只保存参数
torch.save(model.state_dict(), path)保存整个模型
torch.save(net, r'LeNet.pth')层数较少的模型没有太大区别

当你训练一个网络,想要提取中间层的参数、或者特征图的时候,使用hook就能派上用场了。
坡度
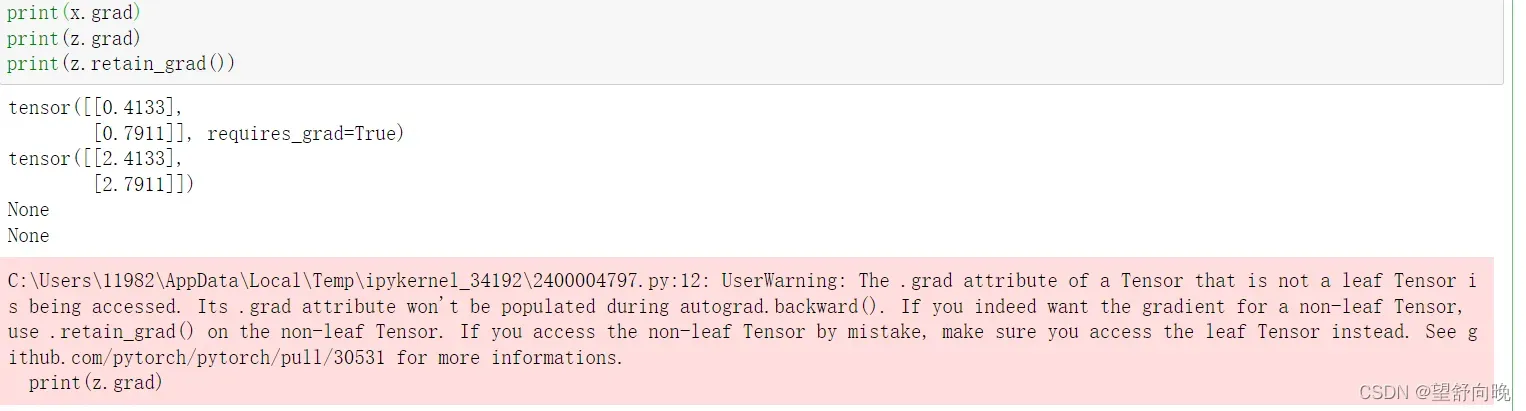
import torch
from torch.autograd import Variable
grad_y=[]
def print_grad_y(grad):
grad_y.append(grad)
x = Variable(torch.randn(2, 1), requires_grad=True)
print(x)
y = x+2
y.register_hook(print_grad_y)
z = torch.mean(torch.pow(y, 2))
lr = 1e-3
z.backward()
x.data -= lr*x.grad.data
print(x.grad)
print(grad_y)


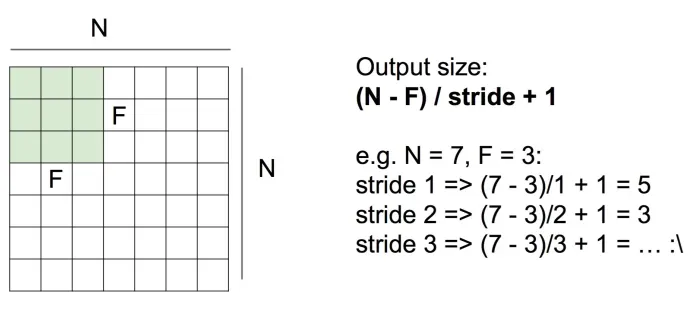
其中N是输入图像的size,F是filter的size,stride是滑动的步长。
stride大于1的时候不一定能整除,这个时候,就需要在原图像上加上一层padding层,这样图像的大小就变化了
卷积神经网络其实和普通的神经网络的区别在于它的输入不再是一维的向量了,而是一个三维的向量,为什么是三维的呢?这是因为图片有三个通道R,G,B。那么输出是什么呢?输出可以认为是一维的向量,比如说那图片分类举例,分为K类的话,输出就是K维的向量。
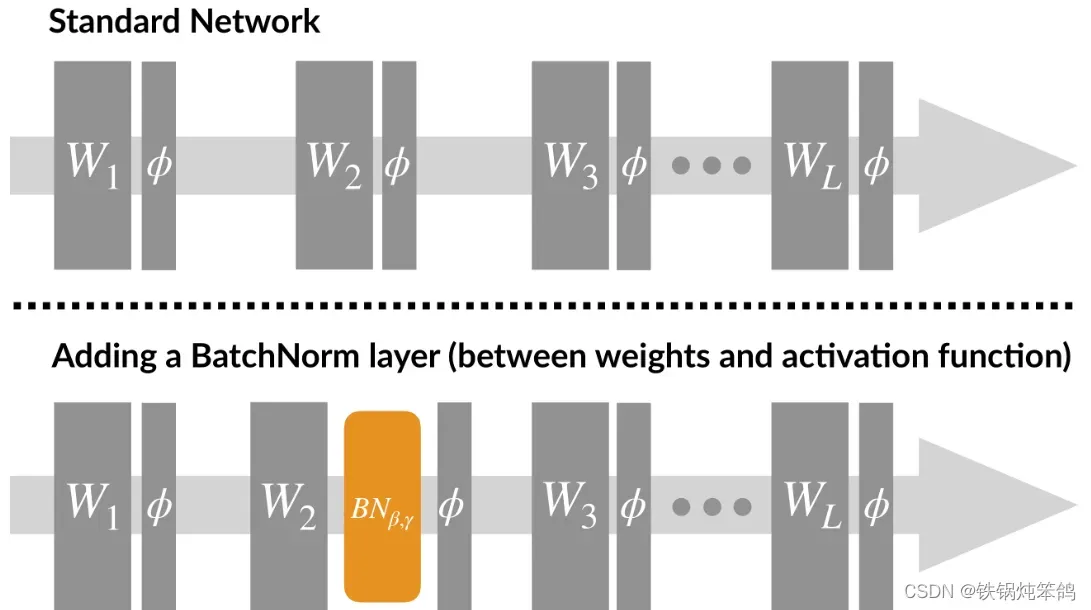
使用Batch Normalization,
- 可以将bias置为0,因为Batch Normalization的Standardization过程会移除直流分量,所以不再需要bias。
权值矩阵、偏置bias
model.state_dict()
pytorch 中的 state_dict 是一个简单的python的字典对象,将每一层与它的对应参数建立映射关系.(如model的每一层的weights及偏置等等)
只有那些参数可以训练的layer才会被保存到模型的state_dict中,如卷积层,线性层等等,像什么池化层、BN层这些本身没有参数的层是没有在这个字典中的;
model.parameters()
parameters没有对应的key名称,是一个由纯参数组成的generator,而state_dict是一个字典,包含了一个key。
在pytorch进行模型保存的时候,一般有两种保存方式,一种是保存整个模型,另一种是只保存模型的参数。
torch.save(model.state_dict(), “my_model.pth”) # 只保存模型的参数
torch.save(model, “my_model.pth”) # 保存整个模型
import torch
model = torch.load('resnet50-19c8e357.pth')
for k in model.keys():
print(k)



- 归一化的目的:
- 使所有的值都落入一个统一的范围内
- 这样算法才能有更好的性能。
模型聚合
模型基于总和的聚合
随机梯度下降用梯度的平均值代替参数的平均值
加权平均
文章出处登录后可见!
已经登录?立即刷新