类,这里改成自己的种类即可,从左到右对应自己的训练集种类排序的从左到右
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
print("using {} device.".format(device))
class GoogLeNet(nn.Module):
def __init__(self, num_classes=1000, aux_logits=True, init_weights=False):
super(GoogLeNet, self).__init__()
self.aux_logits = aux_logits
self.conv1 = BasicConv2d(3, 64, kernel_size=7, stride=2, padding=3)
self.maxpool1 = nn.MaxPool2d(3, stride=2, ceil_mode=True)
self.conv2 = BasicConv2d(64, 64, kernel_size=1)
self.conv3 = BasicConv2d(64, 192, kernel_size=3, padding=1)
self.maxpool2 = nn.MaxPool2d(3, stride=2, ceil_mode=True)
self.inception3a = Inception(192, 64, 96, 128, 16, 32, 32)
self.inception3b = Inception(256, 128, 128, 192, 32, 96, 64)
self.maxpool3 = nn.MaxPool2d(3, stride=2, ceil_mode=True)
self.inception4a = Inception(480, 192, 96, 208, 16, 48, 64)
self.inception4b = Inception(512, 160, 112, 224, 24, 64, 64)
self.inception4c = Inception(512, 128, 128, 256, 24, 64, 64)
self.inception4d = Inception(512, 112, 144, 288, 32, 64, 64)
self.inception4e = Inception(528, 256, 160, 320, 32, 128, 128)
self.maxpool4 = nn.MaxPool2d(3, stride=2, ceil_mode=True)
self.inception5a = Inception(832, 256, 160, 320, 32, 128, 128)
self.inception5b = Inception(832, 384, 192, 384, 48, 128, 128)
if self.aux_logits:
self.aux1 = InceptionAux(512, num_classes)
self.aux2 = InceptionAux(528, num_classes)
self.avgpool = nn.AdaptiveAvgPool2d((1, 1))
self.dropout = nn.Dropout(0.4)
self.fc = nn.Linear(1024, num_classes)
if init_weights:
self._initialize_weights()
def forward(self, x):
# N x 3 x 224 x 224
x = self.conv1(x)
# N x 64 x 112 x 112
x = self.maxpool1(x)
# N x 64 x 56 x 56
x = self.conv2(x)
# N x 64 x 56 x 56
x = self.conv3(x)
# N x 192 x 56 x 56
x = self.maxpool2(x)
# N x 192 x 28 x 28
x = self.inception3a(x)
# N x 256 x 28 x 28
x = self.inception3b(x)
# N x 480 x 28 x 28
x = self.maxpool3(x)
# N x 480 x 14 x 14
x = self.inception4a(x)
# N x 512 x 14 x 14
if self.training and self.aux_logits: # eval model lose this layer
aux1 = self.aux1(x)
x = self.inception4b(x)
# N x 512 x 14 x 14
x = self.inception4c(x)
# N x 512 x 14 x 14
x = self.inception4d(x)
# N x 528 x 14 x 14
if self.training and self.aux_logits: # eval model lose this layer
aux2 = self.aux2(x)
x = self.inception4e(x)
# N x 832 x 14 x 14
x = self.maxpool4(x)
# N x 832 x 7 x 7
x = self.inception5a(x)
# N x 832 x 7 x 7
x = self.inception5b(x)
# N x 1024 x 7 x 7
x = self.avgpool(x)
# N x 1024 x 1 x 1
x = torch.flatten(x, 1)
# N x 1024
x = self.dropout(x)
x = self.fc(x)
# N x 1000 (num_classes)
if self.training and self.aux_logits: # eval model lose this layer
return x, aux2, aux1
return x
def _initialize_weights(self):
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')
if m.bias is not None:
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.Linear):
nn.init.normal_(m.weight, 0, 0.01)
nn.init.constant_(m.bias, 0)
class Inception(nn.Module):
def __init__(self, in_channels, ch1x1, ch3x3red, ch3x3, ch5x5red, ch5x5,
pool_proj): # self.inception3a = Inception(192, 64, 96, 128, 16, 32, 32)
super(Inception, self).__init__()
self.branch1 = BasicConv2d(in_channels, ch1x1, kernel_size=1)
self.branch2 = nn.Sequential(
BasicConv2d(in_channels, ch3x3red, kernel_size=1),
BasicConv2d(ch3x3red, ch3x3, kernel_size=3, padding=1) # 保证输出大小等于输入大小
)
self.branch3 = nn.Sequential(
BasicConv2d(in_channels, ch5x5red, kernel_size=1),
BasicConv2d(ch5x5red, ch5x5, kernel_size=5, padding=2) # 保证输出大小等于输入大小
)
self.branch4 = nn.Sequential(
nn.MaxPool2d(kernel_size=3, stride=1, padding=1),
BasicConv2d(in_channels, pool_proj, kernel_size=1)
)
def forward(self, x):
branch1 = self.branch1(x)
branch2 = self.branch2(x)
branch3 = self.branch3(x)
branch4 = self.branch4(x)
outputs = [branch1, branch2, branch3, branch4]
return torch.cat(outputs, 1)
class InceptionAux(nn.Module):
def __init__(self, in_channels, num_classes):
super(InceptionAux, self).__init__()
self.averagePool = nn.AvgPool2d(kernel_size=5, stride=3)
self.conv = BasicConv2d(in_channels, 128, kernel_size=1) # output[batch, 128, 4, 4]
self.fc1 = nn.Linear(2048, 1024)
self.fc2 = nn.Linear(1024, num_classes)
def forward(self, x):
# aux1: N x 512 x 14 x 14, aux2: N x 528 x 14 x 14
x = self.averagePool(x)
# aux1: N x 512 x 4 x 4, aux2: N x 528 x 4 x 4
x = self.conv(x)
# N x 128 x 4 x 4
x = torch.flatten(x, 1)
x = F.dropout(x, 0.5, training=self.training)
# N x 2048
x = F.relu(self.fc1(x), inplace=True)
x = F.dropout(x, 0.5, training=self.training)
# N x 1024
x = self.fc2(x)
# N x num_classes
return x
class BasicConv2d(nn.Module):
def __init__(self, in_channels, out_channels, **kwargs):
super(BasicConv2d, self).__init__()
self.conv = nn.Conv2d(in_channels, out_channels, **kwargs)
self.relu = nn.ReLU(inplace=True)
def forward(self, x):
x = self.conv(x)
x = self.relu(x)
return x
googlenet = GoogLeNet(num_classes=7, aux_logits=True, init_weights=True)
print(googlenet)
googlenet.to(device)
test1 = torch.ones(64, 3, 224, 224)
test1_1, test_2, test_3 = googlenet(test1.to(device)) # 会输出三个分类器的结果,我们查看主分类器的输出最后是不是我们的种类数
print(test1_1.shape)
googlenet.load_state_dict(torch.load("googlenet.pth", map_location=device))#训练得到的alexnet模型放入当前文件夹下
googlenet.to(device)
googlenet.eval() # 关闭梯度,将模型调整为测试模式
with torch.no_grad(): # 梯度清零
outputs = googlenet(image.to(device)) # 将图片打入神经网络进行测试
# print(googlenet) # 输出模型结构
# print(outputs) # 输出预测的张量数组
ans = (outputs.argmax(1)).item() # 最大的值即为预测结果,找出最大值在数组中的序号,
# 对应找其在种类中的序号即可然后输出即为其种类
print(classes[ans])代码下载链接:链接:https://pan.baidu.com/s/17ZlSNeQIeG2MqyovwDO9aw
提取码:63j4
文章出处登录后可见!